







 超级会员免费看
超级会员免费看
 本文详细介绍了Lift, Splat, Shoot(LSS)方法,一种用于自动驾驶的图像到BEV表示的端到端架构。LSS通过将多摄像头图像提升到点云空间,然后映射到BEV表示,实现了多帧信息融合。模型分为Lift(隐式深度分布)、Splat(pillar池化)和Shoot(运动规划)三个步骤。LSS在训练中无需激光雷达监督,具有良好的泛化性和对相机配置的适应性。"
131495636,5278991,SQL解析器开发:从AST到执行计划,"['数据库', 'SQL', '查询处理器', '编译原理', '数据处理']
本文详细介绍了Lift, Splat, Shoot(LSS)方法,一种用于自动驾驶的图像到BEV表示的端到端架构。LSS通过将多摄像头图像提升到点云空间,然后映射到BEV表示,实现了多帧信息融合。模型分为Lift(隐式深度分布)、Splat(pillar池化)和Shoot(运动规划)三个步骤。LSS在训练中无需激光雷达监督,具有良好的泛化性和对相机配置的适应性。"
131495636,5278991,SQL解析器开发:从AST到执行计划,"['数据库', 'SQL', '查询处理器', '编译原理', '数据处理']

由于本人才疏学浅,解析中难免会出现不足之处,欢迎指正、讨论,有好的建议或意见都可以在评论区留言。谢谢大家!
专栏地址:https://blog.csdn.net/qq_41366026/category_11640689.html?spm=1001.2014.3001.5482
1 前言
计算机视觉算法通常使用图像是作为输入并输出预测的结果,但是对结果所在的坐标系却并不关心,例如图像分类、图像分割、图像检测等任务中,输出的结果均在原始的图像坐标系中。因此这种范式不能很好的与自动驾驶契合。
在自动驾驶中,多个相机传感器的数据一起作为输入,这样每帧图像均在自己的坐标系中;但是感知算法最终需要在车辆自身坐标系(ego coordinate)中输出最终的预测结果;并提供给下游的规划任务。
当前也有很多简单、使用的方法用于扩展单帧图像到多视角图像的方法。简单实用的有来自所有相机的每一帧图像均进行目标检测,然后可以根据各相机的内参与外参对检测的结果进行旋转和平移至ego坐标系中。这一种单帧扩展到多视角的的方法有如下3个重要的对称性质:
1 平移对称性(Translation equivariance):在图像坐标系中所有的像素偏移会导致输出的结果同样带有此偏移。
2 排列不变性(Permutation invariance):算法结果不会因为不同相机输入帧的排列组合不同导致输出结果不一致。
3 ego坐标系的等距性(Ego-frame isometry equivariance):物理世界是三维世界,因此ego在物理世界中,遵循T∈SE3变换;即ego-frame被旋转平移输出也会进行相同的旋转与平移。
上述简单方法的缺点是使用后处理来自单图像检测器的检测,使得网络不能直接在ego坐标系使用预测结果回传到输入来进行优化;导致模型不能很好的融合来自多相机的数据;同时也不能根据下游的规划任务的反馈来优化整个感知算法,因为数据不连贯致使反向传播算法难以应用。
综上所述,本文作者提出了编码来自个相机的图像帧并隐式映射回3D进行感知的方法。
2 Lift, Splat, Shoot(LSS)overview
Lift, Splat, Shoot: Encoding Images from Arbitrary Camera Rigs by Implicitly Unprojecting to 3D
