






MLMs之SFT/RL:《Retaining by Doing: The Role of On-Policy Data in Mitigating Forgetting》翻译与解读
导读:本文通过理论建模与大规模实证比较指出:在现实的多模态模型行为下,使用 on-policy(或近似 on-policy)数据的训练流程——RL 为代表——在提高目标任务性能的同时更能保留模型原有能力;当资源受限时,在 SFT 中引入近似 on-policy 采样是一个高效且工程可行的缓解遗忘策略。
>> 背景痛点:
● 灾难性遗忘(Catastrophic Forgetting):在对已训练语言模型进行后训练(post-training)以适配新任务时,模型原有的能力会被削弱或丢失,表现为在非目标任务上的性能下降(即“drop”)。这一现象在 SFT(监督微调)和 RL(强化学习)两种常用后训练范式中均被观察到,但其强度与机制有差异。本文把“在提高目标任务上获得 gain 与尽量降低非目标任务 drop”作为核心衡量目标。
● SFT 与 RL 的实务痛点差异:SFT(等价于最小化 forward KL)在实际实验中常需要较大学习率才能获得高目标性能,但这通常会带来更大程度的遗忘;而 RL(对应 reverse KL、带 on-policy 数据)反而在多项实验场景下表现出更低的遗忘。
● 训练超参与稳定性问题:SFT 的性能/遗忘在学习率、训练轮次上存在明显 trade-off — 降低学习率能减少遗忘但会难以達到相同的目标 gain;这给工程部署与超参选择带来困难。
>> 具体的解决方案:
● 三路对照与工程替代:作者在实验上对比了三类后训练方案(Self-SFT、SFT 使用更大模型生成标签、以及 RL(采用 GRPO)),并提出:核心能够减轻遗忘的因素并非 RL 的其他算法细节,而是是否使用(近似)on-policy 数据。在资源受限时,作者还提出用“近似 on-policy 的数据采样(如每个 epoch 开始用当前策略采样)”作为高效折中方案。该做法在多模型、多任务上显著降低了非目标任务的 drop,同时保留或接近 RL 的目标增益。
● 数据与度量工程:目标任务(IFEval、MMLU、Countdown 等)在训练后分别测量 target gain(目标提升)与 non-target drop(非目标下降),并把安全性/数学等作为“非目标”敏感能力用于衡量遗忘。作者用 Llama/Qwen 家族(1B–8B)做广泛对比以保证结论不是单一模型/任务的偶然现象。
>> 核心思路步骤:
建模小标题 — KL 方向与混合分布直观分析:
● 将 SFT 视为最小化 forward KL(mode-covering),将 RL(带 KL 正则的 RL)视为最小化 reverse KL(mode-seeking)。在把目标分布建模为“先验知识模式 + 新任务模式”的混合分布后,作者推导并演示:当初始策略为多模态时,mode-seeking(即 RL)更有可能保持旧模式不被抹掉,从而较少遗忘;相反在单峰(uni-modal)初始策略下,forward KL 可能更稳健。
● 对照/消融与结论归因:三路对照实验(Self-SFT、SFT(大模型标签)、RL/GRPO)在相同训练轮次下比较 gain/drop;并对 RL 的各组成(KL 正则、advantage estimate、on-policy 数据来源等)做消融,结论是on-policy 数据的使用是 RL 抗遗忘的关键,而非其它算法细节。
● 若可用 RL:采用带 KL 正则的 RL(例如 GRPO)并用模型自身生成的 on-policy 样本进行训练(reward 为可验证任务正确/错误),以同时追求高 gain 与低 drop。
● 若资源受限:在 SFT 流程中引入“近似 on-policy 数据”(例如每个 epoch 用当前模型采样并筛选正确样本),即可在成本可控下显著缓解遗忘。
>> 优势:
● 为什么这条路有效:RL(带 on-policy 数据)在本文多项实证中能取得与或高于 SFT 的目标性能,同时显著降低非目标任务的性能下降,说明在实际 LM 后训练中“学新不忘旧”是可实现的。将 on-policy 思路用于 SFT(近似 on-policy)提供了一个低成本、高收益的折中方案:不需完整 RL 训练开销即可获得接近的抗遗忘效果,便于工程化部署。
● 理论直觉与可解释性:通过 forward vs reverse KL 在单峰/多峰情景下不同表现的分析,论文为为何 mode-seeking 在实际(多模态)LM 分布下更不易遗忘提供了直观解释,增强了方法转移与推广的可信度。
>> 论文结论与观点(侧重经验与建议):
● SFT 普遍比 RL 更容易导致遗忘:在作者所覆盖的模型族与任务上(Llama、Qwen,1B–8B;IFEval、MMLU、Countdown 等),SFT 普遍比 RL 更容易导致遗忘;RL 能在不显著牺牲原有能力下实现目标提升。
● SFT 呈现明显的 trade-off —— 提升目标性能通常以牺牲非目标任务为代价(尤其当使用较大学习率时);而 RL 通过 on-policy 采样的方式缓和了这种 trade-off。
● 优先级高:若资源与工程能力允许,优先使用带 KL 正则、基于 on-policy 数据的 RL(如 GRPO)进行后训练,以最大限度降低遗忘风险。
● 资源受限时:若无法做完整 RL,可在 SFT 中实施近似 on-policy 数据采样(例如每个 epoch 用当前策略采样一批示例并筛选正确项),这能大幅降低遗忘成本且易于落地。
● 风险评估:在应用这些结论前应评估初始策略的模态结构(uni-modal vs multi-modal);若模型初始行为近似单峰,部分直觉可能反转,需小规模先验试验验证。
● 规模与任务的泛化性:实验主要在 1B–8B 级模型与若干任务上进行,作者提示对更大规模模型或截然不同任务域的泛化尚需进一步验证。
● on-policy 采样成本与安全合规:尽管近似 on-policy 数据更高效,但仍存在算力、采样延迟、以及在生成数据中需做安全/质量过滤的工程成本;这些在真实产品线中需权衡。
● 目标分布远离初始策略时的风险:附录实验指出,当目标分布与初始策略差距很大时,RL 亦可能遗忘或失败(即 RL 并非在所有情形下完美抗遗忘),因此应对任务差异度进行事前评估。
目录
《Retaining by Doing: The Role of On-Policy Data in Mitigating Forgetting》翻译与解读
