







摘要:
近期工作常常集中在提高深度图的准确率上,并且在KITTI等公开数据集上测试结果,它们都展现了神经网络对深度估计的作用,但是没有说如何做的。
本文选用Godard的Monodepth网络来研究它使用什么样的视觉线索来对深度进行估计。我们发现,网络忽略了已知遮挡物的明显大小而选择了图像上的垂直位置(vertical position)。使用水平位置需要已知相机的位姿,然而monodepth只对相机俯仰(pitch)、旋转、和由于遮挡影响估计的部分进行了修正。
我们还展示了monodepth利用垂直图像位置去估计任意遮挡物的距离,即时它没出现在训练集中,但是它需要地面上的边缘与遮挡物体有很紧密的接触才能做到,未来还会应用在其他网络,看是否有同样的效果。
一、介绍
当深度必须由相机图像估计出来时,双目视觉是一个普遍选择;当只能使用单个相机时,光流能够提供对深度的测量;如果图像能够长时间获取那么SLAM和 Structure-from-Motion能够估计场景的结构关系,这些方法都将深度估计看作为几何结构问题,但是完全忽略了图像内的内容。
当只有单张图像时,是不可能使用对极几何的,算法只能依赖于图像线索:能够代表单目图像深度的线索,比如已知物体的明显大小。图像线索需要已知环境信息,通常很难编入,因此被认为关联很少,直到最近才被应用。
随着硬件的发展,目前可以从data中学习图像线索而不是手动标记,最早使用机器学习进行深度估计的是Saxena et al. [14].在2014年,Eigen et al. [3],使用CNN网络进行了单目深度估计(仍使用真值进行训练)。2016年Grag.[7] 使用新的算法采用双目视频对进行训练方法,并由Godard [10] 进行改进。
二、相关工作
特征可视化和成因被用来分析CNN的效果,本质上来说,神经网络使用的特征能够通过优化基于激发相对神经元、特征图或整个网络层的损失函数对输入图像来看到。这些方法了解CNN网络都做了什么(并且对未来的工作很有用),他们没有直接说明深度是如何被估计的。神经网络所提取的一系列特征不是对它行为的解释,还需要更多的解释和实验。
将神经网络看作是一个黑盒,只用来计算某些输入的反馈(在这里是深度图)。我们修正或者向图像添加干扰,而不是优化与损失函数相关的输入,为了确保这样加入了相互冲突的视觉线索,并且寻找深度图的内部关联。
关于人类深度感知的文献关注图像线索,并且被用来估计深度,以下线索来自[8]和最近的评论[1], [2],通常能够在单张图像中找到:
(1)图像中的位置。离得很远的物体要离地平线更近一些,当物体在地面上时,会显得很高
(2)遮挡。离得更近的物体会遮挡在它们后面的物体,遮挡提供了深度顺序但是没有准确距离
(3)稠密纹理。更远的纹理表面显得更有纹理
(4)物体的明显大小。越远越小
(5)阴影与明亮。直接光照的表面会显得更明亮,光通常被假设从上照下来的,阴影通常提供关于表面内部深度变化的信息,而不是相对于图像的其他部分。
(6)聚焦模糊。位于焦平面前面和后面的物体模糊
(7)空中视角。非常远的物体(千米)具有非常少的对比,并且通常是蓝色的
有了这些线索以后,我们认为只有图像中的位置和物体的明显大小能够适用于KITTI数据集。其他的线索由于低分辨率(纹理稠密,聚焦模糊)、限制的深度范围(空中视角)或者他们与估计障碍物的距离不相关(遮挡、照明、直线透视图)
两个线索在冲突条件下被人类观察,特别是视觉图像的垂直位置有一些重要的细微差别。比如, Epstein指出,感知距离不仅取决于视野中的垂直位置,还取决于背景。在天花板般的背景下,视野较低的物体会被更远的地方而不是其周围。
另一个重要的内容特征是水平线,当很少地面(或天花板)纹理存在时,水平线就变得更加重要。Ooi et al.证明人类在现实世界使用的是相对于'眼睛水平'的角度倾斜而不是视觉水平,眼睛水平是视野中地平线的预期高度。
物体的明显大小影响着估计的深度。Sousa 做了一个测试者需要判断不同大小立方体距离的实验。并且观察到即使立方体的真正大小不知道并且视野的高度和其他线索存在但是还是会影响对深度的估计。
三、位置VS明显大小
如上一部分所讲位置和明显大小是网络最可能利用的线索。图一展示了怎么利用这些线索去估计遮挡物体的距离。假设摄像机的焦距已知且固定,并由网络隐式的学习,给定障碍物的真实大小H和图像中的表观大小h,可以使用以下方法估计距离(figure1):


