




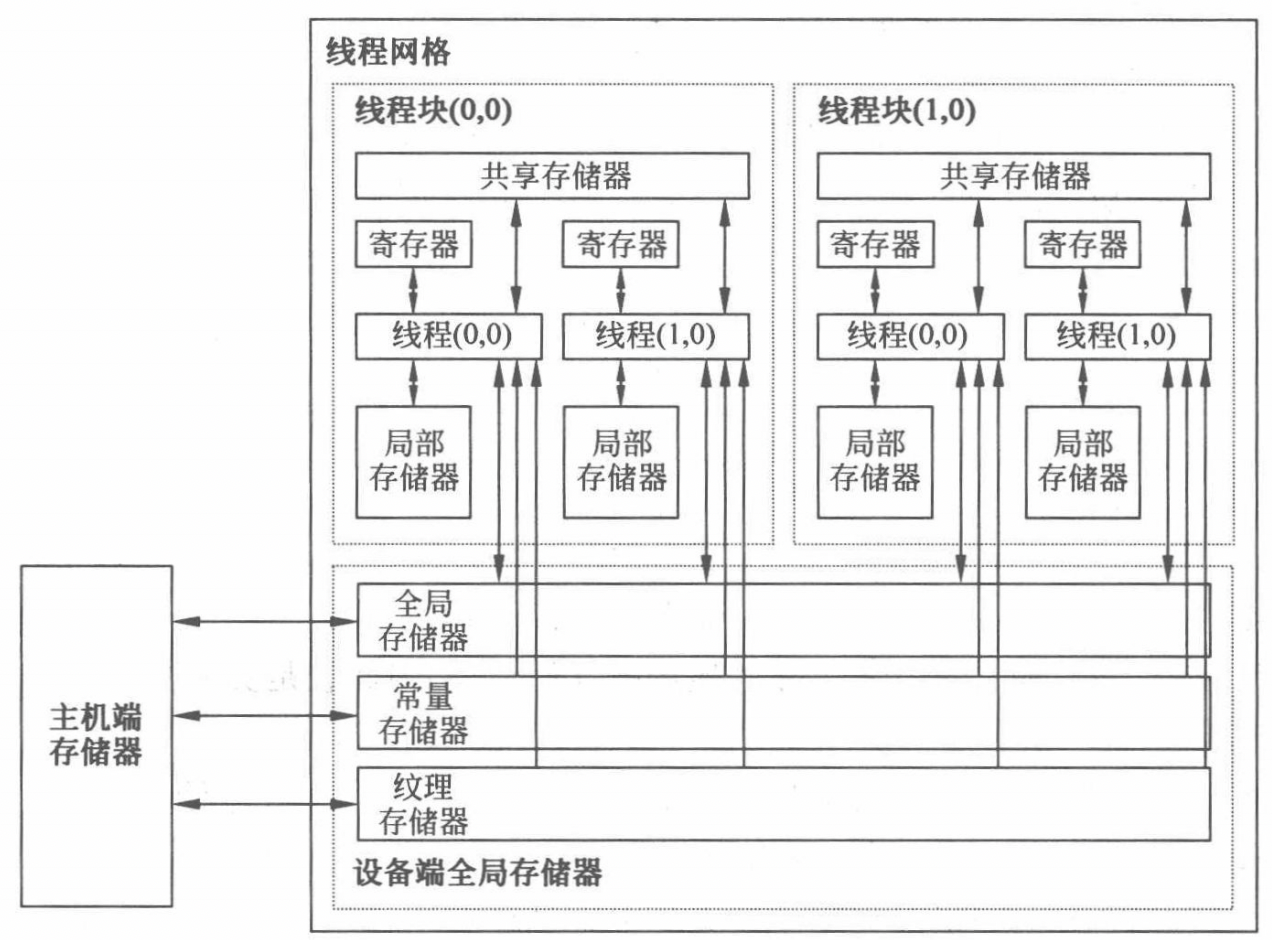
1.数据读写权限:基于箭头方向不同决定是否具备从对应的内存模型读写数据
2.寄存器:
片上内存,访问速度快。在没有添加限定符的前提下变量都是存储于寄存器(这里的限定符是核函数前面的__gloabl__, __share__)由于寄存器空间有限因此对于未添加限定符的数组也可能存储到本地内存
3.本地内存(局部内存):
寄存器放不下的内存就会放到本地内存,一般存储数组结构体等。本地内存本质上也是全局内存的一部分延迟较高,过多使用会降低程序的性能
寄存器溢出:如果核函数所需要的寄存器超过了硬件的支持数量就会将数据将保存到本地内存,导致寄存器溢出------>本地内存本质是全局内存会影响性能
4.全局内存:
特点:容量最大,延迟最大,主机端 device端均可见,生命周期由主机端决定
全局内存的初始化分为动态初始化(cudaMalloc声明内存空间,cudaFree释放)和静态初始化(__device__声明静态全局内存 eg: __device__ int a )
5.共享内存(静态共享内存和动态共享内存):
片上内存,访问速度仅次于寄存器
__shared__定义数据存储到共享内存
由于共享内存作用于block 因此可用于block之间的通信
共享内存的作用:晶频繁访问的数据存储到共享内存,提高访问效率
静态共享内存:
声明:__shared__ array[5]
作用域:如果定义在核函数内 那么作用于进限制在核函数内部,如果定义在核函数外,那么对所有核函数均有效
要求:在申明时明确数据大小
动态共享内存:
声明:extern __shared__ array[]
6.常量内存:
作用:带缓存的全局内存
使用:__constant__ ,必须定义在核函数之外,且为静态定义
初始化:主机端使用cudaMmmcpyToSymbol进行初始化
使用场景:常亮内存可以被所有县城访问,因此对于一些公共的数据(如数据公式的系数)可以放到常量内存

















 4861
4861

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