https://arxiv.org/abs/2008.05711
官方开源代码:
本文提出了一个端到端的架构,对于任意数量不同相机帧的图像直接提取场景的BEV表达;主要由如下三部分实现网络的主要内容:
1、Lift:将每一个相机的图像帧根据相机的内参转换提升到frustum(锥形)形状的点云空间中。
2 splate:将所有相机转换到锥形点云空间中的特征根据相机的内参K与相机相对于ego的外参T映射到栅格化的3D空间(BEV)中来融合多帧信息。
3 shoot:根据上述BEV的检测或分割结果来生成规划的路径proposal;从而实现可解释的端到端的路径规划任务。
注:LSS在训练的过程中并不需要激光雷达的点云来进行监督。
3 LSS的demo推理
3.1 LSS环境搭建
# 基础环境搭建
conda create -n bev python=3.7
conda activate bev
pip install torch==1.9.0+cu111 torchvision==0.10.0+cu111 torchaudio==0.9.0 -f https://download.pytorch.org/whl/torch_stable.html
# LSS依赖库安装
pip install nuscenes-devkit tensorboardX efficientnet_pytorch==0.7.0
# 下载项目源码
git clone https://github.com/nv-tlabs/lift-splat-shoot.git
cd lift-splat-shoot
# 下载图像backbone模型文件
wget https://github.com/lukemelas/EfficientNet-PyTorch/releases/download/1.0/efficientnet-b0-355c32eb.pth
# 自行在官方github的repo上下载LSS网络模型文件
https://drive.google.com/file/d/18fy-6beTFTZx5SrYLs9Xk7cY-fGSm7kw/view?usp=sharing3.2 数据集下载与推理
下载nuscenes数据集https://www.nuscenes.org/download
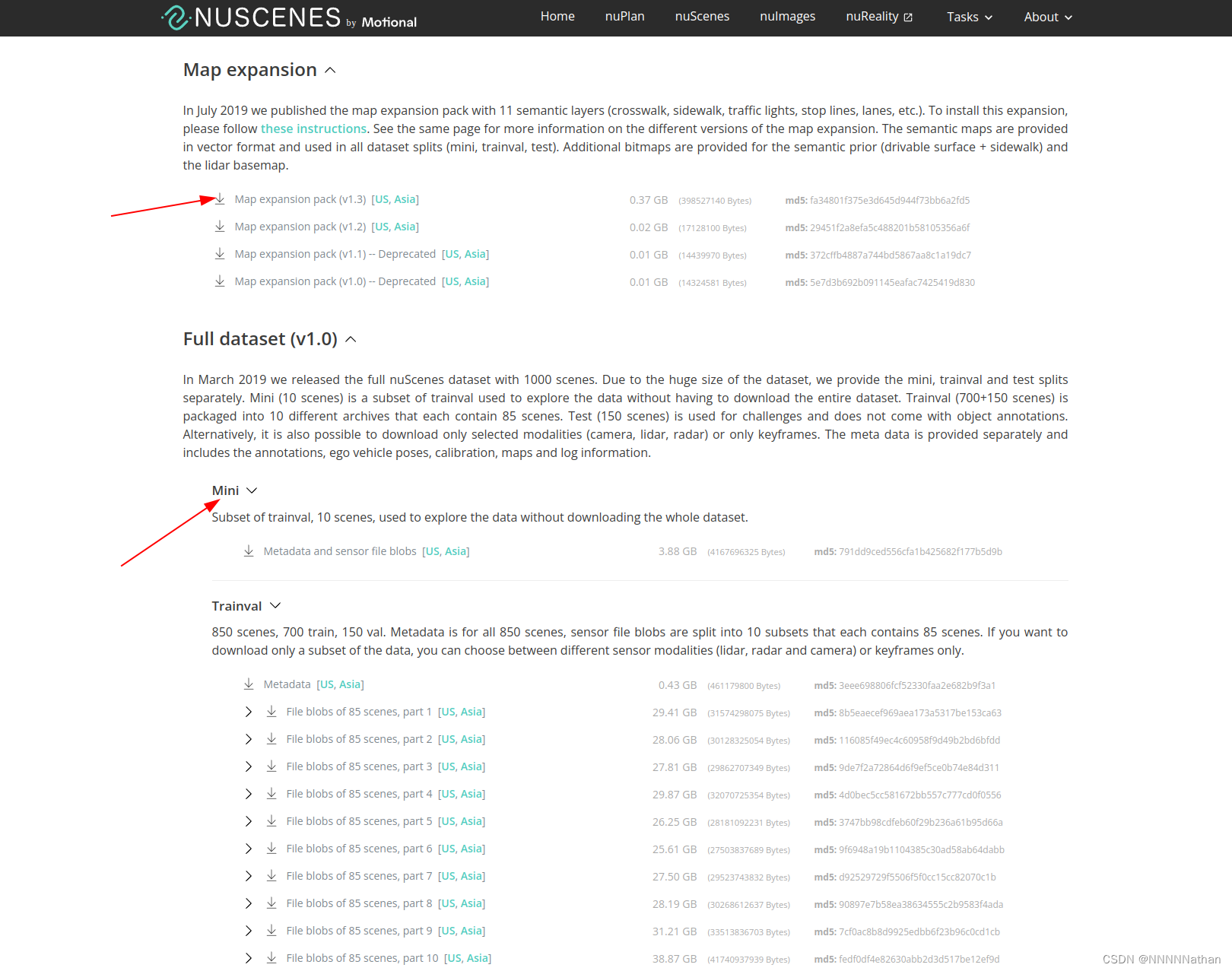
1 下载mini dataset后解压后并将根目录下的v1.0-mini改成mini
2 下载map expansion下的文件并解压到mini/maps文件夹下

在LSS工程下运行:
#这里的dataroot改成你自己的路径位置,GPU如果是默认一块则为0:
python main.py viz_model_preds mini --modelf=model525000.pt --dataroot=/nuscenes --map_folder=/nuscenes/mini --gpuid=0
# 对于代码的训练和测试可以直接管github repo上的指示工程下可以看到如下图像结果

4 相关工作
单目相机实现3D检测主要依靠如何将二维图像的检测结果转换到3位的参考帧坐标系中,常见的做法是在训练2D目标检测模型的同时训练一个网络来将2D的bbox转换到3D空间中,如SSD-6D;和训练2D检测模型的同时使用一个损失函数来预测图像深度信息来缓解错误的BBox。
