






点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达
什么是感受野
The receptive field is defined as the region in the input space that a particular CNN’s feature is looking at (i.e. be affected by).
—— A guide to receptive field arithmetic for Convolutional Neural Networks
感受野(Receptive Field),指的是神经网络中神经元“看到的”输入区域,在卷积神经网络中,feature map上某个元素的计算受输入图像上某个区域的影响,这个区域即该元素的感受野。
卷积神经网络中,越深层的神经元看到的输入区域越大,如下图所示,kernel size 均为3×3,stride均为1,绿色标记的是Layer2每个神经元看到的区域,黄色标记的是Layer3 看到的区域,具体地,Layer2每个神经元可看到Layer1上3×3 大小的区域,Layer3 每个神经元看到Layer2 上3×3 大小的区域,该区域可以又看到Layer1上5×5 大小的区域。
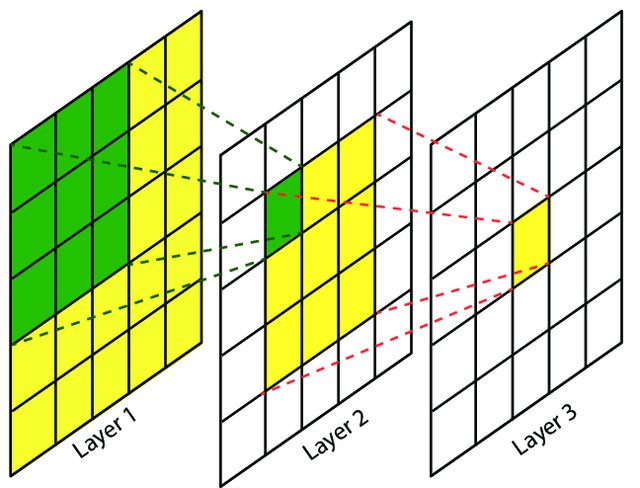
所以,感受野是个相对概念,某层feature map上的元素看到前面不同层上的区域范围是不同的,通常在不特殊指定的情况下,感受野指的是看到输入图像上的区域。
为了具体计算感受野,这里借鉴视觉系统中的概念:
receptive field=center+surround
准确计算感受野,需要回答两个子问,即视野中心在哪和视野范围多大。
只有看到”合适范围的信息”才可能做出正确的判断,否则就可能“盲人摸象”或者“一览众山小”;
目标识别问题中,我们需要知道神经元看到是哪个区域,才能合理推断物体在哪以及判断是什么物体。
但是,网络架构多种多样,每层的参数配置也不尽相同,感受野具体该怎么计算?
约定
在正式计算之前,先对数学符号做如下约定:
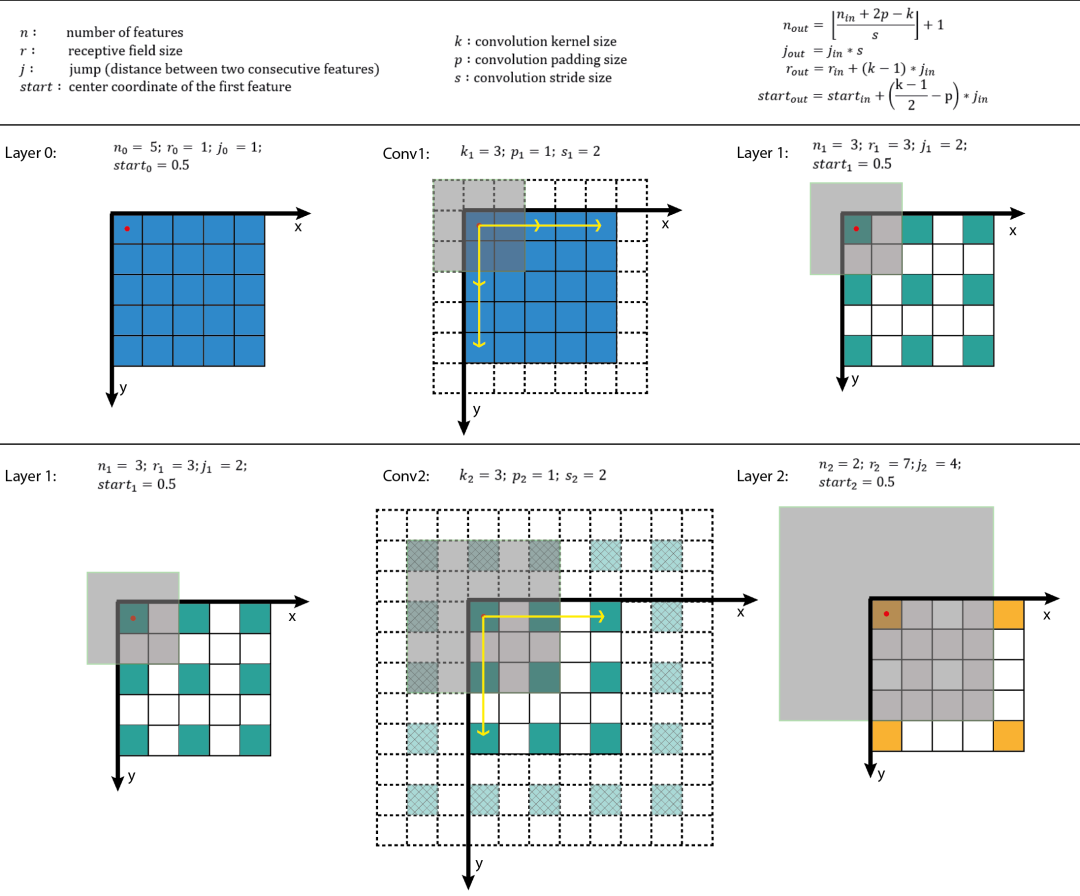
k:kernel size
p:padding size
s:stride size
Layer:用Layer表示feature map,特别地,Layer0为输入图像;
Conv:用Conv表示卷积,k、p、s为卷积层的超参数,Convl的输入和输出分别为Layerl−1和Layerl+1;
n:feature map size为n×n,这里假定height=width;
r:receptive field size为r×r,这里假定感受野为方形;
