






点击下方“ReadingPapers”卡片,每天获取顶刊论文解读
论文信息
题目:FPL+: Filtered Pseudo Label-Based Unsupervised Cross-Modality Adaptation for 3D Medical Image Segmentation
FPL+:用于3D医学图像分割的基于过滤伪标签的无监督跨模态适应
作者:Jianghao Wu, Dong Guo, Guotai Wang, Qiang Yue, Huijun Yu, Kang Li, and Shaoting Zhang
摘要
将医学图像分割模型适应到新领域对于提高其跨领域可转移性至关重要,并且由于昂贵的标注过程,无监督领域适应(UDA)是吸引人的,其中只需要未标记的图像即可进行适应。现有的UDA方法主要基于图像或特征对齐,并使用对抗训练进行正则化,但它们受到目标领域中监督不足的限制。在本文中,作者提出了一种增强型的基于过滤伪标签(FPL+)的UDA方法,用于3D医学图像分割。它首先使用跨领域数据增强将源领域中的标记图像转换为包含伪源域集和伪目标域集的双域训练集。为了利用双域增强图像训练伪标签生成器,使用特定于领域的批量归一化层来处理领域偏移,同时学习领域不变结构特征,为目标域图像生成高质量的伪标签。然后,作者将标记的源域图像和带有伪标签的目标域图像结合起来训练最终的分割器,其中提出了基于不确定性估计的图像级权重和基于双域共识的像素级权重,以减轻嘈杂伪标签的不利影响。在三个公共多模态数据集上的实验,包括听神经瘤、脑肿瘤和整个心脏分割,表明我们的方法超过了十种最先进的UDA方法,并且在某些情况下,它甚至比目标领域中的全监督学习取得了更好的结果。
关键字
领域适应,图像翻译,不确定性,脑肿瘤,伪标签
引言
深度学习彻底改变了医学图像分割领域,实现了各种解剖结构和病变的准确分割[1]。例如,胶质瘤分割算法在过去十年中有了显著改进,并且取得了接近手动分割的结果[2]。在听神经瘤分割中也出现了同样的现象,其中卷积神经网络(CNN)达到了专家级的性能[3]。然而,医学图像通常具有多种模态,它们是具有显著领域差异的不同领域,例如在听神经瘤分割中的对比增强T1(ceT1)和高分辨率T2(hrT2)磁共振(MR)成像。用一种模态训练的模型在另一种模态的图像上通常表现不佳。此外,为每种模态手动标注医学图像既耗时又费力。因此,直接在新模态中应用训练有素的模型进行推理,或者分别用每种模态中的标记图像训练模型是不切实际的。为了解决这个问题,本工作旨在将用一种模态训练的模型适应到不同的模态,以提高其在新模态上的性能,并避免为目标模态注释。领域适应(DA)是解决推理时跨模态性能急剧下降问题的有前途的解决方案。它试图在源域和目标域之间建立映射,以便在源域训练的模型可以在目标域中表现良好。早期的领域适应方法需要源域和目标域中的注释。一种简单的方法是用目标域中的标记图像微调预训练模型[4]。半监督DA利用少量标记图像和许多未标记的图像进行适应[5],[6]。然而,这些方法需要目标域中的注释,这对于3D医学图像来说难以获得且昂贵。无监督领域适应(UDA)作为一种有前途的技术出现,以解决医学图像分割中领域偏移带来的挑战,而不需要依赖标记的目标数据。提出了各种方法来解决这个问题,通过在图像外观、特征分布或输出结构上对齐源和目标域。一些方法,如CycleGAN[7]和对比无配对翻译(CUT)[8],专注于源和目标域之间的图像外观对齐。然而,这些方法可能会引入对图像解剖结构的扭曲,这可能会阻碍准确的分割[9]。Tzeng等人[10]和Long等人[11]专注于特征级别的对齐。CycADA[12],SIFA[13]和SymD[14]旨在在图像和特征级别上对齐域。ADVENT[15]专注于输出级别的对齐,鼓励目标域中的预测遵循与源域中标签相同的分布。然而,在这样的情况下,显著的领域偏移可能会使输出对齐变得具有挑战性。此外,这些方法主要是为2D图像分割提出的,而大多数医学图像是3D体积,处理它们更具挑战性。DAR-Net[24]结合了2D样式迁移网络和3D分割网络来处理3D医学图像。然而,由于病变或有限的训练图像,它很难获得真实的样式迁移,并且合成的和真实的目标3D图像之间仍然存在领域差异,导致性能有限。
