









SPD-Conv:解决步长卷积和池化层导致的细粒度信息丢失
提出背景
论文:https://arxiv.org/pdf/2208.03641v1.pdf
代码:https://github.com/labsaint/spd-conv

文章提出一个新的卷积神经网络(CNN)构建块,称为SPD-Conv,旨在替代传统CNN架构中的步长卷积和池化层,以提高在处理低分辨率图像和小对象时的性能。
- 问题: CNN在处理低分辨率图像和小对象时性能下降的问题,指出这一问题根源于使用步长卷积和池化层导致的细粒度信息丢失。
解法:SPD-Conv = SPD层 + 非步长卷积层:
-
空间到深度(SPD)层: 一个转换层,将输入图像的空间维度转换为深度维度,从而在不丢失信息的情况下增加特征图的深度。
之所以使用SPD层,是因为在处理低分辨率图像和小对象时,需要保留尽可能多的空间信息。
SPD层通过将空间维度的信息转换为深度维度,避免了传统步长卷积和池化操作中的信息丢失。
-
非步长卷积层: 在SPD转换后应用的卷积层,不使用步长,以保留细粒度信息。
在SPD层之后应用非步长卷积层,是因为非步长卷积能够在不减少特征图尺寸的情况下进行特征提取,进一步保持了图像的细粒度信息,这对于提高低分辨率图像和小对象的识别性能至关重要。
假设我们有一个低分辨率的图像,其中包含几个小的物体,我们需要对这些物体进行识别和分类。
在传统的CNN架构中,如果我们直接应用步长卷积和池化层,随着网络层次的加深,图像的空间分辨率会逐渐减少,导致小物体的细节信息丢失,从而使得网络难以准确识别这些小物体。
使用 SPD-Conv 代替 步长卷积和池化层:
-
空间到深度(SPD)层的应用:
- 初始特征图尺寸为 ( 32 × 32 ) (32 \times 32) (32×32),包含小物体的细节信息。
- 应用SPD层后,假设将空间分辨率降低为 ( 16 × 16 ) (16 \times 16) (16×16),同时将这部分减少的空间信息转移到通道维度上,从而通道数增加但没有信息丢失。
- 这样,原本在 ( 32 × 32 ) (32 \times 32) (32×32) 分辨率上分散的细节信息,现在被压缩和保留在更深的通道中。
-
非步长卷积层的应用:
- 经过SPD层处理后,特征图的尺寸变为 ( 16 × 16 ) (16 \times 16) (16×16),但通道数增加,假设从原来的64通道增加到128通道。
- 在这个增加通道数的特征图上应用非步长卷积层,这个卷积层不减少特征图的空间尺寸,而是通过学习这些增加的通道中的信息来提取重要特征。
- 这样,即使是在较小的空间分辨率上,模型也能有效捕捉到小物体的细节信息。
这种结合使用SPD层和非步长卷积层的方法,使得CNN能够更好地处理小物体和低分辨率图像中的挑战,提高了模型在这些复杂场景下的性能和鲁棒性。
SPD-Conv
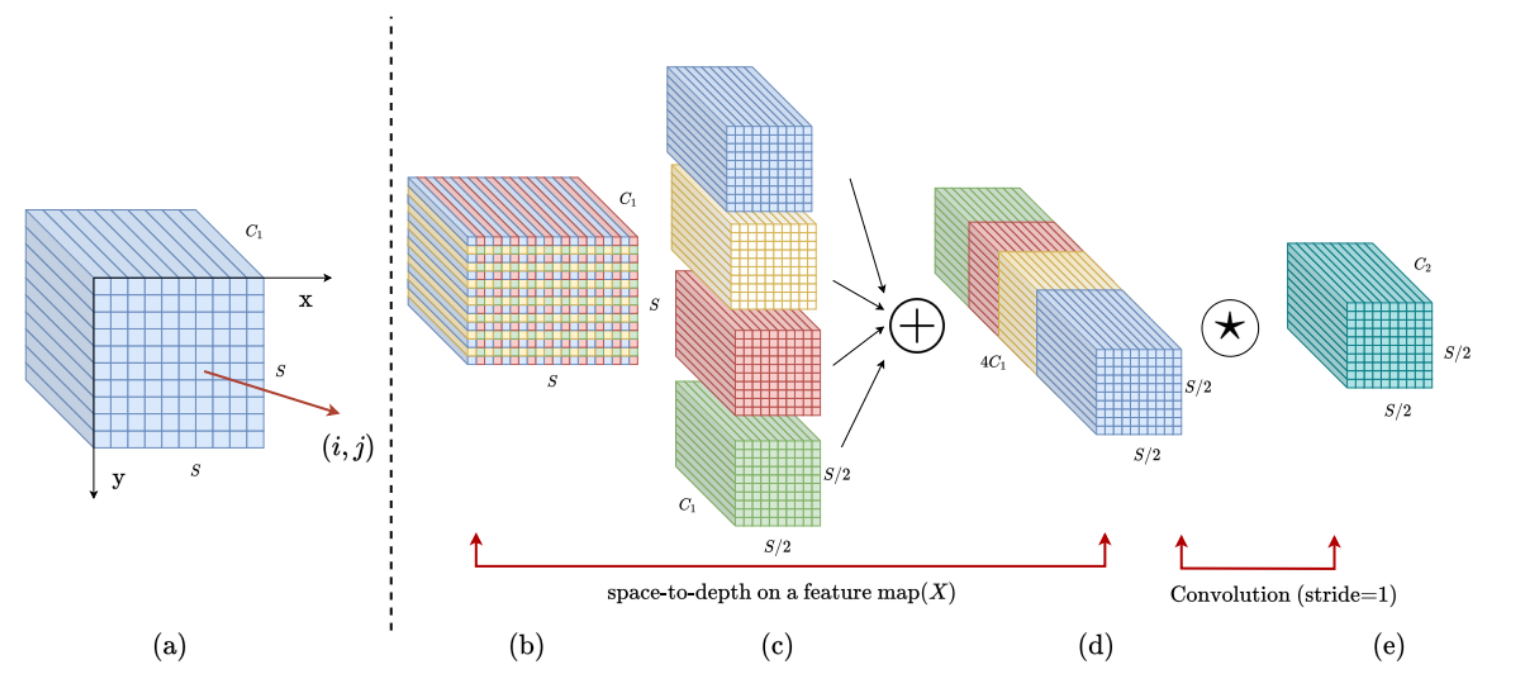
当尺度为2时的SPD-Conv图:
- (a)显示了标准的特征图
- (b)展示了空间到深度操作,其中空间信息被重新排列到深度通道
- (c)显示了结果特征图的深度增加
- (d)表示在SPD操作之后应用的非步长卷积层
- (e)展示了经过步长为1的卷积后的输出特征图,该特征图保持了空间分辨率但改变了深度维度
-
空间到深度(SPD)层 - 特征图切片阶段:
- 从中间特征图 ( X ) 开始,大小为 S × S × C 1 S \times S \times C_1 S×S×C1。
- 使用
scale因子进行下采样,将 ( X ) 划分为 scale 2 \text{scale}^2 scale2 个子特征图 f x , y f_{x,y} fx,y。每个子特征图是 ( X ) 的一部分,其中 X ( i , j ) X(i, j) X(i,j) 中的索引 ( i ) 和 ( j ) 被scale整除。 - 这个阶段通过降低特征图的空间分辨率来增加特征图的深度(通道数)。