另外的方法便是独立训练一个模型用于深度预测、另一个模型用于在BEV视角下进行检测任务;这种方法被称为 “pseudolidar”。该方法取得成功的直接原因是,伪激光雷达(pseudolidar”)能够训练鸟瞰网络,且该网络在最终评估检测的坐标系中;因此相对于图像平面,欧氏距离对于网络的训练更有意义。
第三种类别的单目目标检测模型三维物体的特征投影到所有的相机中来获得primitives。如Mono3D、Orthographic Feature Transform等。
5 LSS模型介绍
LSS模型学习来自任意相机图像帧的数据,并将所有的图像帧表达在BEV空间中。首先给定来自不同视角的n的图片∈
,k≤n,每帧图像有相机自身的内参
∈
和相机到ego坐标系的外参
∈
;最终需要在BEV坐标系y∈
下使用栅格化方式进行特征的表达,因此外参和内参定义了如何将n个相机坐标系的像素(x,y,z)映射到BEV的参考坐标系(h,w,d)下。
5.1 Lift:隐式深度分布
Lift的主要操作是对输入特征图像根据内外参将特征转换到所有相机共享的3维空间中,因此首要做的是对输入的多帧原始图像独立的使用图像特征提取器(论文中使用的是EfficientNet-B0)进行图像的特征提取;然后需要根据图像的深度信息将像素点转换到参考的3维空间中,类似于将RGBD生成点云(此处不清楚坐标系转换的的同学可以自行查询如下4个坐标系转换内容:图像坐标系、像素坐标系、归一化坐标系、相机坐标系),但是由于单目相机本身的深度未知性质;因此作者在此为所有像素生成不同深度下的特征信息。
对于每一帧拥有外参T与内参K的图片X ∈ ,对图像中的每个像素均使用D个离散深度深度来表达,类似于一个RGB图像拥有多帧深度图像,但每帧中深度图像的深度信息都是一样的,不同深度图像帧的深度信息是顺序渐变的。此处使用深度定义为{d0 + ∆, ..., d0 + |D|∆},代码中深度信息取相机Z轴范围4-44米空间,即D为41米,设定每个离散深度间的距离为1米。这样就对一帧图像创建了一份大小为D*H*W的点云信息。
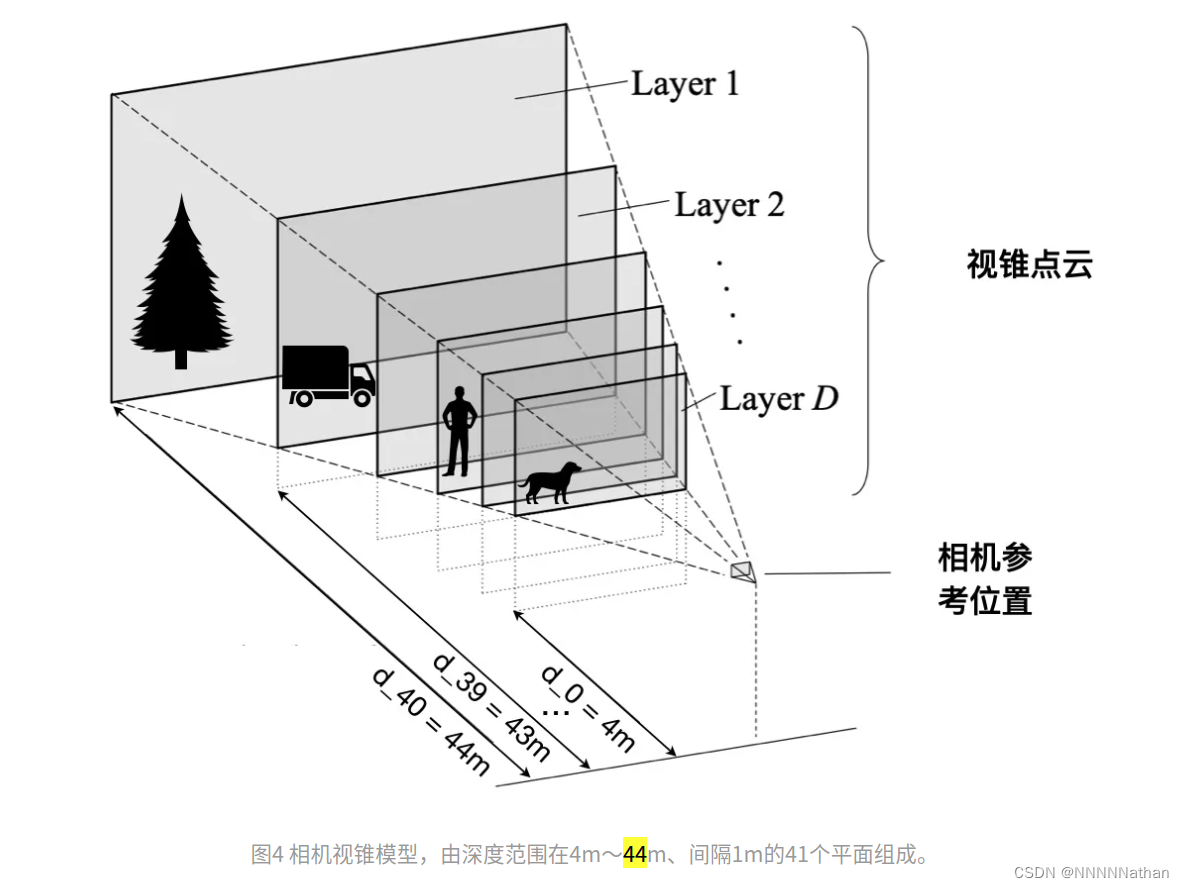
代码中的实现如下图所示
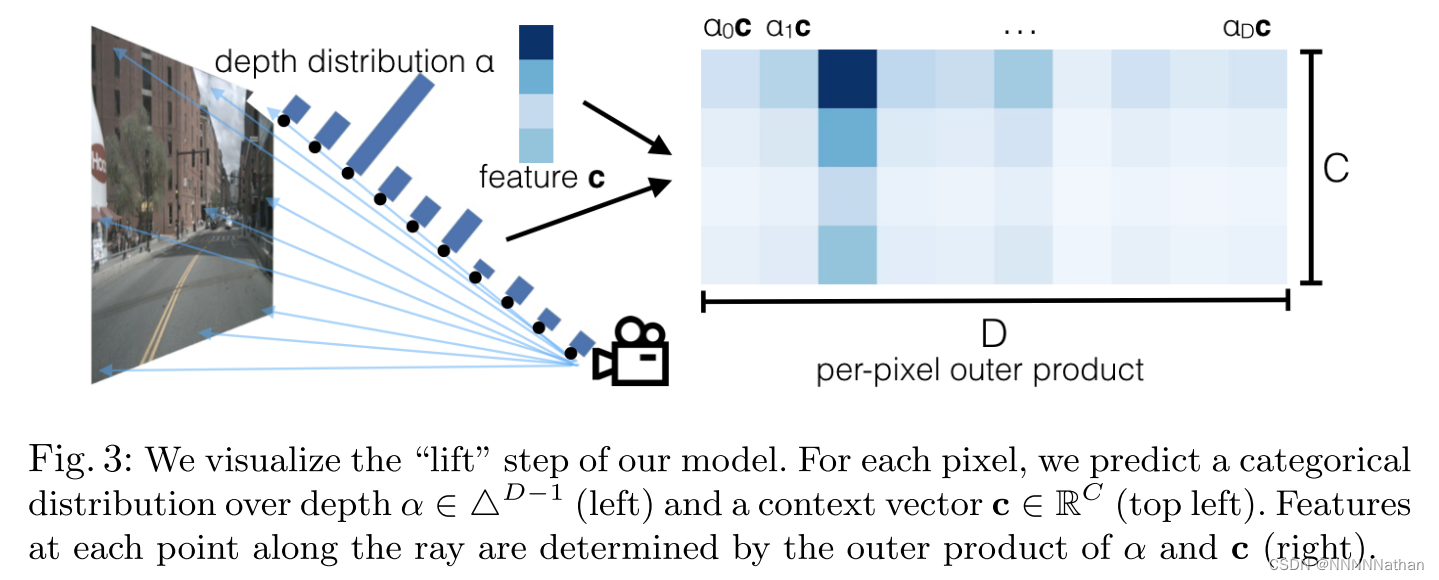
首先在backbone出来的特征上进行上述的转换操作,因此对于特征图像(C,H,W)的每个特征C ∈ 和给定的深度离散分布α ∈
进行外积得到图像特张在当前深度的特征信息
=
* C。
简而言之,该模块的主要内容便是对于一帧特征图,特征图上的每个特征可以被任意深度空间位置相结合生成该空间位置该特征独有的空间特征信息,因此每帧图像会生成一份视锥点云特征。
注:LSS中对原图像进行了裁剪操作,输入网络的图像大小为128 * 352,因此需要对应的调整图像的内参,例如分辨率长宽各变小α倍,相机内参fx,fy,cx, cy各变小α倍;相机到车辆ego的外参不需要进行变化。
到此为止单帧图像的操作才算完成,下面的splate操作会融合来自多帧图像的信息
5.2 splat:pillar池化
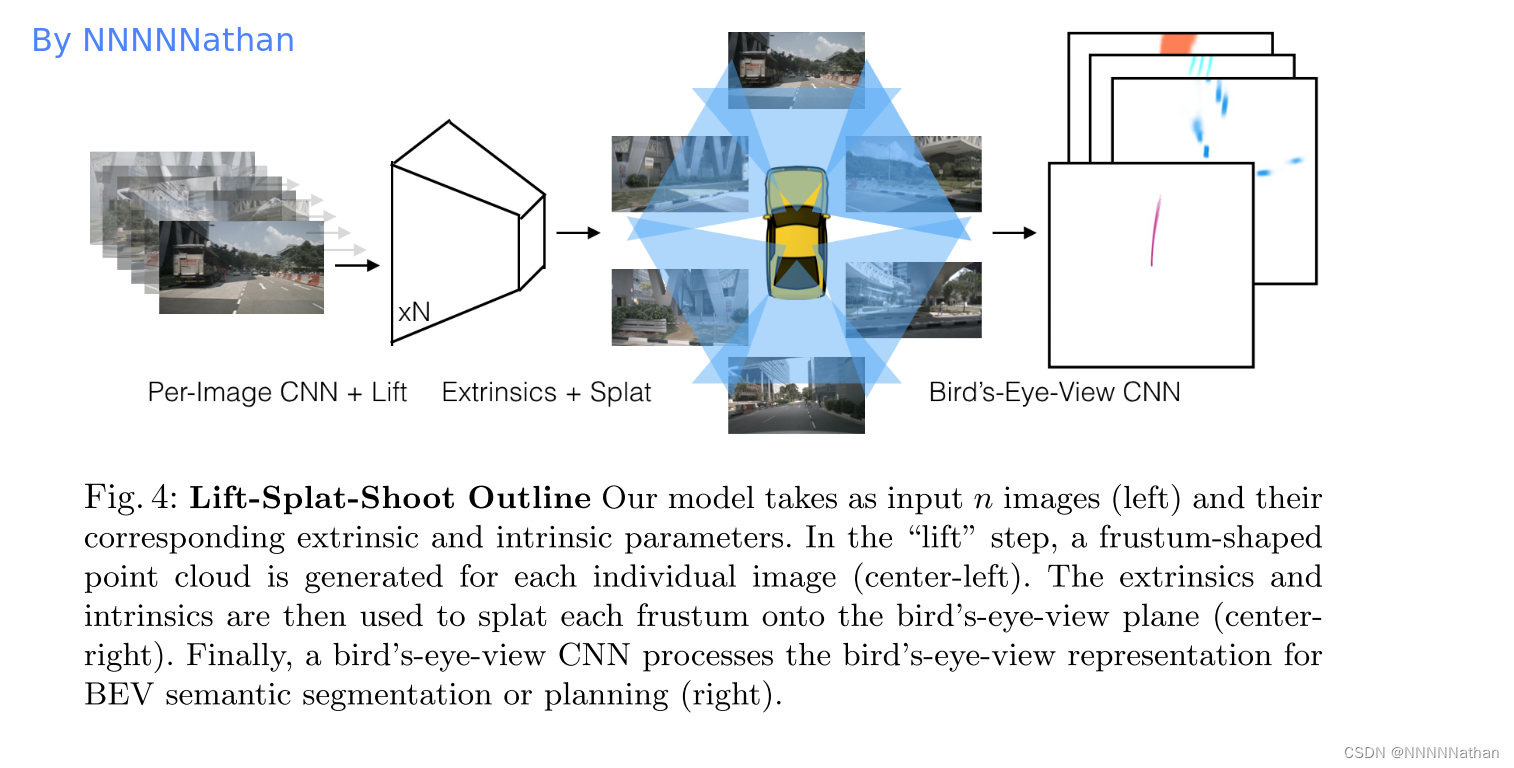
在经过lift模块后,可以获得来自N个相机的N帧视锥点云特征,同时他们之间部分视野也会有重叠的情况,因此此处会将他们转换到BEV空间中进行融合操作。
LSS中BEV网格X向与Y向均为-50米到50米,Z向为-10米到10米,xyz分别间隔0.5*0.5*20米创建一个cells。因此整个BEV网格大小为200*200。