方法
我们提出的FPL+框架如图1所示。为了实现3D医学图像分割的跨模态UDA,它首先为目标域中的训练图像获得高质量的伪标签,然后通过从伪标签中学习来训练该域中的分割模型。为了提高伪标签生成器的性能,我们首先提出了跨域数据增强(CDDA),将标记的源域图像增强为包含伪源域集和伪目标域集的双域数据集,这两个集合具有相同的标签集。然后,提出了一个具有双域批量归一化层的双域伪标签生成器(DDG),用于从增强的双域图像中学习,为目标域训练集生成高质量的伪标签。为了训练最终的分割器,我们引入了从标记的源域图像和带有伪标签的目标域图像的联合训练,并提出了基于大小感知不确定性估计的图像级权重和基于双域共识的像素级权重,以减轻不可靠伪标签的不利影响。
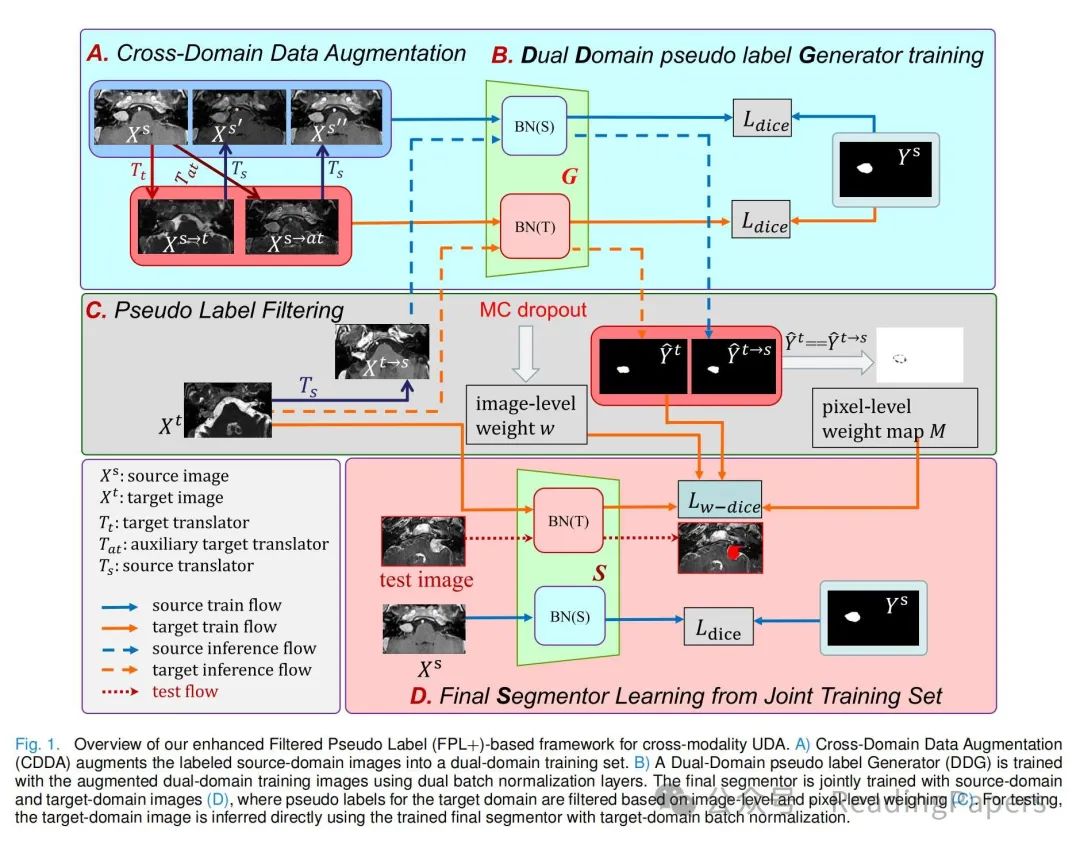
A. 跨域数据增强
设和分别表示标记的源域图像集和未标记的目标域图像集。和分别表示来自和的第个和第个图像,其中的标签为。注意,源域和目标域来自不同的患者群体,即和是未配对的。由于和之间的领域偏移,使用训练模型来为目标域生成伪标签将导致性能不佳。为了提高目标域的伪标签质量,作者提出了跨域数据增强(CDDA),在训练伪标签生成器之前增强。具体来说,作者使用图像样式翻译器将标记的源域图像翻译成伪目标域图像,并使用另一个图像样式翻译器将翻译回源域,得到伪源域图像。注意,和通常是基于未配对训练集联合训练的,如CycleGAN [7]中所用。由于训练集是未配对的,因此很难使和完全匹配真实的目标模态和源模态图像。因此,这些图像在样式翻译后可能存在一些结构扭曲。图2展示了通过不同方法获得的翻译图像的示例,包括CycleGAN [7]、CUT [8]和SIFA [13]。它表明,翻译图像可能存在不同的质量问题,如肿瘤收缩和伪影肿瘤,或样式翻译不足。为了增强训练图像的多样性,并减少在训练伪标签生成器时对图像翻译器获得的结构扭曲的过度拟合的风险,作者引入了一个辅助目标样式翻译器,它与具有相同的架构,其权重在的训练过程中的不同检查点获得,因为作者观察到在不同检查点的翻译器可能导致一些不同的局部细节。

与在FPL [20]中作为第二翻译器训练CUT [8]不同,不需要额外的训练过程,并且可以通过将源域图像翻译成不同的伪目标域图像来提供数据增强。作者还将翻译回伪源域图像。因此,对于每个标记的源域图像,我们获得了四个增强的图像,即两个伪源域图像和,以及两个伪目标域图像和,它们共享相同的分割标签。我们将增强的源域训练集表示为,伪目标域训练集表示为。然后,和一起用于训练伪标签生成器。在本工作中,图像翻译器和基于CycleGAN [7]实现,使用两个鉴别器和分别针对两个域。训练涉及两个对抗性损失,和一个循环一致性损失。目标域的对抗性损失定义为:
源域的对抗性损失基于,和类似定义,一致性损失为:
B. 双域伪标签生成器
在CDDA之后,双域增强训练集具有更多具有不同外观和共享分割标签的训练样本,用于训练伪标签生成器。然而,和中的图像表现出不同的模态,导致不同的统计特性,这使得在标准的全监督设置中很难将它们一起用于训练分割模型[34],[35]。为了有效地利用增强的训练集并处理不同统计特性,作者提出了一个双域伪标签生成器(DDG),它使用双批量归一化(Dual-BN)[36]来分别归一化源域和目标域的特征。具体来说,从源域提取的某一层的特征通过源域BN层归一化,而从目标域提取的特征通过目标域BN层归一化[35]:
其中表示从域获得的特征,表示域标签,即当输入来自时,否则。和是可学习的参数,和分别是相应域的均值和标准差。小常数被添加以确保数值稳定性。在训练期间,BN层使用指数移动平均值来估计特征的均值和方差,其因子为。对于Dual-BN,它们由下式给出:
其中和分别是在迭代时域的估计均值和方差,是移动平均的动量参数。此外,的其他参数在和之间共享,这有助于通过利用双域增强训练集来学习更多的领域不变特征。的参数表示为,其中代表除了批量归一化层之外的共享参数。和是源域特定的BN参数,和是目标域特定的BN参数。设和分别表示和中的样本数量。对于样本,其预测表示为,对于样本,其预测表示为。和的真值分别表示为和。在和上训练的损失函数为:
其中是用于监督分割的Dice损失。
C. 伪标签过滤
在训练伪标签生成器之后,通过为目标域图像获得一个伪标签,其中批量归一化层使用目标域特定的参数。由于这些伪标签在不同样本和图像区域的质量不同,直接将所有伪标签作为真实标签用于训练最终分割器可能会误导最终分割器的训练。因此,作者提出了基于图像级和像素级权重的伪标签过滤方法,以实现鲁棒学习。
基于大小感知不确定性估计的图像级加权:对于图像级加权,基于蒙特卡洛(MC)dropout的不确定性估计是一种广泛使用的方法,不确定性较大的伪标签可能是不可靠的。然而,在分割任务中,不确定区域通常位于目标边缘,导致具有较大目标的案例具有更高的整体不确定性,这可能会忽略具有小目标的图像,特别是对于具有各种大小的肿瘤分割。为了解决这个问题,作者提出了一种基于大小感知的不确定性估计方法,用于可靠的图像级加权伪标签。首先,在获得目标域训练集的伪标签时,我们在中启用dropout层,并为每个案例进行K次连续预测,得到同一案例的K个不同概率图。设表示这些概率图的平均结果,伪标签通过对进行argmax操作获得。对于每个像素,我们计算K次预测中前景概率的方差,得到与形状相同的方差图。中每个像素的值求和得到一个朴素的图像级不确定性:
其中是中像素o的方差。其次,由于往往偏向于具有大目标的图像,我们通过估计的不确定区域大小对进行归一化。具体来说,我们基于计算像素o的熵。定义为:
其中e是像素级熵的阈值。是单位步函数,对于负输入取0.0,对于正输入取1.0。然后,我们提出的图像级不确定性为伪标签:
其中表示当时的最大值。最后,伪标签的图像级权重定义为:
其中是的最小值,较小的图像级不确定性导致较高的图像级权重。
基于双域共识的像素级加权:为了进一步减少不可靠预测在像素级的影响,我们引入了基于双域共识的权重图,通过对及其样式翻译版本应用获得。具体来说,我们使用将翻译成伪源域图像,并获得另一个伪标签:,其中中的BN层使用源域特定的参数。然后,我们将和之间的共识和差异区域分别视为可靠和不可靠的预测。权重图定义为:
其中我们将像素级权重设置为共识为1.0,差异为0.0。在获得和用于后,我们将它们组合成单个权重图,该图在统一公式中整合了图像级和像素级加权。为了使模型更多地从可靠信息中学习,并减少对不可靠信息的过度拟合,我们提出了加权Dice损失,从和中学习:
其中是中的像素数量。是的预测。注意,方程(12)定义了二元分割任务,它可以很容易地扩展到多类分割。图像级加权和像素级加权仅在最终分割器的训练之前生成一次。随后,伪标签和加权值在整个训练迭代过程中保持固定。
D. 从联合训练集学习最终分割器
