






点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达扫描下方二维码,加入前沿学术论文交流星球!可以获得最新顶会/顶刊论文的idea解读、解读的PDF和CV从入门到精通资料,及最前沿应用!

本文转载自:AI缝合术


一、论文信息

1
论文题目:Rewrite the Stars
中文题目: 重写星操作
论文链接:https://arxiv.org/pdf/2403.19967
官方github:https://github.com/ma-xu/Rewrite-the-Stars
所属机构:东北大学,微软
关键词:星操作、网络设计、StarNet、高效网络、核技巧

二、论文概要

Highlight
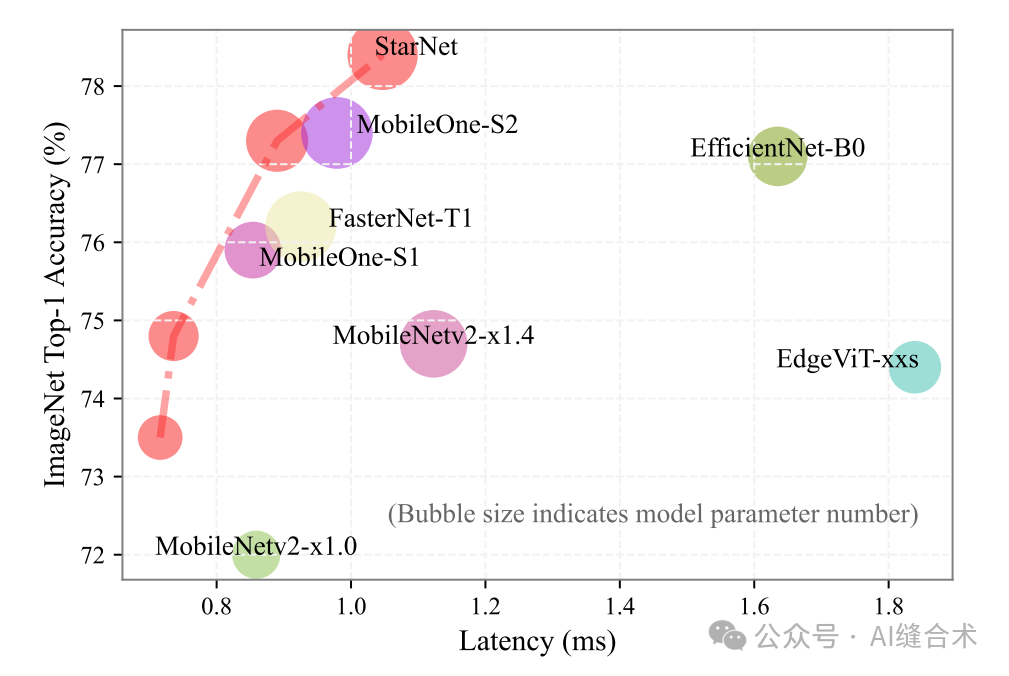 图 4. 移动设备(iPhone13)延迟与ImageNet准确率。此图中排除了延迟过高的模型。
图 4. 移动设备(iPhone13)延迟与ImageNet准确率。此图中排除了延迟过高的模型。
研究背景:
网络设计中的星操作(element-wise multiplication): 星操作在神经网络设计中具有未被充分探索的潜力,尽管已有直观解释,但其应用背后的理论基础尚未被深入研究。
星操作的高维非线性特征映射能力: 星操作能够将输入映射到高维非线性特征空间,类似于核技巧,而无需增加网络宽度。
本文贡献:
StarNet原型网络: 本文提出StarNet原型网络,展示了星操作在紧凑网络结构和高效预算下的出色性能和低延迟。
StarNet通过其独特的“星操作”(元素级乘法)实现了高效的特征表示。这种操作能够在紧凑的网络结构和较低的能耗下,将输入映射到高维非线性特征空间,而无需增加计算复杂度。
StarNet在保持计算效率的同时,能够获得更丰富和表达力更强的特征表示。此外,StarNet还具有低延迟的特性,这对于实时性要求较高的应用场景尤为重要。
 三、方法
三、方法