在BEV中,可以理解为每个网格拥有无限高度的voxel,因此将上面图像生成的视锥点云特征按照位置放到离它最近的BEV pillar中然后进行sum pooling操作生成C x H x W的特征,该特征便可以被常规的CNN在BEV视角下进行处理。整体架构如上贴图所示。
注:一个BEV pillar中的点可能来自于:
- 单张2D图像不同的像素点可以投影在俯视图中的同一个位置,例如垂直于平面的物体,它成像的多个像素点拥有同一个深度信息,因此会被投影到同一个BEV Pillar中。
- 相邻两相机有部分成像重叠区域,因此不同相机图像中的像素点根据外参转化到BEV视角下会投影在同一个BEV Pillar。
cumsum trick:
此处文章提及OFT论文中使用积分图像的方式加速池化了方法,因此作者也设计了cumsum(cumulative sum) trick方法来避免执行max pooling池化操作时的pillar padding致使内存消耗过大,同时该方法拥有数值梯度避免自动求导拖慢训练速度。
伪代码解析示例:
代码中voxel_pooling方法首先对一个pillar中所有特征进行了累计求和,然后滤除在同一个pillar中的特征(通过ranks变量进行判断);找到该pillar的累加特征后减掉rank索引变化的初值得到该位置的特征累加和(上面这里用以下示例介绍以下):
假设有如下特征,并对特征进行了累计求和:
feats = [ [1,1], [1,1], [2,2], [2,2], [0,0], [0,0], [1,1], [1,1], [2,2], [2,2] ]
ft_cumsum = feats.cumsum(0)
>>> [[1,1], [2,2], [4,4], [6,6], [6,6], [6,6], [7,7], [8,8], [10,10], [12,12] ]然后之前计算了rank数组变量,该变量给出了每个pillar的索引信息,相同的索引意味着特征来自同一个pillar;如果有重复的索引,我们只需要保留ft_cum中最右边的特征即可,因为之前的特征均已累加在最右边的特征上了。
# ranks中为什么没有1,因为pillar为1的索引中没有特征
# rank计算的是每个特征的pillar索引
ranks = [0,0,2,3,3,4,5,5,6,7]
kept = ones(feats.shape[0], dtype=bool)
kept[:-1] = (ranks[1:] != ranks[:-1])
>>> [False, True, True, False, True, True, False, True, True, True]通过rank可以看出为0、1;3、4;6、7来自相同的pillar(分别来自索引为0,3,5的pillar中),然后通过对ranks前后错位判断可以得到每个pillar索引跳变的位置。
ft_cumsum = ft_cumsum[kept]
ft_cumsum = cat(ft_cumsum[:1], ft_cumsum[1:] - ft_cumsum[:-1])
>>> [ [2,2], [2,2], [2,2], [0,0], [2,2], [2,2], [2,2] ]取出所有跳变位置的数值,该数值是前面所有数值的累加,若要得到属于该pillar特征的累加和,要减掉之间特征累加的结果,因此需要进行ft_cumsum[1:] - ft_cumsum[:-1]操作。这样就得到了该pillar中所有特征的累加和。巧妙不?