j:feature map上相邻元素间的像素距离,即将feature map上的元素与输入图像Layer0 上感受野的中心对齐后,相邻元素在输入图像上的像素距离,也可以理解为 feature map上前进1步相当于输入图像上前进多少个像素,如下图所示,feature map上前进1步,相当于输入图像上前进2个像素,j=2;
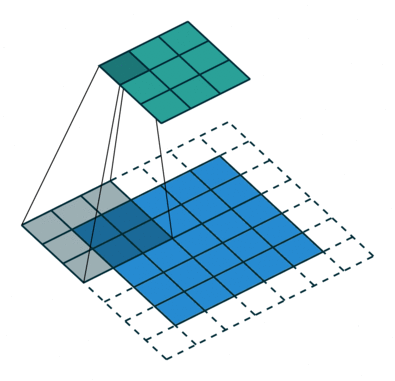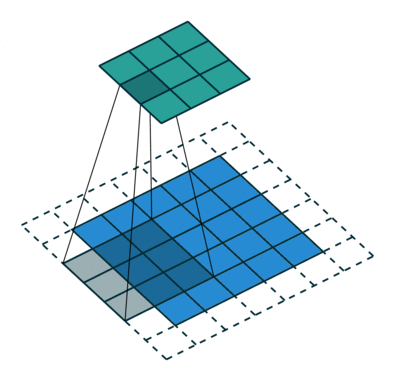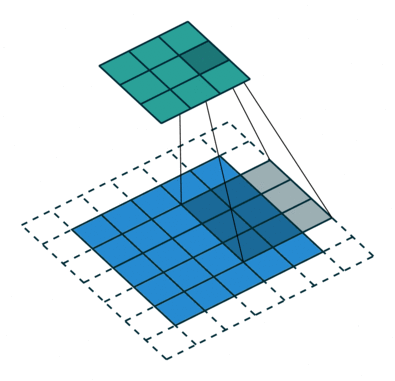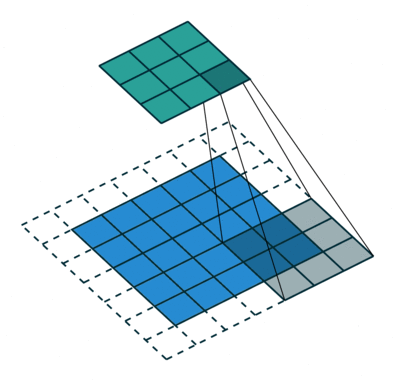
start:feature map左上角元素在输入图像上的感受野中心坐标(start,start),即视野中心的坐标,在上图中,左上角绿色块感受野中心坐标为(0.5,0.5),即左上角蓝色块中心的坐标,左上角白色虚线块中心的坐标为(−0.5,−0.5);
l:l表示层,卷积层为Convl,其输入feature map为Layerl−1,输出为Layerl。
下面假定所有层均为卷积层。
感受野大小
感受野大小的计算是个递推公式。
再看上面的动图,如果feature map 上的一个元素A看到feature map Layer1 上的范围为3×3(图中绿色块),其大小等于kernel size k2,所以,A看到的感受野范围r2等价于Layer1上3×3窗口看到的Layer0 范围,据此可以建立起相邻Layer感受野的关系,如下所示,其中rl为Layerl的感受野,rl−1为 Layerl−1 的感受野,
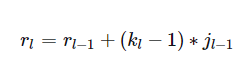
Layerl 一个元素的感受野rl等价于Layerl−1 上k×k个感受野的叠加;
Layerl−1 上一个元素的感受野为rl−1;
Layerl−1 上连续k个元素的感受野可以看成是,第1个元素看到的感受野加上剩余k−1步扫过的范围,Layerl−1 上每前进1个元素相当于在输入图像上前进jl−1个像素,结果等于rl−1+(k−1)×jl−1
可视化如下图所示,
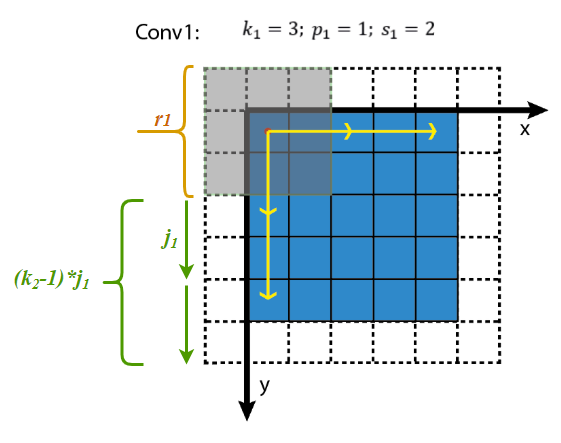
下面的问题是,jin怎么求?
Layerl 上前进1个元素相当于Layerl−1上前进sl个元素,转换成像素单位为
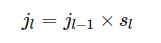
其中,sl为Convl的kernel在 Layerl−1 上滑动的步长,输入图像的s0=1。
根据递推公式可知,