《Retaining by Doing: The Role of On-Policy Data in Mitigating Forgetting》翻译与解读
| 地址 | |
| 时间 | 2025年10月21日 |
| 作者 | 普林斯顿大学 |
Abstract
| Adapting language models (LMs) to new tasks via post-training carries the risk of degrading existing capabilities -- a phenomenon classically known as catastrophic forgetting. In this paper, toward identifying guidelines for mitigating this phenomenon, we systematically compare the forgetting patterns of two widely adopted post-training methods: supervised fine-tuning (SFT) and reinforcement learning (RL). Our experiments reveal a consistent trend across LM families (Llama, Qwen) and tasks (instruction following, general knowledge, and arithmetic reasoning): RL leads to less forgetting than SFT while achieving comparable or higher target task performance. To investigate the cause for this difference, we consider a simplified setting in which the LM is modeled as a mixture of two distributions, one corresponding to prior knowledge and the other to the target task. We identify that the mode-seeking nature of RL, which stems from its use of on-policy data, enables keeping prior knowledge intact when learning the target task. We then verify this insight by demonstrating that the use on-policy data underlies the robustness of RL to forgetting in practical settings, as opposed to other algorithmic choices such as the KL regularization or advantage estimation. Lastly, as a practical implication, our results highlight the potential of mitigating forgetting using approximately on-policy data, which can be substantially more efficient to obtain than fully on-policy data. | 通过后期训练来适应语言模型(LM)以完成新任务存在降低现有能力的风险——这一现象在经典上被称为灾难性遗忘。在本文中,为了确定缓解这一现象的指导方针,我们系统地比较了两种广泛采用的后期训练方法:监督微调(SFT)和强化学习(RL)的遗忘模式。我们的实验表明,在语言模型家族(Llama、Qwen)和任务(指令遵循、通用知识和算术推理)中存在一致的趋势:RL 导致的遗忘比 SFT 少,同时在目标任务上的性能相当或更高。为了探究这种差异的原因,我们考虑了一个简化的设置,在该设置中,将语言模型建模为两个分布的混合,一个对应于先验知识,另一个对应于目标任务。我们发现,由于 RL 使用了在策略数据,其模式寻求的特性使得在学习目标任务时能够保持先验知识的完整性。然后,我们通过证明在实际环境中使用策略内数据是强化学习对遗忘具有鲁棒性的基础,从而验证了这一见解,这与诸如 KL 正则化或优势估计等其他算法选择形成了对比。最后,作为实际应用的启示,我们的研究结果表明,使用近似策略内数据来减轻遗忘具有潜力,而且获取近似策略内数据的效率可能比获取完全策略内数据要高得多。 |
Figure 1: Illustration of the forgetting dynamics for the forward KL objective, corresponding to SFT, and the reverse KL objective, corresponding to RL. Left: we model LM post-training as a mixture of two modes. The “old” mode represents prior knowledge and the “new” mode represents a target task. Initially, the old mode of the training policy πθ roughly matches the old mode of the optimal policy π∗, but its additional “new” mode does not match the new target mode. The goal is for the training policy to match the optimal policy. Top right: minimizing forward KL first stretches the new mode of πθ and then moves probability mass from the old mode to cover the target, leading to forgetting. Bottom right: in contrast, minimizing reverse KL maintains the shape of the old mode and covers the target distribution by shifting the new mode of πθ.图 1:前向 KL 目标(对应于策略迁移)和反向 KL 目标(对应于强化学习)的遗忘动态图示。左:我们将训练后的语言模型建模为两种模式的混合。旧模式代表先验知识,新模式代表目标任务。最初,训练策略 πθ 的旧模式大致与最优策略 π* 的旧模式匹配,但其额外的新模式与目标任务模式不匹配。目标是使训练策略与最优策略匹配。右上:最小化前向 KL 首先拉伸 πθ 的新模式,然后将旧模式的概率质量转移到目标上,导致遗忘。右下:相比之下,最小化反向 KL 保持旧模式的形状,并通过移动 πθ 的新模式来覆盖目标分布。