其他博文中广泛流传的是这张图片,大家也可以对照上述伪代码进行参考。
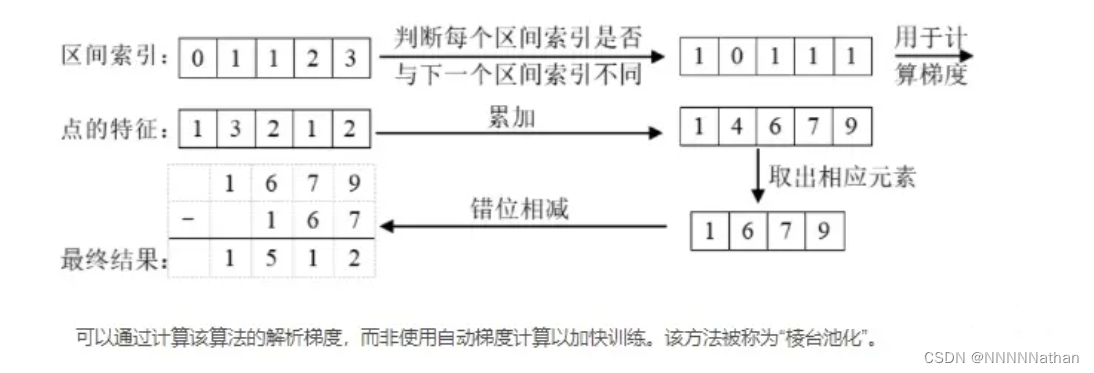
这里再说一下该算法的解析梯度是如何实现的。
@staticmethod
def backward(ctx, gradx, gradgeom):
# 原始ranks:1 1 2 3 3 3 4 4 5;即索引为1的pillar中有两个点云特征,以此类推
# kept: 0 1 1 0 0 1 0 1 1;kept指明了一个pillar中哪个点被最终保留下来
kept, = ctx.saved_tensors
# kept累加: 0 1 2 2 2 3 3 4 5 (back) 可以看到,只有在段末尾,即kept的位置,back的值会发生跳变
back = torch.cumsum(kept, 0)
# back的kept位置减1:
# 0 0 1 2 2 2 3 3 4
back[kept] -= 1
# 基于ranks,可知道原来的0 1 位置的rank都是1,因此被池化,得到x的第0个值;因此回传梯度时,0 1位置的梯度索引都是0;
# 后面同样,例如第3、4、5个位置的rank都是3,池化得到x的第2个值,因此3、4、5位置的梯度索引都是2
val = gradx[back]
return val, None, None5.3 shoot: 运动规划
Lift-Splat部分输出了由N个相机图像编码的BEV features,接下来就是再接上Head来实现特定的任务,如果是运动规划的化,就是文章LSS中的最后一个S->Shoot。
LSS的关键是可以仅使用图像就可以实现端到端的运动规划。在测试时,用推理输出cost map进行规划的实现方法是:”Shoot”输出多种轨迹,并对各个轨迹的cost进行评分,然后根据最低cost轨迹来控制车辆运动。这部分的核心思想来自《End-to-end Interpretable Neural Motion Planner》。
注:此部分不是本专栏的重点,因此感兴趣的小伙伴可以自行查阅这部分内容。
5.4 代码注析
详细的代码注析可以看我的git;这里主要给出LSS特有的部分
"""
Copyright (C) 2020 NVIDIA Corporation. All rights reserved.
Licensed under the NVIDIA Source Code License. See LICENSE at https://github.com/nv-tlabs/lift-splat-shoot.
