









论文:Knowledge Graph Prompting for Multi-Document Question Answering
提出背景
-
KGP方法的创新之处在于它结合了知识图谱的结构化表示和LLM的强大推理能力。这种结合可能有助于解决传统方法在处理复杂、多步骤推理问题时的局限性。
-
知识图谱的构建不仅包括文档内容,还包括文档结构。这意味着KGP方法可能更适合处理具有复杂结构(如页面、表格等)的文档。
-
使用基于LLM的图遍历代理是一个有趣的创新。这可能使得检索过程更加灵活和智能,能够根据问题的具体需求动态调整检索策略。
-
关于主要矛盾和次要矛盾的分析很有洞察力。有效整合多个文档的信息确实是核心挑战,而文档噪声和检索效率则是需要在实际应用中不断优化的问题。
-
图书管理员的类比很恰当,它生动地展示了KGP方法的工作原理。我们可以进一步想象,这个"图书管理员"不仅能找到相关书籍,还能快速阅读并综合多本书的信息来回答复杂问题。
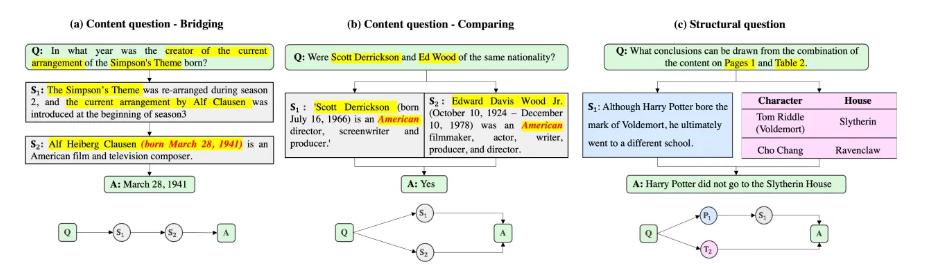
这张图展示了三种常见的多文档问答问题类型,它们都需要在多个文档的段落、页面或表格中进行推理和检索:
(a) 桥接问题(Bridging questions): 这类问题依赖于顺序推理。
例如,问题询问辛普森主题曲的当前编曲者出生年份,需要先找到编曲者信息,再找到他的出生日期。
(b) 比较问题(Comparing questions): 这类问题依赖于对不同段落的并行推理。
例如,问题比较两个人的国籍,需要分别检索两人的信息并进行比较。
© 结构性问题(Structural questions): 这类问题依赖于获取相应文档结构中的内容。
例如,问题要求从特定页面和表格中得出结论,需要定位并理解这些特定结构中的信息。
图中还展示了每种问题类型的具体例子,包括问题内容、相关信息段落以及答案。
底部的简化图表示了回答这些问题所需的信息检索和推理路径。
完全拆解
升维
背景:多文档问答(MD-QA)任务中存在的挑战。
现状:现有方法难以有效整合多文档信息和进行复杂推理。
期望:开发一种能够有效处理多文档信息并进行准确推理的方法。
问题本质:如何在多文档环境中实现高效的信息检索和复杂推理。
降维
-
公式法:KGP = 知识图谱构建 + LLM图遍历 + 问答生成
-
要素:
- 文档集合
- 知识图谱
- LLM
- 图遍历算法
- 问答生成模块
-
逻辑:
文档 → 知识图谱 → 智能遍历 → 相关信息提取 → 答案生成 -
流程:
a. 输入问题和文档
b. 构建知识图谱
c. LLM指导图遍历
d. 提取相关信息
e. 生成答案 -
模型:
- 知识图谱模型
- LLM模型
- 图遍历模型
-
二分法:
- 静态部分(知识图谱)vs 动态部分(LLM遍历)