-
子图串联阶段:
- 这些子特征图沿通道维度合并,形成新的特征图 X 0 X_0 X0。
- X 0 X_0 X0 的空间维度是原来的 1 scale \frac{1}{\text{scale}} scale1,但通道维度增加了 scale 2 \text{scale}^2 scale2 倍。
- 这一阶段保持了原始特征图 ( X ) 中的全部信息,即使其空间分辨率减小。
-
非步长卷积层阶段:
- 接着对 X 0 X_0 X0 应用步长为1的卷积层,这意味着特征图的每个像素都会被卷积核覆盖,没有信息被跳过。
- 使用的过滤器数量 C 2 C_2 C2 少于 X 0 X_0 X0 的通道数 scale 2 C 1 \text{scale}^2 C_1 scale2C1,目的是提取重要的特征并降低通道维度。
- 结果得到特征图 X 00 X_{00} X00,其空间维度保持不变,但通道维度减少到 $C_2$。
假设我们有一个中间特征图 ( X ) 的大小为
8
×
8
×
3
8 \times 8 \times 3
8×8×3(宽、高、通道),scale 设定为2。
-
特征图切片(SPD层之前) - 我们将 ( X ) 切分为四个 4 × 4 × 3 4 \times 4 \times 3 4×4×3 的子特征图 f 0 , 0 , f 1 , 0 , f 0 , 1 , f 1 , 1 f_{0,0}, f_{1,0}, f_{0,1}, f_{1,1} f0,0,f1,0,f0,1,f1,1。
-
子图串联(SPD层) - 然后将这四个 4 × 4 × 3 4 \times 4 \times 3 4×4×3 的子特征图沿通道维度合并,形成一个新的特征图 X 0 X_0 X0 的大小为 4 × 4 × 12 4 \times 4 \times 12 4×4×12。
-
非步长卷积(非步长卷积层) - 在 X 0 X_0 X0 上应用步长为1的卷积层,假设使用8个过滤器,则最终输出特征图 KaTeX parse error: Expected '}', got 'EOF' at end of input: X_{00 的大小为 4 × 4 × 8 4 \times 4 \times 8 4×4×8。
通过这个链条,原始的特征图 ( X ) 经过一系列变换后,空间分辨率降低,但通道数增加并在非步长卷积后得到更有判别性的特征表示。
这种方法尤其适用于小对象检测和低分辨率图像分类,因为它通过增加通道深度来保留更多的信息,而非过减少像素点数来损失信息。
YOLO v5 SPD-Conv版:

- 红色框标出的部分是使用SPD-Conv构建块替换了原有步长为2的卷积层的位置。
- 结构被分为三个主要部分:骨干网络(Backbone)、颈部网络(Neck)和检测头(Head)。
- 骨干网络负责特征提取,颈部网络用于特征融合和处理,头部网络执行对象的分类和定位。
YOLOv5-SPD通过用SPD-Conv构建块替换YOLOv5中的步长为2的卷积层:
- SPD层替换: 在YOLOv5和ResNet中,将所有步长为2的卷积层替换为SPD-Conv构建块,因为这些步长卷积层导致特征图下采样,可能会丢失低分辨率图像和小尺寸物体的重要信息。
- 池化层移除: 对于低分辨率图像,移除最大池化层是合理的,因为在这些情况下,下采样可能不是必要的,且进一步的下采样可能导致更多信息的丢失。
- 可伸缩性设计: 通过调整非步长卷积层中的滤波器数量和C3模块的重复次数,可以根据需要轻松地放大或缩小模型,这是为了满足不同应用或硬件的需求。

YOLOv5-SPD-m能够检测到YOLOv5m漏检的被遮挡的长颈鹿。
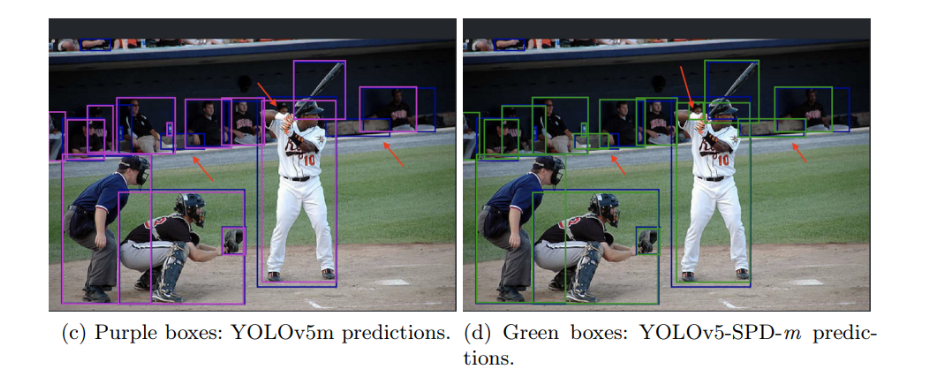
