









DL框架之Tensorflow:深度学习框架Tensorflow的简介、安装、使用方法之详细攻略
目录
(1)、ML之LoR:利用LoR算法(tensorflow)对mnist数据集实现手写数字识别
Tensorflow的简介
TensorFlow是一个基于数据流编程(dataflow programming)的符号数学系统,被广泛应用于各类机器学习(machine learning)算法的编程实现,其前身是谷歌的神经网络算法库DistBelief 。
TensorFlow 最初由Google大脑小组(隶属于Google机器智能研究机构)的研究员和工程师们开发出来,用于机器学习和深度神经网络方面的研究,但这个系统的通用性使其也可广泛用于其他计算领域。TensorFlow由谷歌人工智能团队谷歌大脑(Google Brain)开发和维护,拥有包括TensorFlow Hub、TensorFlow Lite、TensorFlow Research Cloud在内的多个项目以及各类应用程序接口(Application Programming Interface, API)。自2015年11月9日起,TensorFlow依据阿帕奇授权协议(Apache 2.0 open source license)开放源代码。
2015年11月9日,Goggle宣布对Tensorflow开源。一时间Tensorflow在CitHub上面的下载量跃升至全站第2位,可见全世界兴趣爱好者对这款开源软件的热情。作者曾在前言中说过,现如今许多知名的IT企业,Google、Facebook、Microsoft、Apple甚至国内的百度,无不在机器学习研究领域给予非常大的资金和人力的投人;但是,鲜有将内部使用的平台公之于众的。
许多人开始以为Tensorflow只是一个用于深入学习研究的系统,其实不然。应该说,这是一个完整的编码框架。就如同我们按照Python编程语法设计程序一样,Tensorflow内部也有自己所定义的常量、变量、数据操作等要素。不同的是,Tensorflow使用图(Graph)来表示计算任务,并使用会话(Session)来执行图。
TensorFlow是一个采用数据流图(data flow graphs),用于数值计算的开源软件库。节点(Nodes)在图中表示数学操作,图中的线(edges)则表示在节点间相互联系的多维数据数组,即张量(tensor)。它灵活的架构让你可以在多种平台上展开计算,例如台式计算机中的一个或多个CPU(或GPU),服务器,移动设备等等。Tensorflow拥有多层级结构,可部署于各类服务器、PC终端和网页并支持GPU和TPU高性能数值计算,被广泛应用于谷歌内部的产品开发和各领域的科学研究。
参考文章
Tensorflow英文官网
Tensorflow中文社区
Tensorflow官方教程
Tensorflow新手入门
Tensorflow中文文档
1、描述
2015年10月05日,谷歌为TensorFlow提交了注册商标申请(登记编号86778464),并这样描述它:
- (1)、用以编写程序的计算机软件;
- (2)、计算机软件开发工具;
- (3)、可应用于人工智能、深度学习、高性能计算、分布式计算、虚拟化和机器学习这些领域;
