






一、State Value
State values:the mean of all possible returns that can be obtained starting from a state.





二、Bellman Equation【贝尔曼公式】
贝尔曼公式/Bellman Equation:
- 描述了不同状态的stat value之间的关系;
- 用于计算State Value【v_π(s)】,利用v_π(s)来评价一个策略/Policy的优劣



1、推导Bellman Equation【贝尔曼公式】




注意事项:
- 贝尔曼公式不是一个,而是一系列的公式。状态空间S中的每一个s都有一个这种对应的公式。如果S中有n个s,则有n个这种公式,通过这n个公式联合求解就可以解出每一个s的state value,即v_π(s);
- 贝尔曼公式描述了不同状态的state value之间的关系,即:v_π(s)与v_π(s')之间的关系;

2、举例
2.1 例一




2.2、例2


3、Bellman Equation/贝尔曼公式的矩阵与向量形式



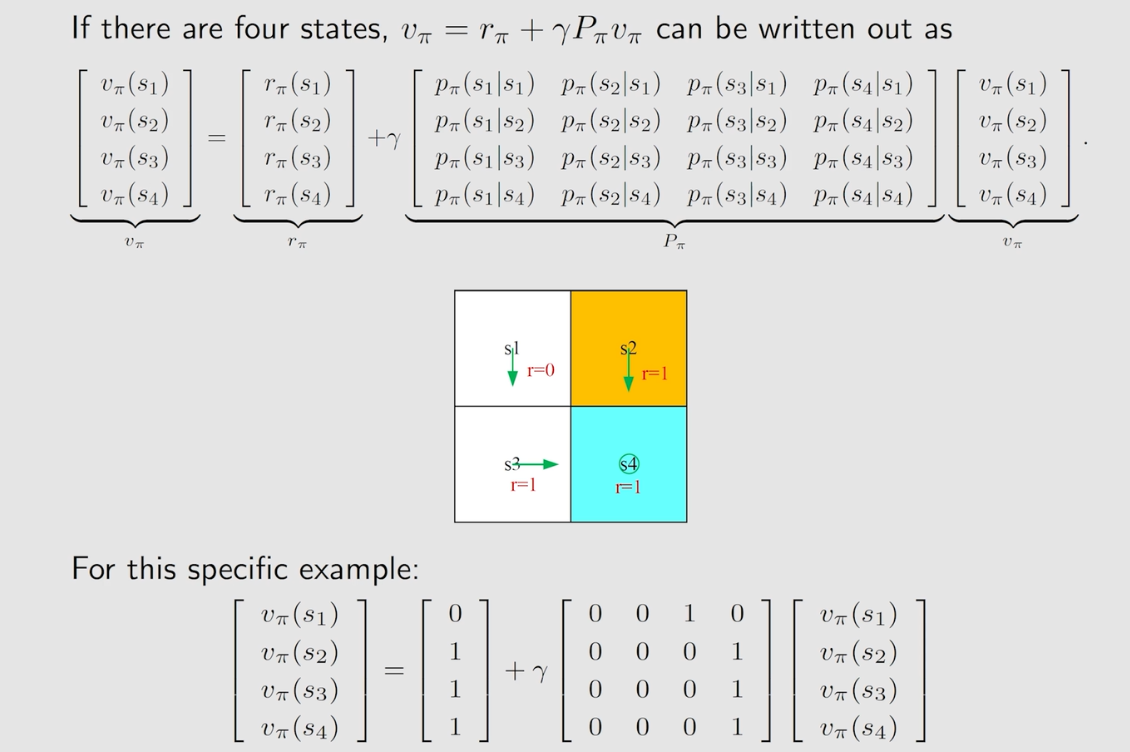
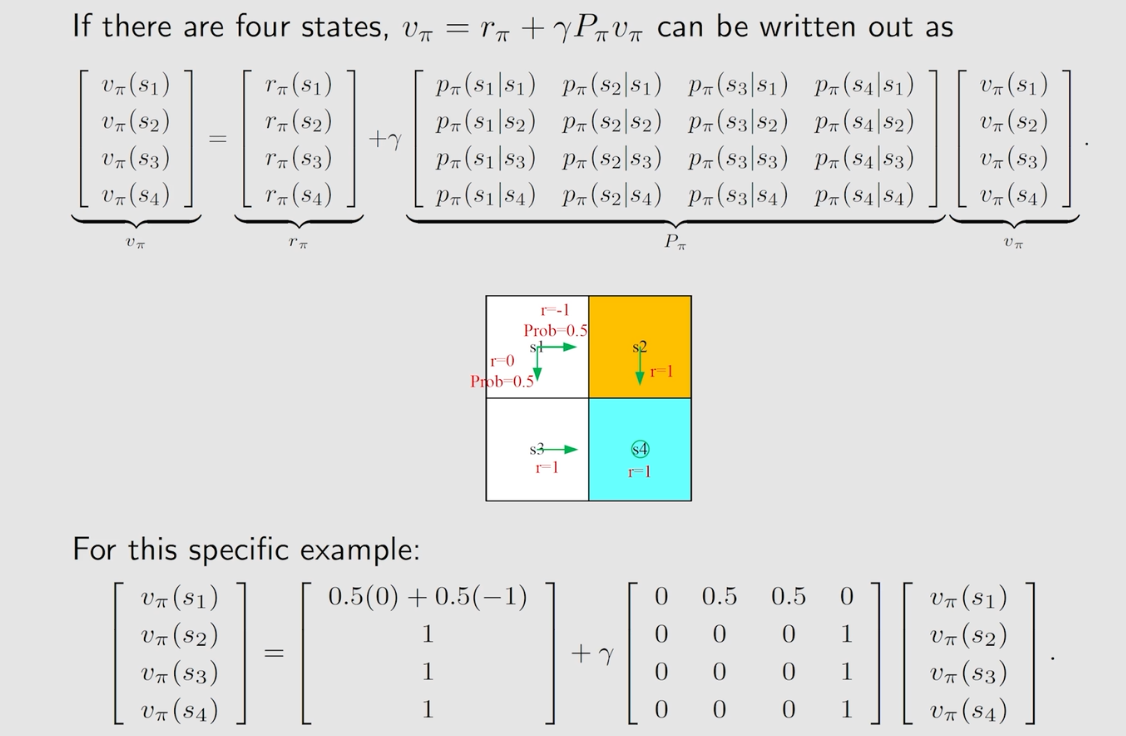
4、Bellman Equation/贝尔曼公式计算state values【v_π(s)】