这需要知道遮挡物体的真实大小H,而KITTI数据集上具有有限类的遮挡物(汽车 卡车 行人)其中每类物体的大小大致相同。因此,网络有可能学会了识别这些物体,并使用它们的表观大小来估计它们的距离。
或者,网络可以使用物体地面接触点的垂直图像位置y来估计深度。给定相机在地面上的高度Y,可以估计距离通过:

这个方法不需要知道任何物体的真实大小,但是要假设地面平滑的以及一个固定或者已知的相机位姿。这些假设在KITTI数据集中也是有效的。
A.评价方法
为了研究哪种线索被网络所使用,生成了三组测试图像。其中:
- 一组物体的明显大小变化但是离地面接触点的垂直距离不变;
- 一组垂直距离改变但是大小保持不变;
- 最后一组,其中的表观大小和位置都随距离而变化;
测试图像按如下生成:将物体(大部分是汽车)从KITTI’s scene flow dataset中剪裁出来。每个物体根据其相对相机的位置被标注出来(比如:左边一条小路朝着摄像机)以及他们裁剪之前所在的图像位置。
第二,每个在测试集的图像都对遮挡物可能插入的位置进行了标注(例如:摄像机左面的小路始终是空的)。结合这样的物体标注信息来确保测试图像可信
被插入的物体的真实距离是不知道的(即使可以通过雷达图像采集),而是对网络测量相对深度的能力进行评估。这个距离是相对于从原来图像中剪裁出的物体大小和位置,其相对距离被定义为Z' / Z = 1这个距离由1.0到3.0的幅度增大,并且控制缩放比例s和物体位置x' , y'如下:
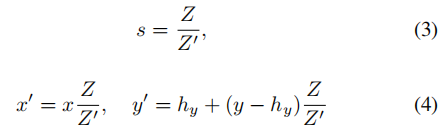
x' 和 y' 是物体的地面接触点的新坐标,hy是图像的水平高度在数据集中假定是不变的,图像坐标x,x',y,y'从图像中心测量。
估计到汽车的深度通过深度图对汽车前面的平坦区域或后面周围的前、尾灯(图二 figure2)进行评估。使用平坦区域而不是整个物体是为了防止估计的车辆长度影响深度估计、其长度很可能与物体大小有关,但是距离则不是。

B、结果
实验结果由图三(figure3)所示。当位置和尺度同时改变,估计效果仍然与这些物体真实深度相近,说明网络能够正确对这些人造图像进行处理。当只有垂直位置被改变,MonoDepth依然能够对物体深度进行估计,但是与控制集相比,距离估计的标准差明显增大了,最特别的结果是只改变物体的明显大小保持与地面接触点不变:MonoDepth在这种情况下结果没有变化

结果表明,MonoDepth更依赖于物体的垂直位置而不是明显大小,即使改变大小对结果有一些影响。对垂直位置的使用暗示了MonoDepth假定水平地面以及已知相机的一些位姿。
四、相机位姿:固定还是估计的?
使用垂直相机位置去估计障碍物深度需要知道相机高度和俯仰的信息:它可以从输入图像得到相机倾斜信息(通过寻找水平或者消失点)
或者可以假设相机位姿是固定的。这一假设在KITTI数据集上可以相当好地工作,因为数据集中相机被固定在汽车上,唯一的偏差来自于相机的俯仰以及从汽车的悬挂和地形上的斜坡的俯仰和隆起运动。这意味着,训练过得网络不能直接在别的设备上使用,因此需要研究monodepth是否假设为固定相机位姿或者可以估计并且可以在线校正(on-the-fly)
A、相机倾斜
如果MonoDepth可以测量相机倾斜,那么改变相机倾斜应该能够反映在估计的深度图上。如果它假设在地面上相机位姿是固定的,那么地面应该在深度估计中保持不变。
没有改变过的KITTI测试图像的水平线位置由于相机俯仰和汽车升降已经有所改变。为了去测试Monodepth是否能够在这些改变下做出正确估计,我们寻找图像中的真实视界水平(根据Velodyne数据确定)与深度估计中的估计视界水平之间的相关性。
水平位置是将深度图的中间区域(路面)剪裁测量得到,并且使用RANSAC对disparity-y拟合出一条直线(Figure 4),将这条线推断为零视差(即无限远)来给出图像中地平线的高度(可能是由于不管车辆如何移动也不会改变最远处地平线在相机中的位置,因此视差为0,最低的地方即为地平面,其他的可能是天空。同理越近的地方视差越大,越远的地方视差越小,视差相同的像素距离相机的距离相同,其最低的Y应为地平面上的点,于是能够找到整个地平面),对每个图像进行五次这样的过程,来平均来自RANSCAC过程的误差