尽管可以使用带有伪标签的目标域图像来训练目标域中的最终分割器,但我们手头有标记的源域图像,并且结合和来训练最终分割器可以更好地利用源域中的知识,以提高其性能。因此,作者提出了一个双域分割器,以从标记的图像在和带有伪标签的图像在中联合学习。为了处理联合学习中和之间的领域偏移,被设计为与伪标签生成器具有相同的架构,基于双BN层。与类似,的参数表示为。的训练损失为:
其中和。是在方程(12)中定义的加权Dice损失。为了加速的训练,我们使用的权重对其进行初始化,然后在目标域中使用特定于目标域的BN层进行测试。
实验
A. 数据集和实现
听神经瘤分割数据集:我们首先在公开可用的听神经瘤(VS)分割数据集上验证了我们的方法,该数据集包括242名患者的3D MRI图像。每个患者都通过对比增强T1加权(ceT1)和高分辨率T2加权(hrT2)MRI进行扫描,平面分辨率约为0.4毫米×0.4毫米,平面尺寸为512×512,切片厚度为1.5毫米。我们使用两种模态进行双向适应,即ceT1和hrT2分别作为源域和目标域,反之亦然。我们随机将数据集分为200名患者用于训练,14名患者用于验证,28名患者用于测试。在训练集中,100名患者的模态图像用作源域,另外100名患者的另一种模态图像用作目标域。我们遵循Cross-modality Domain Adaptation Challenge 2021(CrossMoDA 2021)[40]的设置,使用目标域中的验证集来调整超参数,测试集仅用于最终推理。对于预处理,每个图像通过由训练集中VS最大可能范围确定的立方体框裁剪,并扩展了边缘,并通过强度均值和标准差进行归一化。
BraTS数据集:我们的方法还在多模态脑肿瘤分割(BraTS)挑战2020数据集[45]上进行了验证。由于官方验证和测试集的地面真实情况并不公开,我们使用了官方训练集进行实验,其中包括369名患者的空间对齐MRI扫描的四种模态(T1,ceT1,T2和FLAIR),分辨率为1.0 mm³,平面尺寸为240×240。我们使用T2和FLAIR图像进行双向适应,目标是分割整个肿瘤。在每个方向上,我们使用143名患者的图像作为源域,另143名患者的图像作为目标域。42(每个方向21个)和41个目标域图像分别用于验证和测试。对于预处理,每个模态的强度通过均值和标准差进行归一化。我们移除了每个体积沿z轴的前20层和后20层,因为它们不包含肿瘤。
MMWHS数据集:多模态整个心脏分割挑战2017(MMWHS)数据集[46]包括20个3D CT扫描和20个3D MRI扫描。分割目标包括升主动脉(AA),左心房血腔(LAC),左心室血腔(LVC)和左心室心肌(MYO)。按照[47]中的实验设置,我们将MRI指定为源域,CT作为目标域。每个域包括14个,2个和4个体积分别用于训练,验证和测试。对于预处理,每个体积通过由整个心脏的最大范围定义的立方体框裁剪,强度值使用均值和标准差进行归一化。
实施细节:伪标签生成器G和最终分割器S由现有2.5D网络[3]的修改版本实现,该网络针对脑肿瘤分割进行了设计。它具有类似U-Net的结构,其中前两个分辨率级别使用2D卷积,其他分辨率级别使用3D卷积。我们在所有块中添加了额外的BN层,用于双域批量归一化。G和S都使用动量为0.9和初始学习率为10^-3的Adam优化器进行训练。G训练了200个周期,而S由G初始化,并训练了另外100个周期。VS的补丁大小为32×128×128,BraTS的补丁大小为32×192×192,VS的批量大小为4,BraTS的批量大小为2。我们遵循CycleGAN的实现,使用2D切片训练Ts和Tt。训练进行了300个周期,我们选择了第200个周期的检查点作为Tat的权重,第300个周期作为Ts和Tt的权重。蒙特卡洛dropout的超参数K为5,实验中的e设置为0.2。为了公平和可重复性,我们所有的超参数都遵循上述设置,并且在训练期间没有更新。我们使用PyTorch 1.8.1在NVIDIA GeForce RTX 2080Ti GPU上实现了所有实验。分割性能通过Dice分数和3D空间中的平均对称表面距离(ASSD)进行定量测量。