)进一步展示了YOLOv5-SPD-m在检测非常小的对象(一个面孔和两个长凳)方面的能力,而YOLOv5m则未能检测到这些对象。
YOLO v5 小目标改进
改好的代码:https://github.com/labsaint/spd-conv
也可以自己调一下,有时候我们还得组合改进。
YOLO v5:https://github.com/ultralytics/yolov5
-
定义
SPD模块:确保你已经在models/common.py中定义了SPD`类。 -
导入
SPD模块:在yolo.py的顶部导入SPD类。from models.common import SPD -
修改
parse_model函数:在parse_model函数中处理SPD模块的情况。找到
parse_model函数,并在其中添加处理SPD的逻辑。例如,如果你的模型配置文件中有指示使用
SPD的地方,你需要检测它并相应地构造模块。 -
更新模型配置文件:你可能需要在YOLOv5的模型配置文件(通常是
.yaml格式)中指明哪些卷积层应该被SPD替换。例如,你可能会在配置文件中添加一个新的模块类型
- SPD。 -
替换卷积层:在
parse_model中添加逻辑,以便在解析模型时用SPD`模块替换步长为2的卷积层。
定义 SPD-Conv
在 yolov5/models/common.py 添加 SPD-Conv 代码
import torch
import torch.nn as nn
class SPD(nn.Module): # SPD 层
"""
这个模块实现了空间到深度的操作,它重新排列空间数据块到深度维度,
通过块大小增加通道数并减少空间维度。在卷积神经网络中常用此方法保持
下采样图像的高分辨率信息。
"""
def __init__(self, block_size=2):
"""
初始化 SPD 模块。
参数:
block_size (int): 每个块的大小。它定义了空间维度的下采样因子。
输出通道的数量将增加 block_size**2 倍。
"""
super(SPD, self).__init__()
self.block_size = block_size # 块大小
def forward(self, x):
"""
在输入张量上应用空间到深度操作。
参数:
x (torch.Tensor): 形状为 (N, C, H, W) 的输入张量。
返回:
torch.Tensor: 重新排列块后的输出张量。如果块大小为 2,
输出张量的形状将为 (N, C*4, H/2, W/2)。
"""
N, C, H, W = x.size() # 输入张量的维度
block_size = self.block_size # 块大小
# 确保高度和宽度可以被 block_size 整除
assert H % block_size == 0 and W % block_size == 0, \
f"空间维度必须能被 block_size 整除。得到的 H: {H}, W: {W}"
# 将空间块重新排列到深度
x_reshaped = x.view(N, C, H // block_size, block_size, W // block_size, block_size)
x_permuted = x_reshaped.permute(0, 3, 5, 1, 2, 4).contiguous()
out = x_permuted.view(N, C * block_size**2, H // block_size, W // block_size)
return out
在 YOLOv5 的项目结构中,yolov5/models/common.py 通常包含定义模型中使用的通用层和模块的 Python 代码。
这个文件是模型架构的一部分,它定义了可以在模型的不同部分重复使用的层,比如卷积层、上采样层、激活函数等。
例如,在 YOLOv5 的实现中,common.py 可能包含以下内容:
- 自定义卷积层类(有时为了特殊的初始化或行为)
- 激活函数(如 Mish 激活函数)
- 层组合(如 CSP 结构)
- SPP (Spatial Pyramid Pooling) 结构
- Focus 层(一种特殊的切片和重排层,用于改变输入特征图的空间分辨率)
在模型定义文件中(如 yolov5/models/yolov5s.py),这些通用层会被实例化并组合成完整的神经网络。
这种模块化的方法可以让代码更加整洁,并且可以更容易地在不同的模型配置文件中重复使用相同的层定义。
导入SPD模块
在yolo.py的顶部导入SPD类。
from models.common import SPD
在parse_model中实现更改:
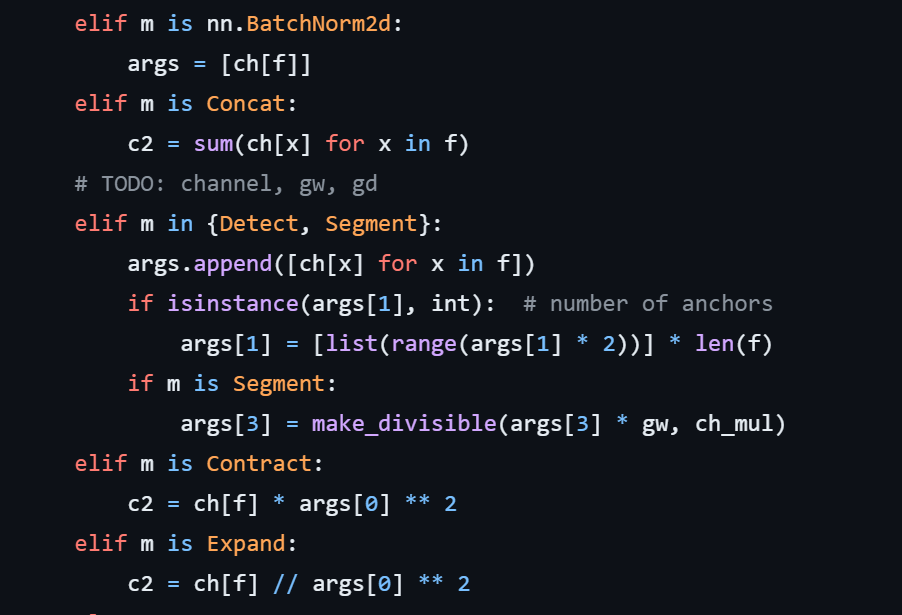
elif m is SPD:
c2 = 4 * ch[f]
# 将输入通道数 ch[f] 增加了四倍
# 4 是基于 SPD 的 block_size 为 2 的假设。如果 block_size 有所不同,这个数字应该是 block_size 的平方
# ch 是一个包含前面所有层输出通道数的列表,f 是指向前面某层的索引
修改 .yaml 文件
在 YOLOv5 的项目中,.yaml 文件通常用来定义模型的架构。
yaml 文件分为:
- 参数部分:nc(数据集类别数量)、
- 网络结构部分:from(从哪层获取输入), repeats(模块重复次数), module(模块名字), args
- 头部部分
文件名中的 yolov5s, yolov5m, yolov5l, yolov5x 等分别代表了不同大小和复杂性的模型配置:
-
yolov5s.yaml - “s” 代表 “small”(小)。
这是 YOLOv5 系列中最小的模型,拥有最少的层数和参数,适用于速度要求较高或计算资源有限的环境。
-
yolov5m.yaml - “m” 代表 “medium”(中等)。
这个配置是介于小型和大型模型之间的中等大小的模型,它在速度和准确性之间提供了一个平衡。
-
yolov5l.yaml - “l” 代表 “large”(大)。
这个配置用于更大的模型,它具有更多的层数和参数,通常能够提供更高的准确性,但需要更多的计算资源。
-
yolov5x.yaml - “x” 代表 “extra large”(特大)。
这是 YOLOv5 系列中最大的模型,有最多的层数和参数,通常在准确性方面表现最好,但也是计算成本最高的。
-
yolov5n.yaml - “n” 代表 “nano”(纳米)。
这是一个非常小的模型,旨在在非常资源有限的设备上运行,比如在边缘计算设备或移动设备上。
这些文件中定义的参数包括了模型的层数、每一层的类型(如卷积层、上采样层等)、每一层的参数(如滤波器数量、步长、激活函数等),以及如何将这些层连接起来。
用户可以根据自己的需求和资源选择合适的模型大小。
例如,如果你需要在移动设备上进行实时物体检测,可能会选择 yolov5s 或 yolov5n;如果你在服务器上进行高准确性的物体检测并且不太关心推理时间,可能会选择 yolov5l 或 yolov5x。
我们选第一个:yolov5S.yaml。

重点在于在特定的层后添加SPD层,然后紧接一个非步长卷积层(卷积步长改为1),以优化模型对小物体的检测能力。
# 参数设置
nc: 80 # 类别数
depth_multiple: 0.33 # 模型深度倍数
width_multiple: 0.50 # 层通道倍数
anchors:
- [10, 13, 16, 30, 33, 23] # P3/8 锚点
- [30, 61, 62, 45, 59, 119] # P4/16 锚点
- [116, 90, 156, 198, 373, 326] # P5/32 锚点
# YOLOv5 v6.0骨干网(添加SPD和非步长卷积层)
backbone:
# [来源, 数量, 模块, 参数]
[
[-1, 1, Conv, [64, 6, 2, 2]], # 初始卷积层
[-1, 1, SPD, [1]], # 添加SPD层,用于增强对小尺寸特征的处理能力
[-1, 1, Conv, [64, 3, 1]], # 在SPD层之后添加非步长卷积层,以保留细粒度信息
# 根据模式继续添加SPD层和非步长卷积层
]
# YOLOv5 v6.0头部(根据需要应用类似修改)
head: [
# 在这里应用类似的SPD和非步长卷积层修改
]
调整后续层的通道数:由于 SPD 操作会增加通道数,你需要调整后续层以匹配新的通道数。这可能包括更改后面的 C3 层的通道数。
SPD 操作通过重新排列输入特征图的像素来增加通道数,同时减少特征图的高度和宽度。
SPD操作的效果和需要调整的通道数可以通过以下方式计算:
给定一个特征图,SPD操作将其划分为较小的块(例如,2x2),然后将这些块内的元素移动到通道维度。
因此,对于一个2x2的块,特征图的高度和宽度会减半,而通道数会增加4倍(因为每个2x2块有4个元素)。
如果原始特征图的通道数为(C),并且使用了2x2的SPD操作,则新的通道数(C’)可以通过以下公式计算:
C ′ = C × 4 C' = C \times 4 C′=C×4
这是因为每个2x2的区域被压缩成了通道维度上的四个额外条目。
如果SPD操作使用的是不同尺寸的块(比如3x3,虽然不太常见),通道数的增加会相应改变。
在应用SPD操作之后,你需要调整后续层以匹配新的通道数。
- 例如,如果你在一个具有64个通道的特征图上应用2x2的SPD操作,新的通道数将为(64 \times 4 = 256)。
- 因此,紧接着SPD操作的下一层(例如,卷积层、C3层等)需要调整其接受的输入通道数为256。
在实际应用中,这意味着你需要仔细规划你的网络结构,并在应用SPD操作后调整网络的相应部分。
这可能包括不仅仅是调整通道数,还可能需要考虑特征图尺寸的变化,以及如何最有效地利用这些调整后的特征图。
总结,YOLO v5 修改三步:
- 把 XXX模块 放入
common.py yolo.py放入类名- 修改
yolov5.yaml
比如把 SPD层、非步长卷积(步长为1的卷积层)替换第二个Conv层、第四、六、九个C3层。
- 二、四、六、九不是固定的,想怎么改都行,只有网络的特征图尺寸对齐就可以了
如何实现对接?
-
在SPD层之后:SPD层会增加通道数,所以紧接着SPD层的卷积层(包括1x1的非步长卷积层)需要设计为能接受这个增加的通道数。
比如,如果SPD层将通道数增加了4倍,则下一层的卷积层的输入通道数也应该是这个增加后的数量。
-
使用1x1卷积层调整通道数:1x1的卷积层可以用来调整通道数,使其与下一层期望的输入通道数匹配。
这个技术常用于深度学习中的特征图通道数调整和信息融合。
-
确保特征图尺寸一致性:如果由于SPD层的使用导致特征图尺寸减半(下采样),那么在网络的后续部分,需要通过上采样或其他结构来调整特征图的尺寸,以确保其与网络其他部分的特征图尺寸一致。
# 参数设置
nc: 80 # 类别数目
depth_multiple: 0.33 # 模型深度倍数
width_multiple: 0.50 # 层宽度倍数
anchors:
- [10,13, 16,30, 33,23] # P3/8 锚点
- [30,61, 62,45, 59,119] # P4/16 锚点
- [116,90, 156,198, 373,326] # P5/32 锚点
# YOLOv5 v6.0 backbone with SPD-Conv
backbone:
# [输入来源, 数量, 模块, 参数]
[[-1, 1, Focus, [64, 3]], # 0-P1/2
[-1, 1, SPD, [1]], # 1 空间到深度转换
