







前言
2023.3.8 总结之前研一学习SV做的笔记,现在看第二遍比之前理解的更深了
SV特点:单一, 同时支持设计和验证的标准语言。支持约束随机的产生。支持覆盖率统计分析。支持断言验证。纯软件的环境。
一、数据类型
1、变量之间类型转换
静态转换:在表达式之前加上单引号,编译时作检查
动态转换:$cast(tgt,src),仿真时检查,会告诉转换成功与否
显式转换:需要系统函数或者其他符号
隐式转换:implicit conversion,不需要
(1)合并数组 非合并数组
int [7:0][3:0] a;位宽和大小声明在变量名的左边,且不能是[7][3] a;
packed类型:按照连续bit存放,数据之间没有空闲空间;相比节省存储空间,效率更高,因为复制内容更少,赋值不需要 '{ }。bit和logic这种数据宽度>=1的可以被定义为压缩数组,但是int这种预定义了数据宽度的不可被定为压缩数组。[5:0]bit[3]中,压缩的维数是6。
unpacked类型:按照字存放,有空闲周期。但其访问效率更高
任何数组类型都可以合并,包括动态数组、队列和关联数组。
如果需要等待数组中的变化,则必须使用合并数组
bit [3][7:0] b_pack; //3个8bit数,三行8列
logic [7:0] b_unpack[3]; //一个logic要用两位进行存储,所以需要48bit,也就是2 word
bit [3:0][7:0] array[3]; //表示3*32bit的数组
array[0] = 32'b0123_4567;
array[0][3] = 8'h01;
array[0][3][0] = 1'b1;
(2)数组循环
for(int i=0;i<$size(array);i++)
array[i] = i;
foreach(a[j]) 这种j从0到最大循环,写起来更简单
a[j] = array[j] * 2;
foreach( array2[i][j] ) $display("数组中第[%0d] [%0d]= %0d;",i,j,array1[i][j]);
//遍历方式二:
foreach(array[i]) begin
foreach(arrayy[,j]) $display("数组中第[%0d] [%0d]= %0d;",i,j,array1[i][j]);
end
(3)数组排序
sort:从小到大rsort:从大到小reverse:反向排序shuffle:乱序
2、定宽数组
用==和!=直接比较,宽度在编译时就固定下来
int lo [0:15]; //有16行,每行1个int数据
int lo [16]; 紧凑声明
//多维数组
int array [0:7][0:3]; //8行,每行4个int数据
int array [8][4];
array [7][3] = 1; //设置最后一个元素
//数组元素初始化
int array1[4] = '{0,1,2,3}; //有4行,不是同一行,不连续,要用`{}赋值
int a1 = '{4{8}};
int a2 = '{9,8,default:-1}; //设置缺省值
int array2 [2] [3] = '{'{2,3,4},'{4,5,6}};
bit [3:0][7:0] arr_mix [2:0]; // [3:0][7:0] 表示一个32bit 的 合并数组,[2:0]表示有3 个32 bit的合并数组
3、动态数组 new[ ]
动态数组可以认为是一个非合并数组,动态数组在声明时没有指定数组的大小,在对数组初始化时(调用new[ ])需要指定数组的大小,从而分配内存空间。
可以是一维,也可以是二维,非合并的部分不指定。
编译时大小不确定,代码运行时数组大小确定下来。
元素数据类型和个数相同,定宽数组和动态数组之间可以相互赋值。

4、队列[$]
- 结合了链表和数组的优点,可以在它的任何地方添加或删除元素,并且通过索引实现对任一元素的访问
