






点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达


一、论文信息

1
论文题目:ConDSeg: A General Medical Image Segmentation Framework via Contrast-Driven Feature Enhancement
中文题目:ConDSeg:一种通过对比驱动特征增强的通用医学图像分割框架
论文链接:https://arxiv.org/pdf/2412.08345
官方github:https://github.com/Mengqi-Lei/ConDSeg
所属机构:中国地质大学,武汉;百度公司,北京
核心速览:本文提出了一种名为ConDSeg的通用医学图像分割框架,通过对比驱动的特征增强来解决医学图像分割中的“软边界”和共现现象两大挑战。

二、论文概要

Highlight
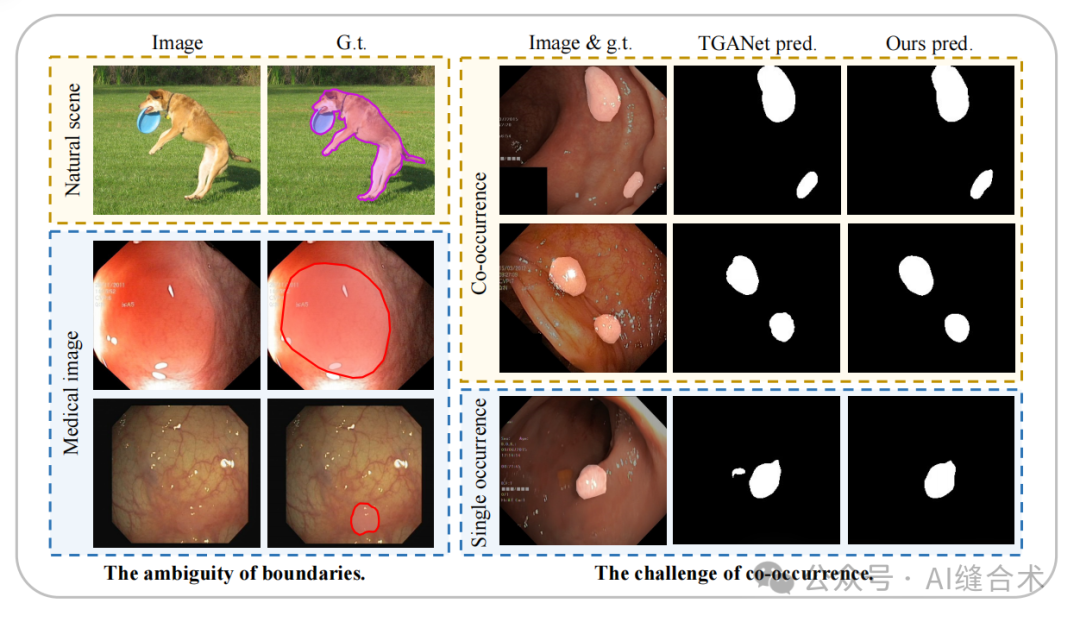
图1:医学图像分割中的主要挑战。
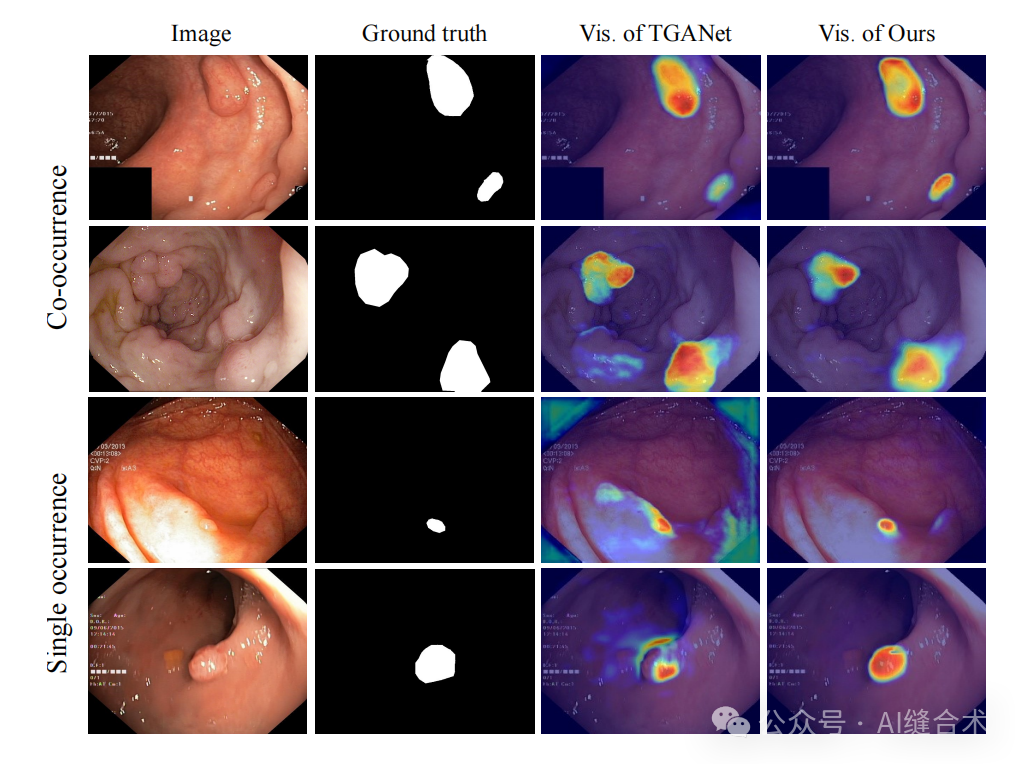
图3:不同方法的Grad-CAM可视化。它展示了我们模型和TGANet在共现和单独出现情况下的注意力区域。
1. 研究背景:
研究问题:医学图像分割在临床决策、治疗规划和疾病监测中扮演着重要角色。然而,由于医学图像中前景和背景之间存在“软边界”,以及图像照明条件差、对比度低,导致前景和背景的可区分性降低,使得准确分割成为挑战。此外,医学图像中广泛存在的共现现象,使得模型容易学习到与目标本身无关的共现特征,导致预测不准确。