B. 与SOTA方法的比较
我们的FPL+与十种最先进的UDA方法进行了比较:1) CycleGAN[7],它执行未配对的图像到图像的翻译,使用循环一致性损失和对抗性学习;2) CUT[8],它通过对比学习最大化对应补丁之间的互信息,用于图像翻译。我们使用CycleGAN和CUT将标记的源域图像翻译成伪目标域图像,以训练目标域的分割器。3) SIFA[13],它使用基于对抗性学习和深度监督机制的协同图像和特征对齐;4) AccSeg[41],它利用补丁对比学习将分割网络适应到目标成像模态;5) ADVENT[15],它结合了熵损失和对抗性损失,用于语义分割中的UDA。6) HRDA[42],它结合了高分辨率和低分辨率作物,以捕获长距离上下文依赖性。7) CDAC[43],它提出了在注意力图上进行适应,具有跨域注意力层。8) MIC[44],它学习目标域的空间上下文关系,作为鲁棒视觉识别的额外线索。9) DAR-Net[24],它使用解耦GAN进行图像翻译,并使用3D CNN进行分割。10) FPL[20],这是我们FPL+的初步版本,它不使用双域生成器/分割器和伪标签的像素级加权。我们还将这些方法与“w/o DA”下限进行比较,即直接将训练有素的模型应用于Dt中的图像,以及与“标记目标”进行比较,即用完整注释在目标域中训练分割模型。它们还与“强上界”进行比较,即用标记的源域和目标域图像训练我们的双域分割网络。这为使用双域数据进行训练提供了理论上限。请注意,CycleGAN,CUT,DAR-Net和我们的FPL+使用基于相同2.5D CNN[3]主干的3D分割网络,其他人使用2D分割网络,这些网络与它们的图像/特征对齐过程耦合。
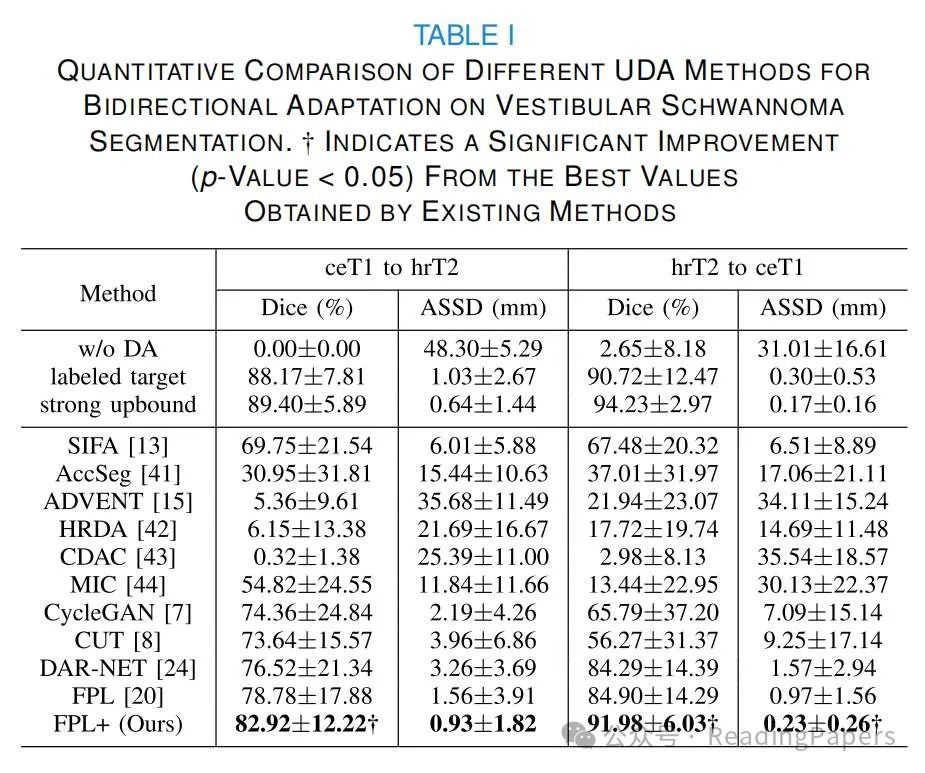
听神经瘤分割结果:我们首先在VS数据集上执行ceT1和hrT2之间的双向UDA。表I显示了不同方法在Dice和ASSD方面的定量比较。“ceT1到hrT2”意味着使用ceT1作为源域,hrT2作为目标域,反之亦然。“w/o DA”方法在“ceT1到hrT2”和“hrT2到ceT1”中分别获得了平均Dice的0.00%和2.65%,表明两种模态之间存在显著的领域偏移。所有UDA方法都比w/o DA有所改进。SIFA[13]在两个方向上分别获得了平均Dice的69.75%和67.48%。AccSeg[41]只分别获得了30.92%和37.01%。ADVENT[15],HRDA[42]和CDAC[43]只比“w/o DA”获得了轻微的性能提升。尽管MIC[44]在“ceT1到hrT2”上比其他三种方法要好得多,但在“hrT2到ceT1”上表现不佳,显示出其在不同的跨模态设置中的低鲁棒性。FPL在现有方法中取得了最高性能,Dice分数分别为78.78%和84.90%。我们的方法FPL+的平均Dice在两个方向上分别为82.92%和91.98%,它们显著高于其他方法。请注意,对于“hrT2到ceT1”,我们的方法不如“强上界”,但甚至略优于“标记目标”(91.98%与90.72%在Dice方面),这主要是因为我们的分割器利用了两个领域的图像进行学习。图3显示了不同方法的可视化分割结果。它表明其他方法存在不同程度的误分割,而我们的方法与地面真实情况紧密对齐。
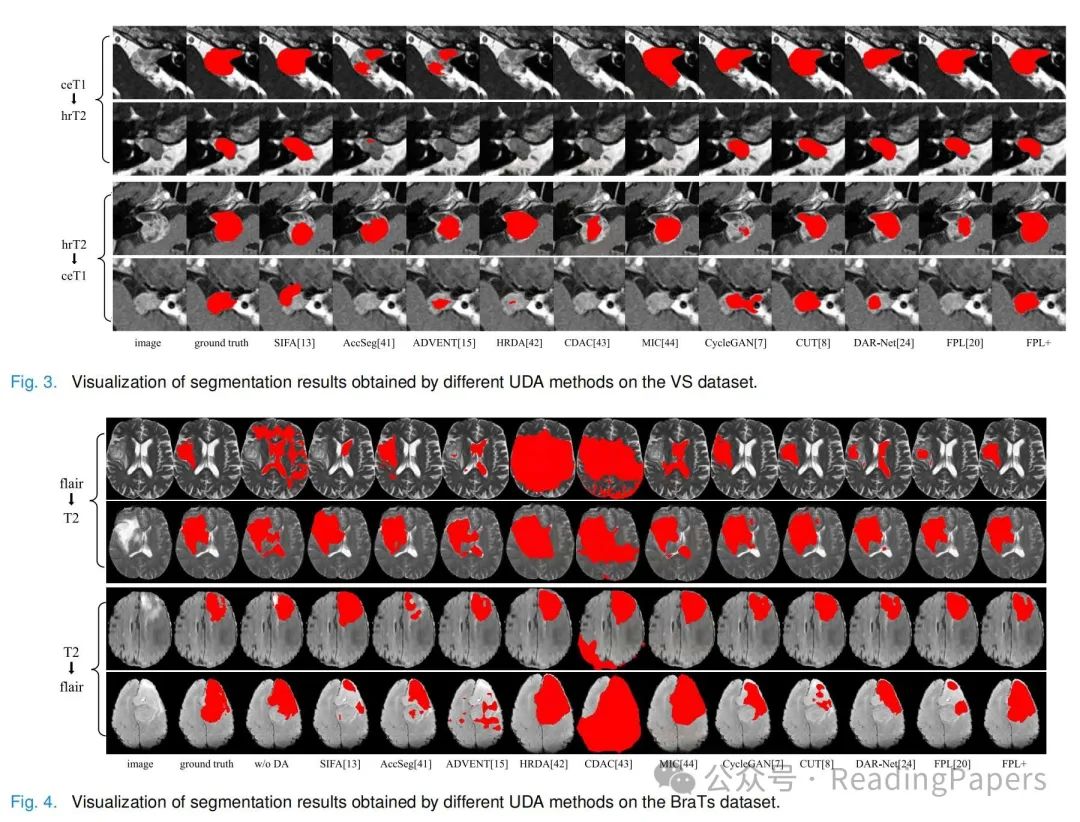