[-1, 1, Conv, [128, 3, 1]], # 2-P2/4 非步长卷积
[-1, 3, C3, [128]], # 3
[-1, 1, SPD, [1]], # 4 空间到深度转换
[-1, 1, Conv, [256, 3, 1]], # 5-P3/8 非步长卷积
[-1, 6, C3, [256]], # 6
[-1, 1, SPD, [1]], # 7 空间到深度转换
[-1, 1, Conv, [512, 3, 1]], # 8-P4/16 非步长卷积
[-1, 9, C3, [512]], # 9
[-1, 1, SPD, [1]], # 10 空间到深度转换
[-1, 1, Conv, [1024, 3, 1]], # 11-P5/32 非步长卷积
[-1, 3, C3, [1024]], # 12
[-1, 1, SPPF, [1024, 5]], # 13
]
# YOLOv5 v6.0 head
head:
[[-1, 1, Conv, [512, 1, 1]], # 14 conv
[-1, 1, nn.Upsample, [None, 2, 'nearest']], # 15 上采样
[[-1, 9], 1, Concat, [1]], # 16 concat backbone P4
[-1, 3, C3, [512, False]], # 17
[-1, 1, Conv, [256, 1, 1]], # 18 conv
[-1, 1, nn.Upsample, [None, 2, 'nearest']], # 19 上采样
[[-1, 6], 1, Concat, [1]], # 20 concat backbone P3
[-1, 3, C3, [256, False]], # 21 (P3/8-small)
[-1, 1, SPD, [1]], # 22 空间到深度转换
[-1, 1, Conv, [256, 3, 1]], # 23 非步长卷积
[[-1, 18], 1, Concat, [1]], # 24 concat head P4
[-1, 3, C3, [512, False]], # 25 (P4/16-medium)
[-1, 1, SPD, [1]], # 26 空间到深度转换
[-1, 1, Conv, [512, 3, 1]], # 27 非步长卷积
[[-1, 14], 1, Concat, [1]], # 28 concat head P5
[-1, 3, C3, [1024, False]], # 29 (P5/32-large)
[[21, 25, 29], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
]
YOLO v7 小目标改进
https://github.com/WongKinYiu/yolov7
# 参数设置
nc: 80 # 类别数
depth_multiple: 0.33
width_multiple: 0.50
anchors:
- [10,13, 16,30, 33,23]
- [30,61, 62,45, 59,119]
- [116,90, 156,198, 373,326]
# YOLOv7 backbone with SPD-Conv
backbone:
# [from, repeats, module, args]
[[-1, 1, Conv, [32, 3, 1]], # 0-P1/2
[-1, 1, Conv, [64, 3, 1]], # 1-P1/2
[-1, 1, SPD, [1]], # 2 空间到深度转换
[-1, 1, Conv, [64, 3, 1]], # 3-P2/4 非步长卷积
[-1, 1, C3, [64]], # 4
[-1, 1, SPD, [1]], # 5 空间到深度转换
[-1, 1, Conv, [128, 3, 1]], # 6-P3/8 非步长卷积