研究难点:医学图像分割面临的主要挑战包括图像中前景和背景之间的模糊边界(软边界)以及图像中广泛存在的共现现象。这些挑战导致模型难以准确提取和区分目标特征,从而影响分割性能。
文献综述:近年来,深度学习方法在医学图像分割领域显示出巨大潜力,如U-Net、U-Net++、PraNet、TGANet、CASF-Net等不断改进分割性能。尽管现有深度学习方法在医学图像分割方面取得了重大突破,但准确分割仍然是一个挑战。为了解决这些问题,本文提出了一种名为ConDSeg的通用医学图像分割框架,通过对比驱动的特征增强来提高模型的分割性能。
2. 本文贡献:
对比驱动特征增强:提出了一种名为ConDSeg的通用医学图像分割框架,通过对比驱动特征增强来解决医学图像中前景和背景之间的“软边界”问题,以及图像中光照不足和对比度低导致的可区分性差的问题。ConDSeg框架包括一致性增强训练策略和语义信息解耦模块,以及对比驱动特征聚合模块和尺寸感知解码器。
对比驱动特征聚合模块(CDFA):提出对比驱动特征聚合模块,接收来自语义信息解耦模块的前景和背景特征,指导多级特征融合和关键特征增强,进一步区分待分割实体。
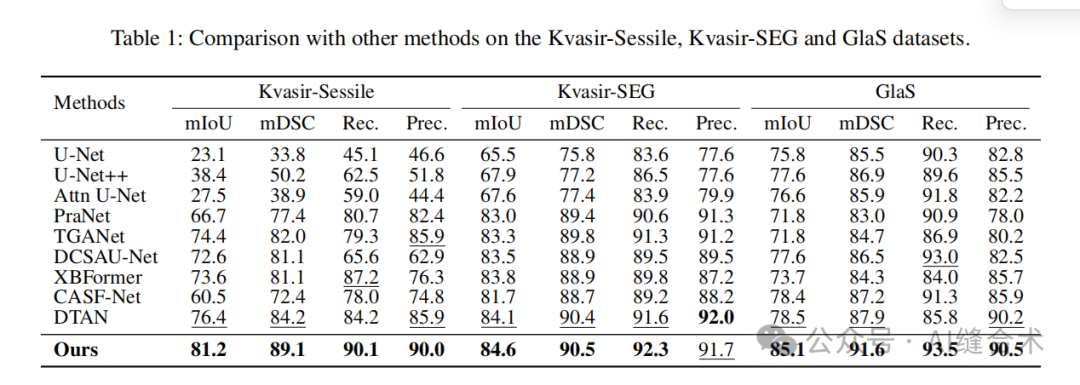
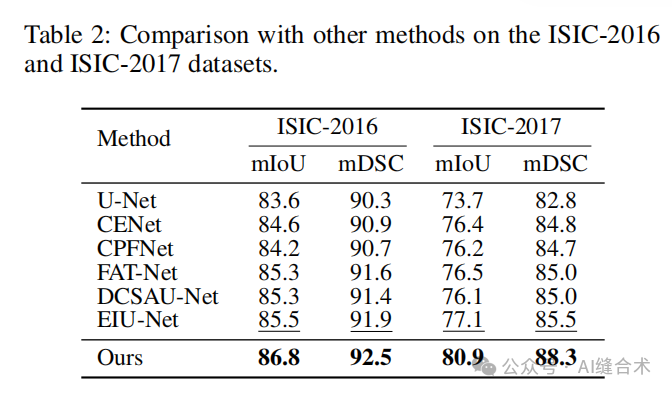
实验结果:在五个具有挑战性的公共医学图像分割数据集上进行了广泛的实验,包括Kvasir-SEG、Kvasir-Sessile、GlaS、ISIC-2016和ISIC-2017,覆盖了三种医学图像模态的任务。ConDSeg在所有五个数据集上均取得了最先进的性能,验证了该框架的先进性和普遍适用性。

