






YOLOV11目标检测注意力机制改进实例与创新改进专栏
目录
论文地址:[1807.06521] CBAM: Convolutional Block Attention Modulehttps://arxiv.org/abs/1807.06521
1.完整代码获取
此专栏提供完整的改进后的YOLOv11项目文件,你也可以直接下载到本地,然后打开项目,修改数据集配置文件以及合适的网络yaml文件即可运行,操作很简单!订阅专栏的小伙伴可以私信博主,或者直接联系博主,加入yolov11改进交流群;
+Qq:1921873112
2.CBAM注意力机制介绍
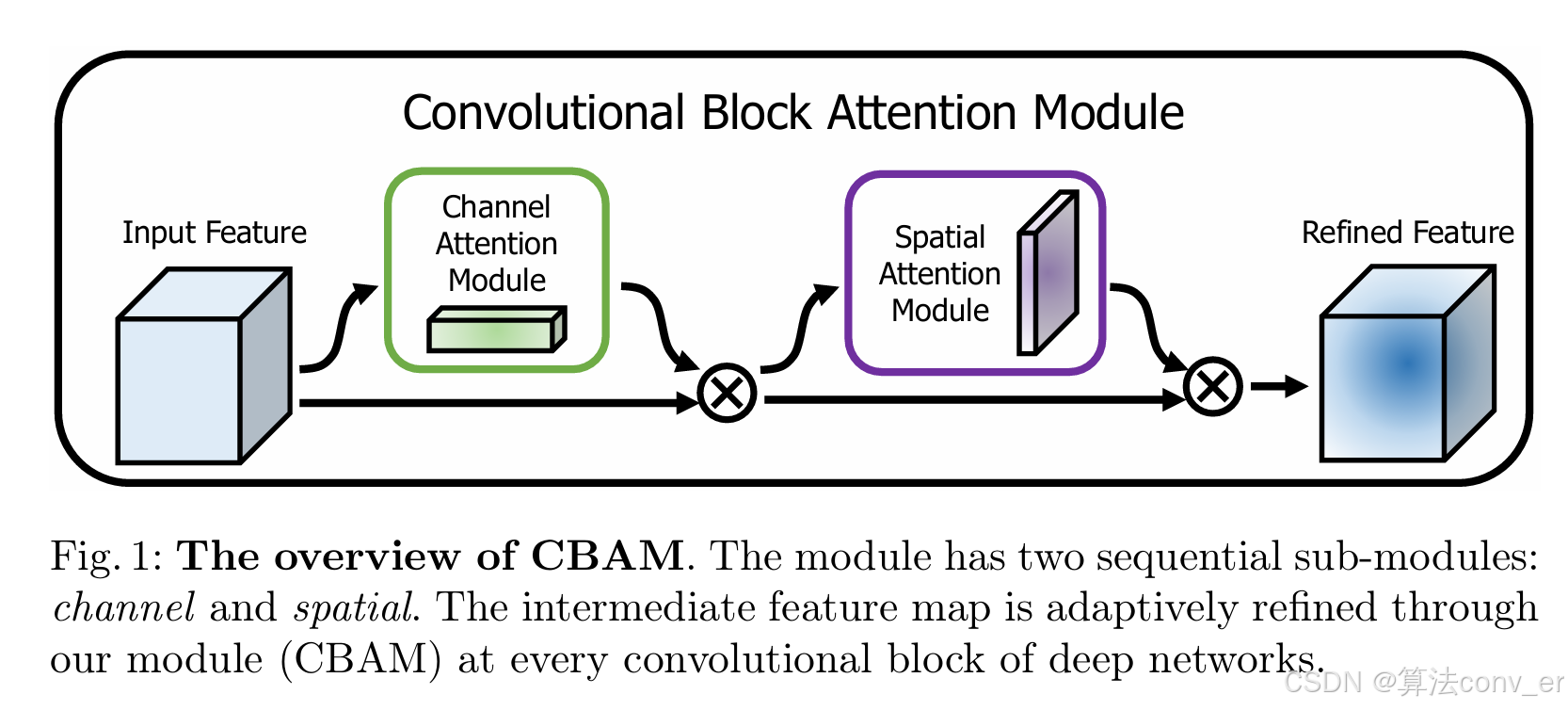
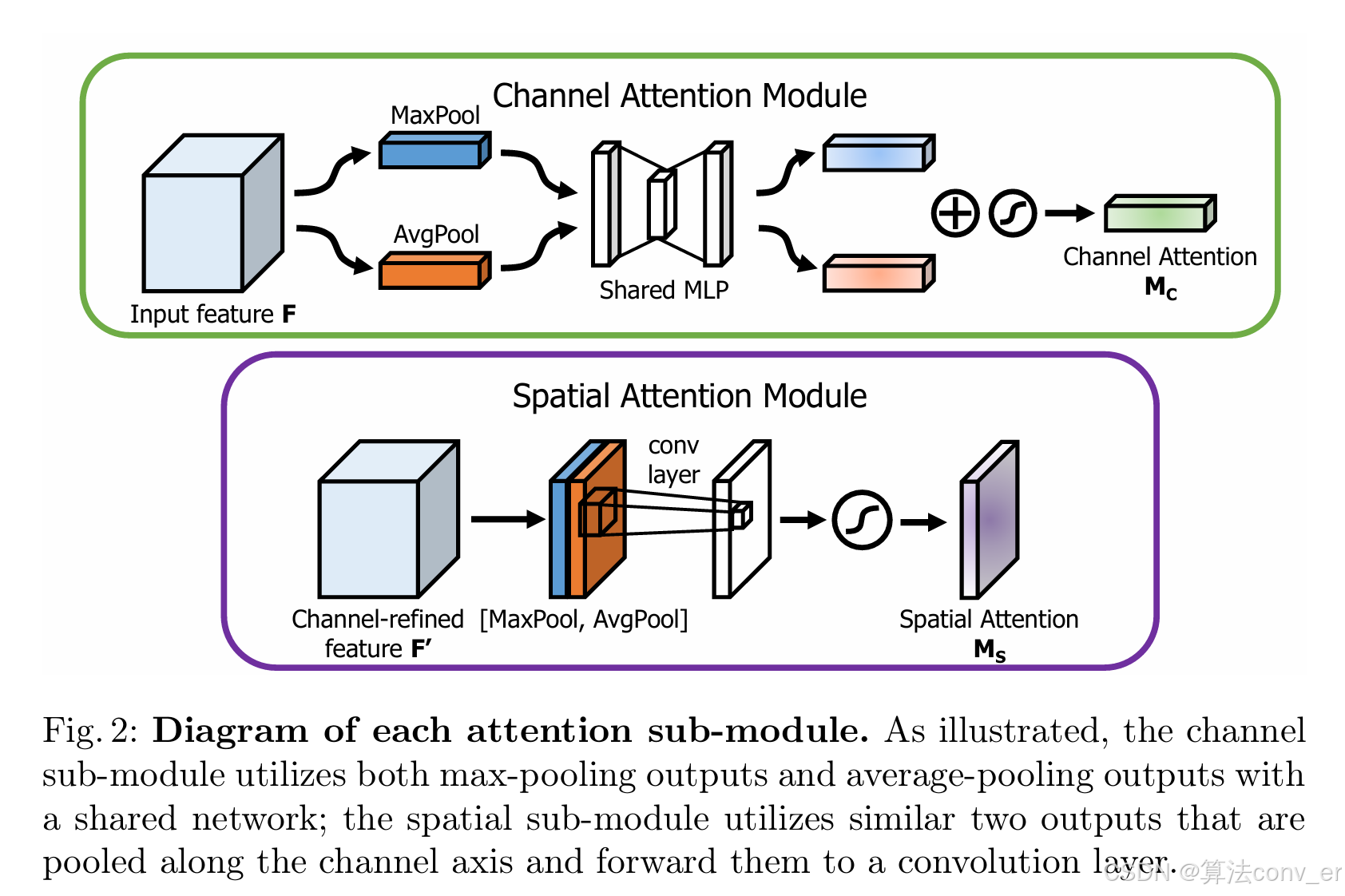
CBAM(Convolutional Block Attention Module)注意力机制是一种用于深度学习中的有效注意力模块。它主要包含通道注意力模块和空间注意力模块两个部分。在通道注意力模块中,通过对输入特征图的通道维度进行操作,利用最大池化和平均池化来聚合特征信息,再经过多层感知机处理,得到通道注意力权重,用于突出重要的通道特征。而空间注意力模块则是在通道注意力的基础上,对空间维度进行处理,通过对特征图在空间维度上进行池化操作,生成空间注意力权重,以此来强调空间位置上更关键的区域。CBAM 能够自适应地对通道和空间信息进行筛选和增强,帮助网络更聚焦于有价值的特征部分,有效提升模型的性能,被广泛应用于图像分类、目标检测、语义分割等众多计算机视觉任务中。
3. CBAM具有优势:
- 增强特征表示能力:
- 通道注意力方面:通过对输入特征图的通道维度进行操作,能够自动学习到不同通道的重要性权重。将每个通道视为一种对图片的特征提取器,例如有的通道可能提取到了物体的纹理特征,有的通道提取到了物体的颜色特征等。CBAM 的通道注意力模块可以突出那些对当前任务更关键的通道特征,抑制不太重要的通道,从而使模型更关注具有代表性的特征信息,增强特征的表达能力。
- 空间注意力方面:考虑了特征图的空间维度信息,能够聚焦于图像中不同区域的重要性差异。它可以帮助模型识别出图像中哪些区域是关键的,哪些区域是背景或不太重要的部分,从而对关键区域给予更多的关注,进一步提高模型对空间信息的利用效率,增强模型对图像内容的理解和识别能力。
