







目录
1.FCN网络简介
首个端对端的针对像素级预测的全卷积网络。全卷积网络即将分类网络中的全连接层全部替换为卷积层。
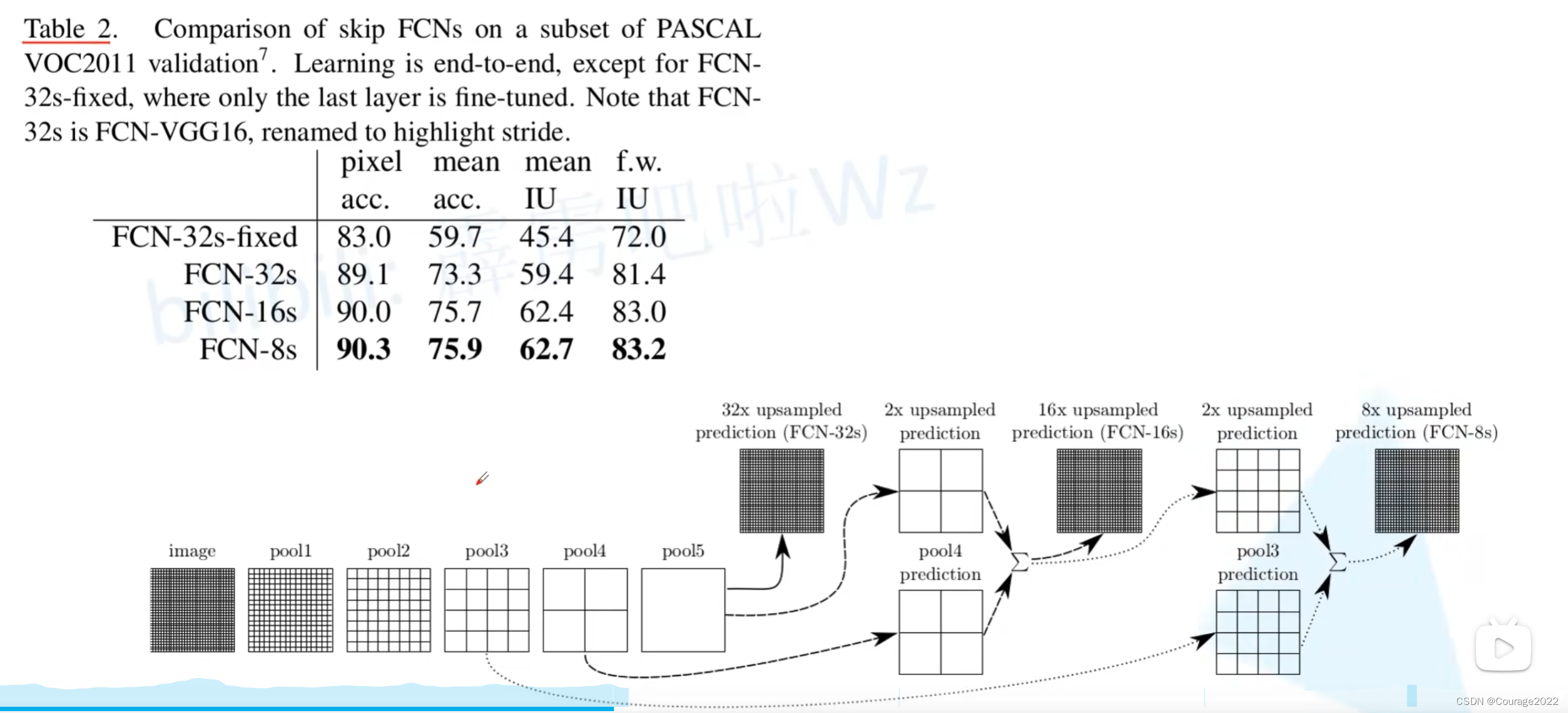
从数据可以看出,它的性能十分优秀!
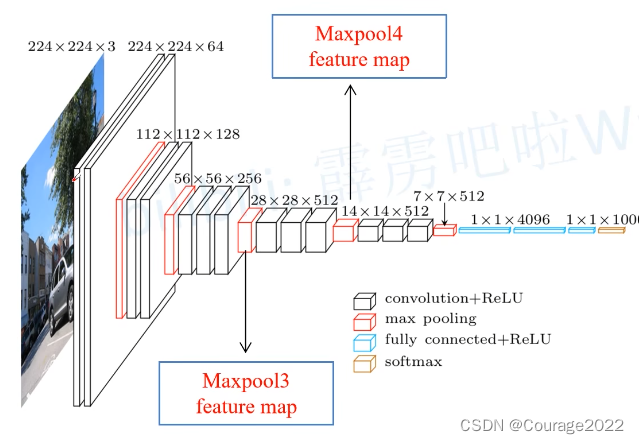
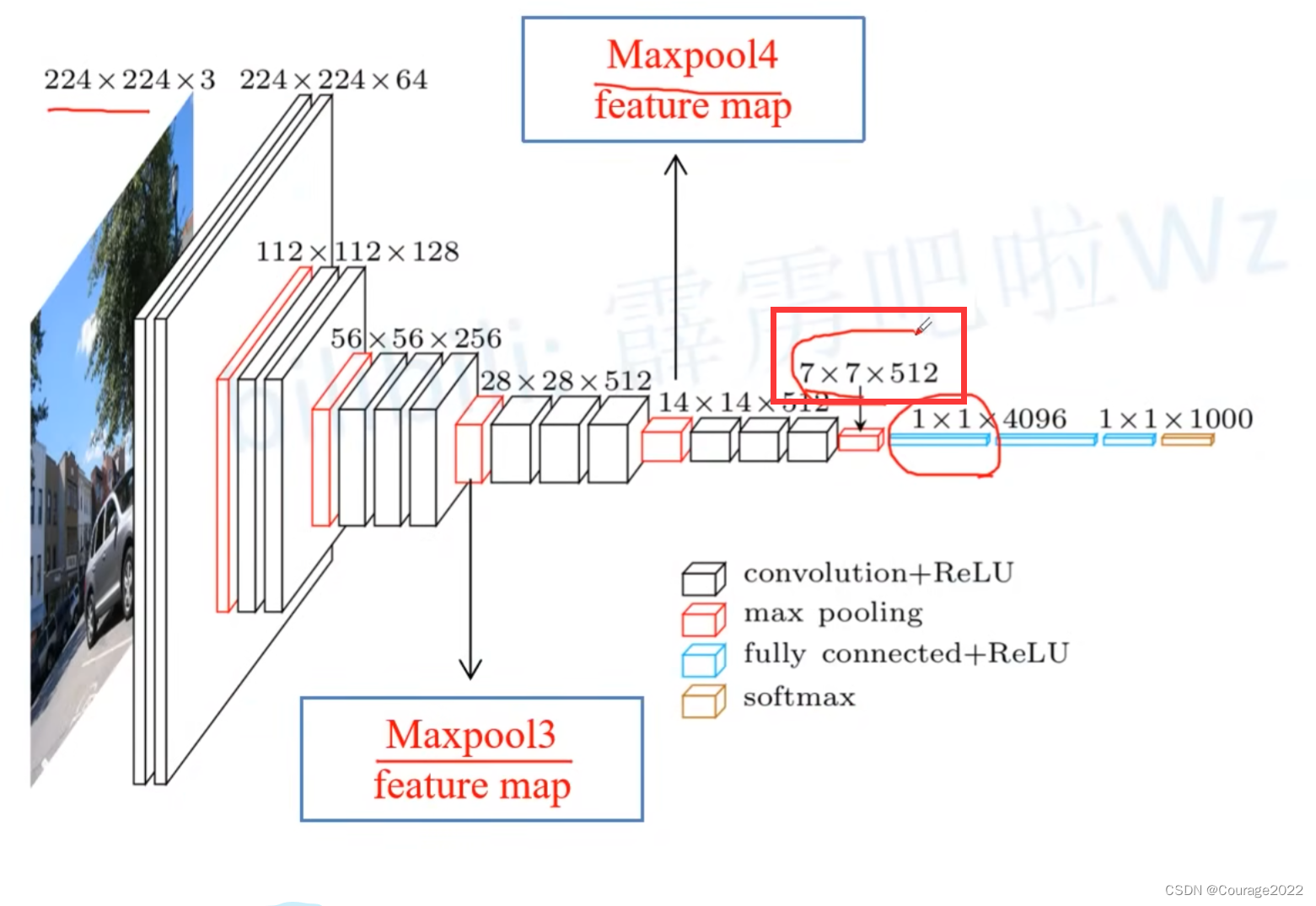
从左图可以看到,其实就是一系列卷积和下采样的过程最后得到一个21个channel的特征层,我们再对其进行一个上采样就得到和原图一样大小的一个特征图,针对这里所得到的特征图的每个像素(每个像素都有21个channel)进行softmax处理,这样我们就能得到该像素对于每个类别的预测概率,取概率最大的为该像素的预测类别。这就是FPN的大致思想。
接下来我们看一下论文中有关于Convolutionalization的过程:
一般的深度学习网络都是一些卷积层池化层,最后加几层全连接层输出预测概率。如上图,我们的最后三个层就是全连接层的输出(4096、4096、1000)。