Authors: Jonah Philion and Sanja Fidler
"""
import torch
from torch import nn
from efficientnet_pytorch import EfficientNet
from torchvision.models.resnet import resnet18
from .tools import gen_dx_bx, cumsum_trick, QuickCumsum
class Up(nn.Module):
def __init__(self, in_channels, out_channels, scale_factor=2):
super().__init__()
# 通过双线性差值进行两倍上采样,且对其边角
self.up = nn.Upsample(scale_factor=scale_factor, mode='bilinear',
align_corners=True)
self.conv = nn.Sequential(
nn.Conv2d(in_channels, out_channels, kernel_size=3, padding=1, bias=False),
nn.BatchNorm2d(out_channels),
nn.ReLU(inplace=True),
nn.Conv2d(out_channels, out_channels, kernel_size=3, padding=1, bias=False),
nn.BatchNorm2d(out_channels),
nn.ReLU(inplace=True)
)
def forward(self, x1, x2):
x1 = self.up(x1)
x1 = torch.cat([x2, x1], dim=1)
return self.conv(x1)
class CamEncode(nn.Module):
def __init__(self, D, C, downsample):
super(CamEncode, self).__init__()
self.D = D # 离散的深度层数->41
self.C = C # 最终图像backbone输出的特征深度 ->64
# 直接使用预训练好的EfficientNet-B0模型进行图像的特征提取
self.trunk = EfficientNet.from_pretrained("efficientnet-b0")
self.up1 = Up(320 + 112, 512) # 上采样
self.depthnet = nn.Conv2d(512, self.D + self.C, kernel_size=1, padding=0)
def get_depth_dist(self, x, eps=1e-20):
return x.softmax(dim=1)#此处在第一个维度(D维度)进行softmax,得到该像素点在41个深度中的置信度信息
def get_depth_feat(self, x):
x = self.get_eff_depth(x)# shape (B*N, 512, 8, 22)
# Depth
x = self.depthnet(x)# shape (B*N, 512, 8, 22) -> (B*N, 41+64, 8, 22)
# 此处在第一个维度(D维度)进行softmax,得到该像素点在41个深度中的置信度信息
depth = self.get_depth_dist(x[:, :self.D])
#此处对应论文中的外积操作,使用深度与该特征点的特征进行外积操作,得到图像特征在不同深度下的空间点云特征
new_x = depth.unsqueeze(1) * x[:, self.D:(self.D + self.C)].unsqueeze(2)
return depth, new_x
def get_eff_depth(self, x):
# adapted from https://github.com/lukemelas/EfficientNet-PyTorch/blob/master/efficientnet_pytorch/model.py#L231
endpoints = dict()
# Stem
x = self.trunk._swish(self.trunk._bn0(self.trunk._conv_stem(x)))
prev_x = x
# Blocks
for idx, block in enumerate(self.trunk._blocks):
drop_connect_rate = self.trunk._global_params.drop_connect_rate
if drop_connect_rate:
drop_connect_rate *= float(idx) / len(self.trunk._blocks) # scale drop connect_rate
x = block(x, drop_connect_rate=drop_connect_rate)
if prev_x.size(2) > x.size(2):
endpoints['reduction_{}'.format(len(endpoints) + 1)] = prev_x
prev_x = x
# Head
endpoints['reduction_{}'.format(len(endpoints) + 1)] = x
x = self.up1(endpoints['reduction_5'], endpoints['reduction_4'])
return x
def forward(self, x):
depth, x = self.get_depth_feat(x)
# 此处x对应论文中的外积后图像特征在不同深度下的空间点云特征
return x
class BevEncode(nn.Module):
def __init__(self, inC, outC):
super(BevEncode, self).__init__()
"""
# BEV空间下,直接使用resnet18作为特征提取器
# Zero-initialize the last BN in each residual branch,
# so that the residual branch starts with zeros, and each residual block behaves like an identity.
# This improves the model by 0.2~0.3% according to https://arxiv.org/abs/1706.02677
"""
trunk = resnet18(pretrained=False, zero_init_residual=True)
self.conv1 = nn.Conv2d(inC, 64, kernel_size=7, stride=2, padding=3,
bias=False)
self.bn1 = trunk.bn1
self.relu = trunk.relu
self.layer1 = trunk.layer1
self.layer2 = trunk.layer2
self.layer3 = trunk.layer3
self.up1 = Up(64 + 256, 256, scale_factor=4)
self.up2 = nn.Sequential(
nn.Upsample(scale_factor=2, mode='bilinear',
align_corners=True),
nn.Conv2d(256, 128, kernel_size=3, padding=1, bias=False),
nn.BatchNorm2d(128),
nn.ReLU(inplace=True),
nn.Conv2d(128, outC, kernel_size=1, padding=0),
)
def forward(self, x):
x = self.conv1(x)
x = self.bn1(x)
x = self.relu(x)
x1 = self.layer1(x)
x = self.layer2(x1)
x = self.layer3(x)
x = self.up1(x, x1)
x = self.up2(x)
return x
class LiftSplatShoot(nn.Module):
def __init__(self, grid_conf, data_aug_conf, outC):
super(LiftSplatShoot, self).__init__()
self.grid_conf = grid_conf
self.data_aug_conf = data_aug_conf
dx, bx, nx = gen_dx_bx(self.grid_conf['xbound'],
self.grid_conf['ybound'],
self.grid_conf['zbound'],
)
# 这几个参数不需要优化,所以将requires_grad设置为False
self.dx = nn.Parameter(dx, requires_grad=False)
self.bx = nn.Parameter(bx, requires_grad=False)
self.nx = nn.Parameter(nx, requires_grad=False)
self.downsample = 16 # 图像的下采样率
self.camC = 64 # 图像经过backbone后最终的特征维度
self.frustum = self.create_frustum() # 创建图像的视锥信息
self.D, _, _, _ = self.frustum.shape
self.camencode = CamEncode(self.D, self.camC, self.downsample)#图像提取器
self.bevencode = BevEncode(inC=self.camC, outC=outC)# BEV特征提取器
# toggle using QuickCumsum vs. autograd
self.use_quickcumsum = True#是否使用QuickCumsum或者自动求导
def create_frustum(self):
# make grid in image plane,根据图像信息创建图像对应的视锥空间索引信息
# 输入网络的图像高宽 -> (128, 352)
ogfH, ogfW = self.data_aug_conf['final_dim']
# 经过16倍下采样后特征图的高宽 -> (8, 22)
fH, fW = ogfH // self.downsample, ogfW // self.downsample
# shape:(41,8,22),为特征层像素创建离散深度,从4米到45米,间隔1米选取一个离散深度,总共41个离散深度
ds = torch.arange(*self.grid_conf['dbound'], dtype=torch.float).view(-1, 1, 1).expand(-1, fH, fW)
# 这里是在下采样的特征图分辨率上,若要将图像坐标系转换到相机坐标系中,需要在输入图像的分辨率上进行,否则相机的内参不对应;
# 因此这里将下采样后特征图上的像素映射回输入的图像像素上,找出该特征中心在原始图像上的XY坐标
D, _, _ = ds.shape
xs = torch.linspace(0, ogfW - 1, fW, dtype=torch.float).view(1, 1, fW).expand(D, fH, fW)
ys = torch.linspace(0, ogfH - 1, fH, dtype=torch.float).view(1, fH, 1).expand(D, fH, fW)
# D x H x W x 3 得到相机坐标系下拥有41层深度的视锥点云x,y,z信息
frustum = torch.stack((xs, ys, ds), -1)
return nn.Parameter(frustum, requires_grad=False) # 该信息不需要经过优化,所以requires_grad设置为False
def get_geometry(self, rots, trans, intrins, post_rots, post_trans):
"""Determine the (x,y,z) locations (in the ego frame)
of the points in the point cloud.