- 即插即用的灵活性:CBAM 是一种即插即用的模块,可以很方便地嵌入到各种现有的卷积神经网络架构中。无论是经典的网络如 VGGNet、ResNet,还是一些新型的网络结构,都可以轻松地将 CBAM 与原网络进行结合,不需要对原有的网络结构进行大规模的改动。这种灵活性使得 CBAM 可以广泛应用于不同的深度学习任务和模型中,帮助提升各种模型的性能。
- 计算高效性:CBAM 在引入注意力机制的同时,并没有大幅增加模型的计算量和参数数量。它主要通过一些简单的池化操作(如最大池化和平均池化)、卷积操作以及多层感知机等相对简单的计算来获取注意力权重,这些操作的计算成本相对较低。与一些复杂的注意力机制相比,CBAM 在保证性能提升的同时,不会给模型带来过大的计算负担,有利于模型的训练和部署,特别是在资源受限的环境下具有很大的优势。
- 提升模型的可解释性:注意力机制本身具有一定的可解释性,CBAM 通过明确地学习通道和空间的注意力权重,能够让人们更直观地理解模型在处理图像时关注的重点区域和特征。这对于分析模型的决策过程、调试模型以及发现模型的潜在问题都具有重要的意义,有助于提高模型的可靠性和可信度。
- 综合性能优势:在实际的实验和应用中,CBAM 已经被证明能够有效地提升模型的性能,无论是在图像分类、目标检测还是语义分割等任务中,都能取得较好的效果。它可以帮助模型更好地应对复杂的视觉任务,提高模型的准确性和鲁棒性。
4. CBAM网络结构图
5. yolov11-CBAM yaml文件
nc: 80 # number of classes
scales: # model compound scaling constants, i.e. 'model=yolo11n.yaml' will call yolo11.yaml with scale 'n'
# [depth, width, max_channels]
n: [0.50, 0.25, 1024] # summary: 319 layers, 2624080 parameters, 2624064 gradients, 6.6 GFLOPs
s: [0.50, 0.50, 1024] # summary: 319 layers, 9458752 parameters, 9458736 gradients, 21.7 GFLOPs
