









 本文详细介绍了SE注意力模块的原理,它作为通道注意力模块,常用于CV模型中提升精度。SE模块包括压缩和激励两部分,通过全局平均池化和全连接层学习通道注意力。此外,提供了基于PyTorch的代码实现,并列举了在模型中的多种应用方式,如在主干网络和多尺度特征分支中使用。
本文详细介绍了SE注意力模块的原理,它作为通道注意力模块,常用于CV模型中提升精度。SE模块包括压缩和激励两部分,通过全局平均池化和全连接层学习通道注意力。此外,提供了基于PyTorch的代码实现,并列举了在模型中的多种应用方式,如在主干网络和多尺度特征分支中使用。
前言
本文介绍SE注意力模块,它是在SENet中提出的,SENet是ImageNet 2017的冠军模型;SE模块常常被用于CV模型中,能较有效提取模型精度,所以给大家介绍一下它的原理,设计思路,代码实现,如何应用在模型中。
一、SE 注意力模块
SE 注意力模块,它是一种通道注意力模块;常常被应用与视觉模型中。即插即用,是指通过它能对输入特征图进行通道特征加强,而且最终SE模块输出,不改变输入特征图的大小。
- 首先解释一下SE的含义,S是指Squeeze,压缩的意思;把输入特征图中的空间信息进行压缩。
- E是指Excitation,激励的意思;学习到的通道注意力信息,与输入特征图进行结合,最终得到具有通道注意力的特征图。
下面分析一下,SE是如何实现通道注意力的;首先看一下,模块的结构:
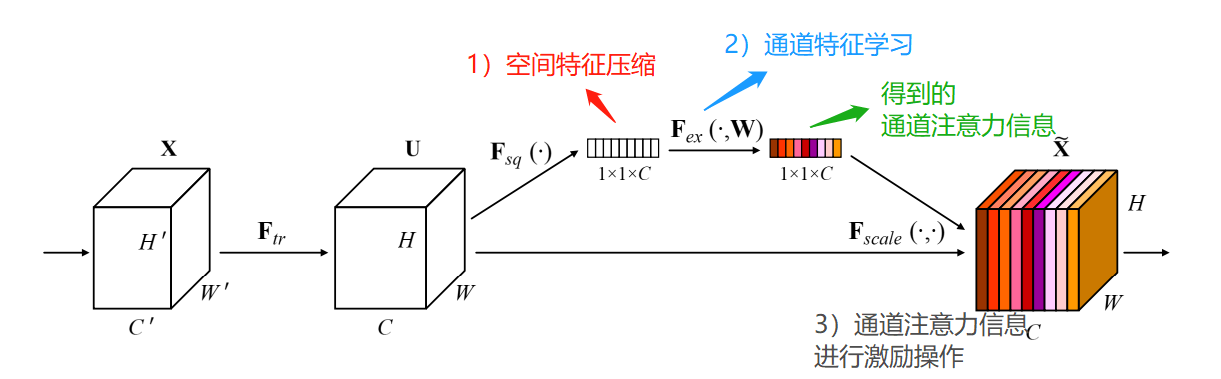
它主要由两部分组成,压缩、激励;模型的流程思路如下:
- 首先输入特征图,它的维度是H*W*C;
- 对输入特征图进行空间特征压缩;实现:在空间维度,实现全局平均池化,得到1*1*C的特征图;
- 对压缩后的特征图,进行通道特征学习;实现:通过FC全连接层操作学习,得到具有通道注意力的特征图,它的维度还是1*1*C;
- 最后将通道注意力的特征图1*1*C、原始输入特征图H*W*C,进行逐通道乘以权重系数,最终输出具有通道注意力的特征图;
其中,在FC全连接层学习通道注意力信息中,是对每个通道的重要性进行预测,得到不同channel的重要性大小后再作用。
备注: SE模块的出处论文:https://arxiv.org/abs/1709.01507?utm_source=ld246.com
注意力机制的实现思路:
- 通常,对特征图进行通道注意力操作,首先对特征图的空间维度进行压缩,然后学习不同通道的重要性;
- 对特征图进行空间注意力操作,首先对特征图的通道维度进行压缩,然后学习不同空间部位的重要性;
二、代码实现
实现SE模块的代码前,首先看一下,它是的流程结构,这里以resnet为基础实现的:
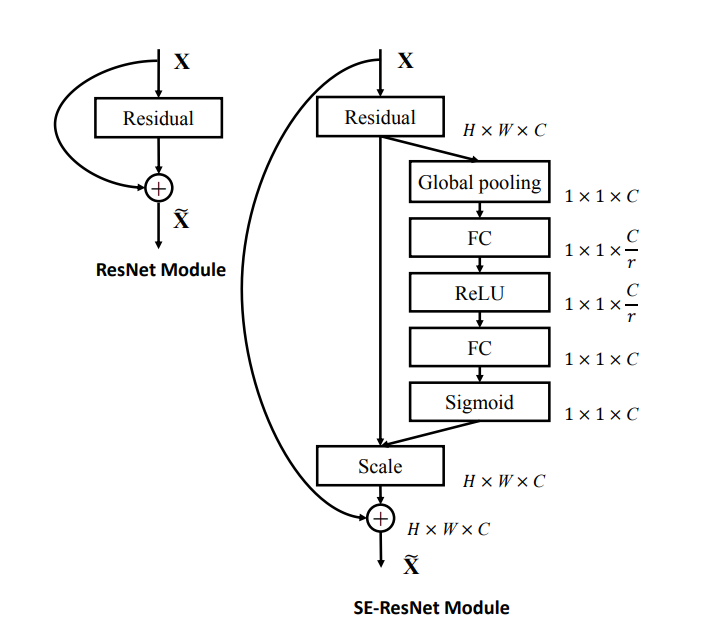
基于pytorch版本的代码如下:
class se_block(nn.Module):
def __init__(self,channels,ratio=16):
super(SE, self).__init__()
# 空间信息进行压缩
self.avgpool=nn.AdaptiveAvgPool2d(1)
# 经过两次全连接层,学习不同通道的重要性
self.fc=nn.Sequential(
nn.Linear(channels,channels//ratio,False),
nn.ReLU(),
nn.Linear(channels//ratio, channels, False),
nn.Sigmoid()
)
def forward(self,x):
b,c,_,_ = x.size() #取出batch size和通道数
# b,c,w,h->b,c,1,1->b,c 压缩与通道信息学习
avg = self.avgpool(x).view(b,c)
#b,c->b,c->b,c,1,1 激励操作
y = self.fc(avg).view(b,c,1,1)
return x * y.expand_as(x)三、SE应用在模型中
SE模块常常被用于CV模型中,能较有效提取模型精度;它是即插即用,是指通过它能对输入特征图进行通道特征加强,而且最终SE模块输出,不改变输入特征图的大小。
应用示例1:
在主干网络(Backbone)中,加入SE模块,加强通道特征,提高模型性能;
应用示例2:
在主干网络(Backbone)末尾,加入SE模型,加强整体的通道特征,提高模型性能;
应用实例3:
在多尺度特征分支中,加入SE模块,加强加强通道特征,提高模型性能。
总体评价:通常,SE模块能提升模型的精度;但速度会下降一点,毕竟它有FC全连接层。
本文只供大家参考与学习,谢谢~
后面还会介绍其它注意力模型:SK-Nets、CBAM、DANet、ECA-Net、CA等注意力模块。


















 7292
7292

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