- (4)、软件库可应用于通用目的的计算、数据收集的操作、数据变换、输入输出、通信、图像显示、人工智能等领域的建模和测试;
- (5)、软件可用作应用于人工智能等领域的应用程序接口(API)。
2、TensorFlow的六大特征
- 高度的灵活性:TensorFlow 不是一个严格的“神经网络”库。只要你可以将你的计算表示为一个数据流图,你就可以使用Tensorflow。你来构建图,描写驱动计算的内部循环。我们提供了有用的工具来帮助你组装“子图”(常用于神经网络),当然用户也可以自己在Tensorflow基础上写自己的“上层库”。定义顺手好用的新复合操作和写一个python函数一样容易,而且也不用担心性能损耗。当然万一你发现找不到想要的底层数据操作,你也可以自己写一点c++代码来丰富底层的操作。
- 真正的可移植性(Portability):Tensorflow 在CPU和GPU上运行,比如说可以运行在台式机、服务器、手机移动设备等等。想要在没有特殊硬件的前提下,在你的笔记本上跑一下机器学习的新想法?Tensorflow可以办到这点。准备将你的训练模型在多个CPU上规模化运算,又不想修改代码?Tensorflow可以办到这点。想要将你的训练好的模型作为产品的一部分用到手机app里?Tensorflow可以办到这点。你改变主意了,想要将你的模型作为云端服务运行在自己的服务器上,或者运行在Docker容器里?Tensorfow也能办到。Tensorflow就是这么拽 :)
- 将科研和产品联系在一起:过去如果要将科研中的机器学习想法用到产品中,需要大量的代码重写工作。那样的日子一去不复返了!在Google,科学家用Tensorflow尝试新的算法,产品团队则用Tensorflow来训练和使用计算模型,并直接提供给在线用户。使用Tensorflow可以让应用型研究者将想法迅速运用到产品中,也可以让学术性研究者更直接地彼此分享代码,从而提高科研产出率。
- 自动求微分:基于梯度的机器学习算法会受益于Tensorflow自动求微分的能力。作为Tensorflow用户,你只需要定义预测模型的结构,将这个结构和目标函数(objective function)结合在一起,并添加数据,Tensorflow将自动为你计算相关的微分导数。计算某个变量相对于其他变量的导数仅仅是通过扩展你的图来完成的,所以你能一直清楚看到究竟在发生什么。
- 多语言支持:Tensorflow 有一个合理的c++使用界面,也有一个易用的python使用界面来构建和执行你的graphs。你可以直接写python/c++程序,也可以用交互式的ipython界面来用Tensorflow尝试些想法,它可以帮你将笔记、代码、可视化等有条理地归置好。当然这仅仅是个起点——我们希望能鼓励你创造自己最喜欢的语言界面,比如Go,Java,Lua,Javascript,或者是R。
- 性能最优化:比如说你又一个32个CPU内核、4个GPU显卡的工作站,想要将你工作站的计算潜能全发挥出来?由于Tensorflow 给予了线程、队列、异步操作等以最佳的支持,Tensorflow 让你可以将你手边硬件的计算潜能全部发挥出来。你可以自由地将Tensorflow图中的计算元素分配到不同设备上,Tensorflow可以帮你管理好这些不同副本。