m: [0.50, 1.00, 512] # summary: 409 layers, 20114688 parameters, 20114672 gradients, 68.5 GFLOPs
l: [1.00, 1.00, 512] # summary: 631 layers, 25372160 parameters, 25372144 gradients, 87.6 GFLOPs
x: [1.00, 1.50, 512] # summary: 631 layers, 56966176 parameters, 56966160 gradients, 196.0 GFLOPs
# YOLO11n backbone
backbone:
# [from, repeats, module, args]
- [-1, 1, Conv, [64, 3, 2]] # 0-P1/2
- [-1, 1, Conv, [128, 3, 2]] # 1-P2/4
- [-1, 2, C3k2, [256, False, 0.25]]
- [-1, 1, Conv, [256, 3, 2]] # 3-P3/8
- [-1, 2, C3k2, [512, False, 0.25]]
- [-1, 1, Conv, [512, 3, 2]] # 5-P4/16
- [-1, 2, C3k2, [512, True]]
- [-1, 1, Conv, [1024, 3, 2]] # 7-P5/32
- [-1, 2, C3k2, [1024, True]]
- [-1, 1, CBAM, [1024]] # 9
- [-1, 1, SPPF, [1024, 5]] # 10
- [-1, 2, C2PSA, [1024]] # 11
# YOLO11n head
head:
- [-1, 1, nn.Upsample, [None, 2, "nearest"]]
- [[-1, 6], 1, Concat, [1]] # cat backbone P4
- [-1, 2, C3k2, [512, False]] # 13
- [-1, 1, nn.Upsample, [None, 2, "nearest"]]
- [[-1, 4], 1, Concat, [1]] # cat backbone P3
- [-1, 2, C3k2, [256, False]] # 16 (P3/8-small)