Returns B x N x D x H/downsample x W/downsample x 3
"""
B, N, _ = trans.shape
# undo post-transformation
# Batch x N_cams x D_41个离散深度 x H高 x W宽 x 3
# 将视锥RGBD图像帧变换原始输入图像的图像坐标系中,并使用原始的内参进行坐标系变换;否则需要对内参进行缩放
points = self.frustum - post_trans.view(B, N, 1, 1, 1, 3)
points = torch.inverse(post_rots).view(B, N, 1, 1, 1, 3, 3).matmul(points.unsqueeze(-1))
# cam_to_ego
# 将当前帧图像坐标系转换到当前帧的相机坐标系中
points = torch.cat((points[:, :, :, :, :, :2] * points[:, :, :, :, :, 2:3],
points[:, :, :, :, :, 2:3]), 5)
#将每帧相机坐标系下的视锥点云根据相机与ego(车辆自身坐标系)的变换矩阵与相机的内参一起,
# 转换到车辆自身坐标系下,此处不清楚的同学可以自行查阅slam14讲第5讲内容或者百度
combine = rots.matmul(torch.inverse(intrins))
points = combine.view(B, N, 1, 1, 1, 3, 3).matmul(points).squeeze(-1)
points += trans.view(B, N, 1, 1, 1, 3)
# 返回在ego坐标系下的视锥点云信息,shape:(4,6,41,8,22,3)
return points
def get_cam_feats(self, x):
"""Return B x N x D x H/downsample x W/downsample x C
"""
B, N, C, imH, imW = x.shape
# 来自不同相机的图像都是独立处理的,所以此处把来自多帧的图像直接放在batch维度一起推理
x = x.view(B * N, C, imH, imW)
x = self.camencode(x)
# shape: (4, 6, 64, 41, 8, 22)
x = x.view(B, N, self.camC, self.D, imH // self.downsample, imW // self.downsample)
# shape: (4, 6, 64, 41, 8, 22)->(4, 6, 41, 8, 22, 64)
x = x.permute(0, 1, 3, 4, 5, 2)
return x
def voxel_pooling(self, geom_feats, x):
B, N, D, H, W, C = x.shape
# 把所有数据的BEV pillar进行展开用于进行池化操作
Nprime = B * N * D * H * W
# flatten x
x = x.reshape(Nprime, C)
# flatten indices
# #geom_feats是上面图像生成的在ego坐标系下的视锥点云信息,
# 此处需要将当前ego下的所有点转换到BEV空间下,所有特征减去BEV空间下的初始值,
# 然后再除以每个pillar的大小得到特征索引
geom_feats = ((geom_feats - (self.bx - self.dx / 2.)) / self.dx).long()
# 展开成一维与上述特征x相对应
geom_feats = geom_feats.view(Nprime, 3)
# 确定上述所有特征各自对应哪个batch
batch_ix = torch.cat([torch.full([Nprime // B, 1], ix,
device=x.device, dtype=torch.long) for ix in range(B)])
# 将特征的索引与batch_idx拼接在一起shape:(Nprime, 4)
geom_feats = torch.cat((geom_feats, batch_ix), 1)
# filter out points that are outside box
# #对于超出BEV空间的点进行剔除,论文中选取的BEV网格大小XY为200,因此对小于0或者大于200的数值直接丢弃
kept = (geom_feats[:, 0] >= 0) & (geom_feats[:, 0] < self.nx[0]) \
& (geom_feats[:, 1] >= 0) & (geom_feats[:, 1] < self.nx[1]) \
& (geom_feats[:, 2] >= 0) & (geom_feats[:, 2] < self.nx[2])
# 索引BEV 200网格范围内的特征点
x = x[kept]
geom_feats = geom_feats[kept]
# get tensors from the same voxel next to each other
"""
geom_feats的前三维为BEV下pillar特征的长宽高索引,其中高索引均为0;
最后一维为该特征所在的batch索引[0, 1, 2, ..., batch-1]。
给geom_feats赋rank值,最后的geom_feats[:, 3],使得不在同一个batch的点的rank不同;
而如果具有相同rank的话,就是在相同的格子里。对rank排序,进而对x、geom_feats排序。
"""
ranks = geom_feats[:, 0] * (self.nx[1] * self.nx[2] * B) \
+ geom_feats[:, 1] * (self.nx[2] * B) \
+ geom_feats[:, 2] * B \
+ geom_feats[:, 3]
sorts = ranks.argsort()
x, geom_feats, ranks = x[sorts], geom_feats[sorts], ranks[sorts]
# cumsum trick
if not self.use_quickcumsum:
x, geom_feats = cumsum_trick(x, geom_feats, ranks)
else:
x, geom_feats = QuickCumsum.apply(x, geom_feats, ranks)
# griddify (B x C x Z x X x Y)
# 将累加后的结果重新恢复到BEV空间的每个pillar中
final = torch.zeros((B, C, self.nx[2], self.nx[0], self.nx[1]), device=x.device)
final[geom_feats[:, 3], :, geom_feats[:, 2], geom_feats[:, 0], geom_feats[:, 1]] = x
