






点击下方“ReadingPapers”卡片,每天获取顶刊论文解读
论文信息
题目:MixFormer: A Mixed CNN-Transformer Backbone for Medical Image Segmentation
MixFormer:一种用于医学图像分割的混合CNN-Transformer骨干网络
作者:un Liu, Kunqi Li, Chun Huang, Hua Dong, Yusheng Song, and Rihui Li
论文创新点
混合CNN-Transformer骨干网络:本文提出了一种混合CNN-Transformer(MixFormer)特征提取骨干网络,在下采样过程中无缝集成了Transformer的全局上下文信息和CNN的局部细节信息。
多尺度空间感知融合(MSAF)模块:为了捕捉跨尺度的特征依赖关系,作者引入了多尺度空间感知融合(MSAF)模块。
混合多分支扩张注意力(MMDA)机制:在编码和解码阶段之间,作者提出了混合多分支扩张注意力(MMDA)机制,用于弥合语义差距并强调特定区域。
基于CNN的上采样方法:为了恢复低级特征并提高分割精度,作者采用了基于CNN的上采样方法。
摘要
Transformer通过自注意力机制在医学图像处理中取得了显著进展,能够建模长距离语义依赖关系,但其缺乏卷积神经网络(CNN)捕捉局部空间细节的能力。本文提出了一种基于混合CNN-Transformer(MixFormer)特征提取骨干网络的新型分割网络,旨在提升医学图像分割的效果。MixFormer网络在下采样过程中无缝集成了Transformer和CNN架构的全局和局部信息。为了全面捕捉跨尺度的视角,作者引入了多尺度空间感知融合(MSAF)模块,有效实现了粗粒度与细粒度特征表示之间的交互。此外,作者还提出了混合多分支扩张注意力(MMDA)模块,用于在编码和解码阶段之间弥合语义差距,同时强调特定区域。