- [-1, 1, Conv, [256, 3, 2]]
- [[-1, 13], 1, Concat, [1]] # cat head P4
- [-1, 2, C3k2, [512, False]] # 19 (P4/16-medium)
- [-1, 1, Conv, [512, 3, 2]]
- [[-1, 10], 1, Concat, [1]] # cat head P5
- [-1, 2, C3k2, [1024, True]] # 22 (P5/32-large)
- [[17, 20, 23], 1, Detect, [nc]] # Detect(P3, P4, P5)
6.CBAM注意力机制代码实现
import numpy as np
import torch
from torch import nn
from torch.nn import init
class ChannelAttentionModule(nn.Module):
def __init__(self, c1, reduction=16):
super(ChannelAttentionModule, self).__init__()
mid_channel = c1 // reduction
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.max_pool = nn.AdaptiveMaxPool2d(1)
self.shared_MLP = nn.Sequential(
nn.Linear(in_features=c1, out_features=mid_channel),
nn.LeakyReLU(0.1, inplace=True),
nn.Linear(in_features=mid_channel, out_features=c1)
)
self.act = nn.Sigmoid()
#self.act=nn.SiLU()
def forward(self, x):
avgout = self.shared_MLP(self.avg_pool(x).view(x.size(0),-1)).unsqueeze(2).unsqueeze(3)
maxout = self.shared_MLP(self.max_pool(x).view(x.size(0),-1)).unsqueeze(2).unsqueeze(3)
