






Structural Deep Embedding for Hyper-Networks
基本信息
博客贡献人
垂杨柳
作者
Haoyu Wang, Defu Lian*, Yong Ge
[重要作者提示]
标签
network embedding;hyperedges;structural deep embedding
摘要
用超边对超网进行分解,提出了DHNE模型(Deep Hyper-Network Embedding),以学习有着不可分解的hyperedges的网络的嵌入表示。
从理论上证明了现有方法中常用的嵌入空间的线性相似度度量不能保持超网络的不可分解性。
问题定义
Definition 1 (Hyper-network). 一个hyper-graph定义为 G = ( V , E ) G=(V,E) G=(V,E),其中 V V V是节点集合,有 T T T种类型, V = { V t } t = 1 T V=\{V_t\}^T_{t=1} V={Vt}t=1T, E E E为边的集合,每个边由于多于2个节点组成, E = E i = ( v i , v 2 , … , v n ) ( n ≥ 2 ) E=E_i=(v_i,v_2,\dots,v_n)(n\geq 2) E=Ei=(vi,v2,…,vn)(n≥2)。边 E i E_i Ei的类型是边中所有节点类型的组合。若 T ≥ 2 T\geq2 T≥2,则该hyper-network是异质的。
**Definition 2 (The First-order Proximity of Hyper-network).**衡量了节点之间N-tuplewise的相似性。对于N个节点,如果存在一个hyper-edge包含了这N个节点,则这N个节点的一阶相似性为1。而且这N个节点的任意子集都没有一阶相似性。
**Definition 3 (The Second-order Proximity of Hyper-network).**二阶相似性衡量了给定邻域结构的两点之间的相似性。对于任意节点 v i ∈ E i v_i\in E_i vi∈Ei, E i / v i E_i/v_i Ei/vi表示节点 v i v_i vi的邻居。如果 v i v_i vi的邻居 { E i / v i f o r a n y v i ∈ E i } \{E_i/v_i\ for \ any \ v_i\in E_i\} {Ei/vi for any vi∈Ei}和 v j v_j vj的邻居相似,则 v i v_i vi的向量表示和 v j v_j vj的相似。
例如,在图中, A 1 A_1 A1的邻居集合为 { ( L 2 , U 1 ) , ( L 1 , U 2 ) } \{(L_2, U_1), (L_1, U_2)\} {(L2,U1),(L1,U2)}。其中 A 1 , A 2 A_1,A_2 A1,A2有二阶相似性,因为他们有共同的邻居 ( L 1 , U 2 ) (L_1,U_2) (L1,U2)。
对于一个图 G G G,我们需要相应节点的嵌入来进行下游的各种任务。现有的绝大多数网络嵌入方法都是为一般的pairwise network设计的,即每条边仅连接一对节点。然而在现实的应用中,节点之间的关系是比较复杂的,超越了pairwise,可能是一对多甚至是多对多的。
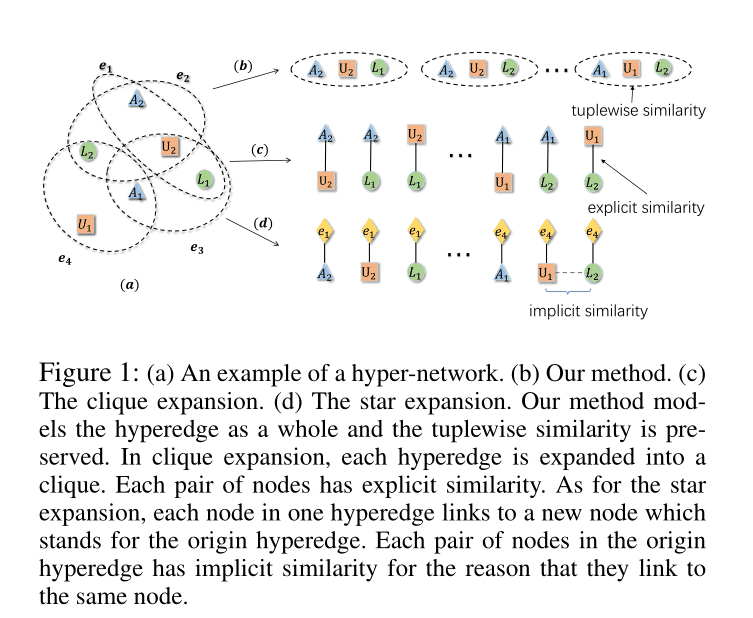