- 具有相同数据类型成员
- 队列不需要用new[ ]去创建内存空间,一开始其所占空间为0
- 队列中的元素是
连续存储的,故不需要使用单引号 ’ { }方式赋值 - 队列的两端存取数据速度很快,但是在队列中间增删数据时就很耗时,因为需要对已经存在的数据进行搬移以便腾出空间
内建函数:pop_front、pop_back、 push_front、 push_back、 insert 、delete size

5、关联数组
如果想从一个关联数组中随机选取一个元素,你需要逐个访问它之前的元素,因为没有办法直接访问第N个元素。
可以用来保存稀疏矩阵的元素,创建超大容量数组,节省空间。当你对一个非常大的地址空间寻址时,该数组只为实际写入的元素分配空间,这种实现方法所需要的空间比定宽或动态数组所占用的空间要小得多。

bit [63:0] assoc[int];
bit [63:0] assoc[bit[63:0]]; //以64bit数据为索引,查找关联数组中的64 bit的数据
int age[string]; //以字符串为索引,查找关联数组中的int类型数据
integer i_array[*]; //未规定索引类型,通配
//赋值
int imem[int];
imem[ 2'b3 ] = 1; //索引为2'b3,索引值为1
imem[ 16'hffff ] = 2; //索引为16'hffff,索引值为2
imem[ 4b'1000 ] = 5; //索引为4b'1000 ,索引值为5
$display( "关联数组中有%0d 个键值对\n", imem.num );//3个
//给数组初始化
bit [63:0] assoc[int], index=1;
repeat(64)begin
assoc[index] = index;
index = index<<1;
end
//输出数组元素
if(assoc.first(index))begin
do
$display("assoc[%h]=%h",index,assoc[index]);
while(assoc.next(index));
end
//找到并删除第一个元素
assoc.first(index);
assoc.delete(index);
6、数据类型选择
(1)如何选择
- 索引是连续的非负整数,采用定宽或动态数组
- 索引不规则,且稀疏分布,采用关联数组
- 元素数目变化很大数组,采用队列
(2)存储速度
- 定宽和动态数组都是存放在连续的存储空间中,访问任何的元素时间都相同,与数组大小无关
- 队列在收尾存取数据几乎没有任何开销,但是在队列中间插入或删除元素需要对其他元素进行搬移以腾出空间。在很长的队列中间插入新的元素,会需要很长的时间
- 关联数组的存取速度是最慢的,因为过程中要有大量算法实现
7、结构体
typedef:创建自定义类型
结构体与前面数据类型不同之处在于其内部的数据类型可以不一样
typedef struct{ int a, byte b, shortint c;}my_struct_s;
my_struct_s st = '{32'haaaa_aaaa, 8'hbb, 16'hcccc}; //注意要用`符号来初始化
typedef struct packed {bit [7:0] r, g, b;} pixel_s; //如果操作频繁,也可以定义为packed类型
pixel_s my_pixel; //声明变量
my_pixel = '{'h10, 'h10, 'h10}; //结构体类型赋值
8、枚举类型
int=enum,enum=type(int),可以把枚举变量赋值给整型变量,但是要经转换把int变量赋值给枚举类型。
当隐式数据类型时,默认为int。
typedef enum {INIT, DECODE, IDLE} state;
state pstate,nstate;
case(pstate)
IDLE:nstate = INIT;
....
endcase