[-1, 2, C3, [128]], # 7
[-1, 1, SPD, [1]], # 8 空间到深度转换
[-1, 1, Conv, [256, 3, 1]], # 9-P4/16 非步长卷积
[-1, 2, C3, [256]], # 10
[-1, 1, SPD, [1]], # 11 空间到深度转换
[-1, 1, Conv, [512, 3, 1]], # 12-P5/32 非步长卷积
[-1, 1, C3, [512]], # 13
[-1, 1, SPPCSPC, [512]], # 14
]
# YOLOv7 head
head:
[[-1, 1, Conv, [256, 1, 1]], # 15
[-1, 1, nn.Upsample, [None, 2, 'nearest']], # 16
[[-1, 10], 1, Concat, [1]], # 17
[-1, 2, C3, [256, False]], # 18
[-1, 1, Conv, [128, 1, 1]], # 19
[-1, 1, nn.Upsample, [None, 2, 'nearest']], # 20
[[-1, 7], 1, Concat, [1]], # 21
[-1, 2, C3, [128, False]], # 22 (P3/8)
[-1, 1, SPD, [1]], # 23 空间到深度转换
[-1, 1, Conv, [128, 3, 1]], # 24 非步长卷积
[[-1, 19], 1, Concat, [1]], # 25
[-1, 2, C3, [256, False]], # 26 (P4/16)
[-1, 1, SPD, [1]], # 27 空间到深度转换
[-1, 1, Conv, [256, 3, 1]], # 28 非步长卷积
[[-1, 15], 1, Concat, [1]], # 29
[-1, 2, C3, [512, False]], # 30 (P5/32)
[[22, 26, 30], 1, Detect, [nc, anchors]], # Detection
]
YOLO v8 小目标改进
在 v8 文件夹下新建一个 xxx.yaml;
把 SPD-Conv 代码添加到 ultralytics 文件中:
- 在 block.py 的 all = {各种模块},把 SPD 代码函数名字添加进来
- 在 block.py 下面添加 SPD 代码
- 在 modules/init.py 中 from .block import (各种模块),把 SPD 代码函数名字添加进来
- 在 task.py 中 from ultralyics.nm.modules import (各种模块),把 SPD 代码函数名字添加进来
将 SPD-Conv 函数名字加入到 ultralytics/nn/tasks.py 中;
修改 xxx.yaml ,用 SPD 构建 SPD-Conv 主干网络 ;
# 参数设置
nc: 80 # 类别数
scales: # 模型缩放
# [depth, width, max_channels]
n: [0.33, 0.25, 1024]
s: [0.33, 0.50, 1024]
m: [0.67, 0.75, 768]
l: [1.00, 1.00, 512]
x: [1.00, 1.25, 512]
# YOLOv8 backbone with SPD-Conv
backbone:
# [from, repeats, module, args]
[[-1, 1, Conv, [64, 3, 1]], # 0-P1/2
[-1, 1, SPD, [1]], # 1 空间到深度转换
[-1, 1, Conv, [128, 3, 1]], # 2-P2/4 非步长卷积
[-1, 3, C2f, [128, True]], # 3