方法
这篇论文的工作思路如下:
提出DHNE模型,以解决超网嵌入的相关问题。
证明嵌入空间的线性相似度度量不能保持超网络的不可分解性。
方法描述

网络的结构如上图,主要有三层结构,第一层主要是自编码器,第二层非线性变换,第三层有监督训练
为了保持超网络的一阶邻近性,需要在嵌入空间中进行N元组相似性度量。如果N个顶点之间存在超边,则这些顶点之间的N元组相似度应较大,否则应较小。
Property 1. X i X_i Xi作为节点 v i v_i vi的嵌入表示, S S S作为N-tuplewise相似性函数。若 ( v 1 , v 2 , … , v n ) ∈ E (v_1,v_2,\dots,v_n)\in E (v1,v2,…,vn)∈E,则 S ( X 1 , X 2 , … , X N ) S(X_1,X_2,\dots,X_N) S(X1,X2,…,XN)应该大于阈值。若 ( v 1 , v 2 , … , v n ) ∉ E (v_1,v_2,\dots,v_n)\notin E (v1,v2,…,vn)∈/E,则 S ( X 1 , X 2 , … , X N ) S(X_1,X_2,\dots,X_N) S(X1,X2,…,XN)应该小于阈值。
这里给出证明线性元组相似函数不能满足性质1的定理。
Theorem 1. 线性函数 S ( X 1 , X 2 , … , X N ) = ∑ i W i X i S(X_1,X_2,\dots,X_N)=\sum_i{W_iX_i} S(X1,X2,…,XN)=∑iWiXi不能满足Property 1.
proof.

上述定理表明N元组相似函数S应该是一个非线性形式。这促使我们用多层感知器对其进行建模。多层感知器由两个部分组成,分别在图2的第二层和第三层中显示。第二层是具有非线性激活函数的全连通层。以3个节点
(
v
i
,
v
j
,
v
k
)
(v_i,v_j,v_k)
(vi,vj,vk)的嵌入
(
X
i
a
,
X
j
b
,
X
k
c
)
(X_i^a,X_j^b,X_k^c)
(Xia,Xjb,Xkc)为输入,将它们连接起来,并将它们非线性地映射到一个共同的潜在空间
L
L
L。它们在潜在空间的联合表示如下所示:
L
i
j
k
=
σ
(
W
a
(
2
)
∗
X
i
a
+
W
b
(
2
)
∗
X
j
b
+
W
c
(
2
)
∗
X
k
c
+
b
(
2
)
)
L_{ijk}=\sigma(W_a^{(2)}*X_i^a+W_b^{(2)}*X_j^b+W_c^{(2)}*X_k^c+b^{(2)})
Lijk=σ(Wa(2)∗Xia+Wb(2)∗Xjb+Wc(2)∗Xkc+b(2))
其中,
σ
\sigma
σ是Sigmoid函数。
在得到潜在表示
L
i
j
k
L_{ijk}
Lijk后,最后将其*映射到第三层的概率空间,以获得相似度:
S
i
j
k
≡
S
(
X
i
a
,
X
j
b
,
X
k
c
)
=
σ
(
W
(
3
)
∗
L
i
j
k
+
b
(
3
)
)
S_{ijk}\equiv S(X_i^a,X_j^b,X_k^c)=\sigma(W^{(3)}*L_{ijk}+b^{(3)})
Sijk≡S(Xia,Xjb,Xkc)=σ(W(3)∗Lijk+b(3))
结合上述提及的两层,我们得到了一个非线性的元组相似性度量函数
S
S