胶质瘤分割结果:不同UDA方法在BraTS数据集上的定量评估结果如表II所示。对于“FLAIR到T2”,“w/o DA”的Dice分数为47.16%,表明两种模态之间存在一定的领域差异。SIFA,AccSeg和MIC的平均Dice分数分别为55.52%,63.95%和49.23%。ADVENT,HRDA和CDAC的性能低于“w/o DA”,分别为39.83%,27.48%和25.55%。与其他2D UDA方法相比,使用3D分割模型的其他方法获得了更好的性能。特别是,FPL在现有UDA方法中获得了最高的性能,平均Dice为70.63%,ASSD为7.10 mm。我们的FPL+进一步超越了FPL[20],平均Dice和ASSD分别为75.76%和4.46 mm。在“T2到FLAIR”方向上,“w/o DA”基线的平均Dice为68.46%,FPL获得了79.62%的平均Dice,超过了其他现有UDA方法。FPL+的平均Dice为84.81%,平均ASSD为2.72 mm,超过了“标记目标”,略低于“强上界”,后者的平均Dice为86.69%,平均ASSD为2.30 mm。这可以归因于FLAIR图像对整个肿瘤的固有更好对比度,以及我们方法提取丰富领域不变信息的能力。图4显示了这些方法之间的视觉比较,展示了我们方法在不同方向上进行跨模态UDA的优越性。

心脏分割结果:表III提供了各种UDA方法在心脏分割数据集上的定量评估结果。“w/o DA”对于不同心脏结构,包括AA,LAC,LVC和MYO的Dice分数分别为15.20%,53.16%,5.96%和6.05%,平均Dice分数(20.09%)显著低于“标记目标”(84.84%)。这表明MR和CT模态之间存在显著的领域差异。相比之下,SIFA,AccSeg,ADVENT,HRDA,CDAC和MIC的平均Dice分数分别为68.15%,64.46%,55.69%,67.00%,60.67%和51.47%。CycleGAN,CUT和DAR-NET使用3D分割模型,平均Dice分数分别为59.86%,61.73%和67.74%。鉴于心脏在不同患者中的解剖一致性,FPL仅使用图像级权重的伪标签,并且只利用目标域图像进行训练,获得了平均Dice分数65.21%。相比之下,我们提出的方法FPL+,通过额外的像素级权重利用双域图像进行训练,表现出优越的性能,平均Dice和ASSD分别为73.70%和2.61 mm,显著优于现有的UDA方法。图5展示了这些方法之间的视觉比较,表明我们的FPL+比其他方法更准确地分割心脏亚结构。


C. 消融研究
为了验证我们FPL+的每个组成部分,我们在VS数据集上对双域伪标签生成器(DDG)和最终分割器S进行了全面的消融研究。对于DDG,我们研究了我们的双BN,Dst和Dss基于CDDA的有效性。对于训练S,我们研究了双BN的有效性,以及基于大小感知不确定性估计的图像级权重和基于双域共识的像素级权重。我们的伪标签过滤方法还与几种现有的噪声鲁棒学习方法进行了比较。请注意,所有消融研究结果都是从目标域的验证集中获得的。
CDDA和双BN对DDG的有效性:为了研究CDDA和双BN的有效性,我们首先使用Ds→t = {(Xs→t i , Y s i )}作为基线训练伪标签生成器。如表IV所示,对于“ceT1到hrT2”,基线获得了平均Dice的79.94%。当使用Ds→t和Ds而不使用双BN训练G时,平均Dice提高到82.67%,显示了结合源域和伪目标域图像进行训练的好处。引入双BN进一步提高到84.94%,证明了使用特定于领域的批量归一化处理领域偏移进行联合训练的有效性。通过引入辅助翻译器Tat,即用Dst替换Ds→t,平均Dice为85.73%。最后,提出的Dst,Dst和双BN的组合获得了最高的平均Dice的86.77%,显示了提出的CDDA的优越性。从“hrT2到ceT1”方向,也可以得出类似的结论,如表IV所示。仅从Ds→t训练的基线只获得了平均Dice的81.23%。引入Ds和双BN分别提高到82.72%和83.08%。使用Dst和Dst中的双域增强图像,结合双BN获得了85.49%的平均Dice分数,超过了其他变体。