比如我们输入一张图片,通过我们的分类网络最后会得到一个针对1000个类别的预测值,在这1000个预测值经过softmax处理后就能得到针对每个类别的概率,其右图是对1000个预测值进行了一个可视化,预测概率越大其高度越高。
另外,我们在之前说过,对于全连接层来说我们要求的输入节点个数是固定的,如果全连接层输入节点发生变化会导致报错,因此我们在输入分类网络时输入图片的大小都是固定的。
在FCN网络中我们将全连接层转化成卷积层,那么是不是网络对图像的输入大小就没有什么限制了呢?可以
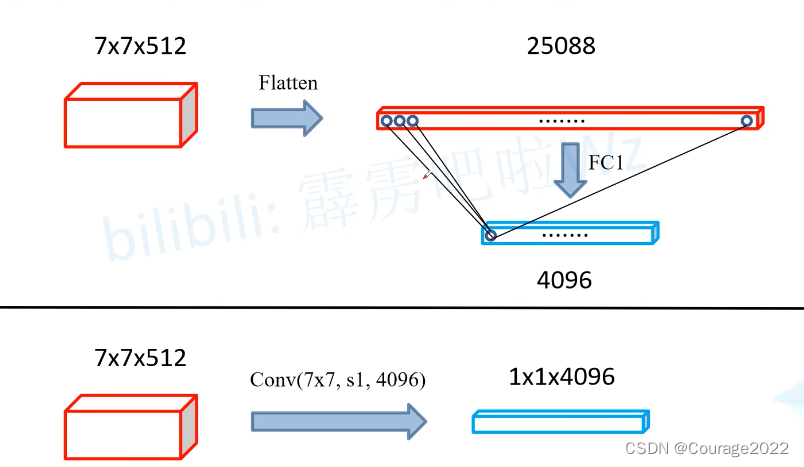
回顾一下VGG-16模型
它们的参数都是一样的,对于展平成全连接层,我们有25088*4096=102760488个参数,对于利用卷积,我们有7*7*512*4096=102760448个参数,因此我们可以将全连接层得到的4096个参数进行一个reshape处理直接赋值给卷积层使用。通过这个步骤我们可以实现Convolutionalization。
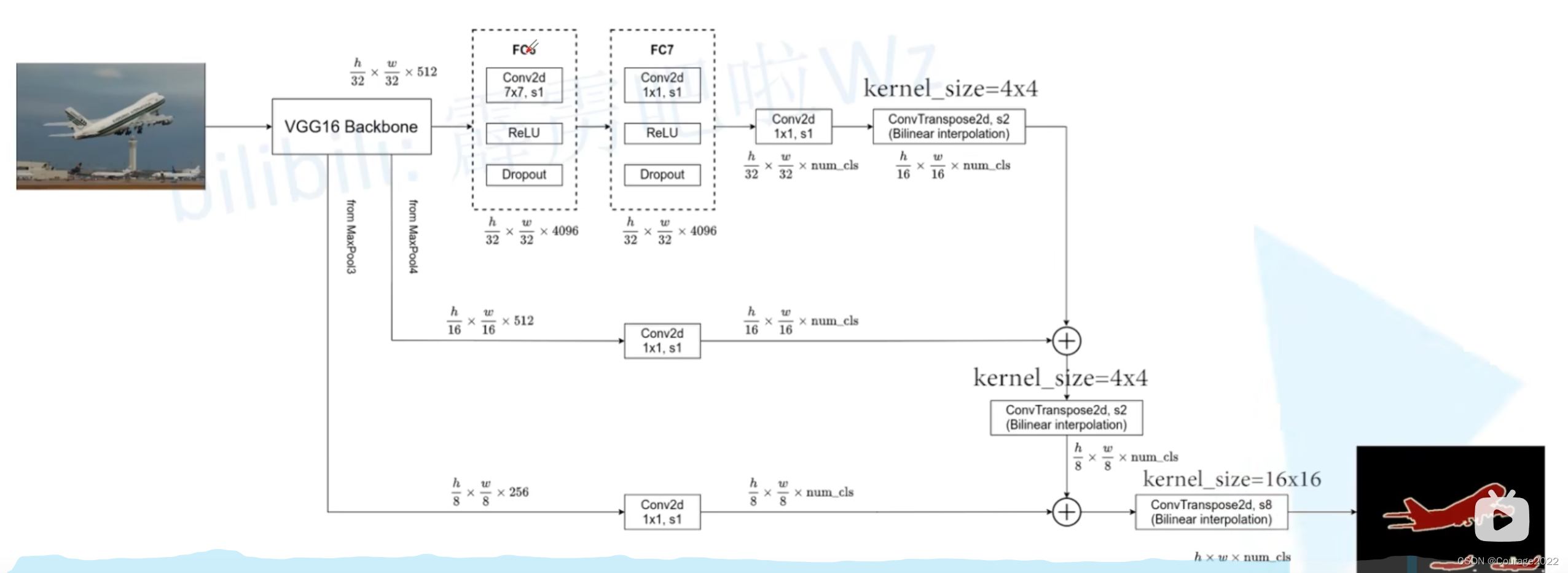