S。为了使这个相似性函数满足Property 1,我们提出了如下的目标函数:
L
1
=
−
(
R
i
j
k
l
o
g
S
i
j
k
+
(
1
−
R
i
j
k
)
l
o
g
(
1
−
S
i
j
k
)
)
L_1=-(R_{ijk}logS_{ijk}+(1-R_{ijk})log(1-S{ijk}))
L1=−(RijklogSijk+(1−Rijk)log(1−Sijk))
其中,当
v
i
,
v
j
,
v
k
v_i,v_j,v_k
vi,vj,vk之间存在超边的时
R
i
j
k
R_{ijk}
Rijk为1,否则为0。根据这个目标函数,很容易判断当
R
i
j
k
R_{ijk}
Rijk为1时,相似度
S
i
j
k
S_{ijk}
Sijk应当更大,否则应该更小。换句话说,保证了一阶相似性。
接下来,我们考虑保留二阶相似性。图2中的第一层用来保证二阶相似性。二阶相似性用来衡量邻居结构的相似度。这里我们定义hyper-network的邻接矩阵来获取邻域的结构。首先我们给出hyper-graph的一些基本定义。对于一个hypergraph
G
=
(
V
,
E
)
G=(V,E)
G=(V,E),定义了一个
∣
V
∣
∗
∣
E
∣
|V|*|E|
∣V∣∗∣E∣的关联矩阵
H
H
H,如果
v
∈
e
v\in e
v∈e,则
h
(
v
,
e
)
=
1
h(v,e)=1
h(v,e)=1,否则为0。对于顶点
v
∈
V
v\in V
v∈V,顶点度定义为
d
(
v
)
=
∑
(
e
∈
E
)
h
(
v
,
e
)
d(v)=\sum_{(e\in E)}h(v,e)
d(v)=∑(e∈E)h(v,e)。设
D
v
D_v
Dv表示包含顶点度的对角矩阵。则hypergraph
G
G
G的邻接矩阵
A
A
A可定义为
A
=
H
H
T
−
D
v
A=HH^T-D_v
A=HHT−Dv,其中
H
T
H^T
HT是
H
H
H的转置。邻接矩阵
A
A
A的每个元素表示两个节点之间的并发次数,邻接矩阵
A
A
A的第
i
i
i行表示顶点
v
i
v_i
vi的邻域结构。我们使用邻接矩阵
A
A
A作为输入特征,并使用自动编码器作为模型来保持邻域结构。自动编码器由编码器和解码器组成。编码器是从特征空间A到潜在表示空间X的非线性映射,解码器是从潜在表示X空间返回到原始特征空间
A
^
\hat{A}
A^的非线性映射,如下所示:
X
i
=
σ
(
W
(
1
)
∗
A
i
+
b
(
1
)
)
X_i=\sigma(W^{(1)}*A_{i}+b^{(1)})
Xi=σ(W(1)∗Ai+b(1))
A ^ i = σ ( W ^ ( 1 ) ∗ X i + b ^ ( 1 ) ) \hat{A}_i=\sigma(\hat{W}^{(1)}*X_i+\hat{b}^{(1)}) A^i=σ(W^(1)∗Xi+b^(1))
自动编码器的目标是最小化输入和输出之间的重建误差。自动编码器的重构过程将使具有相似邻域的节点具有相似的潜在表示,从而保持二阶邻接关系。值得注意的是,输入特征是超网络的邻接矩阵,而邻接矩阵往往是极其稀疏的。为了提高模型的速度,我们只重构邻接矩阵中的非零元素。重构误差如下所示:
∣
∣
s
i
g
n
(
A
i
)
⊙
(
A
i
−
A
i
^
)
∣
∣
F
2
||sign(A_i)\odot (A_i-\hat{A_i})||^2_F