最后,作者采用基于CNN的上采样方法来恢复低级特征,显著提高了分割精度。通过在多个主流医学图像数据集上的实验验证,MixFormer表现出卓越的性能。在Synapse数据集上,该方法达到了82.64%的平均Dice相似系数(DSC)和12.67 mm的平均Hausdorff距离(HD)。在自动心脏诊断挑战(ACDC)数据集上,DSC达到了91.01%。在国际皮肤成像协作(ISIC)2018数据集上,模型的平均交并比(mIoU)为0.841,准确率为0.958,精确率为0.910,召回率为0.934,F1得分为0.913。在Kvasir-SEG数据集上,平均Dice为0.9247,mIoU为0.8615,精确率为0.9181,召回率为0.9463。在CVC-ClinicDB数据集上,平均Dice为0.9441,mIoU为0.8922,精确率为0.9437,召回率为0.9458。这些结果表明,MixFormer在分割性能上优于大多数主流分割网络,如CNN和其他基于Transformer的结构。
关键词
医学图像分割(SEG),混合卷积神经网络(CNN)-Transformer骨干网络,混合多分支扩张注意力(MMDA),多尺度空间感知融合(MSAF)。
III. 方法
A. 网络结构
所提出的MixFormer遵循典型的U形架构,主要由编码器、解码器和跳跃连接组成。编码器由两部分组成:基于CNN-Transformer的混合特征提取骨干网络和MSAF模型。解码器由基本的CNN单元组成。此外,在跳跃连接部分引入了混合多分支扩张注意力(MMDA)模块。在该方法中,混合特征提取器用于从Transformer和CNN中获取多层视觉特征,分别包含全局和局部线索。MSAF机制进一步在多个尺度之间交互语义信息,以获得增强的特征表示。为了获得更好的上采样性能,作者在编码器的最深层实现了Res-Conv块,以进一步加强全局特征表示。最后,作者将MMDA机制集成到跳跃连接中,有效地将融合的语义特征传递到解码器,以进行最终的分割预测。