return self.act(avgout + maxout)
class SpatialAttentionModule(nn.Module):
def __init__(self):
super(SpatialAttentionModule, self).__init__()
self.conv2d = nn.Conv2d(in_channels=2, out_channels=1, kernel_size=7, stride=1, padding=3)
self.act = nn.Sigmoid()
def forward(self, x):
avgout = torch.mean(x, dim=1, keepdim=True)
maxout, _ = torch.max(x, dim=1, keepdim=True)
out = torch.cat([avgout, maxout], dim=1)
out = self.act(self.conv2d(out))
return out
class CBAM(nn.Module):
def __init__(self, c1,c2):
super(CBAM, self).__init__()
self.channel_attention = ChannelAttentionModule(c1)
self.spatial_attention = SpatialAttentionModule()
def forward(self, x):
out = self.channel_attention(x) * x
out = self.spatial_attention(out) * out
return out7.CBAM注意力机制添加方式
参照我的这篇博客:【YOLO11改进- 注意力机制】YOLO11+SA: 基于YOLOv11的深度卷积注意力机制,提取深层语义信息,高效涨点;-CSDN博客
8.训练成功展示
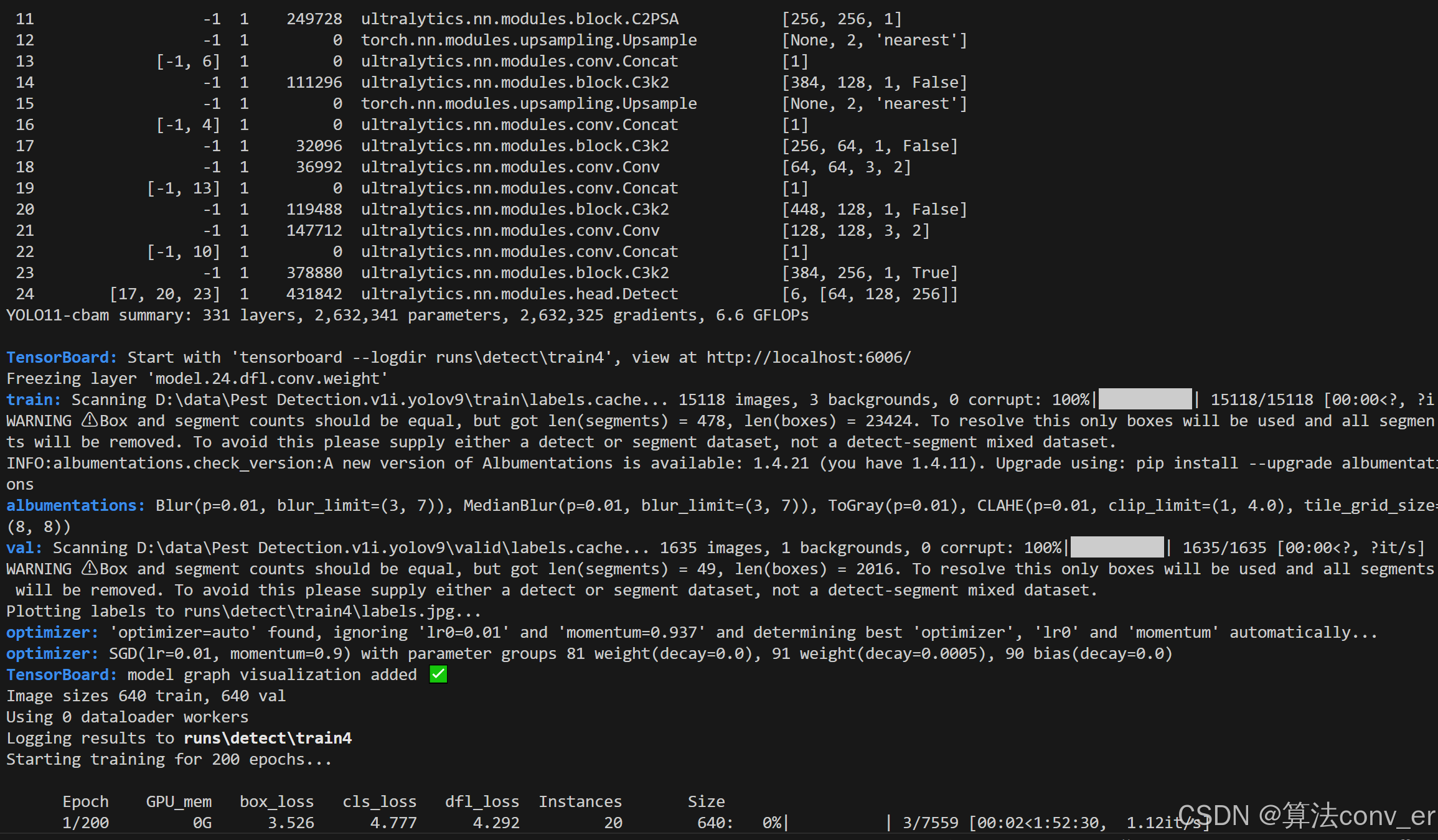
此篇博客到这里就告一段落了,后续我还会继续更新很多改进,大家感兴趣的可以关注我的专栏加入 Qq交流群。

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