- 结构化信息(图谱)vs 非结构化信息(原始文本)
-
矩阵法:
[文档类型 × 图谱构建方法]
[问题类型 × 遍历策略] -
第一性原理:
- 信息表示(知识图谱)
- 信息检索(图遍历)
- 推理生成(LLM)
梳理
-
目标问题:如何在多文档环境中实现高效、准确的问答。
-
实现目标的步骤和要素:
a. 知识图谱构建
b. LLM指导的图遍历
c. 相关信息提取
d. 答案生成
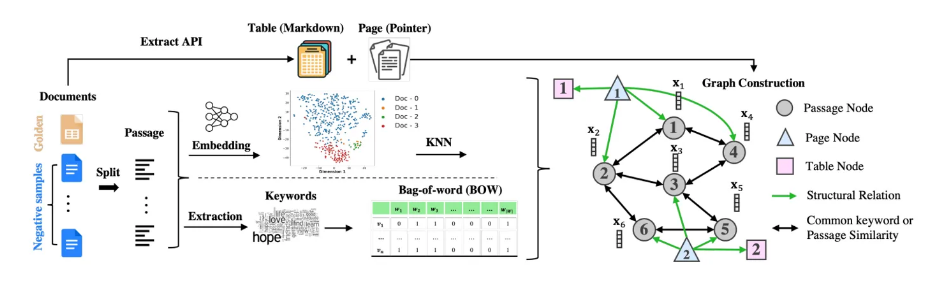
这张图展示了知识图谱 (Knowledge Graph, KG) 的构建过程。主要步骤如下:
-
文档处理:
- 将文档集合中的每个文档分割成段落。
-
特征提取:
- 对每个段落,可以选择两种方式之一:
a) 使用预训练的编码器直接获取段落的嵌入表示 (embeddings)。
b) 提取关键词,构建词袋 (Bag-of-Words, BOW) 特征。
- 对每个段落,可以选择两种方式之一:
-
段落连接:
- 基于段落嵌入的相似性或共享的关键词,将段落之间建立连接。
-
结构信息提取:
- 使用 Extract-PDF API 从文档中提取表格和页面信息。
- 将这些结构信息作为结构节点添加到知识图谱中。
-
关系建立:
- 如果页面包含段落和表格,添加有向边来表示从属关系。
- 表格节点包含以 Markdown 格式的表格内容,据补充材料中的 Figure 8 显示,LLMs 能够理解这种格式的表格。
-
图谱构建:
- 最终的知识图谱包含三种节点类型:段落节点、页面节点和表格节点。
- 节点之间的连接表示结构关系或内容相似性。
图中还展示了不同类型的节点(圆形代表段落,三角形代表页面,方形代表表格)以及它们之间的关系(绿色箭头表示结构关系,黑色双向箭头表示内容相似性或关键词共享)。
这种知识图谱构建方法旨在捕捉文档集合中的内容和结构信息,为后续的多文档问答任务提供基础。
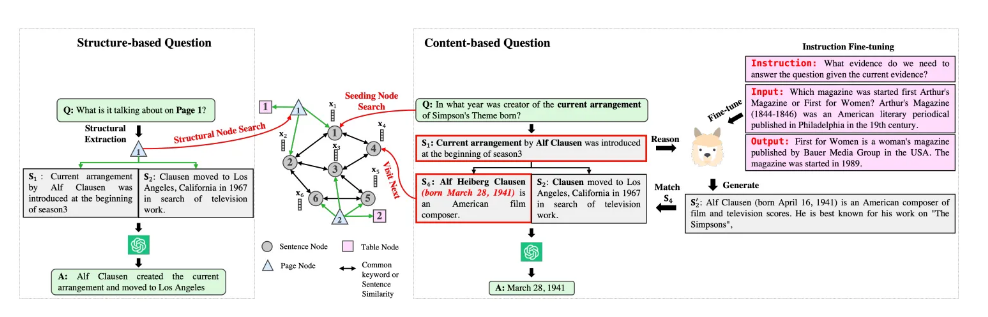
这张图展示了基于LLM(大型语言模型)的知识图谱(KG)遍历代理用于上下文检索的过程。
图片分为两部分,分别处理基于结构的问题和基于内容的问题:
-
基于结构的问题(左侧):
- 使用LLM提取文档结构(如页面、表格)
- 检索相应结构的内容(页面内容是属于该页面的段落,表格内容是markdown格式的文本)
-
基于内容的问题(右侧):
- 将问题与当前检索到的上下文连接
- 提示LLM生成回答问题所需的下一条证据
- 通过比较候选相邻句子与生成的段落的相似度,确定下一个要遍历的段落节点
- 更新候选邻居,为下一轮遍历做准备
-
指令微调(右上角):
- 展示了如何通过指令微调来增强LLM的推理能力
- 包括指令、输入和输出的示例
-