这里32s、16s、8s是指上采样了多少倍,比如这里的32s代表将预测结果上采样了32倍还原成了我们的原图大小。


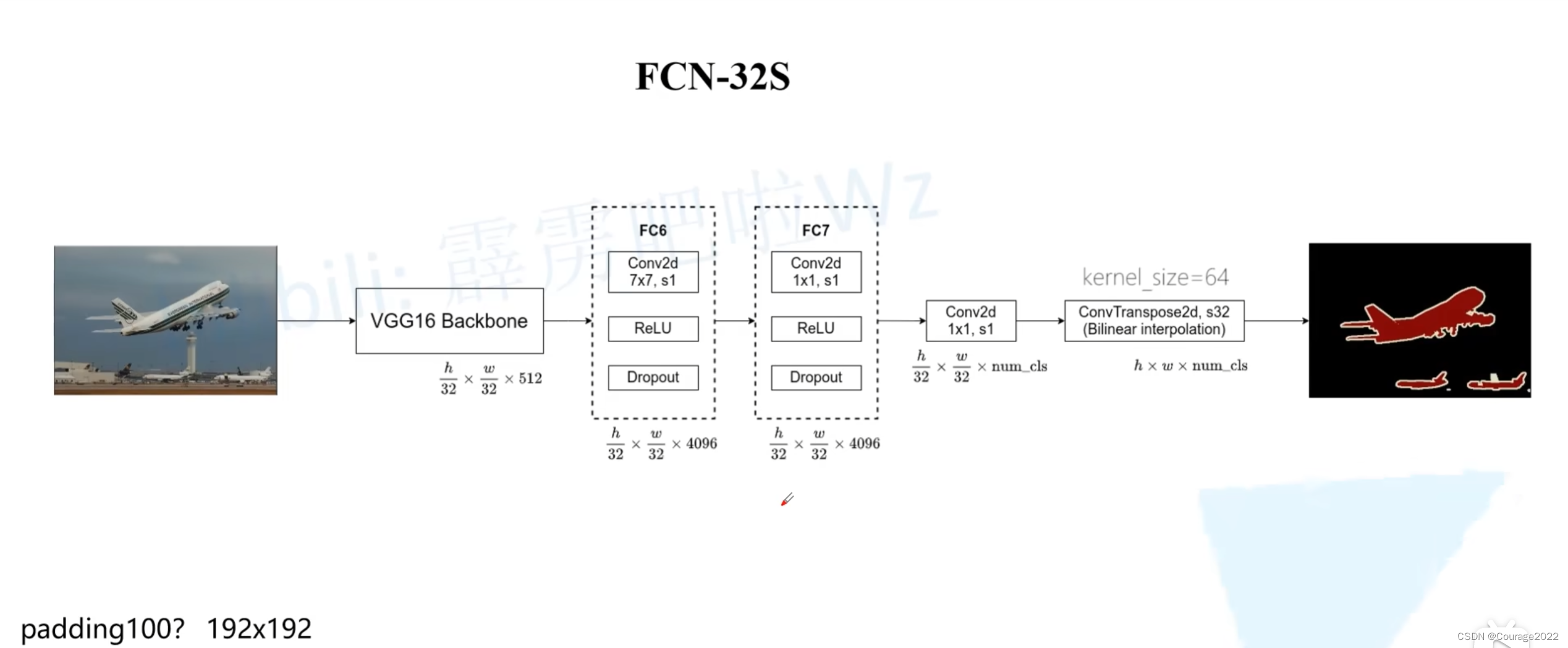
2.FCN-32S
原论文中它所对应的源码在backbone的第一个全连接层处将padding设置为100。作者给出的解释是让FCN网络适应不同大小的图片而设置的,如果我们不做这个100padding会怎么样呢?
如果我们的图片大小是小于
的话,通过我们的VGG模型的backbone到上图位置它的高和宽就小于7了,小于7会面临什么问题?
我们将第一个全连接层FC6进行Convolutionalization后将其转化成了卷积核大小为
的卷积层,那么我们通过backbone得到的特征图的高和宽小于7的话,假设我们这里的padding是为0的,FC6会报错。但我们现在想想,现在像素动不动就一亿....好像没什么必要。
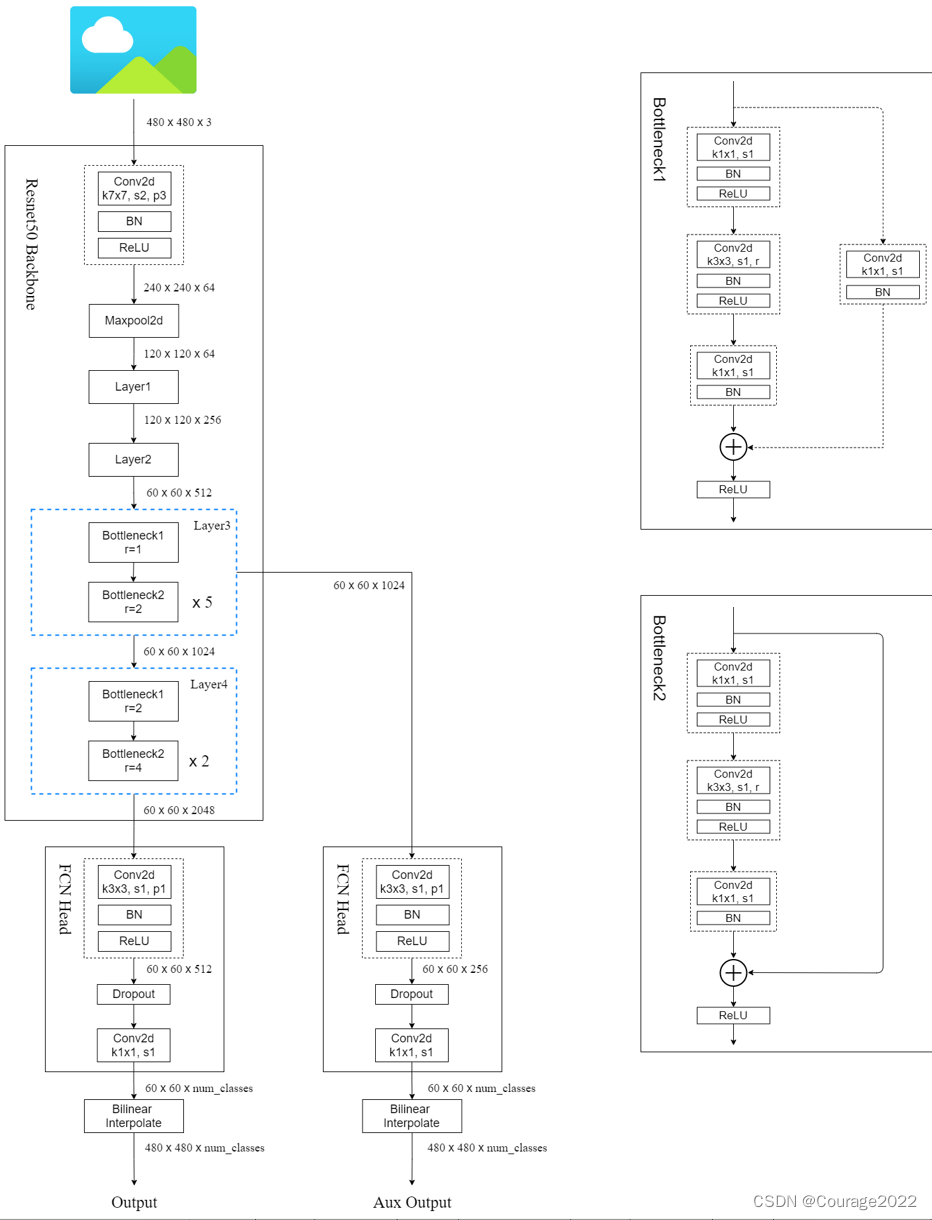
VGG16 backbone对应着这部分:即从图片输入一直到全连接层之前的部分。