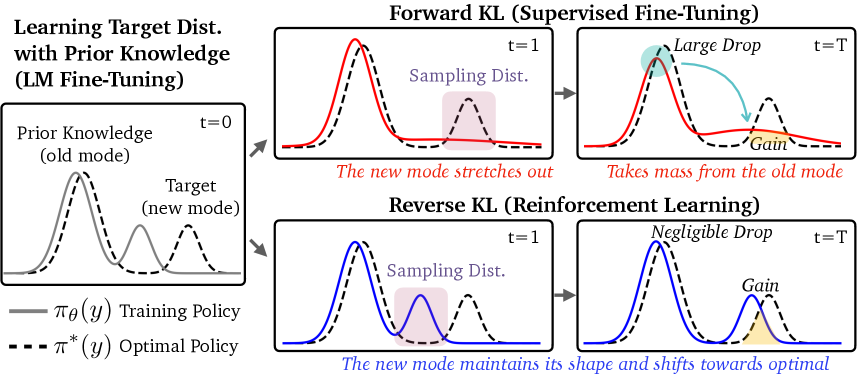
1、Introduction
| Adapting language models (LMs) to new target tasks during post-training carries the risk of eroding previously acquired capabilities—a phenomenon known as catastrophic forgetting (McCloskey & Cohen, 1989; Kirkpatrick et al., 2017). Such forgetting has been reported to occur when training LMs to follow instructions via supervised fine-tuning (SFT) (Luo et al., 2023; Shi et al., 2024; Wu et al., 2024) or aligning them with human preferences via reinforcement learning (RL) (Bai et al., 2022; Ouyang et al., 2022). However, the understanding of how SFT and RL compare in terms of their susceptibility to forgetting remains limited. In this work, we systematically compare the forgetting patterns of SFT and RL in order to identify principled guidelines for mitigating forgetting in LM post-training. We conduct a comprehensive study across instruction following, general knowledge, and arithmetic reasoning tasks, using Qwen 2.5 (Yang et al., 2024) and Llama 3 (Grattafiori et al., 2024) models of up to 8B scale. Our experiments reveal a consistent trend: SFT suffers from severe forgetting, whereas RL can achieve high target task performance without substantial forgetting (Figure 2). | 在语言模型(LM)的后期训练中,将其适应新的目标任务存在削弱先前获得的能力的风险,这一现象被称为灾难性遗忘(McCloskey & Cohen, 1989; Kirkpatrick 等人, 2017)。已有报告指出,在通过监督微调(SFT)(Luo 等人, 2023; Shi 等人, 2024; Wu 等人, 2024)训练语言模型遵循指令,或者通过强化学习(RL)(Bai 等人, 2022; Ouyang 等人, 2022)使其与人类偏好保持一致时,会发生这种遗忘现象。然而,对于 SFT 和 RL 在易发生遗忘方面的比较,目前的理解仍然有限。 在本研究中,我们系统地比较了 SFT 和 RL 的遗忘模式,以确定减轻语言模型后期训练中遗忘现象的原则性指导方针。我们使用 Qwen 2.5(Yang 等人, 2024)和 Llama 3(Grattafiori 等人, 2024)等规模高达 80 亿参数的模型,对指令遵循、通用知识和算术推理任务进行了全面研究。我们的实验揭示了一个一致的趋势:策略迁移(SFT)存在严重的遗忘问题,而强化学习(RL)能够在不出现显著遗忘的情况下实现较高的目标任务性能(图 2)。 |
| We then investigate the cause for the relative robustness of RL to forgetting. At first glance, it may seem at odds with conventional wisdom. Namely, minimizing the cross-entropy loss via SFT is equivalent to minimizing the forward KL divergence with respect to the optimal policy, while maximizing the RL objective corresponds to minimizing the reverse KL (Korbak et al., 2022). Conventional wisdom presumes that the mode-seeking nature of reverse KL enables faster learning of target distributions (Chan et al., 2022; Tajwar et al., 2024b) at the cost of losing coverage of old modes, while the mode-covering forward KL should maintain probability mass across modes. We reconcile this discrepancy by considering a simplified setting, where the target distribution is modeled as a mixture of two distributions: one representing the policy’s prior knowledge and the other representing the target task. We show that, if the initial policy is uni-modal (i.e., has a single mode), then SFT can in fact be more robust than RL to forgetting. However, if the initial policy is multi-modal (i.e., has multiple modes), which is arguably the case for practical LMs, then mode-seeking RL leads to less forgetting than mode-covering SFT; see Figure 1 for an illustration. The mode-seeking behavior of RL (i.e., its accordance with reverse KL minimization) stems from the usage of on-policy data. Through extensive ablations, we empirically verify that this property underlies the robustness of RL to forgetting, as opposed to other algorithmic choices such as the advantage estimation or the application of KL regularization. Moreover, we explore what degree of on-policy data allows mitigating forgetting. We find that for SFT, while generating data only from the initial policy is not enough, approximately on-policy data generated at the start of each epoch can suffice for substantially reducing forgetting. This suggests a practical guideline for LM post-training: leveraging on-policy data, potentially sampled asynchronously or at the start of each epoch for improved efficiency, can reduce unintended disruption of the model’s existing capabilities. | 然后,我们探究了强化学习相对抗遗忘的成因。乍一看,这似乎与传统观念相悖。即,通过策略迁移最小化交叉熵损失等同于相对于最优策略最小化正向 KL 散度,而强化学习的目标最大化则对应于最小化反向 KL 散度(Korbak 等人,2022)。传统观念认为,反向 KL 散度的“模式寻求”特性能够加快目标分布的学习速度(Chan 等人,2022;Tajwar 等人,2024b),但代价是失去对旧模式的覆盖,而“模式覆盖”的正向 KL 散度应能保持各模式的概率质量。我们通过考虑一个简化的设定来解决这一矛盾,即目标分布被建模为两个分布的混合:一个代表策略的先验知识,另一个代表目标任务。我们表明,如果初始策略是单峰的(即只有一个峰值),那么 SFT 实际上比 RL 对遗忘更具鲁棒性。然而,如果初始策略是多峰的(即有多个峰值),这在实际的语言模型中很常见,那么模式寻求型的 RL 导致的遗忘比模式覆盖型的 SFT 要少;见图 1 以作说明。 强化学习(RL)的模式寻求行为(即其与反向 KL 最小化的一致性)源于使用了“在策略”数据。通过大量的消融实验,我们实证验证了这一特性是强化学习对遗忘具有鲁棒性的基础,这与其他算法选择(如优势估计或应用 KL 正则化)不同。此外,我们还探究了何种程度的“在策略”数据能够减轻遗忘。我们发现,对于 SFT 而言,仅从初始策略生成数据是不够的,但在每个时期开始时生成的“近似在策略”数据就足以大幅减少遗忘。这为语言模型的后期训练提供了一条实用的指导方针:利用“在策略”数据,可能异步采样或在每个时期开始时采样以提高效率,可以减少对模型现有能力的意外干扰。 |
| To summarize, our main contributions are: >> We demonstrate that RL is more robust to forgetting than SFT through extensive experiments on instruction following, general knowledge, and reasoning tasks, using LMs from different families and scales. >> We provide intuition for why the mode-seeking nature of RL, which stems from its use of on-policy data, can counterintuitively lead to less forgetting than mode-covering SFT. >> We corroborate this insight by demonstrating that the use of on-policy data underlies the robustness of RL to forgetting in practical settings, and highlight the potential of mitigating forgetting through approximately on-policy data, which can be substantially more efficient to obtain than fully on-policy data. | 综上所述,我们的主要贡献在于: >> 通过在指令遵循、通用知识和推理任务上进行大量实验,我们证明了强化学习(RL)比监督微调(SFT)更能抵御遗忘现象,实验中使用了来自不同家族和规模的语言模型。 >> 我们提供了直觉解释,说明了强化学习寻求模式的特性(源于其使用在策略数据)为何会反直觉地导致比覆盖模式的监督微调更少的遗忘。 >> 我们通过实验证明,在实际场景中,使用在策略数据是强化学习抵御遗忘现象的基础,并强调了通过近似在策略数据来减轻遗忘现象的潜力,这比获取完全在策略数据要高效得多。 |