1
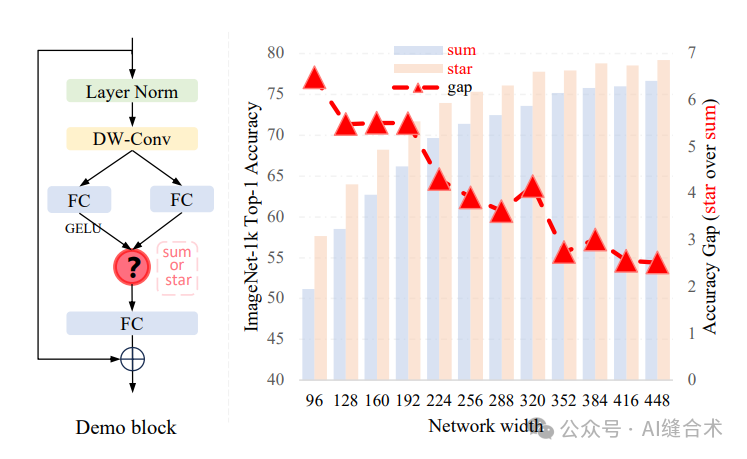
图1. 星操作(逐元素乘法)的优势示意图。左侧描绘了从相关工作中抽象出的基本构建块,其中“?”代表‘星’或‘求和’。右侧突出了两种操作之间的显著性能差异,‘星’操作表现出更优越的性能,特别是在宽度较窄时。
1、什么是星操作?(以单层星操作为例)

作者把星操作重写为:


2、多层网络中的星操作


3、根据星操作设计的StarNet
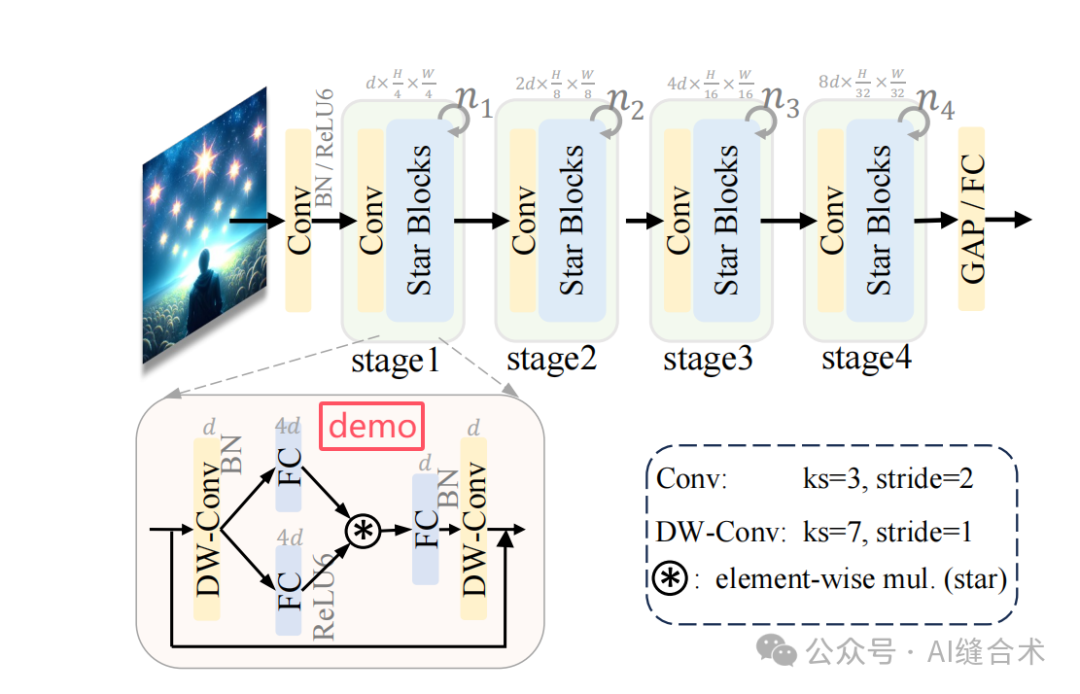
StarNet遵循传统的分层网络结构,直接使用卷积层在每个阶段降低分辨率并使通道数量翻倍。我们重复使用多个星形块来提取特征。StarNet没有复杂的结构和精心选择的超参数,就能实现有前景的性能。
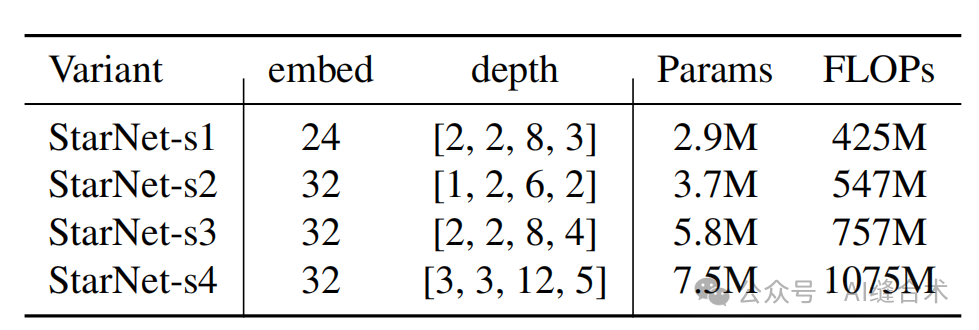
StarNet设计为四阶段的层次结构,利用卷积层进行下采样,并使用修改后的demo块进行特征提取。将层归一化(Layer Normalization)替换为批归一化(Batch Normalization),并将其放置在深度卷积之后(在推理过程中可以融合)。受MobileNeXt的启发,在每个块的末尾加入了深度卷积。通道扩展因子始终设置为4,每个阶段的网络宽度加倍。demo块中的GELU激活函数被替换为ReLU6,遵循MobileNetv2的设计。仅通过改变块的数量和输入嵌入通道数量来构建不同大小的StarNet,具体细节如下表所示,四种StarNet版本。
四、实验分析