图中还展示了知识图谱的结构:
- 包含句子节点、表格节点和页面节点
- 节点之间的连接表示共同关键词或句子相似性
-
遍历过程:
- 对于内容问题,从种子节点开始搜索
- 通过LLM推理和相似度匹配,逐步找到相关的段落
- 最终生成答案
这种方法结合了结构化知识(知识图谱)和非结构化推理(LLM),以有效处理不同类型的问题,并在多文档环境中进行智能的上下文检索。
-
每个步骤的提升/改良:
a. 知识图谱构建:- 优化图谱结构
- 提高构建效率
- 增强图谱的动态更新能力
b. LLM指导的图遍历:
- 改进遍历算法
- 优化LLM提示策略
- 增强遍历的可解释性
c. 相关信息提取:
- 提高提取的准确性
- 优化信息的相关性排序
d. 答案生成:
- 增强LLM的推理能力
- 提高答案的连贯性和准确性
- 增加答案的可解释性
通过这种系统的拆解和分析,我们可以更全面地理解KGP方法,并找出潜在的改进方向。
解法拆解
- 按照逻辑关系中文拆解【KGP方法】:
目的:实现高效准确的多文档问答
问题:如何在多文档环境中有效检索信息并进行复杂推理
解法:知识图谱提示(KGP)方法
KGP方法 = 知识图谱构建(因为需要结构化表示多文档信息) + LLM指导的图遍历(因为需要智能检索相关信息) + 答案生成(因为需要综合推理得出答案)
知识图谱构建 = 文档预处理(因为需要标准化输入) + 实体抽取(因为需要识别关键信息点) + 关系建立(因为需要连接相关信息)
之所以用文档预处理子解法,是因为原始文档可能格式不一,需要统一处理。
例如:将PDF文档转换为文本,对文本进行分段和清洗。
LLM指导的图遍历 = 初始节点选择(因为需要确定起点) + 邻居节点评估(因为需要判断相关性) + 路径选择(因为需要确定遍历方向)
之所以用邻居节点评估子解法,是因为需要LLM判断哪些节点与问题最相关。
- 例如:对于问题"谁发明了电灯",LLM会优先评估包含"发明"和"电灯"相关信息的节点。
答案生成 = 相关信息整合(因为需要汇总检索到的信息) + LLM推理(因为需要根据整合的信息得出答案) + 答案优化(因为需要确保答案的准确性和可读性)
之所以用LLM推理子解法,是因为需要模型理解问题和上下文,进行复杂推理。
- 例如:综合多个文档中关于爱因斯坦的信息,推理出他对现代物理学的贡献。
- 这些子解法的逻辑链是一个决策树网络:
KGP方法
|-- 知识图谱构建
| |-- 文档预处理
| |-- 实体抽取
| |-- 关系建立
|
|-- LLM指导的图遍历
| |-- 初始节点选择
| |-- 邻居节点评估
| |-- 路径选择
|
|-- 答案生成
|-- 相关信息整合
|-- LLM推理
|-- 答案优化
- 分析隐性特征:
在LLM指导的图遍历中,存在一个隐性的特征:上下文感知能力。这个特征不直接体现在问题或条件中,而是在遍历过程中逐步体现。