B. 混合特征提取骨干网络
在MixFormer中,作者使用了一种混合编码器框架,该框架由Swin Transformer和Res2Net50组成,用于在编码阶段提取特征。这使得编码器能够在每个尺度上有效捕捉局部细节和全局上下文信息。Res2Net50在提取多尺度特征方面优于传统的CNN。此外,Swin Transformer在定义的窗口内对图像块进行自注意力计算,其计算开销与图像大小呈线性关系,这与ViT在整个图像块集上进行自注意力计算形成对比。
1) Res2Net50模型
标准的卷积核只能从给定图像中提取相同尺度的特征,因此需要构建不同大小的卷积核以获得多尺度特征。Gao等人提出了Res2Net,专门设计用于获取多尺度特征图。对于包括ResNet和ResNeXt在内的许多CNN架构,瓶颈块是基本组件。Res2Net寻求一种替代设计,以在保持与瓶颈块相当的计算负担的同时,获得更强大的多尺度特征提取能力。Res2Net块与瓶颈块的区别如图3所示。
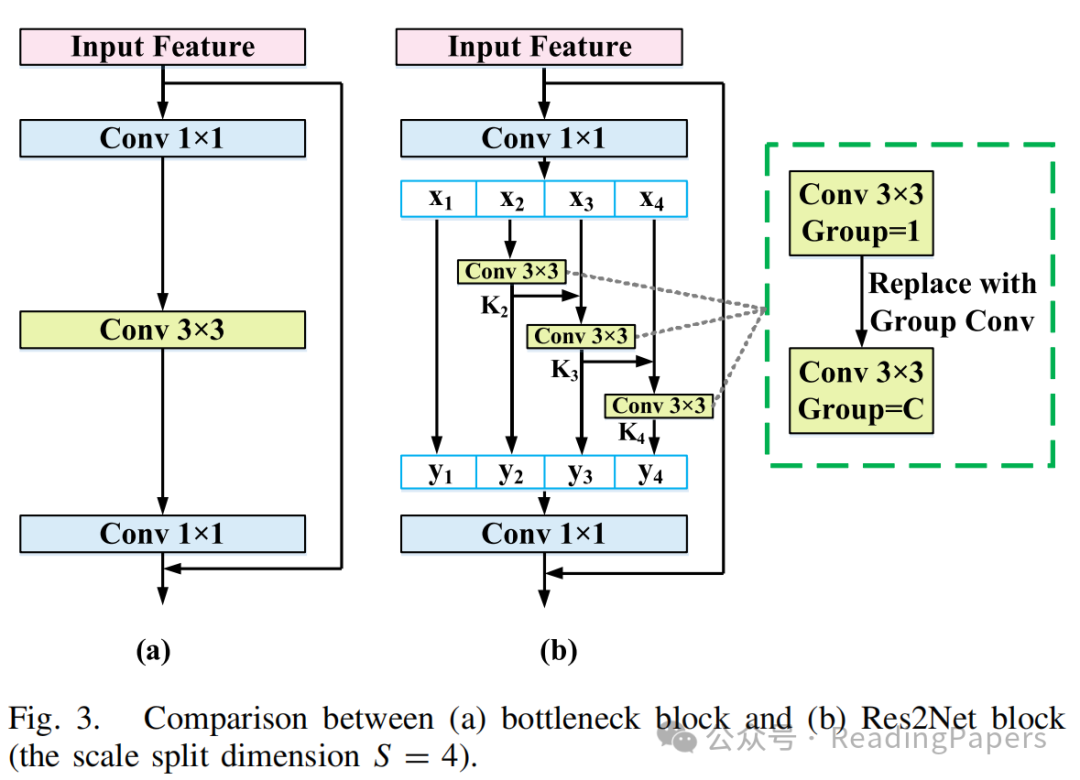
具体来说,在1×1卷积之后,输入特征图被均匀地分为S个子集,表示为,其中。与输入特征图相比,每个子集具有相同的空间大小,但只有1/S的通道数。除了,每个对应一个3×3卷积操作符,表示为。的结果表示为。然后,与子集结合,并输入到中。因此,可以表示为:
在本研究中,通过使用Res2Net50网络作为局部细节提取器,作者有效地分割了原始图像(),以获得不同分辨率的特征金字塔输出到。然后,这些输出的通道维度通过1×1卷积操作映射到与相应Swin Transformer块相同的嵌入维度,并作为补偿Res2Net模型在不同阶段缺失的长距离依赖关系输入到Swin Transformer模块中。在作者的方法中,有四个下采样阶段用于获取局部语义信息。每个阶段的特征图输出大小为、、和,通道数分别为、、和。