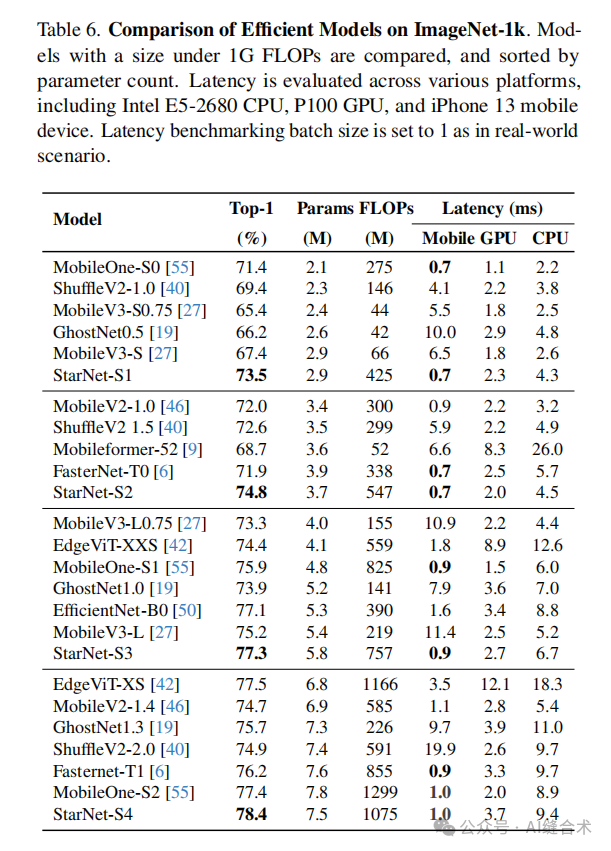
ImageNet-1k分类实验: StarNet模型在ImageNet-1k数据集上取得了优异的性能。StarNet-S4在iPhone 13设备上以0.7秒的延迟实现了73.5%的top-1准确率,超越了MobileOne-S0模型2.1%的准确率。此外,StarNet在1G FLOPs预算下,性能超越了MobileOne-S2模型1.0%,并且在三倍的延迟下超越了EdgeViT-XS模型0.9%。这些结果表明,StarNet在保持模型简洁性的同时,能够提供与复杂设计模型相媲美的性能。