定义:上下文感知遍历
隐性特征:LLM在遍历过程中不仅考虑当前节点和问题的相关性,还考虑已经遍历的路径,从而做出更智能的决策。
例如:在回答"哪个科学家既对相对论有贡献,又获得了诺贝尔奖?"这个问题时,LLM会首先找到与相对论相关的节点,然后在遍历过程中逐步缩小范围到获得诺贝尔奖的科学家,最终定位到爱因斯坦。
- KGP方法可能存在的潜在局限性:
a) 计算复杂度高:构建和遍历大规模知识图谱可能耗时长。
b) 知识图谱质量依赖:图谱构建的质量直接影响最终效果。
c) 领域适应性问题:可能需要为不同领域重新构建知识图谱。
d) LLM的固有限制:如幻觉问题可能影响推理准确性。
e) 隐私安全问题:集中存储多文档信息可能引发数据安全担忧。
f) 维护成本高:需要定期更新知识图谱以保持准确性。
g) 可解释性挑战:LLM的决策过程可能难以完全解释。
h) 长文本处理困难:对于极长文档,构建完整图谱可能不现实。
i) 实时性问题:难以处理需要实时更新的动态信息。
j) 多模态处理限制:可能难以有效处理包含图像、视频等的多模态文档。
为什么以文档的结构单元(段落、页面、表格)作为节点的知识图谱,比以实体的知识图谱,更适合做多文档问答?
5Why 分析:
Why 1: 为什么以文档的结构单元作为节点的知识图谱更适合多文档问答?
- 原因:这种方法保留了原始文档的结构和上下文信息,更接近问答任务的实际需求。
Why 2: 为什么保留原始文档的结构和上下文信息更接近问答任务的需求?
- 原因:多文档问答often需要理解和整合来自不同文档、不同部分的信息,而不仅仅是单一事实。
Why 3: 为什么多文档问答需要整合不同文档、不同部分的信息?
- 原因:复杂问题的答案通常分散在多个文档中,需要系统能够在多个信息源之间建立联系。
Why 4: 为什么复杂问题的答案会分散在多个文档中?
- 原因:现实世界的知识是互联和多面的,单一文档often无法完整覆盖一个复杂主题的所有方面。
Why 5: 为什么现实世界的知识是互联和多面的?
- 原因:知识的本质是复杂和相互关联的,反映了现实世界的复杂性和多样性。
5So 分析:
So 1: 因此,我们可以如何解决或改进?
- 解决方案:设计一个能够捕捉文档结构和内容关联的知识图谱构建方法。
So 2: 这个解决方案会带来什么结果?
- 结果:系统能够更准确地表示和检索文档中的复杂信息,提高多文档问答的质量。
So 3: 这个结果会如何影响整个系统或过程?
- 影响:提高了系统处理复杂问题的能力,使得多文档问答更接近人类的理解和推理过程。
So 4: 进一步的影响是什么?
- 进一步影响:可以应用于更广泛的领域,如法律文件分析、科学研究综述等需要处理大量复杂文档的场景。
So 5: 最终,我们希望达到什么目标或状态?