Layerl上前进1个元素,相当于在输入图像前进了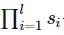 个像素,即前面所有层stride的连乘。
个像素,即前面所有层stride的连乘。
进一步可得,Layerl的感受野大小为:
402 Payment Required
感受野中心
感受野中心的计算也是个递推公式。
在上一节中计算得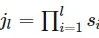 ,表示feature map Layerl上前进1个元素相当于在输入图像上前进的像素数目,如果将feature map上元素与感受野中心对齐,则jl为感受野中心之间的像素距离。如下图所示,
,表示feature map Layerl上前进1个元素相当于在输入图像上前进的像素数目,如果将feature map上元素与感受野中心对齐,则jl为感受野中心之间的像素距离。如下图所示,
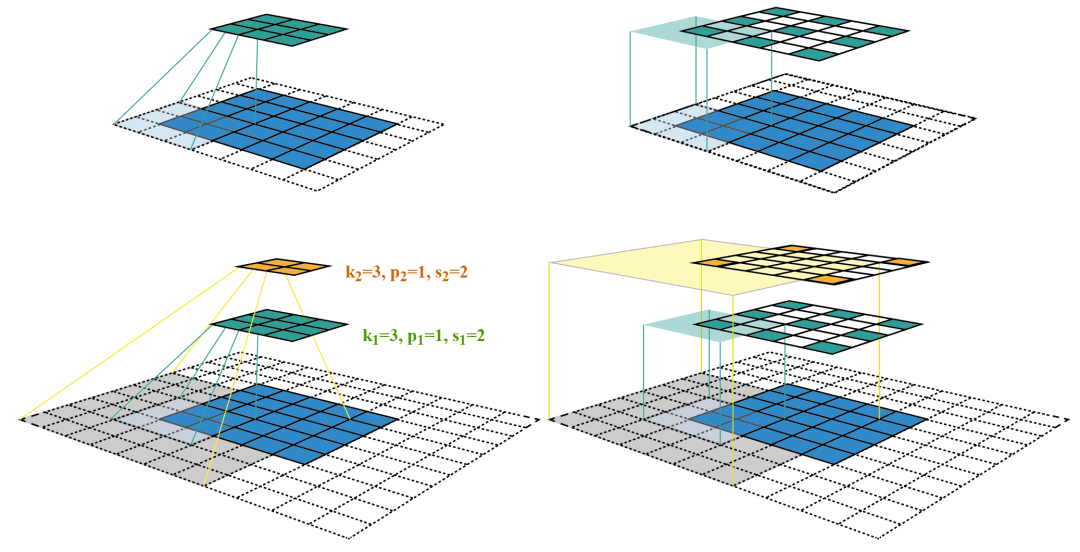
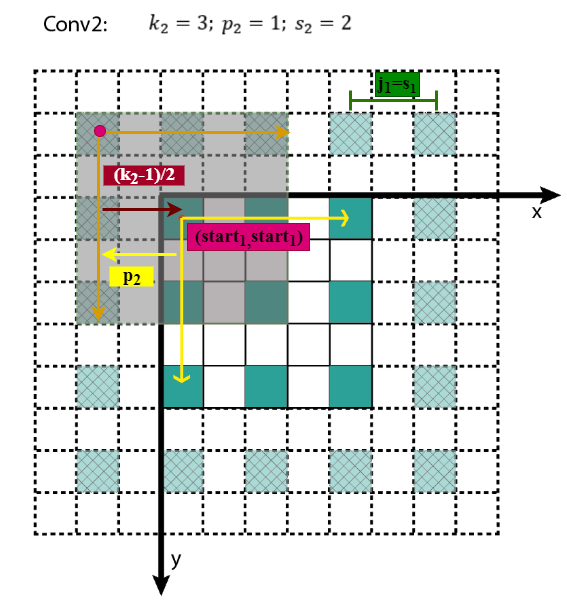
其中,各层的kernel size、padding、stride超参数已在图中标出,右侧图为feature map和感受野中心对齐后的结果。
相邻Layer间,感受野中心的关系为:
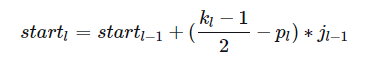
所有的start坐标均相对于输入图像坐标系。其中,start0=(0.5,0.5),为输入图像左上角像素的中心坐标,startl−1表示Layerl−1左上角元素的感受野中心坐标,(2kl−1−pl)为Layerl与Layerl−1感受野中心相对于Layerl−1坐标系的偏差,该偏差需折算到输入图像坐标系,其值需要乘上jl−1,即Layerl−1相邻元素间的像素距离,相乘的结果为(2kl−1−pl)∗jl−1,即感受野中心间的像素距离——相对输入图像坐标系。至此,相邻Layer间感受野中心坐标间的关系就不难得出了,这个过程可视化如下。
知道了Layerl左上角元素的感受野中心坐标(startl,startl),通过该层相邻元素间的像素距离jl可以推算其他元素的感受野中心坐标。
小结
将感受野的相关计算小结一下:
由上面的递推公式,就可以从前向后逐层计算感受野了,代码可参见computeReceptiveField.py,在线可视化计算可参见Receptive Field Calculator。
最后,还有几点需要注意:
Layerl的感受野大小与sl、pl无关,即当前feature map元素的感受野大小与该层相邻元素间的像素距离无关;
为了简化,通常将padding size设置为kernel的半径,即p=2k−1,可得startl=startl−1,使得feature map Layerl 上(x,y)位置的元素,其感受野中心坐标为(xjl,yjl);
