







《------往期经典推荐------》
二、机器学习实战专栏【链接】,已更新31期,欢迎关注,持续更新中~~
三、深度学习【Pytorch】专栏【链接】
四、【Stable Diffusion绘画系列】专栏【链接】
五、YOLOv8改进专栏【链接】,持续更新中~~
六、YOLO性能对比专栏【链接】,持续更新中~
《------正文------》
引言
我们已经有了高效的神经网络,MobileNet和ResNet,它们在轻量级的同时取得了令人印象深刻的结果。但这里有一个挑战:如果我们想让这些网络变得更大、更精确,仅仅增加深度(更多层)、宽度(更多通道)或更高的图像分辨率是不够的。虽然这些调整都可以提高准确性,但它们需要平衡。否则,我们最终会得到一个庞大而低效的模型。
如何使深度(更多层)、宽度(更多通道)或更高的图像分辨率达到平衡以获取更好的性能,EfficientNet就是个很好的例子。
EfficientNet核心思想
EfficientNet论文解决的核心问题是:
“是否有一种原则性的方法来扩大ConvNets,以实现更好的准确性和效率?”
EfficientNet的答案是复合缩放。EfficientNet不是单独增加深度、宽度或分辨率,而是按比例同时扩展这三个方面。这种平衡的增长使模型能够在不需要不必要的计算的情况下*提高*准确性*,并在不牺牲有效性的情况下最大限度地提高效率*。
为什么是深度、宽度和分辨率?
在典型的神经网络中,如果你想提高精度,你可以:
- 增加深度-添加更多的层有助于模型捕捉复杂的模式。
- 增加宽度-增加更多的通道使网络“更宽”,增加其容量。
- 提高图像分辨率-使用更高质量的图像捕捉更精细的细节。
这些方法中的每一种都提高了准确性,但是单独缩放它们会导致效率低下,臃肿的模型,消耗过多的计算能力而不会产生最佳结果。EfficientNet的复合缩放实现了准确性和效率之间的平衡。
相关工作
《EfficientNet》的作者建立在ConvNet设计的几项基础进步之上。早期的模型,如AlexNet,开创了“更大”模型的先例,通过增加参数来实现更高的准确性。随后的模型,如GoogleNet和SENet继续朝着这个方向发展,达到了令人印象深刻的准确性,但需要大量的计算资源。GPipe进一步提高了精度,在ImageNet上达到了84.3%的top-1精度,尽管其5.57亿个参数使其对许多现实世界的应用程序来说不切实际。
在效率方面,作者强调了SqueezeNet、MobileNet和ShuffleNet等模型,这些模型旨在减少模型大小以适应移动的和低功耗设备。此外,**神经架构搜索(NAS)**已被用于通过优化宽度和深度等参数来自动化有效的模型设计。
虽然深度、宽度和分辨率在这些模型中单独进行了调整,但EfficientNet的方法通过复合缩放将所有三个维度独特地结合起来,以实现平衡增长,旨在实现准确性和效率。
复合尺度:最优化问题
EfficientNet的复合缩放方法旨在以平衡的方式在三个维度(深度,宽度和分辨率)上扩展神经网络。目标是在保持资源限制(如内存和计算能力)的同时最大限度地提高准确性。这就产生了一个优化问题:找到缩放因子的最佳组合,以在保持资源限制的同时最大限度地提高精度。😉
把深度、宽度和分辨率看作是“旋钮”,你可以调大或调小它们,使网络更大或更强大。挑战是要弄清楚每个旋钮转动多少,以提高精度,而不过度使用资源。这就是为什么EfficientNet引入了三个缩放系数:
- *d*:控制深度(网络有多少层),
- *w*:控制宽度(每层有多少神经元/通道),
- *r*:控制分辨率(输入图像的大小)。
其目标是在内存和FLOPS(计算成本)的约束下最大限度地提高精度。简而言之:我们如何以平衡的方式扩展深度、宽度和分辨率,以获得最佳性能,而无需高计算成本?