三、方法

1
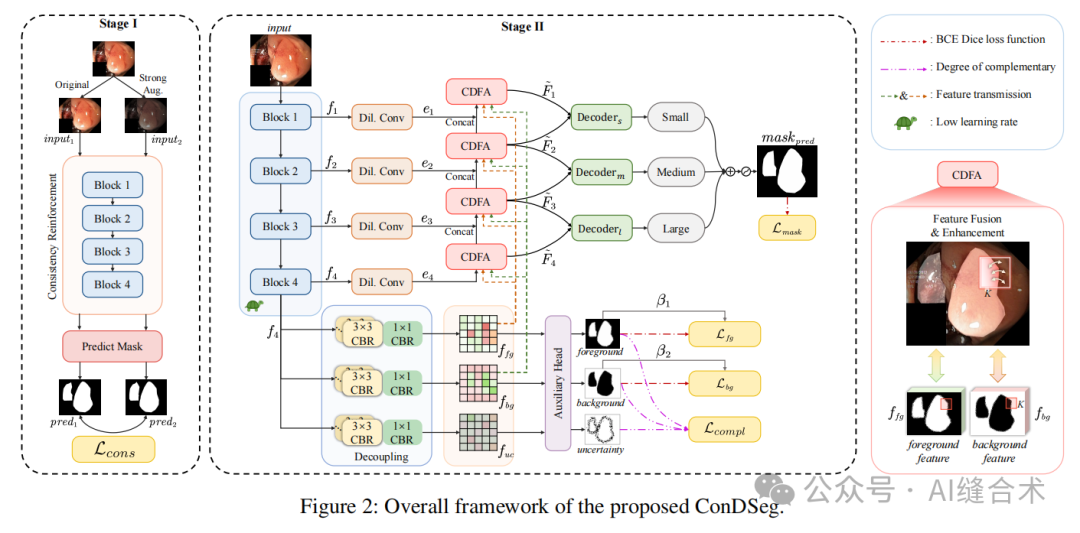
图2:所提出的ConDSeg的整体框架。
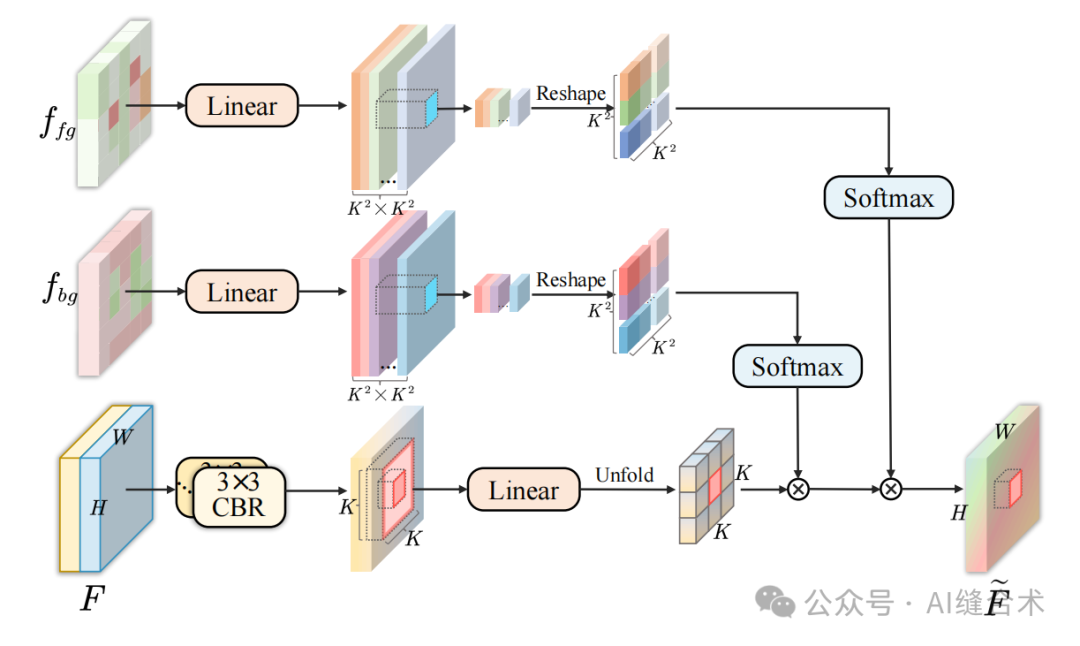
图4:CDFA的结构。
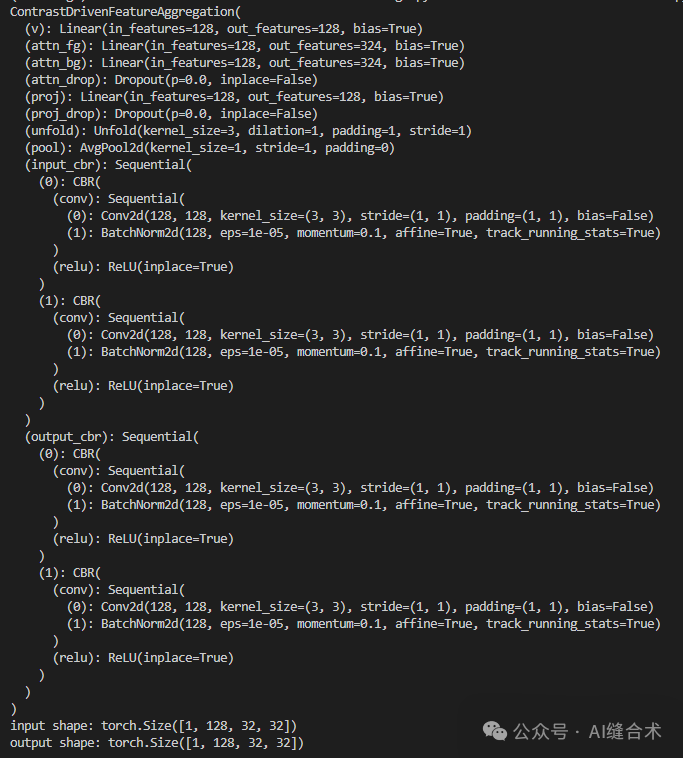
CDFA模块通过显式建模前景特征(foregroundfeature,fg)和背景特征(backgroundfeature,fg)的对比关系,增强输入特征图F的语义表达能力。实现原理:
1. 计算注意力权重:在每个空间位置 (i,j),CDFA 通过包含前景和背景细节的 K ×K 窗口计算注意力权重。输入特征图F首先通过多个 CBR(卷积、BatchNorm和ReLU) 块进行初步融合,然后通过线性层映射到值向量V。接着,V在每个局部窗口展开,准备为每个位置聚合邻域信息。
2. 生成注意力权重:前景和背景特征图通过两个不同的线性层处理,生成相应的注意力权重A_{fg}和A_{bg}。
3. 加权聚合特征表示:通过 Softmax 函数激活前景和背景的注意力权重,然后对展开的值向量V进行加权,以获得每个位置的加权值表示。
4. 密集聚合特征表示:最后,将加权值表示密集聚合以获得最终的输出特征图。