考试题目:
enum interger{a, b = 4, c, d = 10} zimu; zimu a1 = a; zimu a2 = c;
a1 和a2的值为多少
答案:0 5
解析:如果没有指定整数值,那么枚举名的值就是前一个枚举名的值加一,如果是第一个枚举名,那么默认值是0。
9、字符串
string类型来保存长度可变的字符串,单个字符是byte类型
null只用在句柄,字符串结尾是没有null的,和C不同
$sformatf(),$display(),string s;表示里面空“ ”,而不是“\0”
string s;
s = "IEEE ";
s.getc(0); //I
s.tolower(); //ieee
s.putc(s.len()-1, "-"); //把最后的空格变成-
s = {s, "P100"}; //IEEE-P100
s.substr(2,5); //EE-P
10、流操作符
<<:把数据从右至左变成数据流
>>:把数据从左至右变成数据流
int h;
bit [7:0] j[4] = '{8'ha, 8'hb, 8'hc, 8'hd};
//0000_1010,0000_1011,0000_1100,0000_1101
bit [7:0] q,r,s,t;
h = {>>{j}}; //0a0b0c0d
h = {<<{j}}; //从右开始,1011_0000,0011_0000,1101_0000,0101_0000,合起来就是b030d050
h = {<<byte{j}}; //0d0c0b0a
{>>{q,r,s,t}} = j; //把j的每8bit分别给qrst
b = {<<{8'b0011_0101}}; //8'b1010_1100
b = {<<4{8'b0011_0101}}; //半字节,从右至左8'b0101_0011
数据类型总结
单引号初始化数组:动态数组、结构体(非合并型,分开存放)
不用单引号初始化数组:队列
Verilog里面没有结构体和枚举类型
SV新引入的类型:双状态数据类型、队列、动态和关联数组、类和结构、联合和合并结构、字符串、枚举类型
二、过程块和方法
scope:定义的软件变量或者例化的硬件所在的空间称为域
硬件世界:module/endmodule, interface/endinterface
软件世界:program/endprogram和class/endclass软件世界
1、initial和always
class里面无initial和always
(1)相同点
- initial和always整体块是并行执行的,内部是顺序执行
- 无法被延迟执行,在仿真一开始它们都会同时执行
- 可以多次使用
(2) 区别
- initial不可综合;always可综合
- initial没有触发条件;always有触发条件
- initial只执行一次,always满足触发条件多次执行
- initial主要用于仿真测试的初始化,always没有限定
- initial过程块可以在
module、interface和program中使用;
always块只可以在module、interface中使用,描述硬件电路的行为
2、function和task
input:从外部复制传入的形式参数
output:由被调用方法产生并复制给外部的形式参数
inout:进入和出去的时候都复制,复制两次
ref:类似于指针,不会有复制行为,直接引用或修改外部传入的数据对象。为使得ref对象只读取不被写入,可以声明为const。
inout和ref的区别是:inout只有在方法结束之后传递到外部,ref随时修改不需要等待结束
(1)function
- 默认的数据类型是为
logic,例如input [7:0] addr。 数组可以作为形式参数传递。 - function可以返回或者不返回结果,如果返回即需要用关键词
return,如果不返回则应该在声明function时采用void function()。 - 只有数据变量可以在形式参数列表中被声明为