我们将第一个和第二个全连接层全部进行了Convolutionalization,这里的FC6和FC7就对应了这两个卷积层。
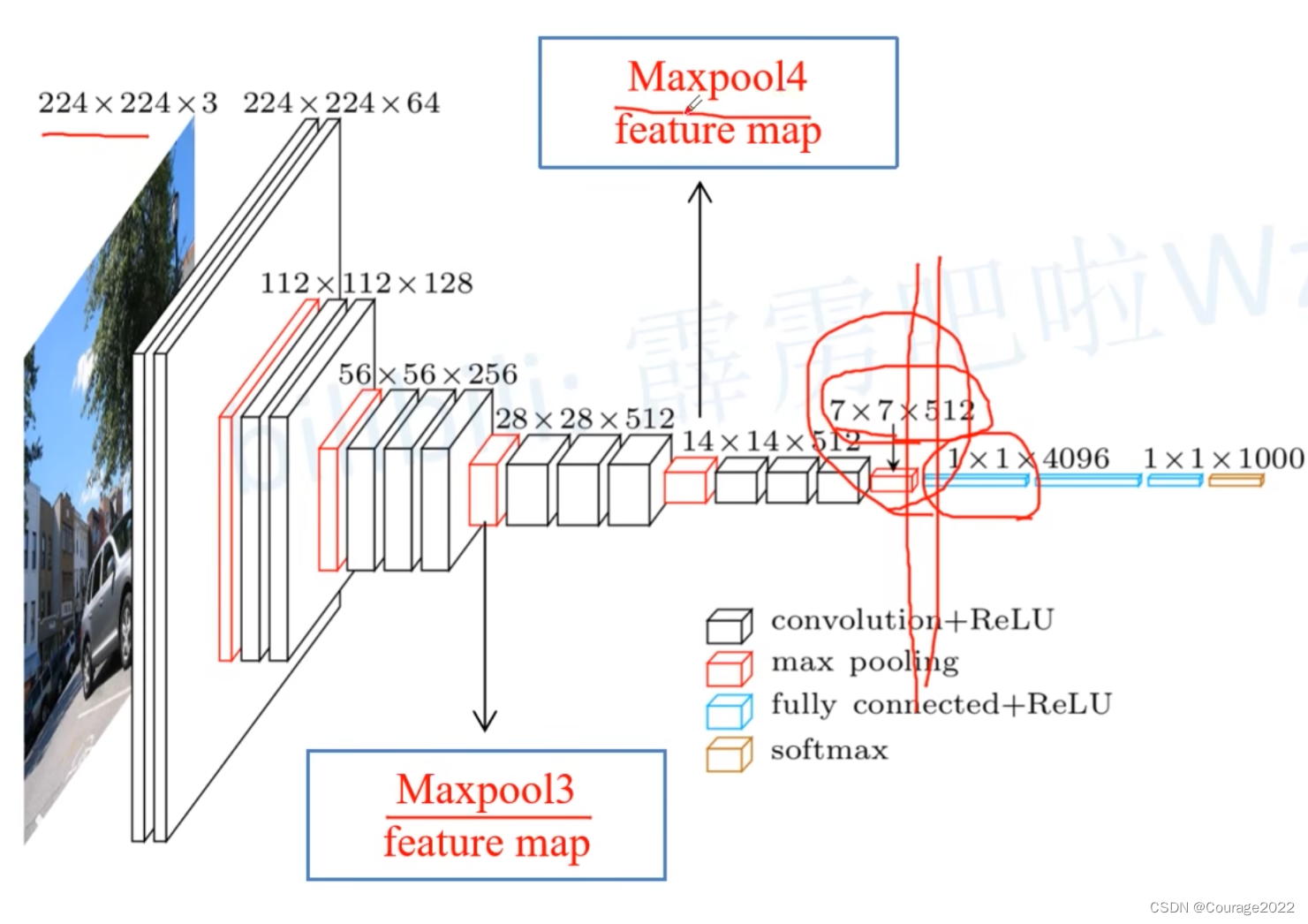
我们通过分类网络将图片的高和宽下采样32倍,因此我们输入一张图片后通过我们的backbone得到的输出特征图的尺寸为
,由于我们的FC6卷积层我们将padding设置为3了,经过FC6不会改变特征图的高和宽了,由于我们使用了4096个卷积核,因此我们的输出是
,FC7对应的卷积核大小是
的,因此输出特征矩阵不会变化。后面我们又加了两个卷积层:
第一个卷积层是
的,它的卷积核个数是与我们分类的类别是一样的(包含背景)。
第二个卷积层是一个转置卷积,我们会上采样32倍,会恢复到原图的大小,现在它的特征图的大小是
,即对于每个像素,它有num_cls个通道,我们对其进行softmax处理就能得到针对每个像素的预测类别了。
我们的权重如何训练:在VGG16网络基本是进行迁移学习的(卷积层 + FC6 + FC7),我们仅仅只是在后面加上了一个
是不是我上我也行!!!好简单啊!!!
