







Federated clustering with GAN-based data synthesis使用基于gan的数据合成的联邦集群
Abstract
联邦聚类:
基于全局相似性度量对数据进行聚类。
k-FED和联邦模糊c-means(FFCM)对联邦学习设置K均值和模糊C均值调整。
目的: 通过在所有局部聚类质心集上运行K均值来构造 K 个全局聚类质心。对Non-iid数据敏感。
本文提出:基于GAN 的数据合成聚类框架,合成数据辅助联合聚类(SDA-FC)。它在有效性和鲁棒性方面优于k-FED和FFCM,只需要一轮通信,可以异步运行,并且可以处理设备故障。指标NMI虽然常用,但不如Kappa可靠
1.INTRODUCTION
对于Non-iid场景,基于 客户端聚类或数据聚类 构建多中心框架(同时训练多个全局模型)比普通单中心框架更好。
客户端集群:
每个客户端可能来自特定分布,使用同一集群中的客户端来协同训练特定的全局模型
但是: 单个客户端中的数据样本也可能来自特定分布
所以: 数据集群(联邦集群)更有利客户端协作。
**联邦聚类:**基于全局相似性对数据进行聚类,并保持数据本地私有。
当前研究的不足:
局部数据不足以正确对自身分组,全局数据可以,但出于隐私性无法共享全局数据。
K-FED和联邦模糊C-means(FFCM) 使用集中聚类算法k-means和模糊c-means
背后原理: 全局相似度度量(K个全局聚类质心)可以通过在所有局部聚类质心集上运行KM来构建,其中K是聚类的真实数量。
局部质心依赖局部数据分布,对Non-iid敏感,故全局质心脆弱。
本文贡献:基于GAN 的数据合成聚类框架,合成数据辅助联合聚类(SDA-FC)。
两个主要步骤:全局合成数据构造和聚类分配
- 第一步:服务器使用本地数据训练多个本地GANs,构建全局合成数据。
- 第二步:服务器对全局合成数据进行 KM/FCM ,得到K个全局聚类执行,根据局部数据到质心的预先聚类进行聚类赋值,得到最终聚类结果。
SDA-FC可以很好地缩小联邦聚类和集中聚类之间的差距
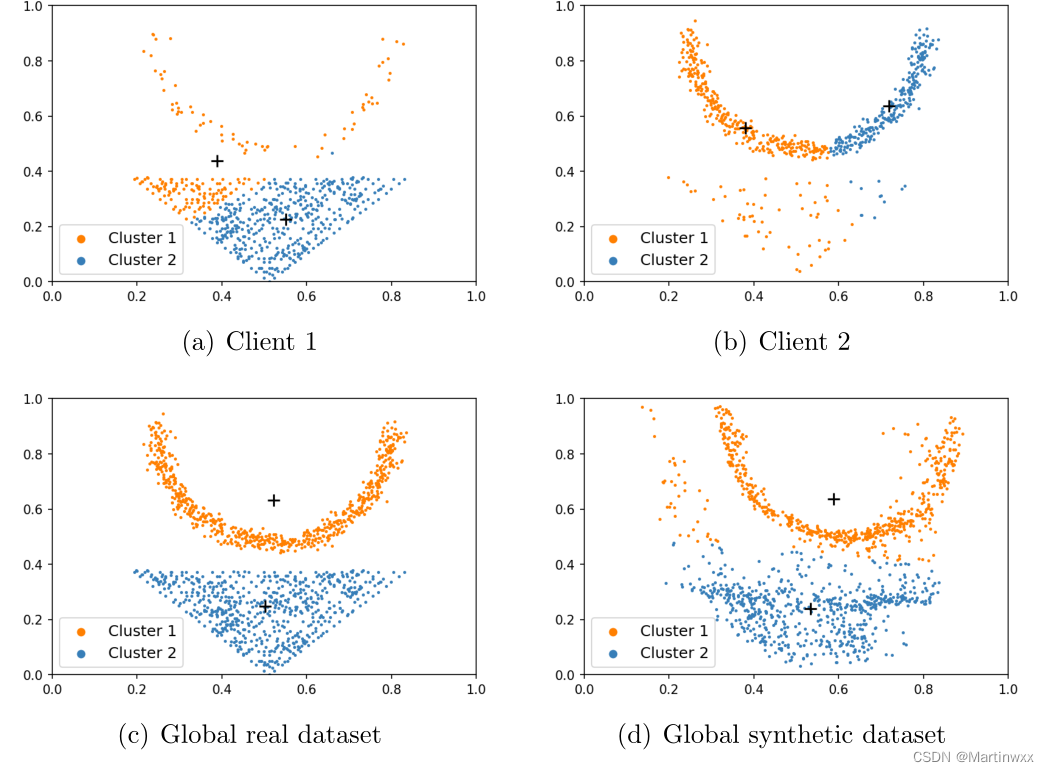
d真实质心,只有c最接近。
2.Related Work
2.1. Core challenges in federated learning
传统集中式学习,服务器存储客户端收集的所有数据。 对服务器存储计算能力要求较高。
即使是分布式学习也需要获取全局数据才能划分数据,有隐私问题。
联邦学习有四个核心挑战:
- Expensive Communication.
需要更少的通讯轮数和传输更小的数据。 - Systems Heterogeneity.
训练大型模型,由于种种局限,不是所有客户端都能参与训练。预测设备的低参与水平并对故障设备有健壮性。 - Data Heterogeneity.
Non-iid数据问题,收敛缓慢,模型性能差。使用基于客户端聚类或数据聚类构建多中心框架。 - Privacy Concerns.
攻击者可以从梯度和参数中重建原始数据。差分隐私用于保护,但降低模型性能。
2.2. Federated clustering
由于隐私性,无法测量客户端之间样本的相似性。
两种类似的方法k-FED和FFCM:依赖于局部数据分布,不可靠。
使用GAN数据合成,构建与全局数据的良好近似,不共享私有数据且更有效的捕获全局相似度特征。只需一次通信,可以异步运行,可以处理设备故障。
3. Synthetic Data Aided Federated Clustering (SDA-FC)
3.1. Preliminaries
GAN由两个网络组成:发生器和鉴别器。
生成器: 生成尽可能真实的样本来欺骗鉴别器
鉴别器: 将生成的样本与正式的样本区分开来
当鉴别器无法区分生成和真实样本时,结束。即以学会真实分布,达到理论全局最优。
函数定义:
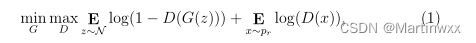
G G G: 输入噪声 z z z并输出生成样本的生成器
N \mathcal N N:高斯分布
D D D 输入样本并输出标量以区分生成和真实样本的判别器
p r p_r pr 真实数据的分布
GAN对抗训练不稳定,模式塌缩表现为生成样本高质量,低多样性 ,模型只能捕捉真实数据的部分特征。
在生成器的输入中引入一个额外的分类变量,使生成数据在潜在空间的聚类结构更加清晰,即生成样本的多样化。
为减轻模式崩溃,使用离散和连续变量的混合作为生成器的输入。遵循:
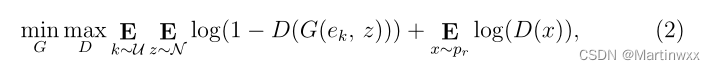
U \mathcal U U 是均匀随机分布,最小1,最大K, e k e_k ek 是one-hot向量,第K个元素为1。
3.2. Synthetic Data Aided Federated Clustering (SDA-FC)
给定一个分布在
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2972
2972

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