主要意见
为了解决这个优化问题,作者提出了两个关键的观察结果。
观察结果一:仅缩放这些维度中的一个(深度、宽度或分辨率)会达到一个点,进一步缩放不会增加太多准确性。每一个维度都有极限,扩展任何一个都会导致收益递减。
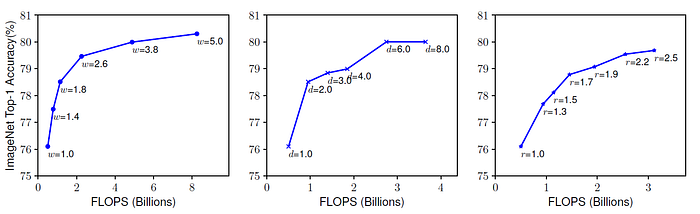
图1:缩放单个维度对ImageNet精度和FLOPs的影响
- 宽度:增加宽度(每层更多的通道)有助于在一开始捕捉更多的细节,但使其太宽会导致有限的精度增益和更高的内存成本,如图****1a所示。
- 深度:添加更多的层最初会提高准确性,但超过某个点,准确性就会趋于稳定,因为更深的网络变得更难训练(由于梯度消失等问题)。这在图1b中示出。
- 分辨率:增加输入分辨率(使用更高质量的图像)最初会提高精度,但更高的分辨率会带来显著的计算成本,并且精度增益最终会变平。这在图****1c中示出。
观察2:同时实现精度和效率的最佳方法是同时缩放深度、宽度和分辨率,而不是单独缩放。
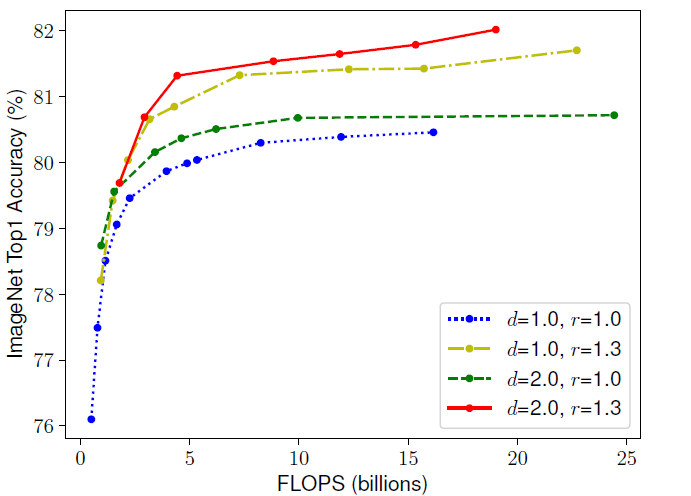
图2:缩放尺寸对准确度和FLOPS的影响
在图2中,线中的每个点表示具有不同宽度系数(w)的模型。最初,仅缩放宽度(同时保持深度d=1.0*和分辨率r=1.0*)很快导致精度饱和。然而,当深度(*d=2.0*)和分辨率(*r=1.3*)也同时缩放时,宽度缩放在相同的FLOPS成本下实现了更好的精度。这种平衡缩放方法突出了第二个观察结果。
使用复合缩放解决问题
为了解决这个优化问题,EfficientNet引入了一个复合缩放公式。他们定义了一个公式,根据一个缩放因子,以平衡的方式调整所有三个维度,而不是手动决定每个维度的缩放幅度。
它是这样工作的:
- 它们引入了三个常数:α、β和γ,分别表示它们将缩放深度、宽度和分辨率的程度。
- 然后,他们定义:
- 深度:d=α^λ
- 宽度:w=β^λ
- 分辨率:r=γ^λ
在这里,网络是控制整个网络增长的主要缩放因子。举例来说:
- 如果λ =1,则深度按α缩放,宽度按β缩放,分辨率按γ缩放。
- 如果λ =2,则深度按α²缩放,宽度按β²缩放,分辨率按γ²缩放。
网格搜索最佳常数:他们使用网格搜索来找到α,β和γ的最佳值,确保这些常数导致平衡增长,从而在约束条件下最大限度地提高精度。
高效网络架构
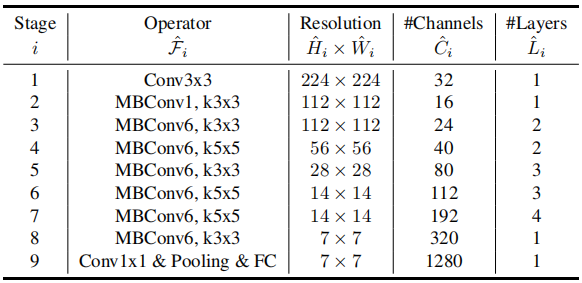
表1:EfficientNet-B 0基线架构
虽然MobileNet和ResNet是高效的网络,但它们的设计并没有考虑到复合扩展。为了充分利用复合扩展的潜力,EfficientNet团队需要一个从头开始高效的基线网络-一个专门优化以平衡方式扩展的网络。这促使他们设计了自己的模型EfficientNet-B 0。
为了实现这一目标,他们将EfficientNet-B 0作为一个优化问题来处理。然而,与平衡深度,宽度和分辨率的复合缩放优化不同,这种优化针对网络的架构本身,确保每一层都有助于高精度和低计算成本(以FLOPS衡量)。他们使用了一种称为多目标神经架构搜索(NAS)的方法来自动化这个过程。
在此NAS过程中,探索并评估了每层的各种配置,以最大限度地提高精度,同时最大限度地减少FLOPS。例如,NAS会测试不同的内核大小(例如,3 × 3,5 × 5),信道计数(例如,16,24,32),以及卷积运算的类型(例如,标准与依赖可分离),最终选择最佳组合以在准确性和计算效率之间进行权衡。