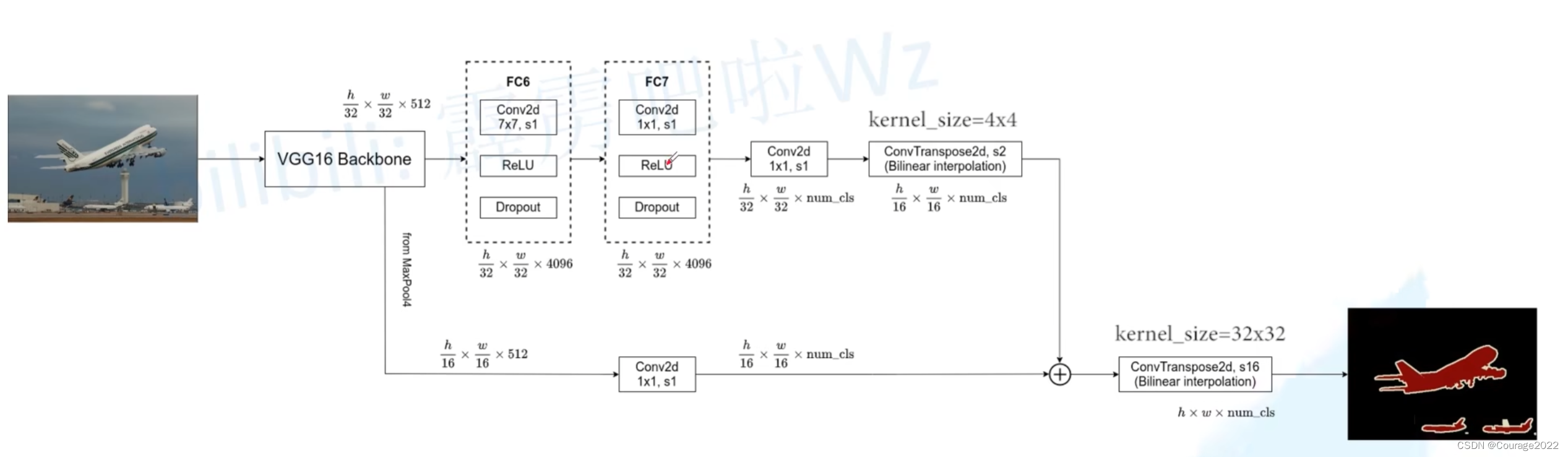
3.FCN-16S
我们到这里之前是和前面没有发生变化的:
不同在之后的第二个卷积层,我们在FCN-32S中直接上采样了32倍得到原图像尺寸,而在FCN-16S中的第二个卷积层我们仅仅上采样了两倍。此外我们还利用VGG16中的MaxPool4层输出的特征图,它的高度和宽度是原图像的十六分之一。
在后面接上一个
我们对这两个卷积层进行相加操作,再通过一个转置卷积上采样16倍就可以得到原图的大小。
4.FCN-8S
和上面同理,不再赘述。
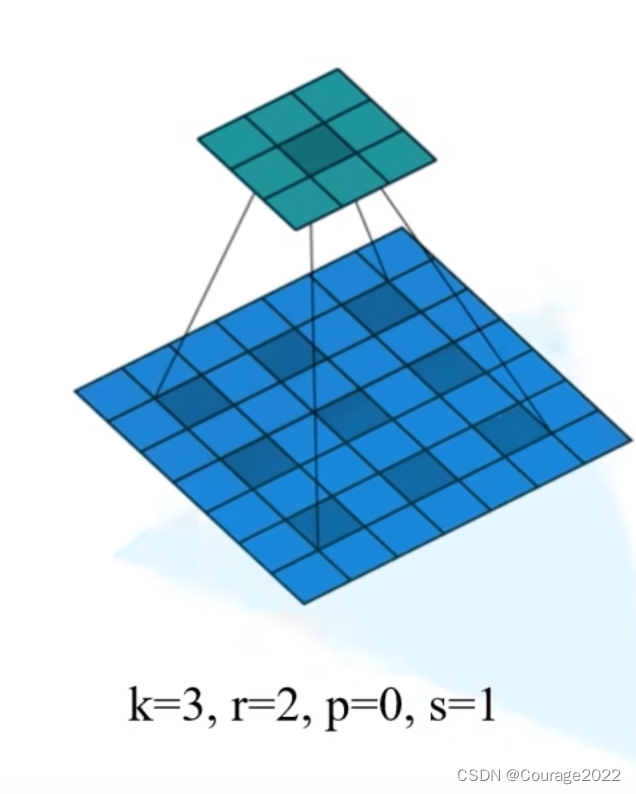
5.膨胀卷积(空洞卷积)
卷积的元素之间存在一定的间隙(膨胀因子
决定),膨胀卷积可以增大我们的感受野还会保持我们原输入特征图的
。
为什么要使用膨胀卷积:
在语义分割中,通常会使用分类网络作为我们网络的backbone,通过backbone后会对我们图像进行一系列的下采样,再通过一系列的上采样还原回我们的原图的大小。平时在使用分类网络中我们通常都会将高度宽度下采样32倍,由于我们后续需要通过上采样还原回原图的尺寸的,因此如果下将特征图采样倍率太大的话对我们还原回原图是有很大的影响的。比如最大池化操作我们会丢失一些细节和比较小的信息,丢失这些信息后我们是无法通过上采样恢复的,这也就导致语义分割中分割效果不是很理想。
这时就可以采用膨胀卷积了,又可以增加我们的感受野,还可以保证原输入特征图的高宽不变。
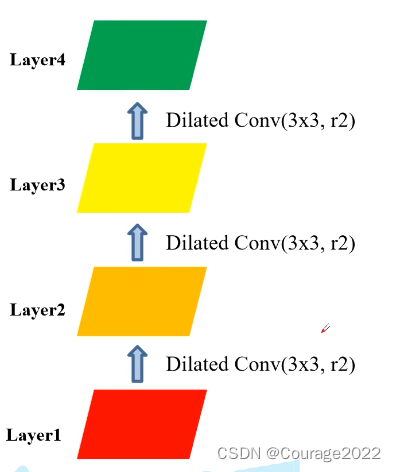
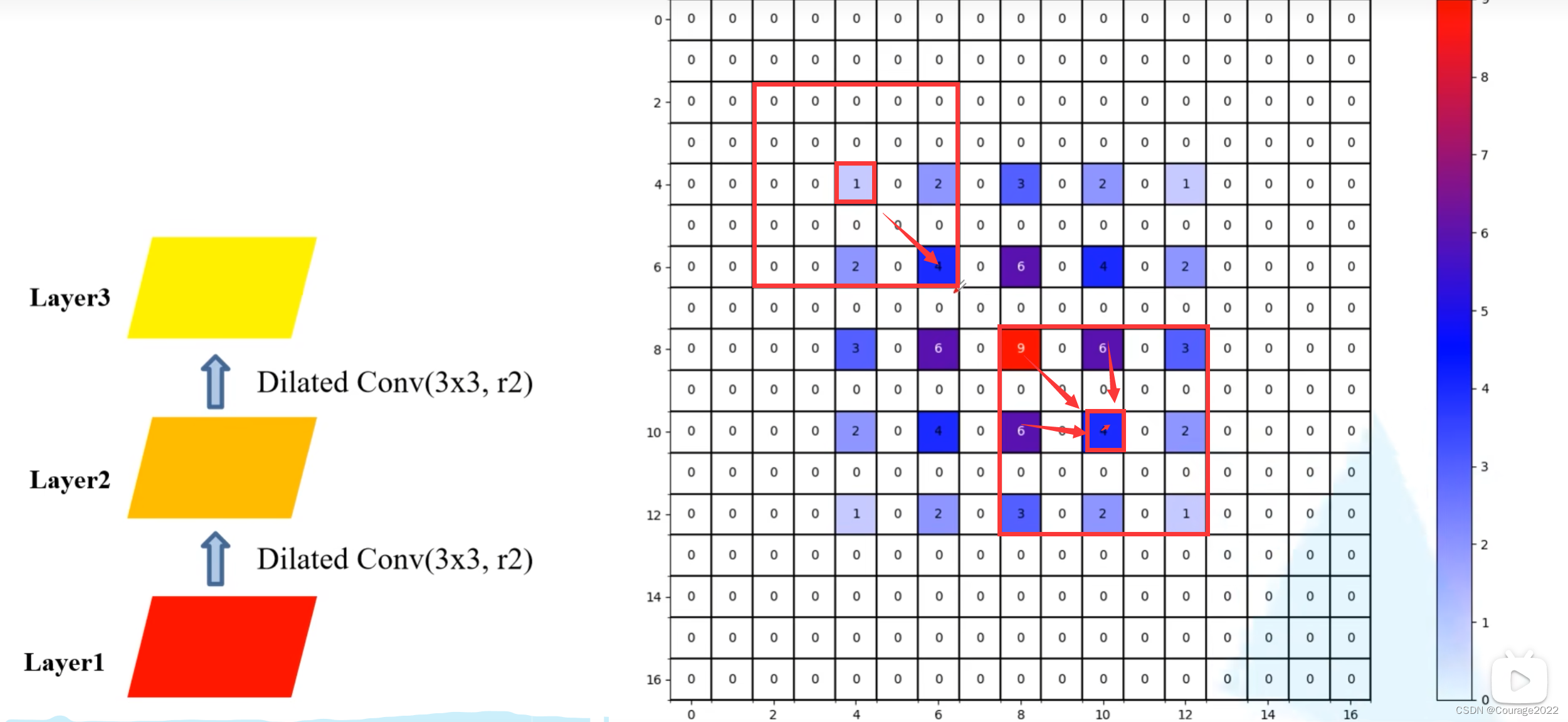
gridding effect问题:
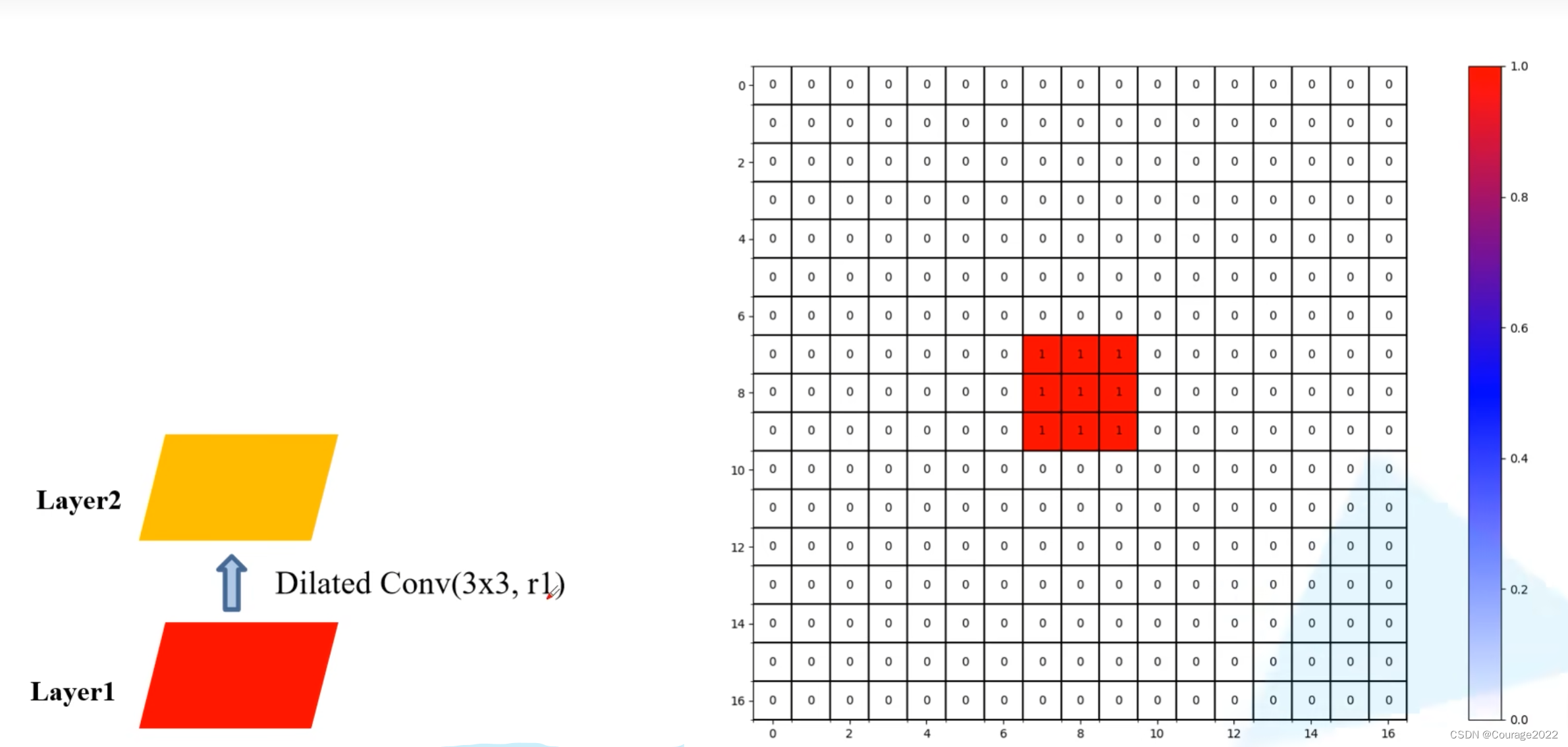
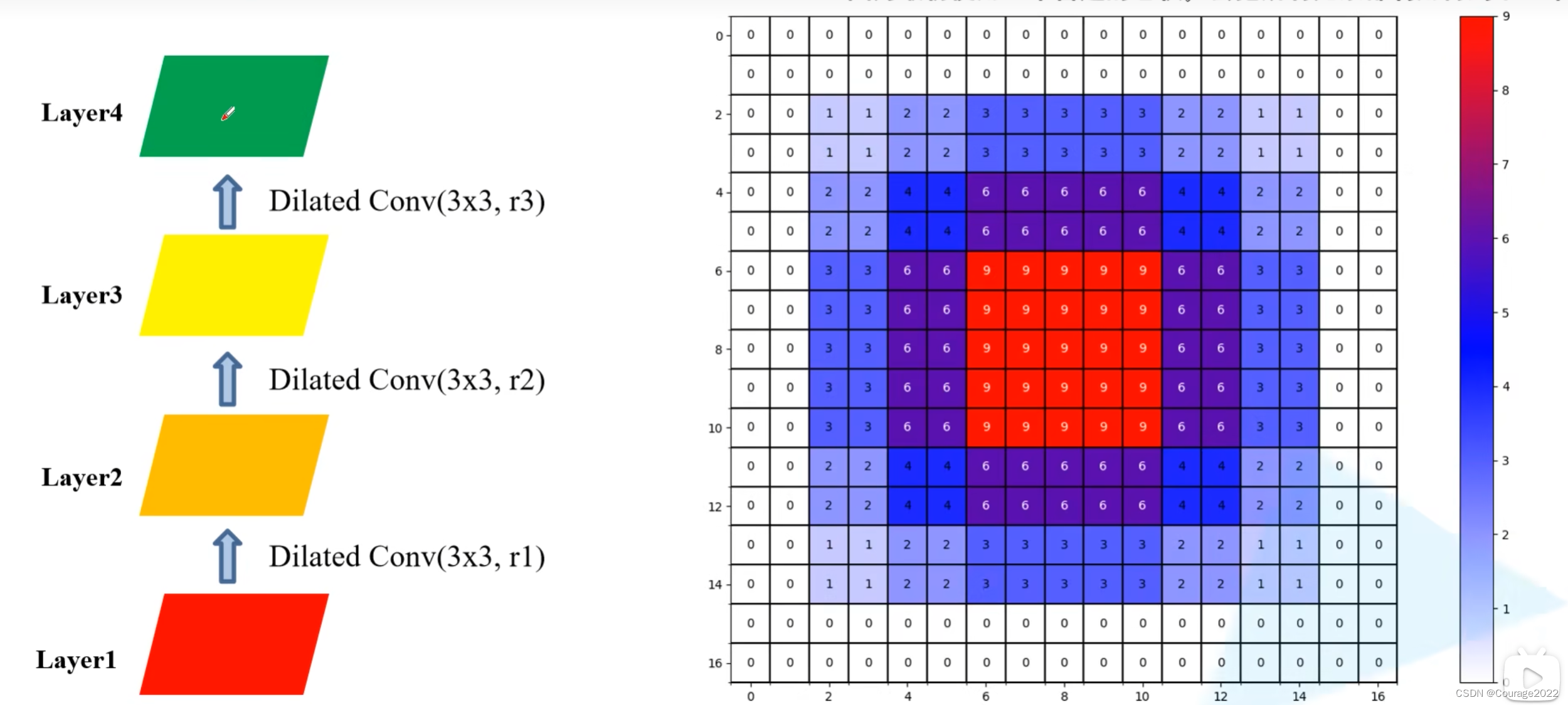
我们假设使用三个膨胀卷积层
卷积大小都是
的,膨胀系数
layer3上:
layer4上:
我们发现在layer4中利用到layer1中的数据不是连续的,在每个非零元素之间都是有一定间隔的,会导致我们丢失一定的细节信息,因此在使用膨胀卷积的时候我们要避免这样的问题。
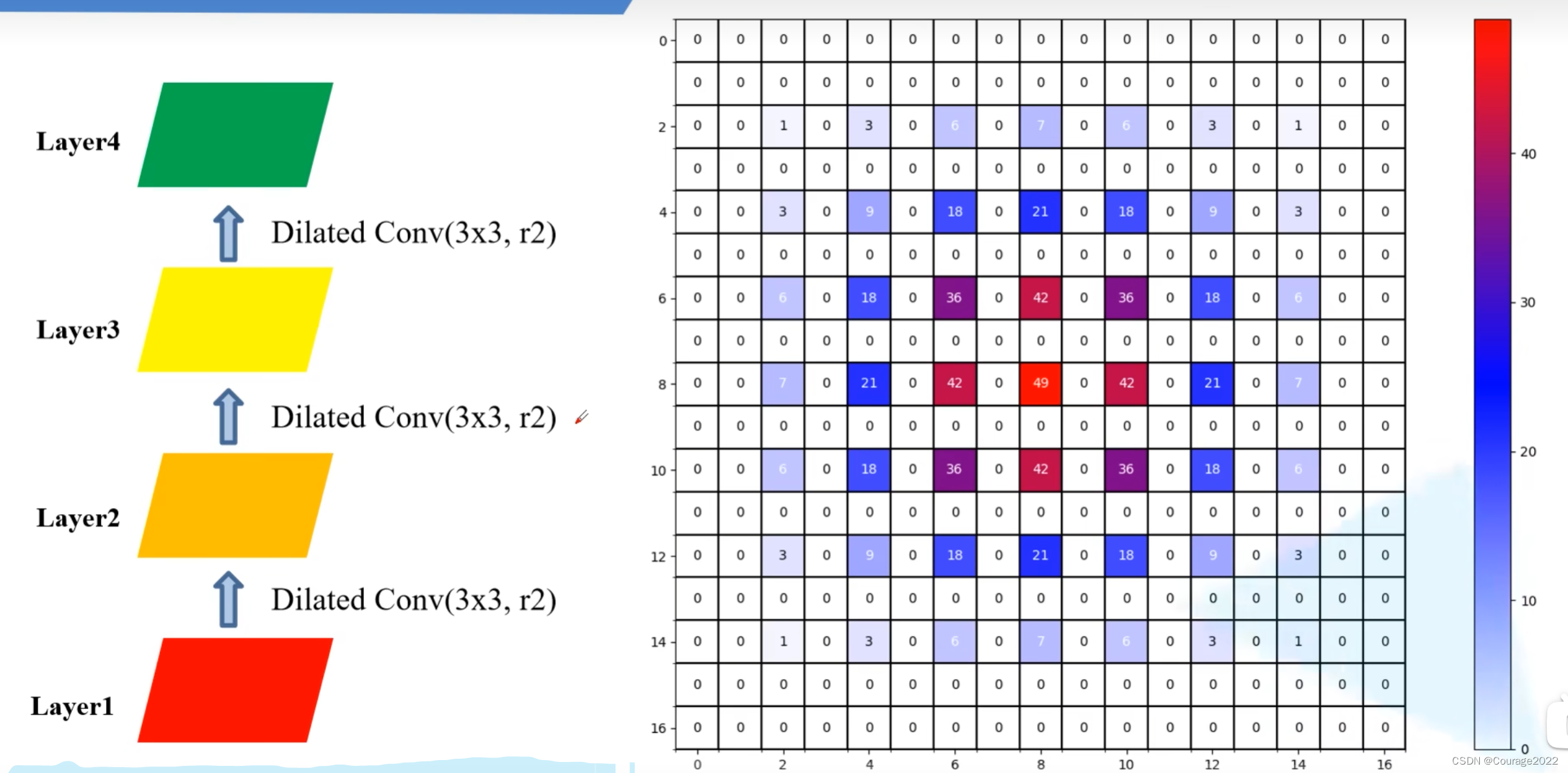
如果我们将膨胀系数设置为1、2、3会发生什么呢?
在layer2上:
在layer3上:
layer4上:(最终感受野
)
这两组实验中,卷积核的大小是一样的,但第二次实验中更能体现出应用信息的完整性!
如果我们都使用普通卷积的话:(感受野
在参数相同的条件下,我们的感受野增大了很多!