图4:从真实或估计的深度图估计地平线水平位置。像素y和视差disparity是从图像的底部中心收集的。路面是用RANSAC拟合的,结果是从视差为0(即无穷远)处出发找到整个地平面水平位置。
图5(figure5) 展示的是真实与估计的水平线之间的关系,虽然人们期待MonoDepth对地平线水平是否正确,但发现了0.60的回归系数,表明它起到了一定作用。第二个实验是为了排除Velodyne数据以及第一个实验中真实水平的小(±10px)范围的任何问题。

图5:未经修改的KITTI图像的真实和估计的水平线。我们发现了一个偏大的的相关关系(Pearson’s r = 0.50, N = 1892),但是斜率只有0.60,这表明在估计的深度图中并没有完全反映出地平线的真实位移。
在第二个实验中,从图像(图6)中不同高度剪裁出一个小区域。对每张图像,从相机中心偏移+-30像素范围截取7块,接近于相机俯仰有2-3度的变化。没有使用Velodyne数据估计真实水平线, 利用中央裁剪图像的深度估计出的水平位置作为参考值。换句话说,这个实验评价的是水平线的变化对于深度估计的影响,而不是它的绝对位置。

图6:对图像在不同高度剪裁来模拟大的相机俯仰
结果由图7(figure7)所示, 与上一次实验相似的结果是:MonoDepth能够检测到相机俯仰的变化,但在深度估计中没有充分考虑这些变化。这个实验的回归系数有0.71

图7:在不同高度裁剪图像后,水平线的真实和估计变化。阴影区域表示±1SD(N=194,六个离群值>3SD去除)。回归系数为0.71发现(Pearson’s r=.92,N=1358),再次表明相机俯仰的变化不能完全显示在深度图中。
由于MonoDepth利用遮挡物的水平位置来估计深度,我们期待希望用相机的俯仰来改变深度估计的效果来弥补这一缺陷。为了验证这一猜想,我们使用相同的俯仰截取的数据集并且评估相机俯仰的变化能够对遮挡物的视差有巨大变化。
遮挡物由KITTI场景流数据集中选取200个训练图像,其中obj_map被用来选取属于遮挡物的像素,结果如图8(figure8)所示,遮挡物的距离的确被相机俯仰所改变了。

图8:改变相机的俯仰会影响相对于遮挡物的深度估计
B.相机滚转
与俯仰角度相似,相机滚转角度会影响相对于遮挡物的深度估计,如果相机具有非零的滚转角度,相对于遮挡物的距离不仅依赖于他们的垂直位置,还和水平位置有关。
对俯仰角度变化也做了相似实验:对图像在不同角度切割出小区域(figure9).然后从估计的深度图中提取滚转角度(figure10)。
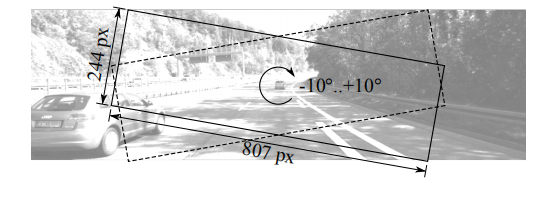
图9:由裁剪较小块模拟相机滚转,倾斜的区域取自KITTI图像

图10:相机滚转角是通过对视差图中视差在0.03到0.031之间的所有像素采样得到,然后使用Hough线探测器来拟合路面
在之前的实验中,我们寻找相机角度和路面估计角度变化之间的联系结果如图11(figure11),与俯仰角度结果相似。MonoDepth能够发现相机的滚转角,但是这个角度对深度图影响很小

图11:裁剪图像中的真实和估计的偏移。 路面角度的变化小于图像裁剪的真实角度。 阴影区域显示±1SD(N = 189, eleven outliers > 3 SD removed)
五、遮挡物识别
第三部分说明了 MonoDepth使用物体在图像中的垂直位置估计它们的距离。要进行估计只需要物体的地面接触点的位置。由于不需要知道其他信息(真实世界大小),这使得Mono能够对任意遮挡物的距离进行估计。然而,图12(Figure12)说明了并不总是如此,汽车被识别为了遮挡物但是其他物体没有被识别出来并且在深度图中消失了并显示为平坦路面。
为了能够估计出遮挡物的深度,神经网络应该:
1)找到遮挡物的地面接触点,用来估计距离 ;
2)找到遮挡物的轮廓,为了填补深度图的相应区域。