policy evaluation:给定一个policy,列出该policy的贝尔曼公式,根据贝尔曼公式求解得出state values。
- 通过评价一个policy的优劣,才能去优化policy;

当k趋向于无穷大时,v_k收敛到v_π。v_π就是真实的state value。证明如下:

4.1、例1【比较好的策略(policy)】

靠近target的state的state value都比较大。
离target越远的state的state value越小。
4.1、例2【比较差的策略(Policy)】

三、Action Value
Action Value:用于比较在某一个state所采取的各个action的优劣。



Action value案例

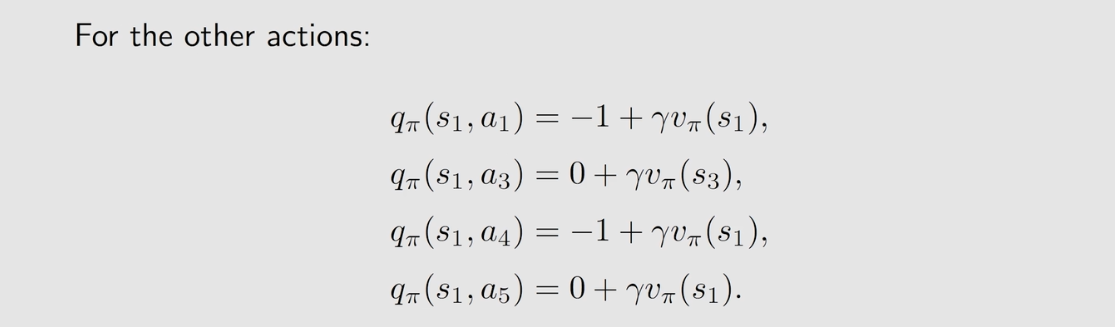
















 580
580











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