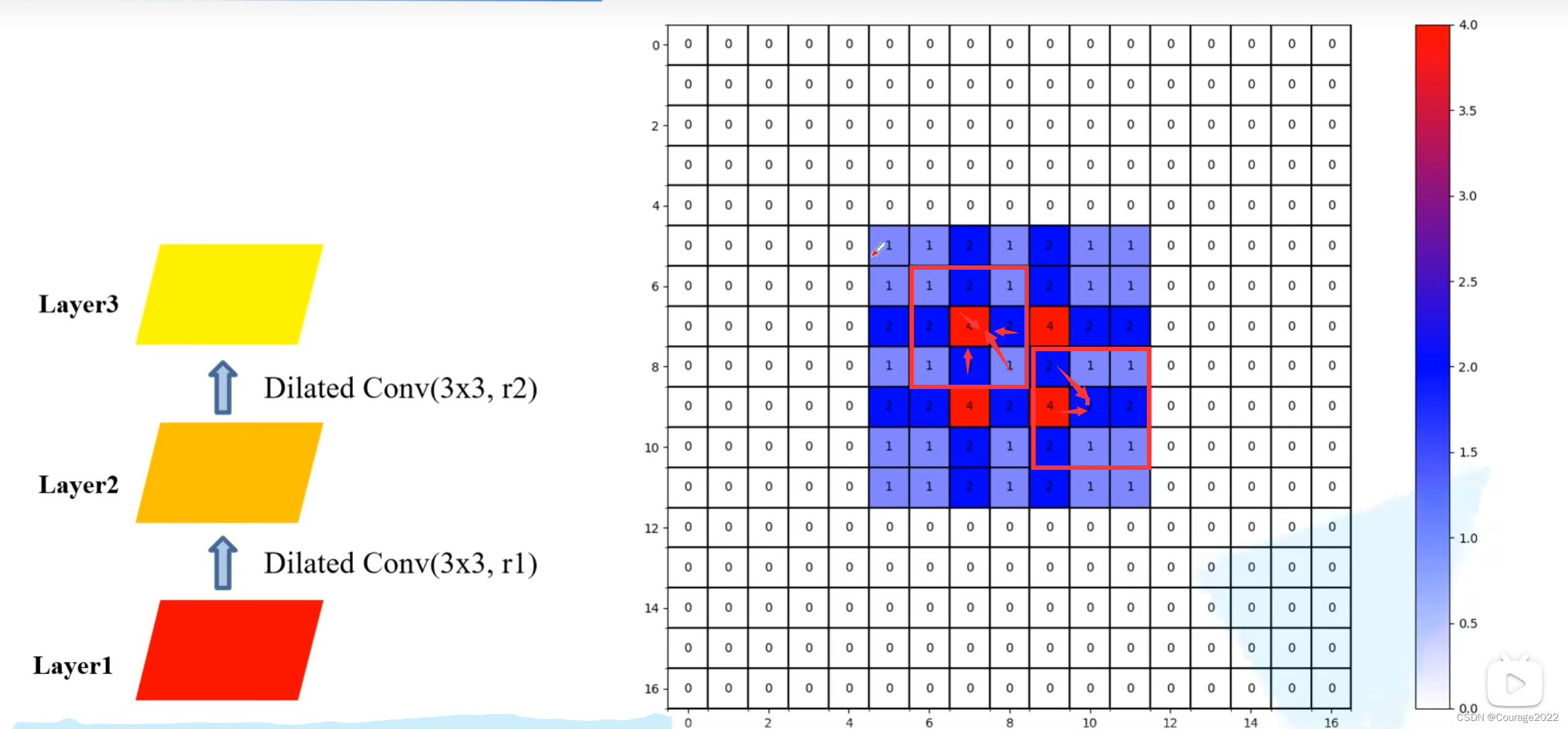
让我们现在来说一下当我们使用多个膨胀卷积的时候,我们如何选取膨胀系数:
这里每个膨胀卷积对应的膨胀系数为:
,HDC的目标是通过一系列的膨胀卷积之后能够完全覆盖底层特征层的方形区域,即方形区域中间没有任何孔洞。
第
层对应两个非零元素最大距离等于三个元素取最大值。
是第
是第
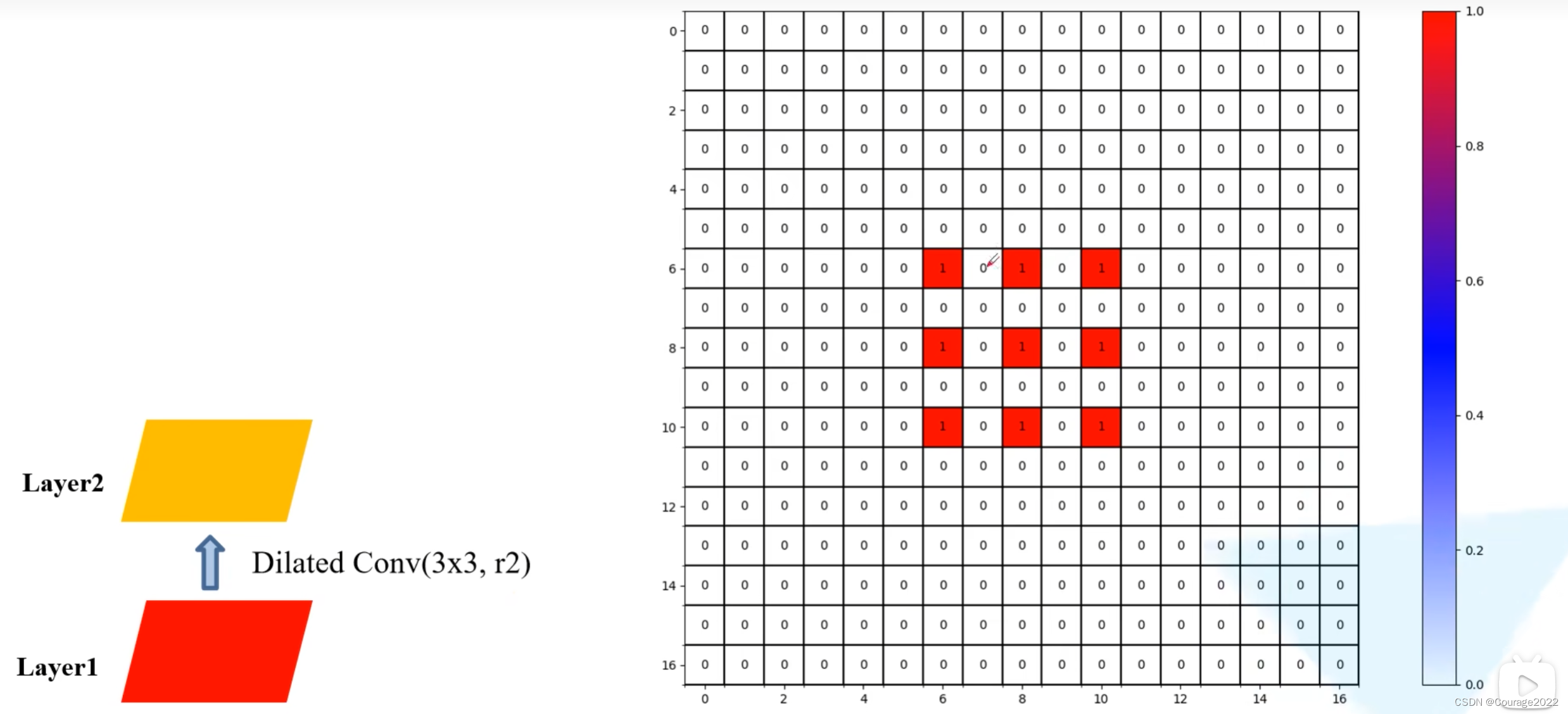





















 1371
1371











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