2) Swin Transformer模型
如图4所示,ViT对整个嵌入的图像块进行自注意力计算。典型的MSA模块中的一个主要问题是计算复杂度是图像空间维度的二次函数。Swin Transformer引入了W-MSA和SW-MSA技术来缓解这一限制。图5(b)显示了两个连续的Swin Transformer块,每个块由LayerNorm(LN)层、MSA模块、多层感知器(MLP)层和残差连接组成。此外,两个相邻的MSA块被替换为W-MSA和SW-MSA块。W-MSA的计算开销与图像大小呈线性关系,因为它在定义的窗口内进行自注意力计算。然而,由于这些窗口之间缺乏信息交换,其建模长距离依赖关系的能力有限。相比之下,SW-MSA引入了循环移位操作,将每个窗口向左上方向移动。这一策略使得各种不相邻的子窗口能够有效地相互交互。因此,Swin Transformer能够有效地建模上下文依赖关系并获取高效的分层特征表示。
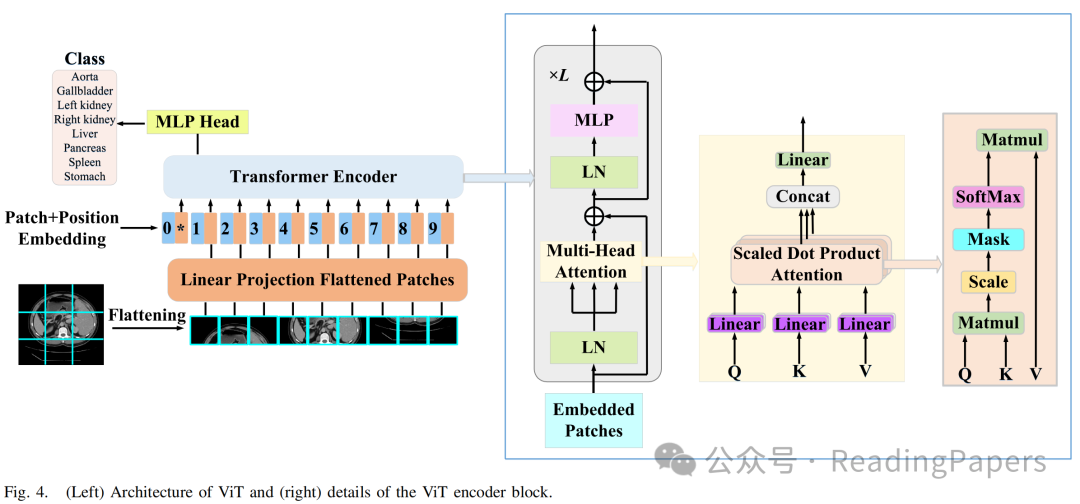
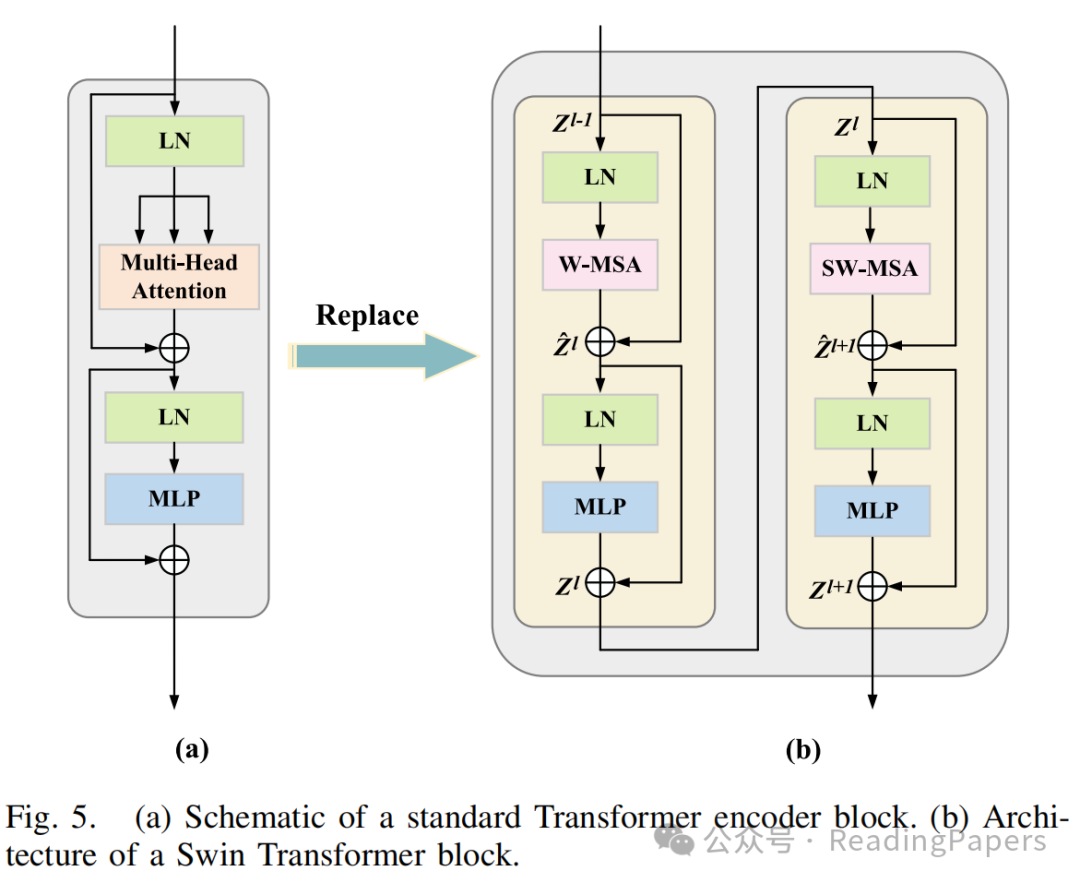
在Swin Transformer中,输入特征图被划分为不重叠的窗口,每个窗口包含(本文中设置为7)个图像块。作为(S)W-MSA的输入,是一个长度为、维度为的图像块序列。基于这种窗口划分策略,Swin Transformer块的输入和输出可以表示为:
其中,和分别表示第个块的W-MSA和MLP的输出。类似地,和分别表示第个块的SW-MSA和MLP的结果。表示层归一化操作。根据先前的工作,自注意力计算如下:
其中,、和分别表示查询、键和值矩阵;表示查询或键的维度。、和表示三个投影矩阵的可学习参数。此外,表示偏置矩阵。
