







GC-Net,论文名为:End-to-End Learning of Geometry and Context for Deep Stereo Regression,ICCV 2017年(CCF A)的论文。
通过端到端的神经网络来学习几何和上下文信息来进行立体几何的视差回归。突然发现MVSNet当中其实相当一部分直接沿用了这个模型的思想而没有做详细的解释,为了更好的理解MVSNet当中一些名词概念、方法原理,对该论文进行补充精读。
对于视差和深度的关系,可以看
【三维重建补充知识-0】视差、深度概念及其转换
一、问题背景
- 在视差估计中,核心问题是计算不同图像之间像素点的关联性,而之前最先进的传统算法往往在无纹理区域、反射面、薄结构和重复图案等方面存在困难,因此往往通过池化或基于梯度的正则化来缓解这些失败,但需要在平滑表面和检测细节结构之间进行折衷
- 目前,深度学习模型可以从原始图像中学习到具有语义信息的特征表示
- 对于立体几何中很多的问题,其算法效果会受益于全局语义上下文的知识,而不仅仅依赖于局部几何
- 在之前的立体几何问题中,使用深度学习特征的方法主要是用深度特征表示来产生一元项,而在深度一元表示上应用代价匹配(cost matching)在估计像素视差时表现不够好,仍需要使用传统的正则化和后处理方法(如SGB和左右视图一致性),但这些手工设计的、浅层的正则化步骤仍容易受到前边提到的弱纹理之类问题的严重限制
二、相关知识
- 深度推断的研究子集:匹配代价计算(matching cost compution)、代价支持聚合(cost support aggregation)、视差计算和优化(disparity compution and optimization)或视差细化(disparity refinement)
- 匹配代价(matching cost):对应图像位置的像素相异性的潜在度量,如绝对差异(absolute differences)、平方差异(squared differences)和截断差异(truncated differences)
- 基于梯度的局部描述符(gradient based local descriptor):CENSUS、BRIEF等
三、论文创新点
目的是利用校正的立体图像对,通过回归方法来寻找图像上的各像素点的视差值。
- 使用神经网络提取的特征表示,利用几何知识来构建代价体
- 使用3D卷积来聚合代价体的上下文信息
- 使用文章提出的soft argmin方法从代价体回归视差,无需后处理即可达到亚像素精度且可以实现端到端训练(因为可反向传播)
四、论文模型
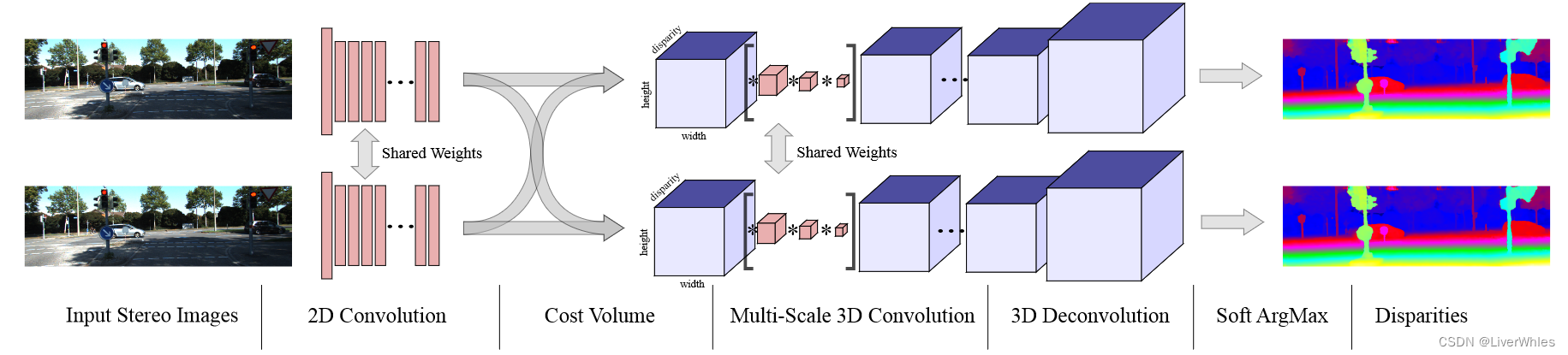
1.一元特征提取(Unary Features)
使用参数共享的神经网络提取深度特征表示,输出尺度为[H/2, W/2, F],F代表特征通道数,这个Unary Features值的就是单值特征。
2.代价体生成
为左、右输入图片各计算一个代价体,使用上一步所提取的一元特征([H/2, W/2, F]),增加一个视差的维度,变成[D/2, H/2, W/2, 2F]的代价体。
新加视差维度之后,原来的3D特征图变成4D代价体,视差的取值为:【1,dmax】
对于每一个视差di,把左右图的一元特征连接在一起,但做连接的是左图像素点p的特征和右图像素点p+di的特征
这样最终得到的代价体尺度为[D/2, H/2, W/2, 2F],D/2是因为视差只沿着水平方向所以最大也是图像宽度的一半,而2F则是因为上述拼接中对每个视差di可以看作把原始左图的特征通道Fn后边加了一个来自右图、加上对应视差之后位置对应的特征通道Fn’。
论文强调这样做的好处在于保留了绝对的特征表示进入代价体当中,而不是像使用点积、或距离度量等方法只能得到不同特征间的相对关系,从而避免了特征维度的减少和信息丢失,可以在后续的过程中更好的计算和使用语义信息。
3.学习上下文(Learning Context)
本部分即代价体正则化,的目的是想学习一个正则化函数,它能够在代价体中考虑上下文并改进视差估计。此外,指出即使是用神经网络学习到的特征来做代价匹配(cost matching)也会存在问题,如对于天空等一些像素强度均匀的场景对应局部局域的匹配均线会很平坦,因此计划使用3D卷积操作来进行滤波和优化表示。
该部分3D卷积的网络结构:

- 三维卷积能够从高度、宽度和视差维度学习特征表示,同时由于计算了每个一元特征的代价曲线,因此可以从这个表示中学习卷积滤波器。
- 使用3D卷积的问题在与多了一个视差维度会带来较大的计算负担,可以通过使用深度编码解码结构(Deep Encoder-Decoder)来缓解,即在编码时下采样特征图,在解码时上采样特征图。
4.可微ArgMin(Differentiable ArgMin)
该部分即推断深度图,提出了之后MVSNet沿用的soft argmin操作
首先指出,在之前的方法中会通过匹配代价来计算出代价体,并沿着视差维度使用argmin来估计视差,这样存在两个问题:
- 计算出的视差时离散的,且无法产生亚像素的视差估计(所以亚像素级精度简单理解就指“连续的、包含小数点”的精度)
- 结果不可微分,因此无法使用反向传播来训练
因此提出了Soft argmin的方法,具体来讲:
- 对正则化后代价体(cost volume)上的每一个像素点的值(predicted cost)取反,得到概率体(probability volume)
- 沿视差方向正则化概率体,即做softmax操作
- 沿视差方向求期望
通过公式表述整个过程即为:
s
o
f
t
a
r
g
m
i
n
:
=
∑
d
=
0
D
m
a
x
d
×
σ
(
−
c
d
)
soft\ argmin:=\sum^{D_{max}}_{d=0}d\times{σ(-c_{d})}
soft argmin:=d=0∑Dmaxd×σ(−cd)
cd为正则化代价体上视差为d时的预测代价值。
- 论文模型图上对该部分的注释是”Soft argmax“,其实在讲述时有一小行注解
Note that if we wished for our network to learn probabilities, rather than cost, this function could easily be adapted to a soft argmax operation, 即如果网络训练的是想得到概率(越大越可能是当前视差)而非代价(越小越可能是当前视差),那么其实需要的是最大值的参数,也即argmax。- 此外,论文特意用一部分篇幅描述如何使soft argmin尽可能产生与直接argmin一样视差预测结果,感觉求期望不是更好吗?可能是从实验效果反向选择这种方式的吧。。
5.损失函数
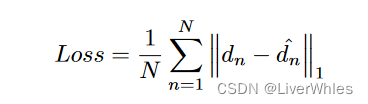
没什么特殊的,就是逐像素求L1损失来当作回归问题来解决。
五、模型显著性(Model Saliency)

论文通过将各像素的视差值作为输入计算其所受各像素的影响来计算出以上图片,可看出每个目标白十字像素出的视差推断是包含了更广的上下文信息的——通过车和周围地面的像素特征来计算其视差,这是之前像使用9x9这样基于Patch的深度学习立体算法所无法做到的。

















 1396
1396

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









