








问题
不同于二维目标检测,三维目标检测中的基准框包含着大量的信息,其能够很自然的提供前景点的标记,甚至提供位于基准框中各个点的内部相对位置。而这些信息对于三维目标检测是非常重要的。三维目标网络的内部相对位置包含了三维基准框内点的分布,这类信息能够很轻易的从点云数据中获得,且包含大量的信息,但是之前从来没有三维边界网络使用这些信息。基于这个观察,本文作者提出了Part-Aware and Part-Aggregation网络.
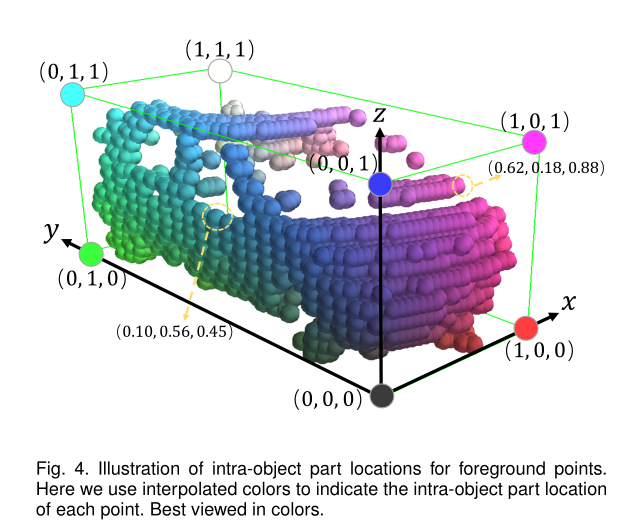
内部相对位置的图示。通过这些相对位置,可以帮助网络更好的预测三维边界框。
解决方法
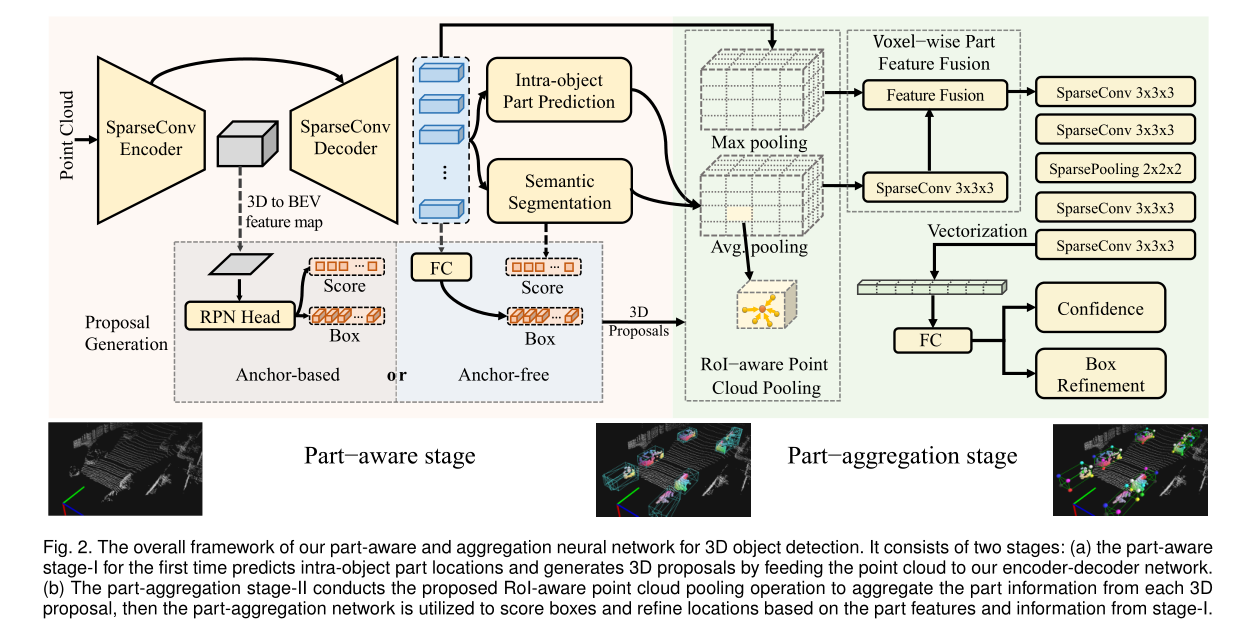
网络的总体结构如上图所示,本文作者设计了一个使用稀疏卷积的U-Net网络。其中这部分Encode-Decode部分的网络如下图所示:
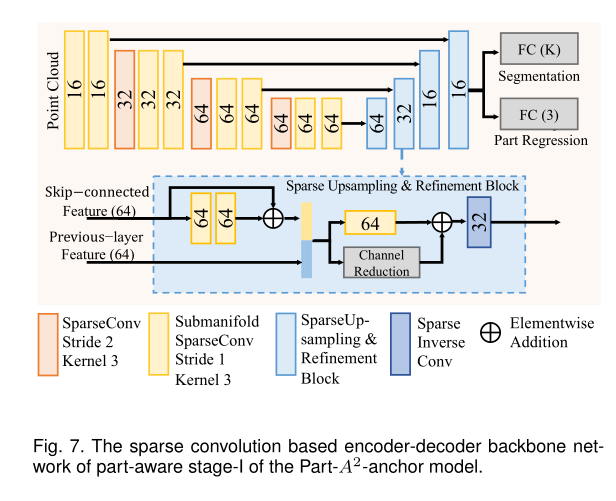
注意,这个与Second中的还是不太一样的,其增加了一个反卷积部分的网络。作者使用这些特征做了两个方面的工作,一个分支是用来预测点的类别,即属于前景点还是属于背景点,另一个分支是用来预测前景点相对边界框的内部相对位置。
关于前景点内部相对位置的计算,其计算公式如下:
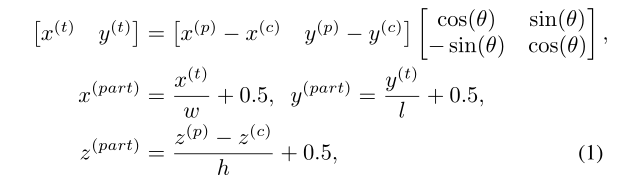
其中 x p x^p xp表示的是点云的原始坐标, x c x^c xc表示的边界框的中心点坐标。 w , l , h w,l,h w,l,h表示的是三维边界框的大小。这样的话三维边界框的中心点的坐标就是(0.5, 0.5, 0.5)。当然,需要计算这些的话就需要计算损失,由于这些相对坐标都是位于[0,1]之间,所以作者使用了一个二值交叉熵损失来作为这个任务的损失。其计算方法如下:
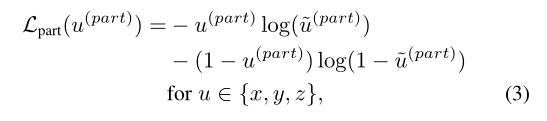
对于点云类别的分类的话,作者使用的是Focal loss损失作为这个任务的损失,其计算方法如下:

在完成上述任务之后,还需要一些proposal来作为下一个阶段的聚合点的特征的标准。文中作者提出了两种方法,一种是anchor-based的,一个是anchor-free的。anchor-based的方法类似于second中的方法,这个方法可以获得更好的recall,但是其需要消耗更多的计算量以及显存。anchor-free相比之下的recall要差一些,但是其计算量小,效率高,anchor-free可能类似于pointrcnn中的生成方法。
使用上述两种方法生成proposal之后,我们需要根据proposal来聚合周围点的特征。本文中作者提出了一种RoI-aware的特征聚合方法。不同于PointRCNN中简单的聚合proposal对应的逐点的特征,然后使用一个PointNet++来提取这些点的特征来作为proposal的特征。作者观察到这个方法存在一些缺陷,一方面是该方法丧失了很多几何特征,另一方面是在不同的proposal中造成了一些模棱两可的表达。其具体含义如下图所示:
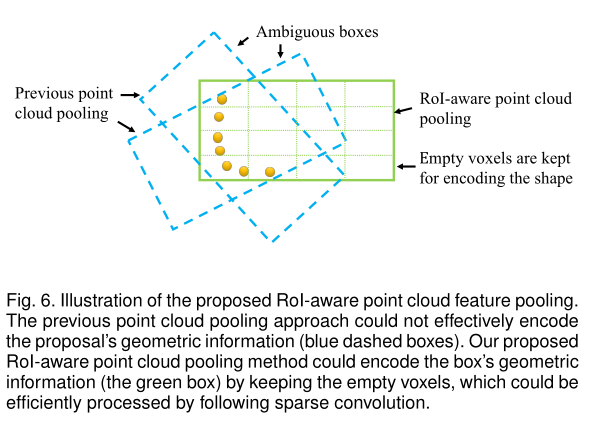
从图中可以看出,蓝色的两个虚线框表示的是不同的proposal,但是他们具有相同的聚合的点,这可能为之后的下游任务带来不利的影响。此外,在对proposal进行特征聚合的时候,作者并没有忽略掉空的voxel。
基于上述问题,作者提出了一种RoI-aware的聚合方法。其将每一个proposal均匀的划分为具有固定空间大小( L x , L y , L z L_x,L_y,L_z Lx,Ly,Lz)的体素。用 F F F表示位于3D 体素内的逐点的特征,这里的逐点的特征应该是每个体素的中心点,称为逐点。用 X X X表示逐点的内部相对位置, b b b表示proposal。对于每一个体素进行池化,对于相对位置的特征,作者使用的是均值池化的方式,即对于一个体素,该体素的特征为位于这个体素内的点的内部相对位置的平均值,语义特征使用的是最大池化的方式。不同于其他在特征上进行池化的方法,该池化方法在很大程度上保留了proposal中几何特征。而其他基于位置的特征则仅保留一部分语义特征。
此外,作者还使用IoU来对边界框的分数进行重新计算,其计算方法如下:

感觉和那个任务对齐有点像。
消融实验
-
使用PointNet++和SparseConvUNet对于网络性能的影响
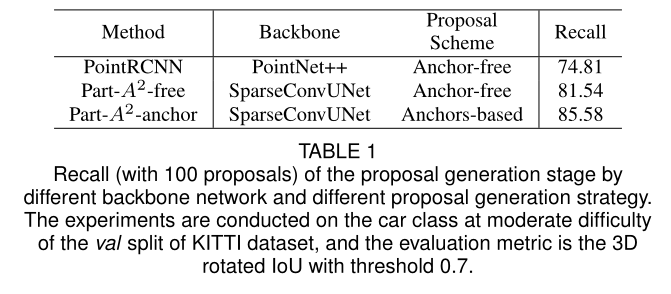
从上表中可以看出,使用SparseConvUNet能够更好的提取点云场景的特征,生成更高质量的proposal。
-
关于RoI-aware的池化方法对比

第一行展示的是对于每一个porposal,使用这个类别的平均尺寸作为proposal的大小,然后将proposal同样划分为固定大小的grid。从上表中的结果可以看出,RoI-aware池化方法相比使用均值大小的proposal在性能上远远超过对方。
-
此外,作者还探究了RoI-aware中池化大小的影响。
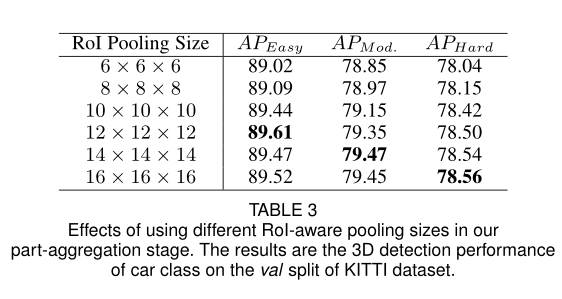
从上表可以看出,当池化大小大于 12 × 12 × 12 12 \times 12 \times 12 12×12×12的时候,基本可以获得差不多的性能。
-
作者还探究了池化之后不同特征提取方法的区别,即使用全连接层还是使用稀疏卷积层来提取池化后的特征.
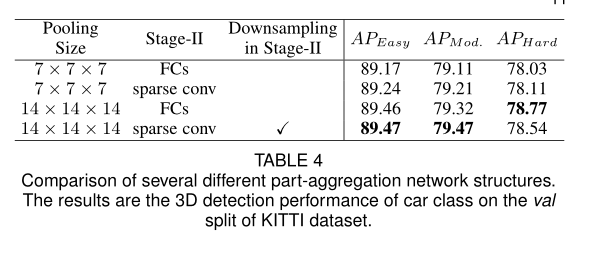
从上表可以看出,使用稀疏卷积和全链接层可以获得相似的性能,但是稀疏卷积所获得精度要高一些.
-
作者还对比了不同阶段的网络性能
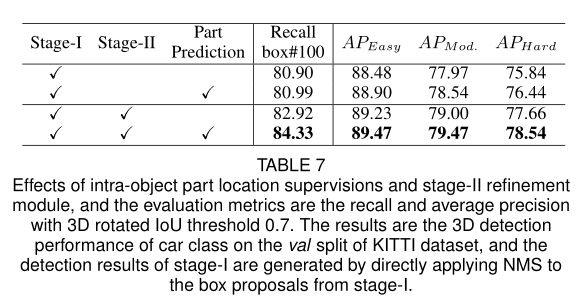
从上表中可以看出,第一行和第二行体现了使用Part预测对于网络性能的影响,第一三行和第二四行展示了所提第二阶段的有效性.
-
作者还展示了使用不同的指标来作为NMS排名的对于网络性能的影响
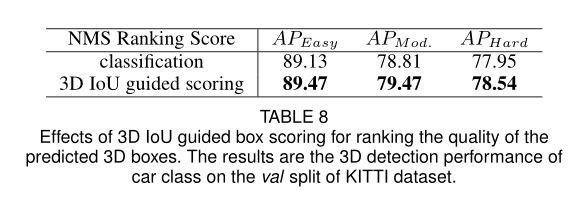
表中展示了使用分类分数和IoU作为指导的分数.从表中可以看出,使用IoU guided的方法可以大幅的提高模型的检测性能.提高了0.7个点.这个和TOOD的指标有点像.














 1587
1587











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