∣∣sign(Ai)⊙(Ai−Ai^)∣∣F2
其中,sign是sign函数。
此外,在超网络中,顶点的类型往往多种多样,形成了异质的超网络。考虑到不同类型节点的特殊性,需要为不同类型的节点学习唯一的潜在空间。在我们的模型中,每种不同类型的实体都有自己的自动编码器模型,如图2所示。然后,对于所有类型的节点,损失函数定义为:
L
2
=
∑
t
∣
∣
s
i
g
n
(
A
i
t
)
⊙
(
A
i
t
−
A
^
i
t
)
∣
∣
F
2
L_2=\sum_{t}||sign(A^t_i)\odot(A^t_i-\hat{A}^t_i)||^2_F
L2=t∑∣∣sign(Ait)⊙(Ait−A^it)∣∣F2
其中
t
t
t是节点类型的索引。
为了同时保持异质超网络的一阶邻近性和二阶邻近性,我们通过组合方程7和方程11来联合最小化目标函数:
L
=
L
1
+
α
L
2
L=L_1+\alpha L_2
L=L1+αL2
实验
实验设置
数据集
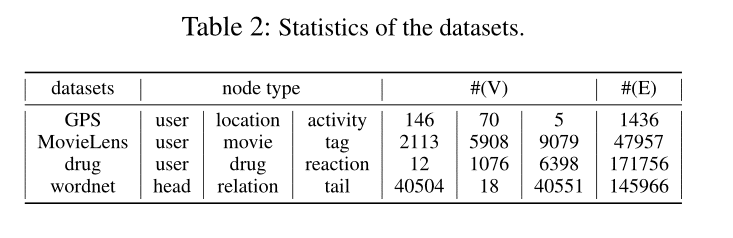
文章使用了四种不同类型的数据集,包括GPS网络、社会网络、医学网络和语义网络。详细信息如下所示。
∙ \bullet ∙ GPS:数据集描述了用户在特定位置加入某个活动。(用户、位置、活动)关系用于构建超网络。
∙ \bullet ∙ MovieLens:此数据集描述来自MovieLens的个人标记活动。每部电影都至少有一种类型的标签。将(用户、电影、标签)关系视为超边,形成一个超网络。
∙ \bull ∙ drug:该数据集来自FDA不良事件报告系统(FAERS)。它包含有关提交给FDA的不良事件和用药错误报告的信息。我们通过(使用者、药物、反应)关系来构建超网络,即使用者发生了一定的反应并服用了某些药物就会导致不良事件。
∙ \bull ∙ wordnet:该数据集由从WordNet 3.0提取的三元组(同义词集、关系类型、同义词集)的集合组成。我们可以将头实体、关系实体、尾实体作为三类节点,将三元组关系作为超边来构建超网络。
对比试验
DeepWalk,LINE、node2vec、Spectral Hypergraph Embedding(SHE)、Tensor decomposition 和HyperEdge Based Embedding (HEBE)
DeepWalk、Line和node2vec是传统的两两网络嵌入方法。Tensor decomposition是一种在异质超网络中保持高阶关系的直接方法。Hebe学习针对异类事件数据的节点嵌入。其中,DeepWalk、Line、node2vec和她只能衡量成对关系。
参数设置
对于DeepWalk和node2vec,窗口大小为10,步长为40,每顶点行走为10。对于Line,负采样数为5。
统一地将所有方法的表示大小设置为64。
自动编码器的隐藏层大小设置为64,也是表示大小。全连接层的大小被设置为来自所有类型的嵌入长度的总和192。文章从{0.01,0.1,1,2,5,10}进行网格搜索,以调整参数α。
实验结果及分析
Link Prediction
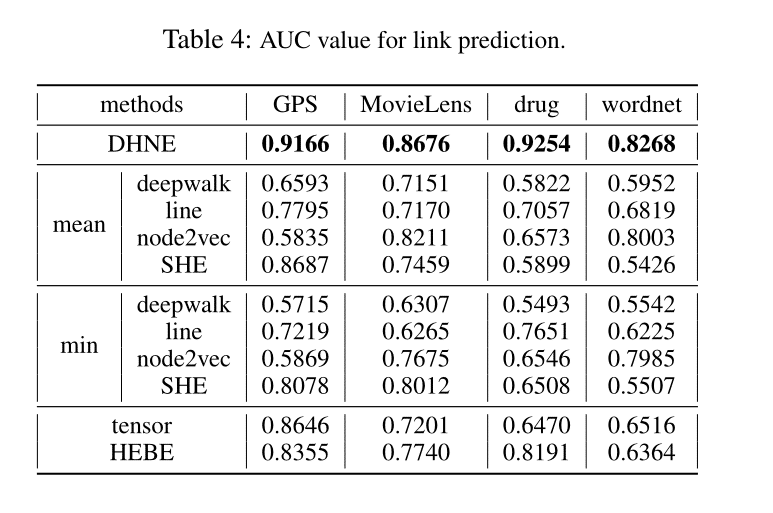
通过比较LINE、DeepWalk、SHE和DHNE的性能,可以观察到,将高阶关系转换为多个两两关系会损害学习嵌入的预测能力。由于张量和Hebe可以在一定程度上解决高阶关系,因此该方法相对于这两种方法的巨大改进幅度清楚地表明了二阶邻近性在超网络嵌入中的重要性。