为了弥补Res2Net模型在全局上下文信息方面的缺失,作者将局部细节特征图()划分为图像块,并将其输入到Swin Transformer中。Swin Transformer有四个阶段,每个阶段包含特定数量的块,能够建模长距离依赖关系。这使得作者能够获得四个阶段的特征表示到,其中包含全局上下文信息。此外,作者在每个阶段采用了图像块合并方法,将特征图的通道维度加倍,同时降低分辨率,然后将其输入到下一阶段的Swin Transformer块中。Swin Transformer四个阶段的特征图分辨率分别为、、和,通道数分别为、、和。最后,局部空间信息()和全局语义信息()在相应层次上连接,以获得四个尺度上的增强特征表示到。然后,这些特征表示被输入到MSAF模型中进行不同尺度之间的信息交互。
C. MSAF模型
已经证明,多尺度信号在分割具有复杂位置和大小变化的器官时极为有价值。为了解决多尺度特征之间的语义信息交互问题,作者利用了MSAF模块。该模块包括四个步骤:图像块匹配、尺度融合、尺度分割和图像块反转,这些步骤共同实现了跨尺度依赖关系的建立。MSAF模块的网络结构如图6所示。
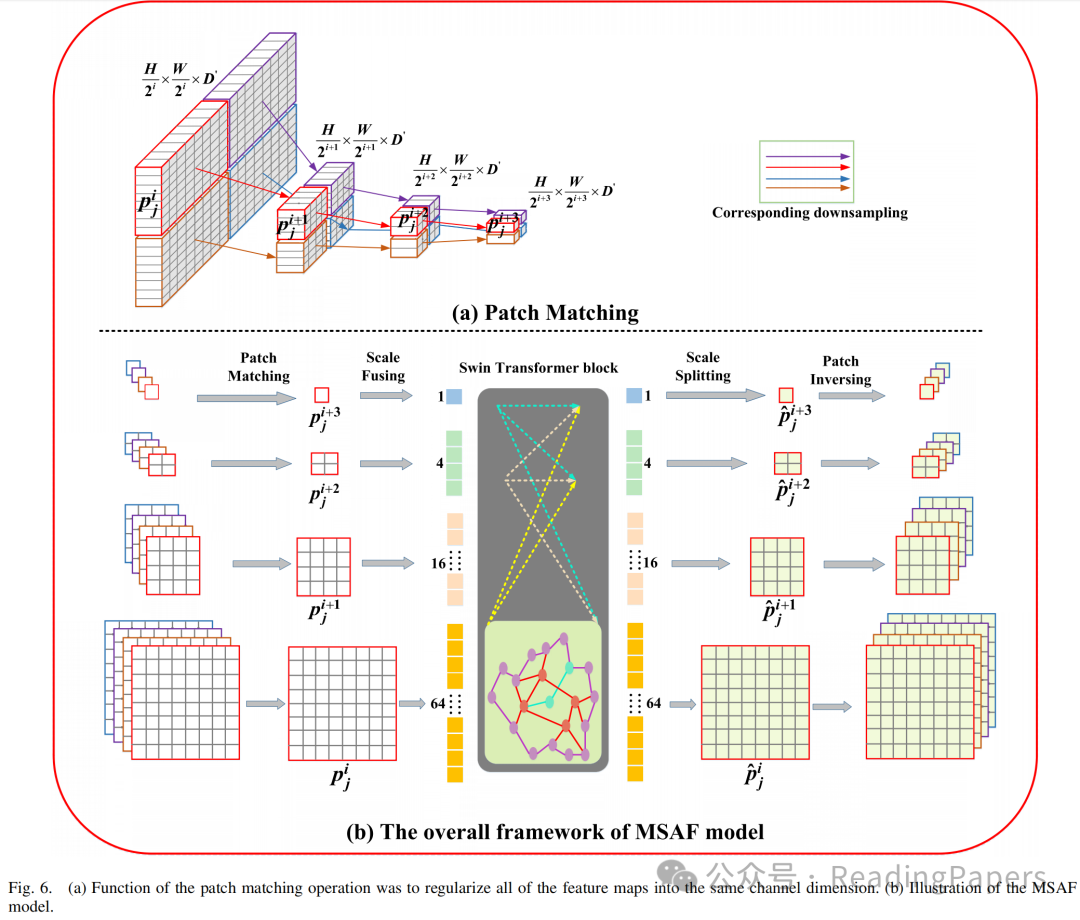
具体来说,作者首先将所有特征图正则化到相同的通道维度,并通过下采样操作将它们分配到具有相同颜色的边界框中(即红色)。如果被视为第个尺度上的第个图像块,那么、和将是匹配的下采样图像块。通过这一步骤,作者能够在从第到第个尺度的四个连续特征映射上定位相关的空间感知图像块,保留最相关图像块的空间对应关系。
然后,作者通过尺度融合方法聚合不同尺度上的空间相关图像块,生成一系列标记。该过程可以描述为:
其中,表示拼接操作。由于这一系列标记缺乏2D空间信息,作者利用Transformer块来确保其空间结构的一致性。
D. 混合多分支扩张注意力模型