- 最终目标:创建一个能够理解和整合复杂知识结构的智能系统,在处理复杂信息任务时接近或超越人类水平。
实体知识图谱 对比 文档知识图谱
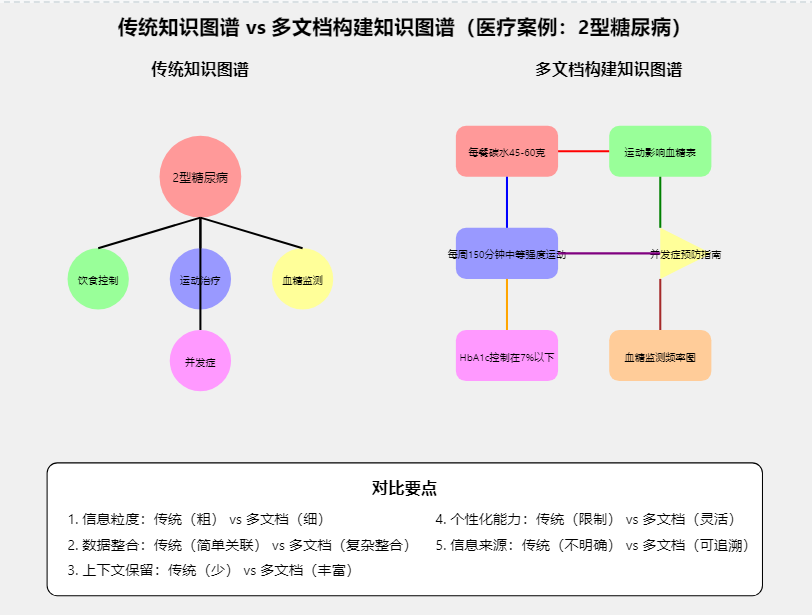
假设我们有一个问题:“2型糖尿病患者如何通过饮食和运动来控制血糖,同时考虑到可能的并发症风险?”
- 传统实体知识图谱:
节点: 2型糖尿病, 饮食, 运动, 血糖控制, 并发症
边: (2型糖尿病)-[通过]->(饮食)-[影响]->(血糖控制)
(2型糖尿病)-[通过]->(运动)-[影响]->(血糖控制)
(2型糖尿病)-[可能导致]->(并发症)
这种图谱的局限性:
- 缺乏具体的饮食和运动建议
- 没有血糖控制的具体标准
- 并发症风险没有详细说明
- 无法体现个体差异和特殊情况
基本上,现在的医学大模型都是这样:检查项目宽泛模糊,你按照ta推荐的检测,会浪费很多时间。
- 以文档结构单元为节点的知识图谱:
节点1 (段落): “2型糖尿病患者应控制碳水化合物摄入,每餐限制在45-60克。优先选择全谷物、蔬菜和水果作为碳水来源。”
节点2 (表格): [不同运动对血糖的影响表]
列:运动类型、运动时长、血糖下降幅度
节点3 (段落): “每周至少进行150分钟中等强度有氧运动,如快走或游泳。运动前后要监测血糖,避免低血糖风险。”
节点4 (页面): “2型糖尿病常见并发症及预防措施”
节点5 (段落): “长期血糖控制不佳可能导致心血管疾病、肾病和视网膜病变。建议每3-6个月检查一次糖化血红蛋白(HbA1c),目标值应低于7%。”
节点6 (图表): [血糖监测频率与并发症风险关系图]
边: 基于内容相似性和结构关系连接这些节点
这种图谱的优势:
- 提供了具体的饮食和运动建议
- 包含了数据支持的信息(如运动影响表)
- 考虑到了并发症风险和预防措施
- 提供了血糖控制的具体标准
- 可以根据不同患者的情况提供个性化建议
回答过程:
- 系统首先从节点1和节点3获取具体的饮食和运动建议。
- 通过节点2的表格,了解不同运动对血糖的影响,有助于制定个性化运动计划。
- 从节点5获取血糖控制的具体目标和监测建议。
- 通过节点4和节点6,了解并发症风险和预防措施。
- 整合这些信息,系统可以提供一个全面、个性化的建议。
这种方法能够提供更详细、更实用的答案。
它不仅回答了"如何"控制血糖,还提供了具体的数据、建议和风险提示。
这种复杂、多方面的信息整合正是多文档问答在医疗领域的优势所在,可以为患者和医护人员提供更全面、更有价值的信息支持。
全流程分析
多题一解:
KGP方法本身就是一种"多题一解"的方法。
它共用的特征是"多文档信息整合和复杂推理",共用的解法是"知识图谱+LLM指导遍历"。
这种解法适用于需要从多个文档中提取和综合信息的复杂问答任务。
一题多解:
对于多文档问答任务,除了KGP方法,还有其他解法:
- 传统检索+阅读理解:对应特征是"关键词匹配"和"单文档理解"。
- 多跳检索:对应特征是"逐步信息整合"。
- 大规模语言模型直接回答:对应特征是"模型内部知识"。
显性特征优化:
4. 知识图谱构建:可以使用更先进的实体识别和关系抽取模型,提高图谱质量。
5. LLM指导遍历:可以设计更有效的提示策略,提高遍历效率。
6. 答案生成:可以引入多模态信息,增强答案的丰富性和准确性。
隐性特征优化:
7. 上下文感知能力:可以设计特殊的注意力机制,让LLM更好地利用已遍历的路径信息。
8. 知识整合能力:可以在LLM中加入知识蒸馏技术,提高模型对图谱信息的理解和利用。
替换解法分析:
9. 替换知识图谱:使用向量数据库存储文档片段,可能提高检索效率,但可能损失结构化信息。
10. 替换LLM指导遍历:使用传统的图遍历算法如PageRank,可能提高效率但降低智能性。
11. 替换答案生成:使用抽取式而非生成式方法,可能提高速度但降低灵活性。
整体优化:
12. 端到端训练:将知识图谱构建、遍历和答案生成整合为一个可微分的端到端模型,可能提高整体性能。
13. 预训练-微调范式:在大规模多文档语料上预训练,然后在特定领域微调,可能提高模型的泛化能力。
局部优化:
- 知识图谱增量更新:设计增量更新机制,提高图谱的实时性。
- 遍历策略动态调整:根据问题类型动态选择遍历策略,提高效率。
- 答案生成多样性:引入对比学习,生成多样化的候选答案,提高答案质量。
整体关联
├── KGP方法【核心概念】
│ ├── 背景和问题【描述背景和问题】
│ │ ├── 多文档问答(MD-QA)任务的挑战【背景介绍】
│ │ └── 有效整合多文档信息的需求【问题描述】
│ │ ├── 检索相关信息的难度【具体挑战】
│ │ └── 利用LLMs进行复杂推理的挑战【具体挑战】
│ │
│ ├── 方法组成【核心组件】
│ │ ├── 知识图谱构建【主要步骤】
│ │ │ ├── 文档预处理【子步骤】
│ │ │ ├── 实体抽取【子步骤】
│ │ │ └── 关系建立【子步骤】
│ │ │
│ │ ├── LLM基于的图遍历【主要步骤】
│ │ │ ├── 初始节点选择【子步骤】
│ │ │ ├── 邻居节点评估【子步骤】
│ │ │ └── 路径选择【子步骤】
│ │ │
│ │ └── 答案生成【主要步骤】
│ │ ├── 相关信息整合【子步骤】
│ │ ├── LLM推理【子步骤】
│ │ └── 答案优化【子步骤】
│ │
│ ├── 关键技术【技术特点】
│ │ ├── 知识图谱表示【核心技术】
│ │ │ ├── 节点表示段落或文档结构【实现细节】
│ │ │ └── 边表示语义或词汇相似性【实现细节】
│ │ │
│ │ ├── LLM指导的遍历【核心技术】
│ │ │ ├── 自适应遍历【技术特性】
│ │ │ └── 上下文感知能力【技术特性】
│ │ │
│ │ └── 指令微调【优化技术】
│ │ ├── 预测下一个支持事实【实现目标】
│ │ └── 整合常识知识【实现目标】
│ │
│ └── 优势和创新【方法评价】
│ ├── 有效整合多文档信息【主要优势】
│ ├── 增强LLMs的推理能力【主要优势】
│ └── 提高答案的准确性和可靠性【主要优势】
│
└── 应用和评估【方法验证】
├── 实验设置【评估方法】
│ ├── 不同LLM代理类型比较【实验设计】
│ └── 不同文档数量的KG构建【实验设计】
│
├── 性能指标【评估标准】
│ ├── MD-QA任务准确率【主要指标】
│ └── 检索效率【主要指标】
│
└── 案例研究【深入分析】
└── KGP方法可视化【分析方法】
组成部分:
├── 方法组成【核心组件】
│ ├── 知识图谱构建【主要步骤】
│ │ ├── 输入【数据来源】
│ │ │ └── 多文档集合【原始数据】
│ │ │
│ │ ├── 处理过程【技术流程】