四、实验分析

1. 本文在五个具有挑战性的公共数据集上进行了实验,这些数据集包括Kvasir-SEG、Kvasir-Sessile、GlaS、ISIC-2016和ISIC-2017,涵盖了内窥镜、全切片图像(WSI)和皮肤镜三种不同的医学图像模态。实验结果表明,本文提出的ConDSeg方法在所有数据集上均取得了最先进的性能。ConDSeg在Kvasir-Sessile数据集上的mIoU(平均交并比)为84.6%,mDSC(平均Sorensen-Dice系数)为90.5%;在Kvasir-SEG数据集上,mIoU为81.2%,mDSC为89.1%;在GlaS数据集上,mIoU为85.1%,mDSC为91.6%。在ISIC-2016数据集上,mIoU为86.8%,mDSC为92.5%;在ISIC-2017数据集上,mIoU为80.9%,mDSC为88.3%。这些结果均优于其他对比方法,如U-Net、U-Net++、PraNet、TGANet等。

五、代码

1
 温馨提示:对于所有推文中出现的代码,如果您在微信中复制的代码排版错乱,请复制该篇推文的链接,在任意浏览器中打开,再复制相应代码,即可成功在开发环境中运行!或者进入官方github仓库找到对应代码进行复制!
温馨提示:对于所有推文中出现的代码,如果您在微信中复制的代码排版错乱,请复制该篇推文的链接,在任意浏览器中打开,再复制相应代码,即可成功在开发环境中运行!或者进入官方github仓库找到对应代码进行复制!
import torch
import torch.nn as nn
import math
import torch.nn.functional as F
# 论文题目:ConDSeg: A General Medical Image Segmentation Framework via Contrast-Driven Feature Enhancement
# 中文题目:ConDSeg:一种通过对比驱动特征增强的通用医学图像分割框架
# 论文链接:https://arxiv.org/pdf/2412.08345
# 官方github:https://github.com/Mengqi-Lei/ConDSeg
# 所属机构:中国地质大学,武汉;百度公司,北京
# 代码整理:微信公众号《AI缝合术》
class CBR(nn.Module):
def __init__(self, in_c, out_c, kernel_size=3, padding=1, dilation=1, stride=1, act=True):
super().__init__()
self.act = act
self.conv = nn.Sequential(
nn.Conv2d(in_c, out_c, kernel_size, padding=padding, dilation=dilation, bias=False, stride=stride),
nn.BatchNorm2d(out_c)
)
self.relu = nn.ReLU(inplace=True)
def forward(self, x):
x = self.conv(x)
if self.act == True:
x = self.relu(x)
return x
class ContrastDrivenFeatureAggregation(nn.Module):
def __init__(self, in_c, dim, num_heads, kernel_size=3, padding=1, stride=1,
attn_drop=0., proj_drop=0.):
super().__init__()
self.dim = dim
self.num_heads = num_heads
self.kernel_size = kernel_size
self.padding = padding
self.stride = stride
self.head_dim = dim // num_heads
self.scale = self.head_dim ** -0.5
self.v = nn.Linear(dim, dim)
self.attn_fg = nn.Linear(dim, kernel_size ** 4 * num_heads)
self.attn_bg = nn.Linear(dim, kernel_size ** 4 * num_heads)
self.attn_drop = nn.Dropout(attn_drop)
self.proj = nn.Linear(dim, dim)
self.proj_drop = nn.Dropout(proj_drop)
self.unfold = nn.Unfold(kernel_size=kernel_size, padding=padding, stride=stride)
self.pool = nn.AvgPool2d(kernel_size=stride, stride=stride, ceil_mode=True)
self.input_cbr = nn.Sequential(
CBR(in_c, dim, kernel_size=3, padding=1),
CBR(dim, dim, kernel_size=3, padding=1),
)
self.output_cbr = nn.Sequential(
CBR(dim, dim, kernel_size=3, padding=1),
CBR(dim, dim, kernel_size=3, padding=1),
)
def forward(self, x, fg, bg):
x = self.input_cbr(x)
x = x.permute(0, 2, 3, 1)
fg = fg.permute(0, 2, 3, 1)
bg = bg.permute(0, 2, 3, 1)
B, H, W, C = x.shape