6 Conclusion
| We systematically compared catastrophic forgetting in SFT and RL for LM post-training. Across tasks, scales, and model families, we found that RL consistently achieves strong target performance with substantially less forgetting than SFT. Our experiments in both simplified and real-world settings establish that the robustness of RL to forgetting primarily stems from its use of on-policy data, rather than other algorithmic choices such as the advantage estimate or KL regularization. Furthermore, they highlight the potential of efficiently mitigating forgetting by incorporating approximately on-policy data, sampled asynchronously or at the start of each epoch. | 我们系统地比较了语言模型在 SFT 和 RL 后训练中的灾难性遗忘情况。在各项任务、不同规模和模型家族中,我们发现 RL 一直能取得强劲的目标性能,且遗忘程度明显低于 SFT。我们在简化和真实世界设置中的实验表明,RL 对遗忘的鲁棒性主要源于其使用了在策略数据,而非优势估计或 KL 正则化等其他算法选择。此外,它们还突显了通过引入近似在策略数据(异步采样或在每个时期开始时采样)来有效减轻遗忘的潜力。 |
| Limitations and future directions. Our work provides evidence that RL is more robust than SFT to forgetting across several tasks, model families, and scales. However, investigating how forgetting patterns vary as the model and dataset sizes are further scaled, beyond our compute budget, remains a valuable direction for future work. Moreover, while we provide intuition for why RL forgets less than SFT based on a simplified mixture-of-Gaussians setting (§3) and empirically identify the use of on-policy data as a main cause for this difference in forgetting (§4), additional research is necessary to theoretically establish the role of on-policy data in mitigating forgetting. Going forward, the issue of forgetting becomes central as the community moves toward building agents that continually learn from experience (Silver & Sutton, 2025). Deciding what data to consume is consequential to the stability of the agent. Our results indicate that data generated on-policy will better preserve existing capabilities, and is therefore safer to learn from, than off-policy data such as content on the internet or experience from other agents. In a similar vein, our insights lays groundwork for understanding forgetting in the emerging paradigm of test-time training (Sun et al., 2020; Hardt & Sun, 2024). | 局限性和未来方向。我们的工作提供了证据,表明 RL 在多个任务、模型家族和规模上都比 SFT 更能抵抗遗忘。然而,研究随着模型和数据集规模进一步扩大(超出我们的计算预算)遗忘模式的变化,仍是未来工作的一个有价值的方向。此外,虽然我们基于简化的高斯混合模型设置(第 3 节)提供了强化学习(RL)比监督学习(SFT)遗忘更少的直觉,并通过实证研究确定了使用策略内数据是造成这种遗忘差异的主要原因(第 4 节),但还需要进一步的研究从理论上阐明策略内数据在减少遗忘方面的作用。展望未来,随着社区朝着构建能够持续从经验中学习的智能体迈进(Silver & Sutton, 2025),遗忘问题将变得至关重要。决定智能体应消费何种数据对其稳定性具有重大影响。我们的研究结果表明,策略内生成的数据将更好地保留现有能力,因此比诸如互联网内容或来自其他智能体的经验等策略外数据更安全。同样,我们的见解为理解新兴的测试时训练范式中的遗忘问题奠定了基础(Sun 等人,2020;Hardt & Sun,2024)。 |




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