对于空洞卷积dilated convolution,相当于改变了卷积核的尺寸,若含有 dilation rate参数,只需将kl替换为dilation rate∗(kl−1)+1 ,dilation rate=1时为正常卷积;
对于pooling层,可将其当成特殊的卷积层,同样存在kernel size、padding、stride参数;
非线性激活层为逐元素操作,不改变感受野。
以上。
参考资料
wiki-Receptive field
wiki-Receptive Field Calculator
arXiv-Understanding the Effective Receptive Field in Deep Convolutional Neural Networks
medium-A guide to receptive field arithmetic for Convolutional Neural Networks
medium-Topic DL03: Receptive Field in CNN and the Math behind it
ppt-Convolutional Feature Maps: Elements of Efficient (and Accurate) CNN-based Object Detection
SIGAI-关于感受野的总结
Calculating Receptive Field of CNN
好消息!
小白学视觉知识星球
开始面向外开放啦👇👇👇

下载1:OpenCV-Contrib扩展模块中文版教程
在「小白学视觉」公众号后台回复:扩展模块中文教程,即可下载全网第一份OpenCV扩展模块教程中文版,涵盖扩展模块安装、SFM算法、立体视觉、目标跟踪、生物视觉、超分辨率处理等二十多章内容。
下载2:Python视觉实战项目52讲
在「小白学视觉」公众号后台回复:Python视觉实战项目,即可下载包括图像分割、口罩检测、车道线检测、车辆计数、添加眼线、车牌识别、字符识别、情绪检测、文本内容提取、面部识别等31个视觉实战项目,助力快速学校计算机视觉。
下载3:OpenCV实战项目20讲
在「小白学视觉」公众号后台回复:OpenCV实战项目20讲,即可下载含有20个基于OpenCV实现20个实战项目,实现OpenCV学习进阶。
交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~
















 1326
1326

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