Classification
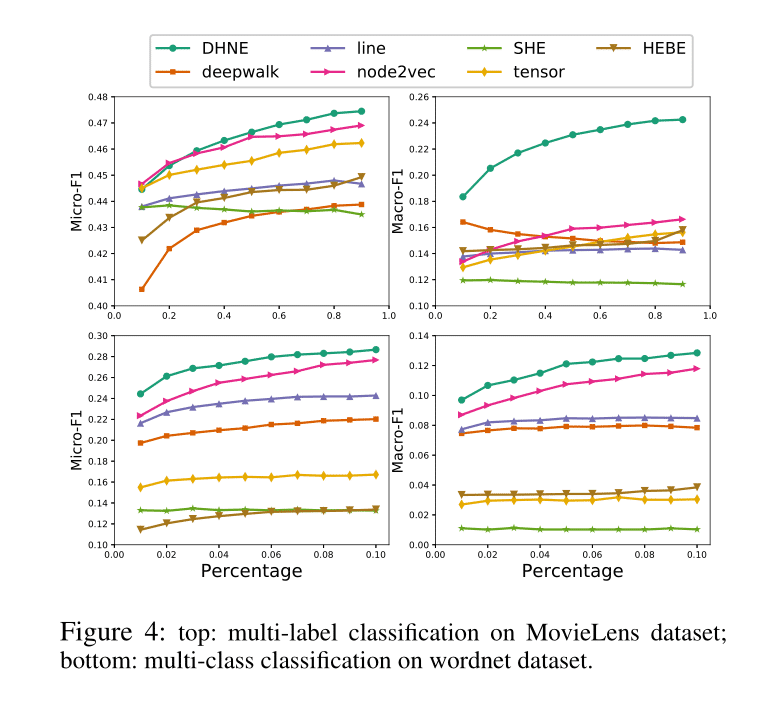
从结果来看,我们有以下几点观察:
∙ \bull ∙ 在Micro-F1和Macro-F1曲线上,该方法都比基线表现得更好。实验结果证明了该方法在分类任务中的有效性。
∙ \bull ∙ 当标注的数据变得更丰富时,该方法的相对改进比基线更明显。此外,如上图底部所示,当标记的数据相当稀疏时,该方法仍然优于基线。这证明了我们方法的健壮性。
相关知识链接
下载
电影数据集[https://movielens.org/]
药物数据集[http://www.fda.gov/Drugs/]
基础知识
基准实验涉及的论文
Line: Large-scale information network embedding. 【https://dl.acm.org/doi/abs/10.1145/2736277.2741093】
Deepwalk: Online learning of social representations.【http://hanj.cs.illinois.edu/cs512/survey_slides/2-15-wang.pdf】
node2vec: Scalable feature learning for networks.【https://dl.acm.org/doi/abs/10.1145/2939672.2939754】
Learning with hypergraphs: Clustering, classification, and embedding. 【https://proceedings.neurips.cc/paper/2006/file/dff8e9c2ac33381546d96deea9922999-Paper.pdf】
Structural deep network embedding.【https://dl.acm.org/doi/abs/10.1145/2939672.2939753】
方法组件涉及的论文
相关工作涉及的论文
后续研究涉及的论文
总结
[亮点]
利用超边来学习超网的低维表示,提出一阶二阶相似性,对大图时间复杂度较为友好。
从理论上证明了现有方法中常用的嵌入空间中的任何线性相似度量都不能保持超网络中的不可分解性质,从而提出了一种新的深度模型来实现非线性元组相似函数,同时保持形成的嵌入空间中的局部和全局邻近性。
[不足]
在超边内部,单一的认为相似度为1,有改进空间。
[启发]
采用超边处理知识图谱有一定的理论根据。
BibTex
@article{tu2017structural,
title={Structural Deep Embedding for Hyper-Networks},
author={Tu, Ke and Cui, Peng and Wang, Xiao and Wang, Fei and Zhu, Wenwu},
journal={arXiv preprint arXiv:1711.10146},
year={2017}
}















 3084
3084











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