ref类型,而线网类型wire则不能被声明为ref类型。只可以通过输入变量来采样线网数值,不能通过ref来直接修改。 - 在使用ref时,有时候为了保护数据对象只被读取不被写入,可以通过
const的方式来限定ref声明的参数。 - 在声明参数时,可以给入默认数值,例如input[7:0] addr =0,同时在调用时如果省略该参数的传递,那么默认值即会被传递给function。
- 默认数据的方向为
input。
(2)相同点
- 函数和任务都不能传递硬件的信号或者reg
(3)区别(4点)
- function可以被函数和任务调用,task只能用任务调用,不能被function调用(因为里面有延时语句,假如没有延时语句SV也是可以调用的)
- function可以通过
return返回;task无法通过return返回结果,因此只能通过output、inout或者ref的参数来返回 - function如果不用return返回值则要声明
void,如果用return返回值则需要声明返回什么类型的值;而task并不用声明返回什么类型的值 - task内可以置入耗时语句,非零时刻执行;而function则不能,从仿真0时刻开始执行,不包含非阻塞赋值。常见的耗时语句包括
@event、wait event、# delay等 - function至少要有一个输入变量,可以没有输出;task可以没有,也可以有多个输入、输出、双向变量
3、变量生命周期
(1)静态变量和动态变量
automatic动态变量:在实例化时调用new初始化,只有实例化才能使用,对象消失它也会消失,如function/task里面的变量
static静态变量:被这个类的所有实例所共享,并且使用范围仅限这个类,不会因为对象消失而消失;在声明时就应该对其初始化,它只初始化一次,也就是在仿真0时刻就存在。在类没有实例化时也可以使用这个变量class::static_variable。
class Transaction;
static int count = 0;
int id;
function new();
id = count++;
endfunction
endclass
Transaction t1,t2;
initial begin
t1 = new(); // t1 中:count = 1,id =0
t2 = new(); // t2 中:count = 2,id =1
$display("t2中count=%0d和id=%0d",t2.count,t2.id);
$display("Transaction中count=%0d",Transaction::count);
end//Transaction类中:count = 2
(2)全局变量和局部变量
全局变量:从仿真开始到结束一直存在的,如module下的变量
局部变量:生命周期和所在域相同,如function/task
(3)静态方法和动态方法
如果方法被static/automatic修饰,那么其内部所有的声明的变量都是 static/automatic的。
静态方法可以在类没有被实例化时被调用,通过 :: 操作符获取,具有全局的静态生命周期;在仿真开始时即会被创建,且可以被多个进程和方法共享。
如果被修饰为 automatic,那么在进入该方法后,automatic变量会被创建,而离开该进程/方法后就被销毁
(4)SV中一些默认的情况
- 在
module、program和interface中定义的task、function默认都是static类型 - 在module、interface和program内部声明,且在task、process或者function外部声明的变量也是static变量,且作用域在该块中
- 在module、program、interface、task和function之外声明的变量拥有静态的生命周期
ABCD
三、interface