3、了解Tensorflow
2017年谷歌开发者大会欧洲站上,谷歌研究院工程师Andrew Gasparovic所做演讲。他用深入浅出、妙趣横生的方式,给大家分享了TensorFlow的发展情况与最新成果。
TensorFlow能够让你直接解决各种机器学习任务。目标就是在一般情况下,无论你遇到什么问题,TensorFlow都可以在一定程度上提供API的支持。总的来说TensorFlow就是为了快而设计的,所以它针对你实际使用的硬件和平台做了优化。其中在机器学习框架方面,TensorFlow的真正独特之处在于,能够在5行或者10行代码中构建模型。然后应用这个模型,进行扩展做出产品。因此,你能够在几十甚至几百个机器的簇上进行训练。从而用该模型进行非常低的延迟预测。
4、TensorBoard:可视化学习
参考文章:TF之Tensorboard:Tensorflow之Tensorboard可视化简介、入门、使用方法之详细攻略
Tensorflow的安装
Anaconda之tensorflow:深度学习之Anaconda下安装tensorflow正确运行之史上最强攻略
Py之TF/Cuda/Cudnn:Win10下安装深度学习框架Tensorflow+Cuda+Cudnn最简单最快捷最详细攻略
TF学习——TensorFlow:深度学习框架TensorFlow & TensorFlow-GPU的简介、安装详细攻略
TensorFlow基础知识架构
1、基础知识架构
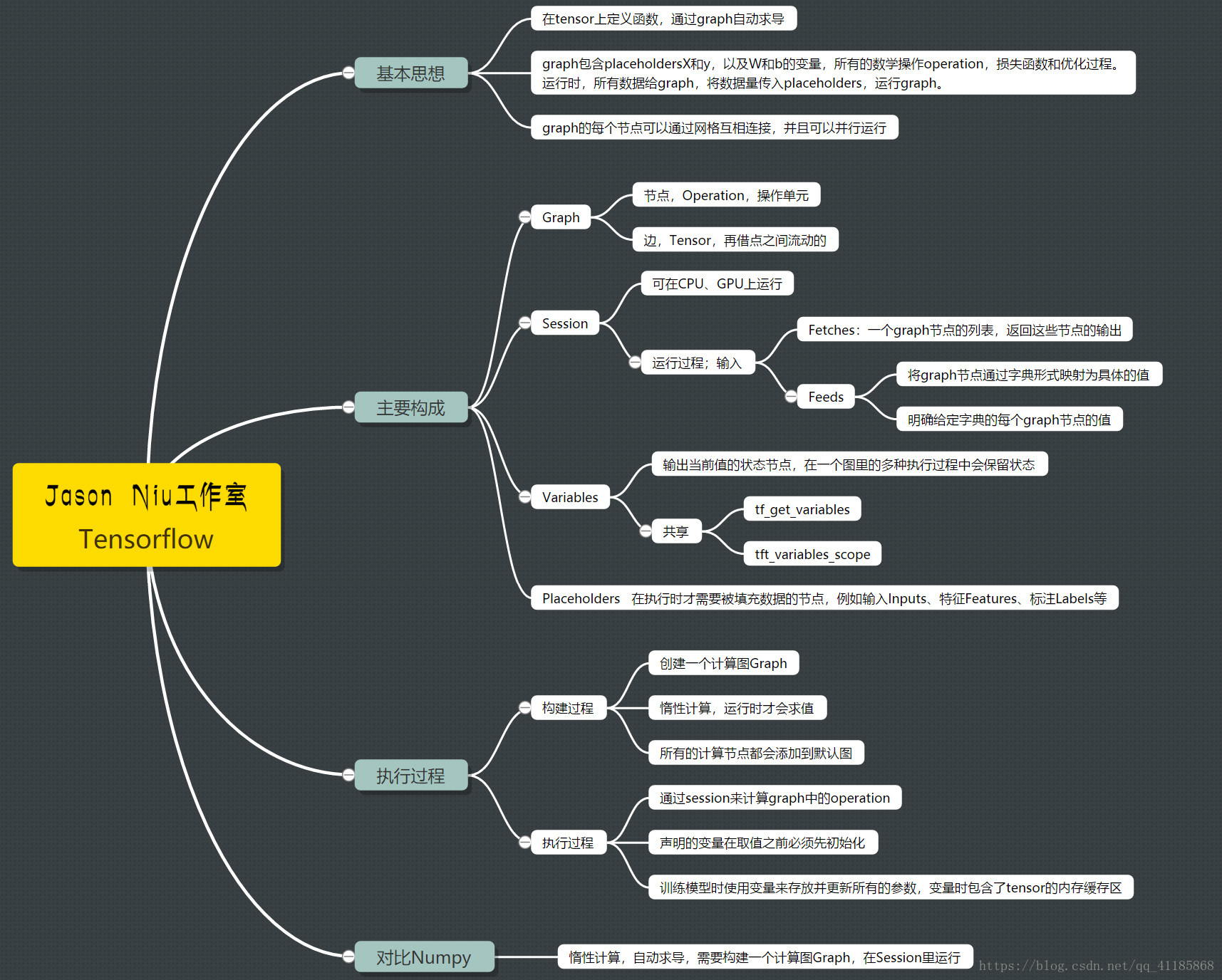
2、计算图与会话
1、计算图方法
基本上所有的Tensorflow代码都包含两个重要部分:
- 构建计算图(使用tf.Graph)
- 运行会话(使用tf.Session),执行图中的运算
2、计算图由两种类型的对象组成
(1)、操作(简称“op”):图的节点。操作描述了消耗和生成张量的计算。

(2)、张量:图的边。它们代表将流经图的值。大多数TensorFlow 函数会返回tf.Tensors。
重要提示:tf.Tensors 不具有值,它们只是计算图中元素的手柄。
Edges are N-dimensional arrays:Tensors
with tensors 保留tensors

with state 保留状态

3、图和会话
- TensorFlow 使用数据流图将计算表示为独立的指令之间的依赖关系。
- 这可生成低级别的编程模型,在该模型中,你首先定义数据流图,然后创建TensorFlow 会话,以便在一组本地和远程设备上运行图的各个部分。
- 较高阶的API(例如tf.estimator.Estimator 和Keras)会向最终用户隐去图和会话的细节内容。
2、相关概念
1、张量(tensor)
TensorFlow 中的核心数据单位是张量(tensor)。一个张量由一组形成阵列(任意维数)的原始值组成。张量的阶(rank)是它的维数,而它的形状(shape)是一个整数元组,指定了阵列每个维度的长度。以下是张量值的一些示例:
3. # a rank 0 tensor; a scalar with shape [],