v = self.v(x).permute(0, 3, 1, 2)
v_unfolded = self.unfold(v).reshape(B, self.num_heads, self.head_dim,
self.kernel_size * self.kernel_size,
-1).permute(0, 1, 4, 3, 2)
attn_fg = self.compute_attention(fg, B, H, W, C, 'fg')
x_weighted_fg = self.apply_attention(attn_fg, v_unfolded, B, H, W, C)
v_unfolded_bg = self.unfold(x_weighted_fg.permute(0, 3, 1, 2)).reshape(B, self.num_heads, self.head_dim,
self.kernel_size * self.kernel_size,
-1).permute(0, 1, 4, 3, 2)
attn_bg = self.compute_attention(bg, B, H, W, C, 'bg')
x_weighted_bg = self.apply_attention(attn_bg, v_unfolded_bg, B, H, W, C)
x_weighted_bg = x_weighted_bg.permute(0, 3, 1, 2)
out = self.output_cbr(x_weighted_bg)
return out
def compute_attention(self, feature_map, B, H, W, C, feature_type):
attn_layer = self.attn_fg if feature_type == 'fg' else self.attn_bg
h, w = math.ceil(H / self.stride), math.ceil(W / self.stride)
feature_map_pooled = self.pool(feature_map.permute(0, 3, 1, 2)).permute(0, 2, 3, 1)
attn = attn_layer(feature_map_pooled).reshape(B, h * w, self.num_heads,
self.kernel_size * self.kernel_size,
self.kernel_size * self.kernel_size).permute(0, 2, 1, 3, 4)
attn = attn * self.scale
attn = F.softmax(attn, dim=-1)
attn = self.attn_drop(attn)
return attn
def apply_attention(self, attn, v, B, H, W, C):
x_weighted = (attn @ v).permute(0, 1, 4, 3, 2).reshape(
B, self.dim * self.kernel_size * self.kernel_size, -1)
x_weighted = F.fold(x_weighted, output_size=(H, W), kernel_size=self.kernel_size,
padding=self.padding, stride=self.stride)
x_weighted = self.proj(x_weighted.permute(0, 2, 3, 1))
x_weighted = self.proj_drop(x_weighted)
return x_weighted
if __name__ == '__main__':
cdfa =ContrastDrivenFeatureAggregation(in_c=128, dim=128, num_heads=4)
# 输入特征图
x = torch.randn(1,128,32,32)
# 前景特征图
fg = torch.randn(1,128,32,32)
# 背景特征图
bg = torch.randn(1,128,32,32)
# 打印网络结构
print(cdfa)
#前向传播,输入张量x,fg,和bg
output = cdfa(x,fg,bg)
#打印输出张量的形状
print("input shape:", x.shape)
print("output shape:", output.shape)运行结果
便捷下载
https://github.com/AIFengheshu/Plug-play-modules/blob/main/(AAAI%202025)%20ContrastDrivenFeatureAggregation.py
下载1:OpenCV-Contrib扩展模块中文版教程
在「小白学视觉」公众号后台回复:扩展模块中文教程,即可下载全网第一份OpenCV扩展模块教程中文版,涵盖扩展模块安装、SFM算法、立体视觉、目标跟踪、生物视觉、超分辨率处理等二十多章内容。
下载2:Python视觉实战项目52讲
在「小白学视觉」公众号后台回复:Python视觉实战项目,即可下载包括图像分割、口罩检测、车道线检测、车辆计数、添加眼线、车牌识别、字符识别、情绪检测、文本内容提取、面部识别等31个视觉实战项目,助力快速学校计算机视觉。
下载3:OpenCV实战项目20讲
在「小白学视觉」公众号后台回复:OpenCV实战项目20讲,即可下载含有20个基于OpenCV实现20个实战项目,实现OpenCV学习进阶。
交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~
















 429
429

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