-
接口可以用作设计,也可以用作验证;在验证环境中,接口可以使得连接变得简洁而不易出错。
-
可以使用
initial和always,也可以定义function和task。 -
interface可以在硬件环境和软件环境中传递,例如作为module的端口列表,也可以作为软件方法的形式参数。
-
在interface的端口列表中只需要定义
时钟、复位等公共信号,或者不定义任何端口信号,转而在变量列表中定义各个需要跟DUT和TB连接的logic变量。一般没有声明方向,用modport限制信号的方向,不同模块与interface相连时不会发送错误,不会产生反向驱动等问题 -
interface也可以依靠参数化方式提高复用性
-
module可以例化module/interface,interface可以例化interface,不可以例化module
interface reg_if;
logic addr;
logic wr;
logic rd;
modport dut(
input addr,
output wr,rd
);
endinterface:reg_if;
1、clocking block 时钟块
应用场景:接口中的部分信号需要与时钟保持同步,这时信号才可以被同步的驱动或者采样
一般cb驱动采用<=,采样采用=。
delta-cycle:组合/时序电路中无限最小的延时
time-slot时间片:run 0 让仿真器运行无限个delta-cycle的时间
为了避免在RTL仿真行为中发生的信号竞争问题,一般通过非阻塞赋值或者特定的信号延迟来解决同步问题
(1)输入采样、输出驱动、事件同步,定义在interface/module/program里面
(2)默认:输入1step 1个时间片采样(clock上升沿的上一个time slot的postponed区域,保证是上一个时钟周期的数据),输出#0/无数多个delta-cycle再驱动
- 如果直接指定default input #0 ,这会在相应地时钟事件发生的 time slot 的
Observed区域采样。 - 如果直接指定default output #0 ,会作为非阻塞事件,在
NBA区域进行采样。
(3)可以添加多个clocking,同一个变量在不同clocking里面可以声明不同的方向
clocking bus @(posedge clk);
default input #10ns output #2ns;
input data,ready;
output negedge ack;
input #1step addr; //保证采样到的是上一个时钟周期的数据
endclocking
2、modport
用途:对接口信号进行分组并指定方向
虽然定义了不同的modport,但是不同的modport中的同一接口还是一样的,是共同作用的,并不是就变成不同的接口了。也就是说同一个信号可以定义在多个modport里面,都是同一个信号
interface arb_if(input clk);
logic request;
logic rst;
modport TEST(output request,rst);
modport DUT(input request,clk);
modport MONITOR(input request,clk);
endinterface
3、interface好处
- 简化模块之间的连接
- 实现类和模块之间的通信
- 为硬件模块提供了标准化的封装方式,可重用性高

四、SV的仿真调度区域
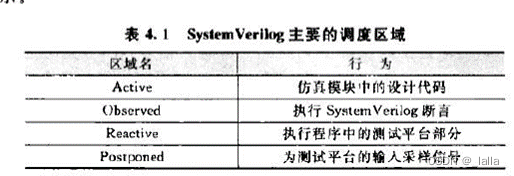
SV的仿真调度机制/调度区域scheduling regions:一个时间片time-slot/Ts内所有线程的优先级
preponed区域:从上一个Ts进入本时间单位的入口
active区域:仿真模块中的设计代码,always、assign、initial等