[1., 2., 3.] # a rank 1 tensor; a vector with shape [3]
[[1., 2., 3.], [4., 5., 6.]] # a rank 2 tensor; a matrix with shape [2, 3]
[[[1., 2., 3.]], [[7., 8., 9.]]] # a rank 3 tensor with shape [2, 1, 3] TensorFlow 使用numpy数组来表示张量值。
tf.Tensor 具有以下属性:
- 数据类型(例如float32、int32 或string)
- 形状
张量中的每个元素都具有相同的数据类型,且该数据类型一定是已知的。形状,即张量的维数和每个维度的大小,可能只有部分已知。如果其输入的形状也完全已知,则大多数操作会生成形状完全已知的张量,但在某些情况下,只能在执行图时获得张量的形状。
(1)、阶(rank)和形状(shape)
tf.Tensor 对象的阶是它本身的维数。阶的同义词包括:秩、等级或n 维。请注意,TensorFlow 中的阶与数学中矩阵的阶并不是同一个概念。如下表所示,TensorFlow 中的每个阶都对应一个不同的数学实例:
张量的形状是每个维度中元素的数量。TensorFlow 在图的构建过程中自动推理形状。这些推理的形状可能具有已知或未知的阶。如果阶已知,则每个维度的大小可能已知或未知。TensorFlow 文件编制中通过三种符号约定来描述张量维度:阶,形状和维数。下表阐述了三者如何相互关联:



Tensorflow的使用入门
1、基础用法
sess.run()
#当我们构建完图后,需要在一个会话中启动图,启动的第一步是创建一个Session对象。 为了取回(Fetch)操作的输出内容, 可以在使用 Session 对象的 run()调用执行图时,传入一些 tensor, 这些 tensor 会帮助你取回结果。那么调用sess.run()的时候,ensorflow并没有计算整个图,只是计算了与想要fetch 的值相关的部分。
占位符和 feed_dict :占位符并没有初始值,它只会分配必要的内存。在会话中,占位符可以使用 feed_dict 馈送数据。 feed_dict 是一个字典,在字典中需要给出每一个用到的占位符的取值。在训练神经网络时需要每次提供一个批量的训练样本,如果每次迭代选取的数据要通过常量表示,那么 TensorFlow 的计算图会非常大。因为每增加一个常量,TensorFlow 都会在计算图中增加一个结点。所以说拥有几百万次迭代的神经网络会拥有极其庞大的计算图,而占位符却可以解决这一点,它只会拥有占位符这一个结点。
(1)、输出tensorflow的版本号
import tensorflow as tf
print('输出tensorflow的版本:',tf.__version__)(2)、使用Tensorflow输出一句话
#TF:使用Tensorflow输出一句话
import tensorflow as tf
import numpy as np
greeting = tf.constant('Hello Google Tensorflow!')