五、代码

1
 温馨提示:对于所有推文中出现的代码,如果您在微信中复制的代码排版错乱,请复制该篇推文的链接,在任意浏览器中打开,再复制相应代码,即可成功在开发环境中运行!或者进入官方github仓库找到对应代码进行复制!
温馨提示:对于所有推文中出现的代码,如果您在微信中复制的代码排版错乱,请复制该篇推文的链接,在任意浏览器中打开,再复制相应代码,即可成功在开发环境中运行!或者进入官方github仓库找到对应代码进行复制!
import torch
import torch.nn as nn
from timm.models.layers import DropPath, trunc_normal_
from timm.models.registry import register_model
from torchsummary import summary
# 论文题目:Rewrite the Stars
# 中文题目: 重写星操作
# 论文链接:https://arxiv.org/pdf/2403.19967
# 官方github:https://github.com/ma-xu/Rewrite-the-Stars
# 所属机构:东北大学,微软
# 关键词:星操作、网络设计、StarNet、高效网络、核技巧
# 微信公众号:AI缝合术
model_urls = {
"starnet_s1": "https://github.com/ma-xu/Rewrite-the-Stars/releases/download/checkpoints_v1/starnet_s1.pth.tar",
"starnet_s2": "https://github.com/ma-xu/Rewrite-the-Stars/releases/download/checkpoints_v1/starnet_s2.pth.tar",
"starnet_s3": "https://github.com/ma-xu/Rewrite-the-Stars/releases/download/checkpoints_v1/starnet_s3.pth.tar",
"starnet_s4": "https://github.com/ma-xu/Rewrite-the-Stars/releases/download/checkpoints_v1/starnet_s4.pth.tar",
}
class ConvBN(torch.nn.Sequential):
def __init__(self, in_planes, out_planes, kernel_size=1, stride=1, padding=0, dilation=1, groups=1, with_bn=True):
super().__init__()
self.add_module('conv', torch.nn.Conv2d(in_planes, out_planes, kernel_size, stride, padding, dilation, groups))
if with_bn:
self.add_module('bn', torch.nn.BatchNorm2d(out_planes))
torch.nn.init.constant_(self.bn.weight, 1)
torch.nn.init.constant_(self.bn.bias, 0)
class Block(nn.Module):
def __init__(self, dim, mlp_ratio=3, drop_path=0.):
super().__init__()
self.dwconv = ConvBN(dim, dim, 7, 1, (7 - 1) // 2, groups=dim, with_bn=True)
self.f1 = ConvBN(dim, mlp_ratio * dim, 1, with_bn=False)
self.f2 = ConvBN(dim, mlp_ratio * dim, 1, with_bn=False)
self.g = ConvBN(mlp_ratio * dim, dim, 1, with_bn=True)
self.dwconv2 = ConvBN(dim, dim, 7, 1, (7 - 1) // 2, groups=dim, with_bn=False)
self.act = nn.ReLU6()
self.drop_path = DropPath(drop_path) if drop_path > 0. else nn.Identity()
def forward(self, x):
input = x
x = self.dwconv(x)
x1, x2 = self.f1(x), self.f2(x)
x = self.act(x1) * x2
x = self.dwconv2(self.g(x))
x = input + self.drop_path(x)
return x
class StarNet(nn.Module):
def __init__(self, base_dim=32, depths=[3, 3, 12, 5], mlp_ratio=4, drop_path_rate=0.0, num_classes=1000, **kwargs):
super().__init__()
self.num_classes = num_classes
self.in_channel = 32
# stem layer
self.stem = nn.Sequential(ConvBN(3, self.in_channel, kernel_size=3, stride=2, padding=1), nn.ReLU6())
dpr = [x.item() for x in torch.linspace(0, drop_path_rate, sum(depths))] # stochastic depth
# build stages
self.stages = nn.ModuleList()
cur = 0
for i_layer in range(len(depths)):
embed_dim = base_dim * 2 ** i_layer
down_sampler = ConvBN(self.in_channel, embed_dim, 3, 2, 1)
self.in_channel = embed_dim
blocks = [Block(self.in_channel, mlp_ratio, dpr[cur + i]) for i in range(depths[i_layer])]
cur += depths[i_layer]
self.stages.append(nn.Sequential(down_sampler, *blocks))
# head
self.norm = nn.BatchNorm2d(self.in_channel)
self.avgpool = nn.AdaptiveAvgPool2d(1)
self.head = nn.Linear(self.in_channel, num_classes)