这种优化的结果是EfficientNet-B 0的架构,如表1所示。网络的每个阶段都经过精心设计,以便在深度、宽度和分辨率上进行高效扩展,从而为复合扩展奠定平衡的基础。
实验结果
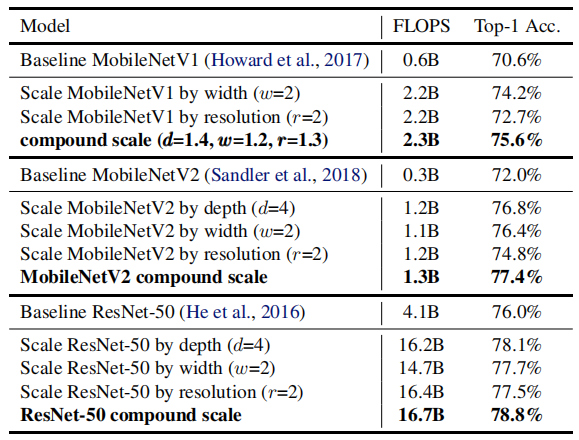
表2:扩展MobileNets和ResNet
为了验证他们的复合扩展方法,作者最初将其应用于现有网络MobileNet和ResNet,如表2所示。当仅缩放宽度或分辨率时,这些网络实现了适度的精度增益。然而,复合缩放(他们提出的方法)在MobileNetV 1,MobileNetV 2和ResNet-50中始终具有更高的准确性。虽然这种方法导致了FLOPS的增加,但精度的提高使这种权衡是值得的。
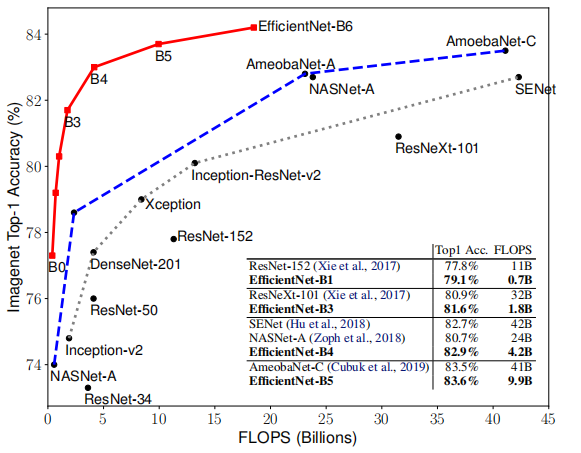
图3:与其他最先进的网络相比,ImageNet Top-1精度与EfficientNet模型(B 0到B6)的FLOPS。
在此之后,作者在ImageNet上评估了他们的EfficientNet模型(B 0到B7)。图3展示了EfficientNet与其他流行架构的性能比较。EfficientNet模型在准确性和计算效率之间实现了很好的平衡,每个模型的性能都优于ResNet、SENet和NASNet等竞争对手,FLOPS明显更低。例如,EfficientNet-B1仅需0.7B FLOPS即可实现79.1%的准确度,而ResNet-152需要11B FLOPS才能实现77.8%的准确度。
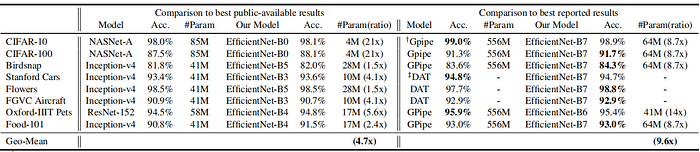
表3:迁移学习数据集上的EfficientNet性能结果
EfficientNet还在各种流行的迁移学习数据集上进行了评估,如表3所总结。该表突出显示了EfficientNet在多个任务中的上级性能,通常以显著更少的参数实现最高精度。例如,EfficientNet在8个数据集中的5个数据集上达到了最先进的精度,而与NASNet-A和Inception-v4等其他模型相比,平均使用的参数少了9.6倍。
关键要点
以下是论文中最重要的内容:
- EfficientNet使用复合缩放方法来按比例平衡深度,宽度和分辨率,提高准确性,同时最大限度地减少资源使用。
- EfficientNet-B 0是使用神经结构搜索(NAS)设计的,以优化高精度和低计算成本。
- EfficientNet系列(B 0至B7)从B 0向上扩展,与其他型号相比,使用更少的参数和FLOP实现一致的性能改进。
- 只缩放一维(深度、宽度或分辨率)会导致精度递减; EfficientNet的复合缩放更有效。
- 在ImageNet上,EfficientNet模型提供了最先进的准确性,计算成本比ResNet和NASNet等替代方案低得多。
- EfficientNet也擅长迁移学习。它在CIFAR-10和斯坦福大学汽车等数据集上实现了最佳性能,同时使用的参数减少了9.6倍。

好了,这篇文章就介绍到这里,喜欢的小伙伴感谢给点个赞和关注,更多精彩内容持续更新~~
关于本篇文章大家有任何建议或意见,欢迎在评论区留言交流!


















 2987
2987

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