sess = tf.Session() #启动一个会话
result = sess.run(greeting) #使用会话执行greeting计算模块
print(result)
sess.close() #关闭会话,这是一种显式关闭会话的方式![]()
2、进阶用法
(1)、TF实现加法
张量和图的两种方式实现:声明两个常量 a 和 b,并定义一个加法运算。先定义一张图,然后运行它,
# -*- coding: utf-8 -*-
#1、张量和图的两种方式实现:声明两个常量 a 和 b,并定义一个加法运算。先定义一张图,然后运行它,
import tensorflow as tf
import os
import numpy as np
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2'
#T1
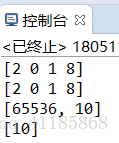
a=tf.constant([1,0,1,4])
b=tf.constant([ 1 , 0 , 0 , 4 ])
result=a+b
sess=tf. Session ()
print (sess.run(result))
sess.close
#T2
with tf.Session() as sess:
a=tf.constant([ 1 , 0 , 1 , 4 ])
b=tf.constant([ 1 , 0 , 0 , 4 ])
result=a+b
print (sess.run(result))
#2、常量和变量
#TensorFlow 中最基本的单位是常量(Constant)、变量(Variable)和占位符(Placeholder)。常量定义后值和维度不可变,变量定义后值可变而维度不可变。在神经网络中,变量一般可作为储存权重和其他信息的矩阵,而常量可作为储存超参数或其他结构信息的变量。下面我们分别定义了常量与变量
#声明了不同的常量(tf.constant())
a = tf.constant( 2 , tf.int16) #声明了不同的整数型数据
b = tf.constant( 4 , tf.float32) #声明了不同的浮点型数据
c = tf.constant( 8 , tf.float32)
#声明了不同的变量(tf.Variable())
d = tf. Variable ( 2 , tf.int16)
e = tf. Variable ( 4 , tf.float32)
f = tf. Variable ( 8 , tf.float32)
g = tf.constant(np.zeros(shape=( 2 , 2 ), dtype=np.float32))#声明结合了 TensorFlow 和 Numpy
h = tf.zeros([ 11 ], tf.int16) #产生全是0的矩阵
i = tf.ones([ 2 , 2 ], tf.float32) #产生全是 1的矩阵
j = tf.zeros([ 1000 , 4 , 3 ], tf.float64)
k = tf. Variable (tf.zeros([ 2 , 2 ], tf.float32))
l = tf. Variable (tf.zeros([ 5 , 6 , 5 ], tf.float32))
#声明一个 2 行 3 列的变量矩阵,该变量的值服从标准差为 1 的正态分布,并随机生成
w1=tf.Variable(tf.random_normal([2,3],stddev=1,seed=1))
#TensorFlow 还有 tf.truncated_normal() 函数,即截断正态分布随机数,它只保留 [mean-2*stddev,mean+2*stddev] 范围内的随机数
#案例应用:应用变量来定义神经网络中的权重矩阵和偏置项向量
weights = tf.Variable(tf.truncated_normal([256 * 256, 10]))
biases = tf. Variable (tf.zeros([10]))
print (weights.get_shape().as_list())
print (biases.get_shape().as_list())
(3)、TF实现乘法
Tensorflow之session会话的使用,定义两个矩阵,两种方法输出2个矩阵相乘的结果
import tensorflow as tf
matrix1 = tf.constant([[3, 20]])
matrix2 = tf.constant([[6],
[100]])
product = tf.matmul(matrix1, matrix2)
# method 1,常规方法
sess = tf.Session()
result = sess.run(product)
print(result)
sess.close()
