






 本文主要梳理不同类型的分类评价指标原理。先介绍了Accuracy、Precision、recall等概念及计算示例,还提到F值、ROC用于评判二分类模型性能,混淆矩阵可计算多标签情况,Kappa系数用于一致性检验和判断分类精度。
本文主要梳理不同类型的分类评价指标原理。先介绍了Accuracy、Precision、recall等概念及计算示例,还提到F值、ROC用于评判二分类模型性能,混淆矩阵可计算多标签情况,Kappa系数用于一致性检验和判断分类精度。
通常我们在构建模型之后都会涉及到一个模型的精度评价。针对不同的模型由主要可以分回归评价指标和分类评价指标,本文主要是想梳理一下各种不同类型的分类评价指标原理。
分类评价指标
在了解二分类之前需要先了解下面四个概念
| TP(正确预测正分类结果) | FP(错误预测正分类结果) |
| TN(正确预测负分类结果) | FN(错误预测负分类结果 |
Accuracy(总体分类精度):预测正确的样本数 / 所有的样本数
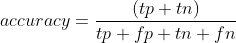
Precision(精确度):正确预测正分类的样本数 / 预测为正样本的样本数
你真正预测对的正样本占了所有正样本的比例,就是预测对了的占比如何
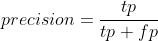
recall(召回率):正确预测正分类的样本数 / 所有正样本数
简单来说:你真正预测对的正样本占了你预测的所有正样本的比例,考虑的是预测错了占比如何
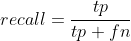
比如我有10张图,5张猫,5张狗,我全部预测为猫,猫预测全对,猫的召回:5/(5+0)=100%,猫的精度:5/(5+5)=50%。同理,剩下5张狗也也预测为了猫,狗的召回:0/(5+0) = 0%,狗的精度:0%
F值:综合precision和recall得分,是precision和recall的调和均值,当中的 通常取0.5 ,1 , 2 代表精确度的权重占比
通常取0.5 ,1 , 2 代表精确度的权重占比
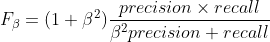
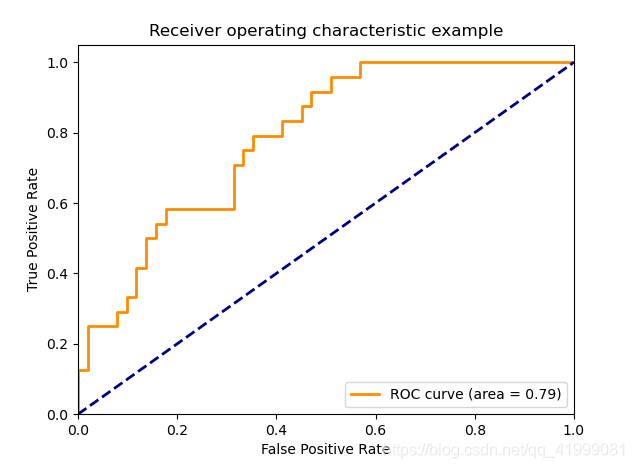
ROC 全称 Receiver operating characteristic,作为一个图形,随着判断阈值的变化,常用于评判二分类模型的性能,横纵表FPR(false positive rate) = FP/(FP+TN) 表示在所有实际为负类的样本中,被错误的判断为正类的比率;纵坐标TDR(True positive rate) = TP/(TP+FN) 表示在所有实际为正类的样本中,被正确的判断为正类的比率。通常来说,横坐标越小,纵坐标的值越大,ROC的面积越大,模型的效果也就越好,python代码详见Receiver Operating Characteristic (ROC) — scikit-learn 1.1.1 documentation:
混淆矩阵(Multilabel confusion matrix)计算多标签的混淆矩阵,再多分类任务中,标签以“一对多”的方式进行二值化:
| confusion matrix | 预测值 | |||
| 类别1 | 类别2 | 类别3 | ||
| 真实值 | 类别1 | a | b | c |
| 类别2 | d | e | f | |
| 类别3 | g | h | i | |
表中的a,e,i表示正确分类,类别1的precision= a/(a+d+g) ,类别1的recall = a/(a+b+c),类别2,类别3的precision和recall同理。
Kappa:kappa系数常用于一致性检验,也用于判断分类精度,kappa系数的计算通常是基于混淆矩阵的,kappa精度评价参考每日一学 kappa系数_阿尔卑斯山脉的小菇凉的博客-CSDN博客_kappa系数:
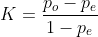
混淆矩阵中正确分类的样本数(对角线的值)除以所有样本数 :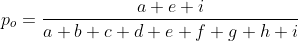
混淆矩阵中每一类的真实值于每一类的预测值相乘求和 / (总样本数) ^2:
![]()

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