对训练最终分割器的消融研究:对于最终分割器S的消融研究,我们将基线设置为使用DDG获得的目标域图像的伪标签的标准监督学习,并逐步引入以下组件:1)将标记的图像添加到S的训练集中;2)在从Dt和Ds联合学习时使用双BN;3)从训练有素的G初始化S;4)使用基于大小感知不确定性估计的提出的图像级权重;5)使用基于双域共识的提出的像素级权重。如表V所示,基线在“ceT1到hrT2”和“hrT2到ceT1”中的Dice分数分别为82.67%和81.01%。通过额外训练Ds和使用双BN,相应的平均Dice分别提高到85.54%和81.62%。在应用从G初始化后,相应的Dice分数进一步提高到87.21%和83.32%。当使用图像级权重时,平均Dice分数增加到“ceT1到hrT2”的88.01%和“hrT2到ceT1”的87.57%,分别证明了我们的图像级权重在抑制低质量伪标签以实现鲁棒学习中的有用性。最后,当提出的图像级权重和像素级权重图结合用于训练最终分割器时,结果平均Dice分别为“ceT1到hrT2”的88.29%和“hrT2到ceT1”的86.57%,超过了其他变体。这些结果证明了我们提出的方法对训练最终分割器的每个组件都是有效的。
与其他伪标签学习方法的比较:使用相同的一组由DDG为目标域训练图像生成的伪标签,我们的训练策略还与三种最新的噪声鲁棒学习方法进行了比较:1)Co-teaching[31],它涉及同时训练两个神经网络,每个网络根据批次内的培训损失为另一个网络选择高质量的伪标签;2)GCE Loss[27],这是MAE和交叉熵损失的概括,用于鲁棒学习;3)TriNet[32],它使用三个网络迭代选择信息丰富的样本进行训练,基于它们的预测之间的共识和差异。这些方法的结果如表V的最后三行所示。Co-teaching[31]在“ceT1到hrT2”中获得了83.93%的Dice分数,而在“hrT2到ceT1”中获得了81.19%。GCE损失[27]获得了更高的平均Dice分数,分别为“ceT1到hrT2”的84.14%和“hrT2到ceT1”的83.78%。TriNet[32]的相应值分别为“ceT1到hrT2”的85.86%和“hrT2到ceT1”的84.18%。请注意,这些方法的性能低于我们的性能。
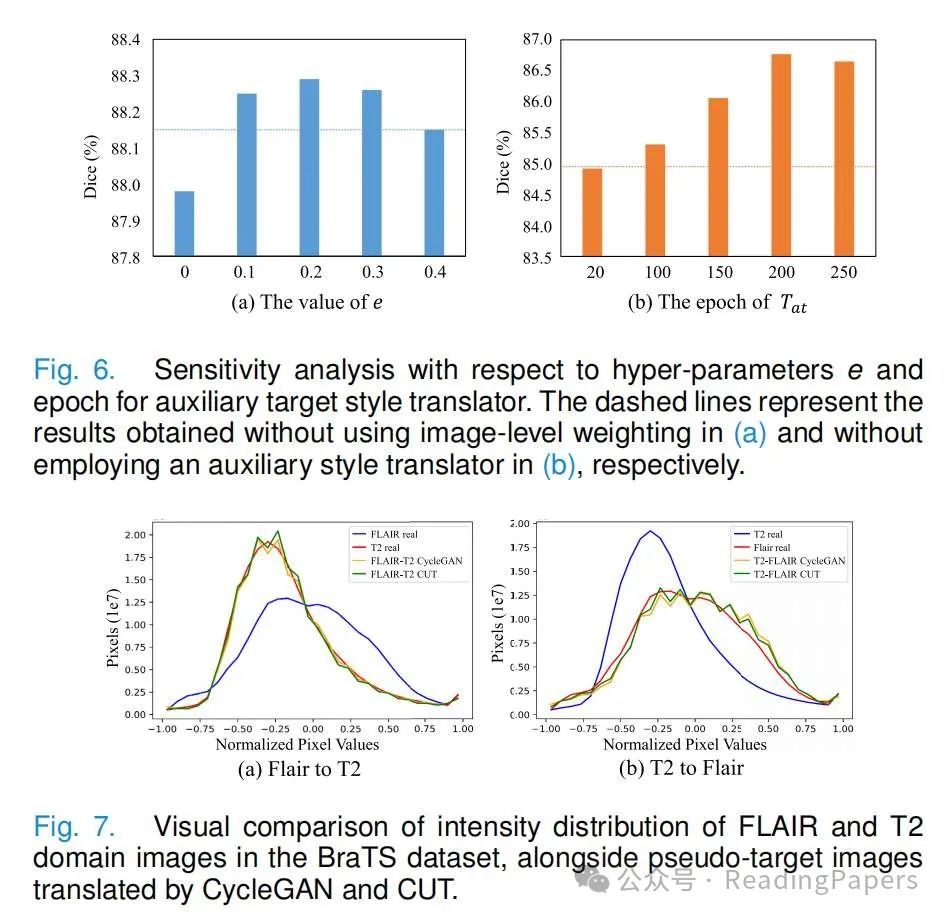
超参数的有效性:我们的方法有两个核心超参数:用于图像级权重的阈值e和用于选择辅助目标样式翻译器的epoch数量。为了探索e的影响,我们将其值从0变化到0.4。在VS数据集的hrT2验证集上的性能如图6所示。显然,当e=0时,即用所有像素在体积中归一化v j,性能不如使用其他e值。当e从0.1设置到0.3时,性能得到了改善,我们可以发现当e从0.1变化到0.3时,性能相对稳定,最高结果在e=0.2时获得。因此,我们为我们的方法设置了e=0.2。然后,我们研究了辅助目标样式翻译器Tat的训练周期对伪标签生成质量的影响。图6显示了hrT2验证集上的结果。将Tat的周期数设置为20,Dice为84.92%,略低于不使用辅助翻译器(84.94%),表明Tat用小的周期数无助于改善伪标签生成器。当周期数增加到100和150时,伪标签生成器获得的Dice分别提高到85.31%和86.06%。在第200个周期时,性能达到峰值86.77%。然而,在第250个周期时,由于Tat变得类似于主要翻译器,增强图像的多样性将减少,相应的Dice略微降低到86.65%。