图12的结果表明,Mono依赖于一组适用于汽车的特性,而不是插入到测试图像中的其他对象的特性
A、颜色和纹理
插入图12的物体与车辆颜色、纹理、形状不同 ,在第一个实验,我们通过评估KITTI图像的修改版本来研究颜色和纹理产生的影响。
对于颜色的影响,生成了两个新的测试集:
- 图像转为灰色来移除所有颜色信息;
- 其中色调和饱和度通道被KITTI的semantic rgb数据集中的通道所取代,以进一步干扰图像中的颜色信息
关于纹理的两个数据集:
- 其中所有的对象都被一该对象类的颜色平均值代替—去掉所有的纹理,但保持颜色不变;
- 语义rgb本身设置了对象被不真实的平坦颜色代替。 变化的图像以及深度图的结果如图13(figure13),表1列了测试结果


图13: 未修改的示例图像和深度映射,灰度,假颜色,类平均颜色和语义rgb图像..

只要图像中的值信息保持不变(未修改、灰度和假彩色图像),Mono的效果几乎差不多, 灰度图像的误差略有增加,添加假颜色时误差进一步增加,但所有误差和性能度量仍然接近原始测试集的误差和性能度量。这说明遮挡物的颜色对深度估计影响不大。
当只使用了平滑颜色(类平均色和语义RGB)发现效果有明显下降,该网络在错误颜色的语义rgb数据集上的表现也比在颜色更真实的类平均颜色数据集上的表现要好,这进一步表明障碍物的确切颜色并不重要。相反,其他特征:比如物体内部相邻区域或明亮和黑暗区域之间的对比可能更重要
B、形状和对比
物体不需要被发现相似的纹理或形状(Figure 14),粘贴在图像的三角被正确检测出来了,其中上面的具有汽车的纹理,下面的全部是黑色。距离似乎是跟随不熟悉物体的最低点。这支持了距离是根据图像中的垂直位置来估计的,并假定物体停留在地面上的说法。

图14:物体不需要有熟悉的纹理或形状来检测。与这些不存在的障碍的距离似乎取决于其较低程度的位置
特别的是,物体的边缘及其与环境对比对于正确的距离估计似乎最重要。在Figure 15中我们移除了多种车,得到的深度图显示神经网络填补一个物体,主要是依靠它的
底部! 和 边缘! (图15右下角)


图15: 汽车部件和边缘对深度图的影响。 移除轿车中心(右上角)对检测无明显影响.. 汽车的底部和侧面(右下角)似乎 最多对检测到的形状有影响,这几乎与完整的汽车图像相同(左上角)。
例如,右下角的图像,只有底部和侧面的边缘,仍然导致一个几乎完全检测到的汽车。把底部的边缘留下来,就可以发现车的两侧是分开的,很薄的物体。
请注意,图15中的边缘与环境有显著的对比。 在KITTI数据集中,汽车下面的阴影几乎在所有情况下都提供了高对比度的底部边缘,事实上,在图12中一个没有被检测到的物体下面添加影子能够成功被识别到(Figure16), 然而,在深度图中,冰箱只延伸到冰箱两节之间的边缘,使深度图垂直方向小于它应该的大小。
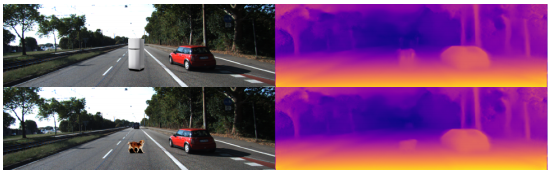
图16: 在图12的对象底部添加一个阴影会导致它们被检测到。 然而,冰箱只被检测到底部和顶部门之间的下一个水平边缘。
VI、总结和未来工作
在本工作中,我们已经证明了Godard等人的Monodepth主要是利用物体在图像中的垂直位置来估计它们的深度,而不是它们的明显大小, 这一估计取决于相机的姿态,但这种姿态的变化并没有得到完全的解释,导致在摄像机俯仰变化时对障碍物距离的低估或高估。 我们进一步表明,MonoDepth可以检测不出现在训练集中的对象,但是这种检测并不总是可靠的,取决于外部情况,如物体下面存在阴影。这些都是重要的限制,在最初的工作中没有提到-也没有在任何其他关于单目深度估计的工作中提到-从而突出了我们的观点,即这些行为的学习行为。在未来的工作中,我们计划重复在这里发表的与其他网络和数据集的实验,看看是否学习了相同的行为。















 475
475











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









