









Contents
NMS(Non-Max Suppression)
NMS,非极大值抑制,是一种目标检测框架的后处理模块,用来删除检测器输出的冗余bbox。在目标检测领域中被广泛应用,还发展出了相当多的变体。

如上图所示,对每个图中的物体,在图片经过分类器后,会产生多个bbox及对应的置信度,再使用回归网络修正位置。但框的数量还是很多,所以我们需要一种将这些冗余框合并的算法----这就是NMS算法。
首先,NMS又名为非极大值抑制,是通过空间距离结合交并比(IoU)完成聚类的划分。
IoU的计算
IoU是一种简单的评价度量方式,用于评估任何输出为bounding box的模型算法性能。
计算IoU需要Ground-truth bounding box和Predicted bounding box,如下图所示:

IoU被认为是两个区域的重叠部分(交集)除以两个区域的集合部分(并集)所得到的比值。

NMS的步骤
- 将所有框的置信度(得分)排序,选中最高分及其对应的框
- 遍历其余的框,如果和当前得分最高的框的IoU大于所设定的阈值(一般是0.3-0.5),则将该框删除(抑制)。
- 从未处理的框中继续选择一个得分最高的,继续上述过程,直到每个类(cluster)只保留一个得分最高的bbox。
NMS代码实现(来自Fast-RCNN)
import numpy as np
def py_cpu_nms(dets,thresh):
#对x1,y1,x2,y2及score赋值
x1 = dets[:,0]
y1 = dets[:,1]
x2 = dets[:,2]
y2 = dets[:,3]
scores = dets[:,4]
#计算每个检测框的面积
areas = (x2 - x1 + 1) * (y2 - y1 + 1)
#按照每个框的得分(score)降序排序
order = scores.argsort()[::-1]
keep = [] #保留最后留下的bbox集合
while order.size > 0:
i = order[0] #置信度最高的bbox的index
keep.append(i) #保留该类剩余bbox中得分最高的一个的index
#得到重叠区域
#选择大于x1,y1和小于x2,y2的区域
xx1 = np.maximum(x1[i],x1[order[1:]])
yy1 = np.maximum(y1[i],y1[order[1:]])
xx2 = np.minimum(x2[i],x2[order[1:]])
yy2 = np.minimum(y2[i],y2[order[1:]])
#计算重叠面积,不重叠时面积为0
w = np.maximum(0.0,xx2 - xx1 + 1)
h = np.maximum(0.0,yy2 - yy1 + 1)
inter = w * h
#计算IoU=重叠面积/(面积1+面积2-重叠面积)
ovr = inter / (areas[i] + areas[order[1:]] - inter)
#保留IoU小于所设定阈值的bbox
inds = np.where(ovr <= thresh)[0]
order = order[inds + 1] #将所有下标后移一位,因为ovr数组的长度比order的少1
return keep #迭代过程
WBC(Weighted Box Clustering)
WBC,加权框聚类,是在Retina U-Net这篇论文中提出的一种对检测后冗余bbox进行后处理算法,也是用来删除冗余的bbox的。

如上图,可以看出在医学图像上利用WBC的效果优于NMS。
WBC的计算
这个算法与非极大值抑制算法(NMS)类似,根据IoU阈值进行聚类的预测。
其计算公式如下:
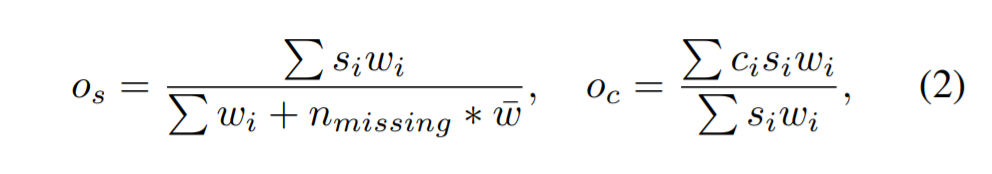
其中,os表示每个预测框的加权置信分数,oc表示每个坐标的加权平均值,i是聚类的下标,s是置信度分数,c是坐标。
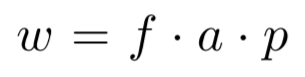
w是加权因子,包含:
重叠因子f:预测框与得分最高的框(softmax confidence)之间的重叠权重。
区域a:表明较大的框有较高的权重。
patch中心因子p:以patch中心的正态分布密度分配分数。
而对于nmissing,如下图:

Prediction1、2、3是对同一张图的三张预测图,1中有两个框,相对来说,2、3中就missing了两个框,所以nmissing=2。
WBC的代码实现(来自Retina U-Net)
import numpy as np
def weighted_box_clustering(dets, box_patch_id, thresh, n_ens):
#2D
dim = 2 if dets.shape[1] == 7 else 3
y1 = dets[:, 0]
x1 = dets[:, 1]
y2 = dets[:, 2]
x2 = dets[:, 3]
scores = dets[:, -3]
box_pc_facts = dets[:, -2]
box_n_ovs = dets[:, -1]
#计算每个检测框的面积
areas = (y2 - y1 + 1) * (x2 - x1 + 1)
#3D
if dim == 3:
z1 = dets[:, 4]
z2 = dets[:, 5]
areas *= (z2 - z1 + 1)
#按照每个框的得分(score)降序排序
order = scores.argsort()[::-1]
keep = [] #保留最后留下的bbox集合
keep_scores = [] #保留最后留下的bbox的置信度集合
keep_coords = [] #保留最后留下的bbox的坐标信息集合
while order.size > 0:
i = order[0] #置信度最高的bbox的index
#得到重叠区域
#选择大于x1,y1和小于x2,y2的区域
xx1 = np.maximum(x1[i], x1[order])
yy1 = np.maximum(y1[i], y1[order])
xx2 = np.minimum(x2[i], x2[order])
yy2 = np.minimum(y2[i], y2[order])
#计算重叠面积,不重叠时面积为0
w = np.maximum(0.0, xx2 - xx1 + 1)
h = np.maximum(0.0, yy2 - yy1 + 1)
inter = w * h
#3D
if dim == 3:
zz1 = np.maximum(z1[i], z1[order])
zz2 = np.minimum(z2[i], z2[order])
d = np.maximum(0.0, zz2 - zz1 + 1)
inter *= d
#计算IoU=重叠面积/(面积1+面积2-重叠面积)
ovr = inter / (areas[i] + areas[order] - inter)
#获取与当前框匹配的所有预测以构建一个聚类(cluster)
matches = np.argwhere(ovr > thresh)
match_n_ovs = box_n_ovs[order[matches]]
match_pc_facts = box_pc_facts[order[matches]]
match_patch_id = box_patch_id[order[matches]]
match_ov_facts = ovr[matches]
match_areas = areas[order[matches]]
match_scores = scores[order[matches]]
#通过patch因子和大小对cluster中的所有分数进行加权
match_score_weights = match_ov_facts * match_areas * match_pc_facts
match_scores *= match_score_weights
#对于权重平均值,分数必须除以当前cluster位置的预期总数。预计每个patch预测1次。因此,整体模型的数量乘以该位置处的patches的平均重叠(cluster的框可能部分位于不同重叠的区域中)。
n_expected_preds = n_ens * np.mean(match_n_ovs)
#获得缺失预测的数量作为补丁的数量,其不对当前聚类(cluster)做出任何预测。
n_missing_preds = np.max((0, n_expected_preds - np.unique(match_patch_id).shape[0]))
#对misssing的预测给出平均权重(预期预测是cluster中所有预测的平均值)。
denom = np.sum(match_score_weights) + n_missing_preds * np.mean(match_score_weights)
#计算聚类(cluster)的加权平均分数
avg_score = np.sum(match_scores) / denom
#计算聚类(cluster)坐标的加权平均值。现在只考虑现有的预测。
avg_coords = [np.sum(y1[order[matches]] * match_scores) / np.sum(match_scores),
np.sum(x1[order[matches]] * match_scores) / np.sum(match_scores),
np.sum(y2[order[matches]] * match_scores) / np.sum(match_scores),
np.sum(x2[order[matches]] * match_scores) / np.sum(match_scores)]
if dim == 3:
avg_coords.append(np.sum(z1[order[matches]] * match_scores) / np.sum(match_scores))
avg_coords.append(np.sum(z2[order[matches]] * match_scores) / np.sum(match_scores))
#由于大量的缺失预测,一些聚类的分数可能非常低。用较小的阈值过滤掉,以加快评估速度。
if avg_score > 0.01:
keep_scores.append(avg_score)
keep_coords.append(avg_coords)
#保留IoU小于所设定阈值的bbox
inds = np.where(ovr <= thresh)[0]
order = order[inds]
return keep_scores, keep_coords















 533
533











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









