







YOLOv11创新升级1:引入SPDConv提升检测性能
前言
随着深度学习技术的发展,YOLO系列模型在目标检测任务中不断演进。在最新的YOLOv11模型中,引入SPDConv(Sparse Depthwise Convolution),旨在提升检测精度和速度。SPDConv作为一种高效的卷积操作,通过减少卷积层的参数数量和计算复杂度,极大地优化了模型性能。与传统卷积操作相比,SPDConv仅在必要区域进行计算,显著提高了运算效率。这种稀疏计算方式使得YOLOv11在保持高精度的同时,显著降低了推理时间,适用于实时检测场景。结合SPDConv的YOLOv11不仅提升了对小目标的检测能力,还在复杂背景下表现出色,展现了在工业缺陷检测和智能监控等应用中的强大实用性。
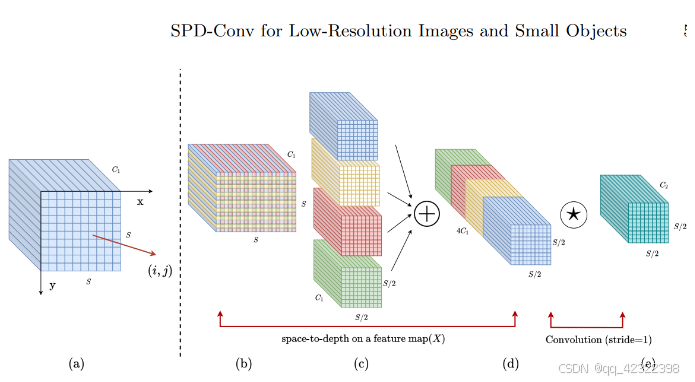
1. SPD-Conv 的关键概念
1.1 替代步长卷积与池化层
SPD-Conv旨在替代YOLOv11中的传统步长卷积和池化层。这些层在处理小物体时往往会导致细粒度信息丢失,影响模型的检测能力。
1.2 空间到深度(SPD)层
SPD层的设计目的是将输入图像的空间维度转换为深度维度。这一过程增加了特征图的深度,同时尽可能保留空间信息,从而避免传统方法中的信息损失。
1.3 非步长卷积层
在SPD层之后,YOLOv11应用非步长卷积(步长为1)进行特征提取。这种方式在不减少特征图空间尺寸的情况下,有效保留了细节信息,尤其适合于低分辨率图像和小物体的检测。
1.4 SPD层的应用
- 初始特征图尺寸为(32x32),通过SPD层处理后,空间分辨率可能降低到(16x16),而通道数增加,确保信息的完整性。
1.5 非步长卷积层的应用
- 处理后的特征图尺寸为(16x16),通道数从64增加到256。通过非步长卷积层,YOLOv11能够有效提取特征,而不损失空间信息,提升了对小物体的检测能力。
2. 核心代码
import torch
import torch.nn as nn
__all__ = ['SPDConv']
class SPDConv(nn.Module):
def __init__(self, dimension=1):
super().__init__()
self.d = dimension
def forward(self, x):
return torch.cat([x[..., ::2, ::2], x[..., 1::2, ::2], x[..., ::2, 1::2], x[..., 1::2, 1::2]], 1)
2.1在ultralytics/nn/modules/下新建SPDConv.py,并将代码写入。

2.2 在ultralytics\nn\modules_init_.py中加入
from . 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1389
1389

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