# # method 2,with方法
# with tf.Session() as sess: #
# result2 = sess.run(product)
# print(result2)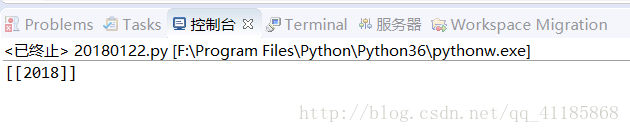
(4)、TF实现计算功能
输出结果
代码设计
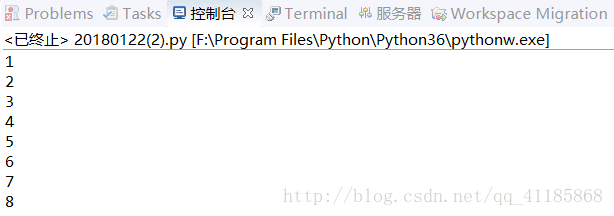
#TF:Tensorflow定义变量+常量,实现输出计数功能
import tensorflow as tf
state = tf.Variable(0, name='Parameter_name_counter')
#print(state.name)
one = tf.constant(1)
new_value = tf.add(state, one)
update = tf.assign(state, new_value)
init = tf.global_variables_initializer()
with tf.Session() as sess:
sess.run(init)
for _ in range(8):
sess.run(update)
print(sess.run(state))(5)、利用Tensorflow完成一次线性函数计算
#TF:Tensorflow完成一次线性函数计算
#思路:TF像搭积木一样将各个不同的计算模块拼接成流程图,完成一次线性函数的计算,并在一个隐式会话中执行。
matrix1 = tf.constant([[3., 3.]]) #声明matrix1为TF的一个1*2的行向量
matrix2 = tf.constant([[2.],[2.]]) #声明matrix2为TF的一个2*1的列向量
product = tf.matmul(matrix1, matrix2) #两个算子相乘,作为新算例
linear = tf.add(product, tf.constant(2.0)) #将product与一个标量2求和拼接.作为最终的linear算例
#直接在会话中执行linear算例,相当于将上面所有的单独算例拼接成流程图来执行
with tf.Session() as sess:
result = sess.run(linear)
print(result)
(6)、使用常量和占位符进行计算
#使用常量和占位符进行计算:其中 y_1 的计算过程使用占位符,而 y_2 的计算过程使用常量
w1=tf. Variable (tf.random_normal([ 1 , 2 ],stddev= 1 ,seed= 1 )) #因为需要重复输入x,而每建一个x就会生成一个结点,计算图的效率会低。所以使用占位符
x=tf.placeholder(tf.float32,shape=( 1 , 2 ))
x1=tf.constant([[ 0.7 , 0.9 ]])
a=x+w1
b=x1+w1
sess=tf. Session ()
sess.run(tf.global_variables_initializer()) #运行y时将占位符填上,feed_dict为字典,变量名不可变
y_1=sess.run(a,feed_dict={x:[[ 0.7 , 0.9 ]]})
y_2=sess.run(b)
print (y_1)
print (y_2)
sess.close
(7)、输出w、b和计算两个数值相乘
import tensorflow as tf
import numpy as np
W = tf.Variable(np.arange(6).reshape((2, 3)), dtype=tf.float32, name="weights")
b = tf.Variable(np.arange(3).reshape((1, 3)), dtype=tf.float32, name="biases")
saver = tf.train.Saver()
with tf.Session() as sess:
saver.restore(sess, "niu/save_net.ckpt")
print("weights:", sess.run(W))
print("biases:", sess.run(b))
import tensorflow as tf
#构建一个计算图
a=tf.constant([1.0, 2.0])
b=tf.constant([3.0, 4.0])
c=a*b
#T1、传统的方法,先构建再释放
sess=tf.Session() #构建一个Session
print(sess.run(c)) #把计算图放到session里,并运行得到结果
sess.close() #关闭session释放资源
#T2、with语句的方法,先构建再释放
with tf.Session() as sess:
print(sess.run(c)) #把计算图放到session里,并运行得到结果 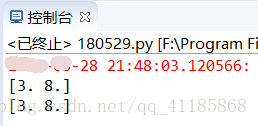
Tensorflow的案例应用
1、基础用法
(1)、TF根据三维数据拟合平面
Python 程序生成了一些三维数据, 然后用一个平面拟合它.