V. 讨论
对于跨模态无监督适应,图像对齐以减少领域差距,以及选择可靠的伪标签是获得我们方法良好性能的两个关键因素。首先,我们的跨域数据增强使用CycleGAN可以有效对齐两个领域的图像级别。图7比较了源域,目标域和增强的源和目标域的强度分布。可以观察到,当从FLAIR转换到T2加权成像时,增强的图像与真实的T2图像很好地对齐,并且当从T2加权图像转换到FLAIR时,也可以获得相同的结论。这不仅使两个领域很好地对齐,而且还为两个领域提供了更多的标记样本,从而提高了分割模型在目标域上的性能。其次,图像级和像素级权重选择可靠的伪标签用于训练最终分割器。对于不同大小和形状的肿瘤,目标域中不同样本的伪标签质量差异很大,图像级权重可以有效地拒绝低质量的伪标签,特别是对于形状和外观不规则的小肿瘤。然而,对于目标域中形状和外观变化有限的器官(例如心脏),伪标签在图像级的质量相似,我们的图像级权重难以显示出明显的优势,像素级权重在处理这种情况时更具有效性。此外,我们的方法专注于3D医学图像,由于GPU内存限制和逐片图像翻译引入的伪影,实现3D图像的端到端图像生成和分割是具有挑战性的。因此,我们的方法涉及两个步骤,分别用于训练伪标签生成器和最终分割器,这增加了一定的复杂性。然而,由于最终分割器是从伪标签生成器初始化的,因此前者需要较少的训练周期。此外,我们的方法要求分割目标在源域和目标域中具有相似的拓扑结构。例如,我们在FLAIR和T2图像之间进行了UDA实验,因为它们都能显示整个肿瘤区域,但是将我们的方法应用于FLAIR和ceT1之间的UDA可能不合适,因为ceT1在可视化肿瘤周围水肿区域方面效果较差。在模型复杂性方面,我们的方法有两个翻译器(每个11.366M),两个鉴别器(每个2.763M),伪标签生成器G和最终分割器S的模型大小为30.708M。请注意,S是由G初始化的。与使用CycleGAN进行图像翻译然后使用分割器在目标域中相比,我们的方法只引入了额外的BN层,导致模型大小略有增加0.012M。由于跨域数据增强,我们的方法为训练G和S提供了更多的增强图像,它们在VS数据集上分别需要32.7小时和6.5小时,而使用CycleGAN后的分割器需要13.2小时。尽管如此,两种方法都只使用分割器进行推理,并且具有相同的推理时间,每个3D体积为0.43秒,这对于测试来说是高效的。
VI. 结论
在本文中,我们提出了一种增强版的基于过滤伪标签(FPL)的跨模态无监督领域适应方法,称为FPL+,用于3D医学图像分割。为了在目标域生成高质量的伪标签,我们首先提出了跨域数据增强(CDDA)方法,将标记的源域图像增强为包含伪源域集和伪目标域集的双域训练集。双域增强图像用于训练双域伪标签生成器(DDG),它结合了特定于领域的批量归一化层,从双域图像中学习,同时有效处理领域偏移。为了提高最终分割器的性能,我们提出了从标记的源域图像和带有伪标签的目标域图像的联合训练,为了处理嘈杂的伪标签,提出了基于大小感知不确定性的图像级权重和基于双域共识的像素级权重。在三个公共多模态数据集上的实验,包括脑肿瘤和整个心脏分割,表明我们的方法超过了现有的UDA方法,并且在某些情况下,甚至超过了目标域中的全监督学习。将来,有兴趣将我们的方法应用于其他分割任务。
声明
本文内容为论文学习收获分享,受限于知识能力,本文对原文的理解可能存在偏差,最终内容以原论文为准。本文信息旨在传播和学术交流,其内容由作者负责,不代表本号观点。文中作品文字、图片等如涉及内容、版权和其他问题,请及时与我们联系,我们将在第一时间回复并处理。


















 49
49

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