self.apply(self._init_weights)
def _init_weights(self, m):
if isinstance(m, nn.Linear or nn.Conv2d):
trunc_normal_(m.weight, std=.02)
if isinstance(m, nn.Linear) and m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.LayerNorm or nn.BatchNorm2d):
nn.init.constant_(m.bias, 0)
nn.init.constant_(m.weight, 1.0)
def forward(self, x):
x = self.stem(x)
for stage in self.stages:
x = stage(x)
x = torch.flatten(self.avgpool(self.norm(x)), 1)
return self.head(x)
@register_model
def starnet_s1(pretrained=False, **kwargs):
model = StarNet(24, [2, 2, 8, 3], **kwargs)
if pretrained:
url = model_urls['starnet_s1']
checkpoint = torch.hub.load_state_dict_from_url(url=url, map_location="cpu")
model.load_state_dict(checkpoint["state_dict"])
return model
@register_model
def starnet_s2(pretrained=False, **kwargs):
model = StarNet(32, [1, 2, 6, 2], **kwargs)
if pretrained:
url = model_urls['starnet_s2']
checkpoint = torch.hub.load_state_dict_from_url(url=url, map_location="cpu")
model.load_state_dict(checkpoint["state_dict"])
return model
@register_model
def starnet_s3(pretrained=False, **kwargs):
model = StarNet(32, [2, 2, 8, 4], **kwargs)
if pretrained:
url = model_urls['starnet_s3']
checkpoint = torch.hub.load_state_dict_from_url(url=url, map_location="cpu")
model.load_state_dict(checkpoint["state_dict"])
return model
@register_model
def starnet_s4(pretrained=False, **kwargs):
model = StarNet(32, [3, 3, 12, 5], **kwargs)
if pretrained:
url = model_urls['starnet_s4']
checkpoint = torch.hub.load_state_dict_from_url(url=url, map_location="cpu")
model.load_state_dict(checkpoint["state_dict"])
return model
# very small networks #
@register_model
def starnet_s050(pretrained=False, **kwargs):
return StarNet(16, [1, 1, 3, 1], 3, **kwargs)
@register_model
def starnet_s100(pretrained=False, **kwargs):
return StarNet(20, [1, 2, 4, 1], 4, **kwargs)
@register_model
def starnet_s150(pretrained=False, **kwargs):
return StarNet(24, [1, 2, 4, 2], 3, **kwargs)
if __name__ == "__main__":
# 配置设备(CPU 或 GPU)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(f"Using device: {device}")
# 加载 starnet_s1 模型
model = starnet_s1(pretrained=False, num_classes=1000).to(device)
print("Model loaded successfully.")
# 模拟输入数据(batch_size=1, 3通道图像,大小为224x224)
input_tensor = torch.randn(1, 3, 224, 224).to(device)
# 模型推理
with torch.no_grad(): # 关闭梯度计算
model.eval() # 设置模型为评估模式
output = model(input_tensor)
# 打印输出结果形状
print(f"Output shape: {output.shape}")
# 打印模型摘要(可选)
summary(model, input_size=(3, 224, 224))便捷下载
https://github.com/AIFengheshu/Plug-play-modules/blob/main/(CVPR%202024)%20StarNet.py
下载1:OpenCV-Contrib扩展模块中文版教程
在「小白学视觉」公众号后台回复:扩展模块中文教程,即可下载全网第一份OpenCV扩展模块教程中文版,涵盖扩展模块安装、SFM算法、立体视觉、目标跟踪、生物视觉、超分辨率处理等二十多章内容。
下载2:Python视觉实战项目52讲
在「小白学视觉」公众号后台回复:Python视觉实战项目,即可下载包括图像分割、口罩检测、车道线检测、车辆计数、添加眼线、车牌识别、字符识别、情绪检测、文本内容提取、面部识别等31个视觉实战项目,助力快速学校计算机视觉。
下载3:OpenCV实战项目20讲
在「小白学视觉」公众号后台回复:OpenCV实战项目20讲,即可下载含有20个基于OpenCV实现20个实战项目,实现OpenCV学习进阶。
交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~
















 3495
3495

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