import tensorflow as tf
import numpy as np
# 使用 NumPy 生成假数据(phony data), 总共 100 个点.
x_data = np.float32(np.random.rand(2, 100)) # 随机输入
y_data = np.dot([0.100, 0.200], x_data) + 0.300
# 构造一个线性模型
#
b = tf.Variable(tf.zeros([1]))
W = tf.Variable(tf.random_uniform([1, 2], -1.0, 1.0))
y = tf.matmul(W, x_data) + b
# 最小化方差
loss = tf.reduce_mean(tf.square(y - y_data))
optimizer = tf.train.GradientDescentOptimizer(0.5)
train = optimizer.minimize(loss)
# 初始化变量
init = tf.initialize_all_variables()
# 启动图 (graph)
sess = tf.Session()
sess.run(init)
# 拟合平面
for step in xrange(0, 201):
sess.run(train)
if step % 20 == 0:
print step, sess.run(W), sess.run(b)
# 得到最佳拟合结果 W: [[0.100 0.200]], b: [0.300]2、进阶用法
(1)、ML之LoR:利用LoR算法(tensorflow)对mnist数据集实现手写数字识别
import tensorflow as tf
import numpy as np
from tensorflow.examples.tutorials.mnist import input_data
#1、定义数据集:mnist
mnist = input_data.read_data_sets('MNIST_data', one_hot=True)
trainimg = mnist.train.images
trainimg_label = mnist.train.labels
testimg = mnist.test.images
testimg_label = mnist.test.labels
print(trainimg_label[0]) #输出第一行label值
#2、定义x、y、w、b:tf.placeholder占位符、tf.Variable变量
x = tf.placeholder("float",[None,784]) # [None,784]样本的个数(无限大),每个样本的特征(784个像素点)
y = tf.placeholder("float",[None,10]) #样本的类别(10个)
W = tf.Variable(tf.zeros([784,10])) #每个特征(784个像素点)对应输出10个分类值
b = tf.Variable(tf.zeros([10]))
#3、模型预测:LoR(softmax多分类)
#3.1、定义计算损失:actv、cost
actv = tf.nn.softmax(tf.matmul(x,W)+b) #计算属于正确类别的概率值
cost = tf.reduce_mean(-tf.reduce_sum(y*tf.log(actv),reduction_indices=1)) #计算损失值(预测值与真实值间的均方差)
#3.2、定义模型训练:learning_rate、optm:
#(1)、采用GD优化参数w、b,最小化损失值
learning_rate=0.01
optm = tf.train.GradientDescentOptimizer(learning_rate).minimize(cost) #学习率为0.01
# optimizer = tf.train.GradientDescentOptimizer(0.01) #学习率为0.01
# optm = optimizer.minimize(cost) #最小化损失值
#3.3、定义模型的pred、accr
pred = tf.equal(tf.argmax(actv,1),tf.argmax(y,1)) #预测值:equal返回的值是布尔类型,argmax返回矩阵中最大元素的索引,0,代表列方向;1代表行方向
accr = tf.reduce_mean(tf.cast(pred,"float")) #准确率,cast进行类型转化 (true为1,false为0)
#3.4、定义模型训练参数init_op、train_epochs、batch_size、display_step
init_op = tf.global_variables_initializer() #初始化所有variables 的op
train_epochs = 50 #将所有样本迭代50次
batch_size = 100 #每次迭代选择样本的个数
display_step =5 #每进行5个epoch进行一次展示
#3.5、运行模型tf.Session()
with tf.Session() as sess: #在session中启动graph
sess.run(init_op) #启动运行使用variables的op
for epoch in range(train_epochs):
#(1)、定义avg_cost、num_batch
avg_cost =0.0 #初始化损失值
num_batch = int(mnist.train.num_examples/batch_size)
#(2)、for循环实现num_batch批量训练
for i in range(num_batch):
batch_xs, batch_ys = mnist.train.next_batch(batch_size) #以batch为单位逐次进行
sess.run(optm,feed_dict={x: batch_xs,y: batch_ys}) #给x,y赋值
feeds={x: batch_xs,y: batch_ys}
avg_cost +=sess.run(cost,feed_dict= feeds)/num_batch
#(3)、if判断实现每轮结果输出:输出每轮(5个epoch)的cost、trian_acc、test_acc
if epoch % display_step == 0:
feeds_train = {x: batch_xs,y: batch_ys}
feeds_test = {x:mnist.test.images,y: mnist.test.labels}
train_acc = sess.run(accr,feed_dict= feeds_train)
test_acc = sess.run(accr,feed_dict= feeds_test)
print("Epoch: %03d/%03d cost:%.9f trian_acc: %.3f test_acc: %.3f"
% (epoch,train_epochs,avg_cost,train_acc,test_acc))
print("Done")
















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