inactive区域:仿真模块中的设计代码,所有零延时操作的线程在inactive区域被激活,然后前往active区域执行。零延时会延缓线程的执行时间。
NBA区域:仿真模块中的设计代码,在所有active和inactive均没有任何其他线程的情况下到达的区域,之前在active区域的非阻塞赋值生效。
observed区域:SV中的property/sequence,进入这表示前面的设计部分线程全部执行完毕,接下来是验证部分。执行SV的断言。
reactive区域:数据采样之后断言语句要进行属性判断。如果再次赋值,被激活的线程又转到active区域执行。执行程序中的测试平台部分/testbench代码。
postponed区域:前面经历了设计、testbench部分,该区域内数值保持稳定,Tb采样信号。
active、inactive、NBA三个阶段执行设计代码,observed执行断言,reactive执行验证平台代码,postponed数值稳定,是下个Ts采样的数据。
五、program
1、介绍:将设计验证分开,避免竞争冒险
- 将验证部分与设计部分进行有效隔离,因UVM中有更加好的方式将验证与设计部分隔离开来,因此项目中program的使用不是很多。
- 可以在program中定义内部变量,和发起initial块。如果testbench中只有一个program,则会在执行完该program中最后一个
initial过程块后自动结束仿真。如果testbench中有多个program,那么需要等待所有program中最后一个initial过程块完成后,才能结束仿真。有些initial不会自动结束,$exit()强制结束,显式结束 - program中不可以出现硬件行为相关的语句和实例,不可以有
always、interface(硬件软件媒介,中间域)、module(硬件盒子,硬件域)、program(软件盒子,放些验证激励等) - program可以消除delta-cycle竞争问题。加入program的目的是
为了解决testbech和rtl信号可能产生的竞争冒险现象
2、program和module区别(3点)
-
module里不能调用program里定义的task/function,而program可以调用module里定义的task/function;
-
program里不能例化module,interface,其它program,也不能包含always块;而module都可以,module里可以定义program
-
program中的initial块在
reactive区域执行,module中的initial块在active区域执行,所以program在module后执行,可以解决竞争冒险现象
3、program使用建议
我们建议将设计部分放置在module中,而将测试采样部分放置在program中。
下面是更多关于program实现的要求和建议:
- 读者可以将program看做是软件的"领地"”,所以program中不可以出现和硬件行为相关的过程语句和实例,例如
always、module、interface,也不应该出现其它program例化语句。 - 为了使得program进行类软件方式的顺序执行方式,可以在program内部定义变量,以及发起多个initial块。
- program
内部定义的变量赋值的方式应该采用阻塞赋值(软件方式)。 - program内部在
驱动外部的硬件信号时应该使用非阻塞赋值(硬件方式)。
六、深拷贝和浅拷贝
module shallow_copy();
class A;
integer j = 5;
endclass
class B;
integer i =1;
A a;
function new();
this.a=new();
endfunction
endclass
B b1,b2;
initial begin
integer test;
b1=new();//创建一个B的对象
b2=new b1;//复制b1对象
b2.i=10;//改变b2中i的值