# collapse Z 使用unbind将Z维度切片,然后cat到C的维度上。
final = torch.cat(final.unbind(dim=2), 1) # shape (batch, C, X, Y) = (4,64,200,200)
return final
def get_voxels(self, x, rots, trans, intrins, post_rots, post_trans):
# 生成相机下视锥的坐标
geom = self.get_geometry(rots, trans, intrins, post_rots, post_trans)
# 生成图像的特征
x = self.get_cam_feats(x)
# 论文中的池化操作包括了lift和splate部分
x = self.voxel_pooling(geom, x)
return x
def forward(self, x, rots, trans, intrins, post_rots, post_trans):
"""
imgs 归一化图像信息,
rots 相机到ego的旋转矩阵,
trans 相机到ego的平移向量,
intrins 相机的内参,
post_rots 图像的单应矩阵的旋转,
post_trans 图像的单应的平移向量,这里把图像的二维单应矩阵矩阵变成三维了齐次矩阵方便后面计算
binimg 得到目标在BEV下的二值图像用于网络的训练
"""
# 该函数对应论文中所说的lift和splat部分
# 其中lift使用了efficientnet对图像进行特征提取
x = self.get_voxels(x, rots, trans, intrins, post_rots, post_trans)
# 使用resnet作为BEV下的特征提取器
x = self.bevencode(x)
return x
def compile_model(grid_conf, data_aug_conf, outC):
return LiftSplatShoot(grid_conf, data_aug_conf, outC)
6 loss计算
LLS的训练LOSS使用了图像分割的方式,更确切的说直接是对BEV的每个grid网格进行了BEC分类来完成的。在数据的dataloader中会通过get_bin函数来获取target图像,用于监督网络训练;target图像来自将标注文件中的3D的BBOX投影到BEV平面上,其中nescens中测car类型包含了如下几个类别{ car, truck, other_vehicle, bus, bicycle }
主要的代码包含如下一段:
def get_binimg(self, rec):# 用于本文的loss监督的图像
egopose = self.nusc.get('ego_pose',#车辆自身位姿,这里由顶部的激光雷达建图获取来egopose位姿
self.nusc.get('sample_data', rec['data']['LIDAR_TOP'])['ego_pose_token'])
trans = -np.array(egopose['translation'])#该操作相当于对位姿求逆,把车辆在世界坐标系下的位姿转换到以当前自身为坐标系系
rot = Quaternion(egopose['rotation']).inverse
img = np.zeros((self.nx[0], self.nx[1]))
for tok in rec['anns']:
inst = self.nusc.get('sample_annotation', tok)
# add category for lyft
if not inst['category_name'].split('.')[0] == 'vehicle':
continue
box = Box(inst['translation'], inst['size'], Quaternion(inst['rotation']))#得到该物体在世界坐标系下的旋转和平移
box.translate(trans)#将该物体的在世界坐标系下的位姿转换到当前自身坐标系下,这样得到的用于训练网络的分割图像才是自身在图像中心,物体在自身周围BEV下
box.rotate(rot)
pts = box.bottom_corners()[:2].T# 取出3维box底部的4个点,仅去xy坐标,舍弃z轴;因为BEV本身就在Z轴空间进行了压缩
pts = np.round(
(pts - self.bx[:2] + self.dx[:2]/2.) / self.dx[:2]
).astype(np.int32)#将坐标转换到BEV的grid中
pts[:, [1, 0]] = pts[:, [0, 1]]# xy坐标调换以对应grid坐标顺序
cv2.fillPoly(img, [pts], 1.0)#在二值图像中画出该物体的box
return torch.Tensor(img).unsqueeze(0)下图是单目标生成的bin_img图像信息

loss计算部分,直接输入预测的二值图像与get_binimg得到的二值图像,计算BECloss后返回loss信息。
class SimpleLoss(torch.nn.Module):
def __init__(self, pos_weight):
super(SimpleLoss, self).__init__()
self.loss_fn = torch.nn.BCEWithLogitsLoss(pos_weight=torch.Tensor([pos_weight]))
def forward(self, ypred, ytgt):
loss = self.loss_fn(ypred, ytgt)
return loss7 结果
LSS是BEV空间下比较sperm的工作,这里主要说一下他的泛化性内容:
1、首先可以看到,LSS的方法学习到了物体的有效深度分布和上下文表征;因此这里可以回到前文提到的3个重要性质对于网络的学习来说是非常重要的。
2、BEV视角写LSS使用CNN可以学习到如何融合来自不同相机视野的信息,能够让模型对标定的偏差、或者相机数量变动导致的噪音有较好的泛化性;这里作者测试了训练过程中分别丢掉nuscens中6个相机的其中一个并推断该操作会让强迫模型学习学习来自不同图像帧之间的相关性;同时还测试了带有噪音的外参训练可以使得模型在测试时发挥更好。
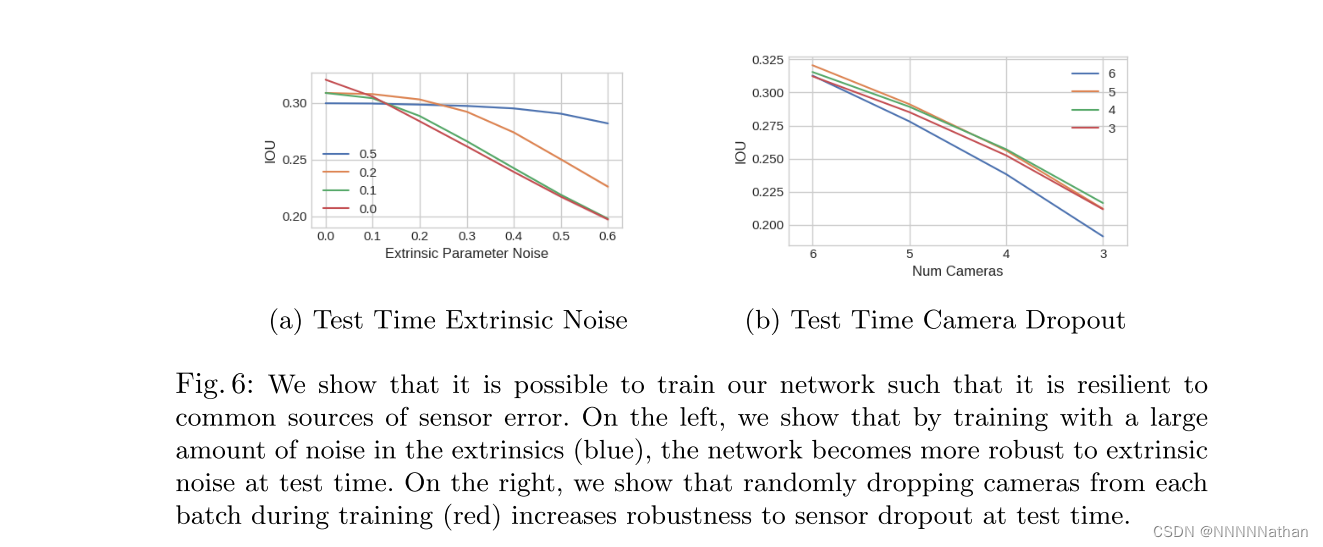
相机缺失时分割效果

3 Zero-Shot Camera Rig Transfer
为了查看LSS方法的通用性,作者使用了nuscens中的固定4个相机来对网络进行训练,并在测试时候加上剩余的两个相机。结果显示,加上额外的两个相机能够提升模型的整体性能。

nuscens上训练,Lyft上测试

参考文献或文章
1、https://www.nuscenes.org/nuscenes#download
2、https://arxiv.org/abs/2008.05711
3、一文读懂BEV自底向上方法:LSS 和 BEVDepth - 知乎


















 678
678

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