│ │ │ ├── 文档预处理【子步骤】
│ │ │ │ ├── 文本分割【技术方法】
│ │ │ │ └── 格式标准化【技术方法】
│ │ │ │
│ │ │ ├── 实体抽取【子步骤】
│ │ │ │ ├── 命名实体识别(NER)【技术方法】
│ │ │ │ └── 关键词提取【技术方法】
│ │ │ │
│ │ │ └── 关系建立【子步骤】
│ │ │ ├── 语义相似度计算【技术方法】
│ │ │ └── 结构关系识别【技术方法】
│ │ │
│ │ └── 输出【中间结果】
│ │ └── 结构化知识图谱【数据表示】
│ │
│ ├── LLM基于的图遍历【主要步骤】
│ │ ├── 输入【数据来源】
│ │ │ ├── 结构化知识图谱【上一步输出】
│ │ │ └── 用户问题【查询输入】
│ │ │
│ │ ├── 处理过程【技术流程】
│ │ │ ├── 初始节点选择【子步骤】
│ │ │ │ └── TF-IDF搜索【技术方法】
│ │ │ │
│ │ │ ├── 邻居节点评估【子步骤】
│ │ │ │ ├── LLM生成证据【技术方法】
│ │ │ │ └── 相似度匹配【技术方法】
│ │ │ │
│ │ │ └── 路径选择【子步骤】
│ │ │ ├── 自适应遍历【技术特性】
│ │ │ └── 上下文感知【技术特性】
│ │ │
│ │ └── 输出【中间结果】
│ │ └── 相关段落集合【检索结果】
│ │
│ └── 答案生成【主要步骤】
│ ├── 输入【数据来源】
│ │ ├── 相关段落集合【上一步输出】
│ │ └── 用户问题【查询输入】
│ │
│ ├── 处理过程【技术流程】
│ │ ├── 相关信息整合【子步骤】
│ │ │ └── 信息融合【技术方法】
│ │ │
│ │ ├── LLM推理【子步骤】
│ │ │ ├── 上下文理解【技术方法】
│ │ │ └── 逻辑推断【技术方法】
│ │ │
│ │ └── 答案优化【子步骤】
│ │ ├── 一致性检查【技术方法】
│ │ └── 事实验证【技术方法】
│ │
│ └── 输出【最终结果】
│ └── 生成的答案【回答结果】
│
└── 步骤间衔接【流程连接】
├── 知识图谱构建 -> LLM基于的图遍历【数据传递】
│ └── 结构化知识作为遍历基础【功能说明】
│
└── LLM基于的图遍历 -> 答案生成【数据传递】
└── 相关段落作为生成输入【功能说明】
创意迸发
- 组合:
- 结合多模态信息:整合图像、音频等非文本信息到知识图谱中。
- 融合人类专家知识:在LLM遍历过程中引入人类专家指导。
- 混合符号推理和神经网络:结合传统AI的符号推理与LLM的神经网络能力。
- 拆开:
- 模块化知识图谱:将知识图谱分解为多个专题子图。
- 分布式LLM:将大型LLM拆分为多个专门的小型模型。
- 任务分解:将复杂问题拆分成多个子问题,分别处理后再整合。
- 转换:
- 创意写作应用:利用KGP生成新颖的故事情节或诗歌。
- 教育领域应用:创建个性化学习路径。
- 科学发现工具:用于发现跨学科知识关联,促进创新。
- 借用:
- 社交网络分析算法:优化图遍历策略。
- 推荐系统思想:预测用户感兴趣的知识点。
- 搜索引擎技术:改进相关性排序和快速检索。
- 联想:
- 蚁群算法启发:优化知识图谱遍历策略。
- 免疫系统类比:设计动态知识图谱更新机制。