b2.a.j=50;//改变b2中a.j的值
test=b1.i;
$display( "test is %d",test); //输出为1
test=b2.i;
$display("test is %d", test); //输出为10
test=b1.a.j;
$display( "test is %d",test); //输出为50
end
endmodule
从上面结果可以看到,修改b2.a.j的值,结果b1.a.j的值也同样发生了改变
浅拷贝shallow copy:对于变量i,会复制一个新的对象出来,对于对象a,复制的引用,不是一个新的对象。所以当改变b2的值时,b1的值也会发生改变。只拷贝对象中的成员变量和声明的句柄
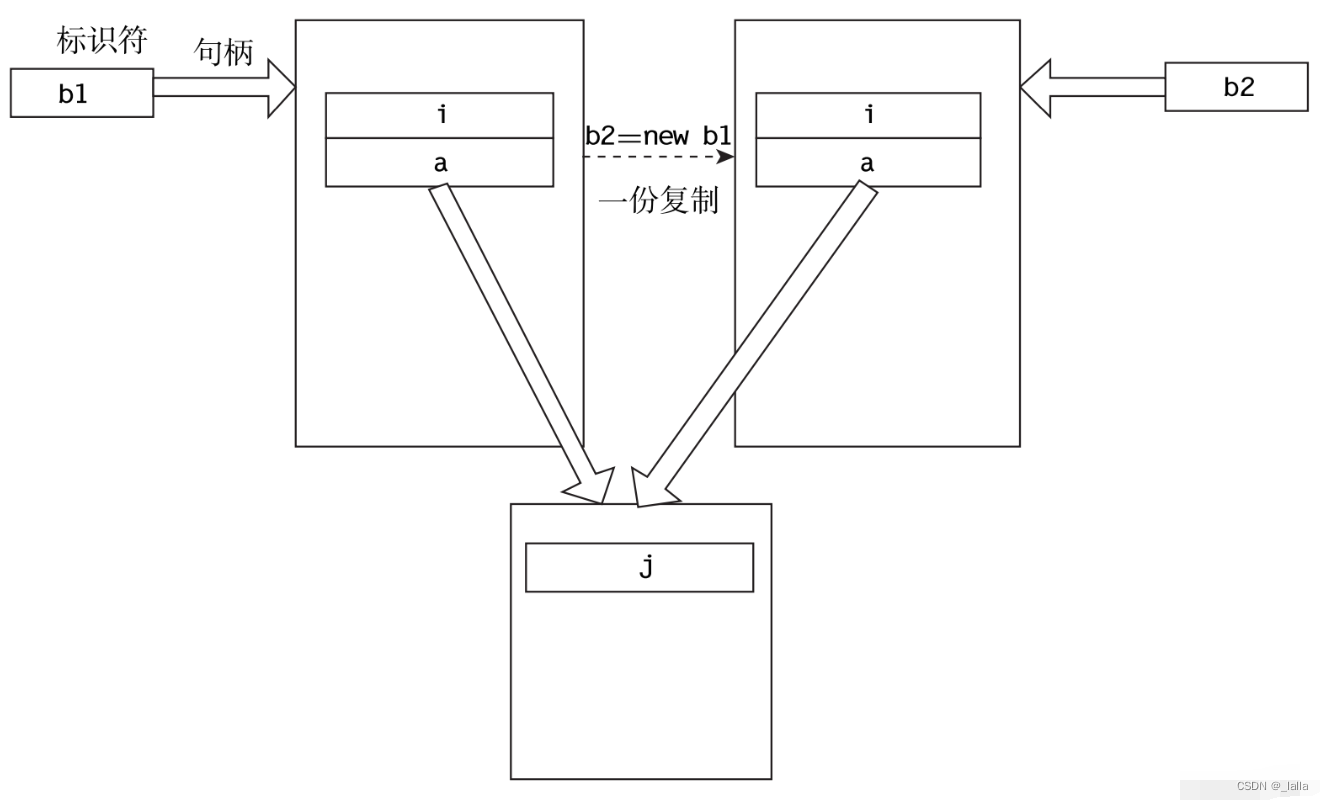
深拷贝deep copy:每一个数据成员 (包括嵌套的对象)都要被复制。复制对象中的所有成员变量以及对象中嵌套的其他类的实例的内容
module deep_copy();
class A;
integer j = 5;
endclass
class B;
integer i =1;
A a;
function new();
this.a=new();
endfunction
function B deep_copy();
B b=new();
b.i=this.i; //新建一个i
b.a.j=this.a.j;
return b;
endfunction
endclass
B b1,b2;
initial begin
integer test;
b1=new();
b2=b1.deep_copy; //调用deep_copy函数,返回值为b1的句柄,
b2.i=10;
b2.a.j=50;
test=b1.i;
$display( "test is %d",test); //1
test=b2.i;
$display("test is %d", test); //10
test=b1.a.j;
$display( "test is %d",test); //5
test=b2.a.j;
$display( "test is %d",test); //50
end
endmodule
总结:
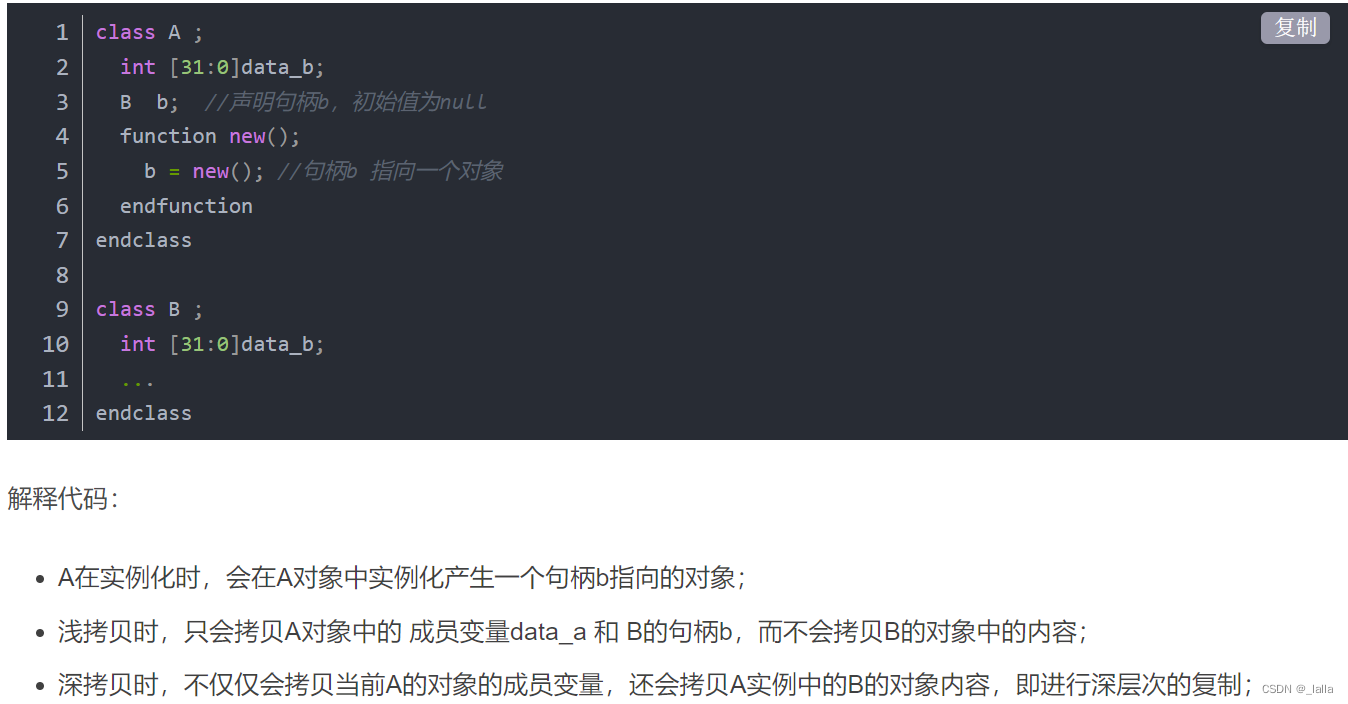
深拷贝和浅拷贝的区别是指在复制一个对象时,是否也复制它包含的子对象。
- 浅拷贝只复制对象的结构,不复制它包含的子对象。浅拷贝后,两个对象共享同一个子对象。如果修改了子对象,那么两个对象都会受到影响。
- 深拷贝复制对象的结构和它包含的子对象。深拷贝后,两个对象完全独立,不共享任何子对象。如果修改了子对象,那么只有一个对象会受到影响。
面试题目
1、SV和verilog的区别
- Verilog作为硬件描述语言,用来描述数字电路的语言,倾向于设计人员自身懂得所描述的电路中哪些变量应该被实现为寄存器,而哪些变量应该被实现为线网类型。这不但有利于后端综合工具,也更便于阅读和理解。
- SystemVerilog是一种在Verilog基础上扩展的语言,提供了更丰富的功能和特性,旨在改进硬件设计和验证的能力。如面向对象编程、引入新的数据类型(logic、枚举、结构体)、验证的特性(随机约束、断言、事务级建模)、直接内存访问(DMA)语法等。
- SV作为侧重于验证的语言,并不十分关切logic对应的逻辑应该被综合为寄存器还是线网,因为logic被使用的场景如果是验证环境,那么它只会作为单纯的变量进行赋值操作,而这些变量也只属于软件环境构建。 logic被推出的另外一个原因也是为了方便验证人员驱动和连接硬件模块、而省去考虑究竟该使用reg还是wire的精力。这既节省了时间,也避免了出错的可能。















 121
121











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