[-1, 1, SPD, [1]], # 4 空间到深度转换
[-1, 1, Conv, [256, 3, 1]], # 5-P3/8 非步长卷积
[-1, 6, C2f, [256, True]], # 6
[-1, 1, SPD, [1]], # 7 空间到深度转换
[-1, 1, Conv, [512, 3, 1]], # 8-P4/16 非步长卷积
[-1, 6, C2f, [512, True]], # 9
[-1, 1, SPD, [1]], # 10 空间到深度转换
[-1, 1, Conv, [1024, 3, 1]], # 11-P5/32 非步长卷积
[-1, 3, C2f, [1024, True]], # 12
[-1, 1, SPPF, [1024, 5]] # 13
]
# YOLOv8 head
head:
[[-1, 1, nn.Upsample, [None, 2, 'nearest']], # 14 上采样
[[-1, 9], 1, Concat, [1]], # 15 concat backbone P4
[-1, 3, C2f, [512]], # 16
[-1, 1, nn.Upsample, [None, 2, 'nearest']], # 17 上采样
[[-1, 6], 1, Concat, [1]], # 18 concat backbone P3
[-1, 3, C2f, [256]], # 19 (P3/8-small)
[-1, 1, SPD, [1]], # 20 空间到深度转换
[-1, 1, Conv, [256, 3, 1]], # 21 非步长卷积
[[-1, 16], 1, Concat, [1]], # 22 concat head P4
[-1, 3, C2f, [512]], # 23 (P4/16-medium)
[-1, 1, SPD, [1]], # 24 空间到深度转换
[-1, 1, Conv, [512, 3, 1]], # 25 非步长卷积
[[-1, 13], 1, Concat, [1]], # 26 concat head P5
[-1, 3, C2f, [1024]], # 27 (P5/32-large)
[[19, 23, 27], 1, Detect, [nc]] # Detect(P3, P4, P5)
]
-
SPD操作的加入- 修改后的版本在多个层后加入了
SPD操作,这是最显著的改变。 - SPD操作通常用于增加通道数,同时减少特征图的空间尺寸,这有助于模型更有效地学习空间层次结构中的信息。
- 修改后的版本在多个层后加入了
-
卷积层的步长调整
- 在加入SPD操作的相应位置,卷积层的步长从2调整为1。
- 这种调整是为了保持特征图的空间尺寸,在SPD操作之后不立即减半,从而允许更细粒度的特征提取。
-
特征融合点的变化
- 由于SPD的加入和步长调整,特征融合点(在
head部分的Concat操作)也相应地发生了变化。 - 例如,在原始版本中,
P4特征图与[-1, 6]进行融合,而在修改后的版本中,这一融合点变为[-1, 8]。这表明特征图的来源或编号有所改变。
- 由于SPD的加入和步长调整,特征融合点(在
-
类别数的调整
- 原始版本的
nc(类别数)为80,而修改后的版本中nc被设置为4。 - 这可能是根据特定的应用场景或数据集需求进行的调整。
- 原始版本的
-
检测层的Concat操作的索引调整
- 在检测头部分,由于SPD层的加入,Concat操作的索引也进行了相应的调整,以适应网络结构的改变。
修改 ultralytics/yolo/cfg/default.yaml 文件的 ‘–model’ 参数,或使用指令训练。

















 2228
2228

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