- 城市规划思想:优化知识图谱的结构和连接。
- 反向思考:
- 反向问答:从答案推导可能的问题,增强系统的理解能力。
- 错误引导学习:故意引入错误信息,训练系统识别和纠正错误。
- 知识缺口发现:通过识别知识图谱中的空白来指导学习和研究方向。
- 问题:
- 元问题分析:系统自动分析用户问题的类型和难度,调整回答策略。
- 问题重构:将复杂问题重新表述为更容易回答的形式。
- 问题生成:基于知识图谱自动生成相关问题,促进深度学习和探索。
- 错误:
- 错误分析学习:系统自动分析错误回答,不断改进推理过程。
- 创意错误利用:将系统的"错误"联想用于创意生成。
- 对抗训练:故意生成具有挑战性的错误样本来增强系统的鲁棒性。
- 感情:
- 情感理解集成:在知识图谱中加入情感标注,增强对问题情感倾向的理解。
- 个性化回答风格:根据用户情感状态调整回答的语气和风格。
- 情感智能对话:在回答中加入适当的情感元素,提高交互的自然度。
- 模仿:
- 专家模仿:模仿不同领域专家的回答风格和思维方式。
- 跨领域类比:借鉴其他成功AI系统的特点,如AlphaGo的决策机制。
- 人类认知过程模仿:模仿人类的记忆和推理过程,如工作记忆和长期记忆的交互。
- 联想方法:
- 概念网络扩展:通过语义关联自动扩展知识图谱。
- 跨领域知识迁移:利用一个领域的知识解决另一个领域的问题。
- 随机刺激创新:引入随机元素激发新的连接和思路。
- 最渴望联结:
- 用户意图预测:预测并满足用户潜在的信息需求。
- 知识探索引导:根据用户兴趣主动推荐相关知识点。
- 学习动机激发:将枯燥知识与用户感兴趣的主题联系。
- 空隙填补:
- 知识图谱自动补全:识别并填补知识图谱中的信息空白。
- 跨文档信息整合:自动整合多个文档中的碎片信息。
- 推理能力增强:在现有知识的基础上进行合理推测,填补逻辑空缺。
- 再定义:
- 动态知识表示:根据上下文动态调整知识的表示方式。
- 多维度问题解析:从多个角度重新定义和解析用户问题。
- 知识应用场景拓展:探索知识在新领域的应用可能。
- 软化:
- 幽默回答生成:在适当情况下加入幽默元素,增加交互趣味性。
- 类比解释复杂概念:使用简单类比软化难以理解的概念。
- 渐进式信息展示:通过循序渐进的方式软化复杂信息的呈现。
- 附身:
- 角色扮演回答:根据不同专业背景或历史人物的视角回答问题。
- 跨学科思维模拟:模拟不同学科专家的思维方式解决问题。
- 用户视角同理:从用户的知识水平和视角出发组织回答。
- 配角:
- 次要信息挖掘:关注并利用文档中的次要信息,提供更全面的回答。
- 背景知识强化:增强对问题背景信息的理解和利用。
- 元数据分析:利用文档的元数据(如作者、日期)提供额外洞见。
- 刻意:
- 极端场景探索:考虑问题在极端情况下的答案,激发创新思维。
- 反常识推理:故意违背常识,探索新的可能性。
- 夸张类比:使用夸张的类比来强调关键点,加深理解。
这些创新思路涵盖了多个方面,从技术改进到应用拓展,再到交互体验的提升。下一步,我们可以根据实现难度、潜在影响和与原始目标的契合度等标准,评估这些创新点,选择最有价值的方向进行深入探索。

















 3224
3224

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