神经网络中浅层和深层特征具有不同的表示能力。因此,迫切需要寻求一种解决方案,以有效弥合编码和解码阶段相应特征之间的语义差距,同时最小化由采样过程引发的信息丢失。为此,作者引入了一种混合多分支扩张注意力(MMDA)模型,从三个维度(即通道、空间和全局上下文)映射特征,综合优化提取特征的信息丢失。该方法有效地减少了提取特征中的信息丢失,从而帮助解码器准确恢复特征图的原始分辨率。作者将MSAF每一层(除了最深层的下采样层)提取的特征图与相应的CNN特征金字塔输出融合。然后,通过跳跃连接将该组合输入到MMDA模块中进行特征提取。最终,该方法实现了与相应解码器层的和谐特征融合。MMDA模型由三个单元组成,包括全局自注意力单元、通道注意力单元和空间注意力单元,如图7所示。
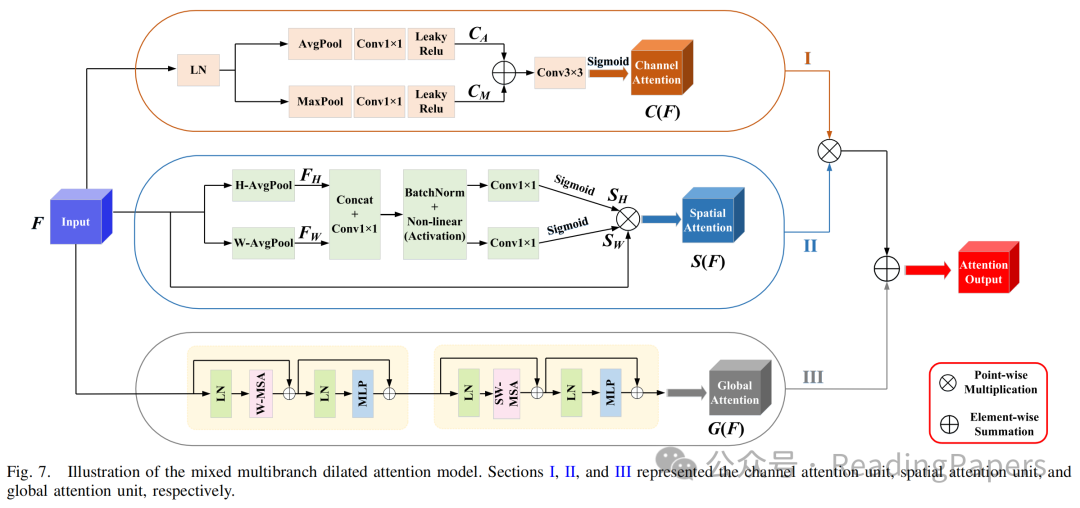
通道注意力单元(图7的第I部分)主要获取图像纹理信息,同时关注每个通道的特征交互。对于给定的输入特征图,通过MaxPooling和AvgPooling操作沿空间轴提取特征信息。获得的特征图和分别经过1×1卷积和LeakyReLU激活,然后进行逐元素加法操作。最后,使用Sigmoid函数获得通道注意力图。具体流程如下:
其中,表示通道注意力图,表示逐像素求和。
空间注意力单元(图7的第II部分)的主要目标是识别网络中最重要区域以进行进一步处理。受先前使用坐标注意力(CA)模块的工作启发,作者采用CA技术作为MMDA模型的空间注意力部分,以编码具有精确空间位置信息的特征表示。该方法分为两个子步骤:坐标信息嵌入和CA生成。具体来说,给定特征图,首先使用尺寸为或的池化核沿水平和垂直坐标对每个通道进行编码。因此,双向坐标信息嵌入的输出如下:
在CA生成步骤中,首先将两个特征图和拼接,并使用共享的1×1卷积操作符生成包含水平和垂直方向空间信息的中间特征图。具体操作如下:
其中,表示非线性激活函数,表示批归一化操作。缩减比通常用于最小化模型的计算复杂度(例如16)。
接下来,作者将沿空间维度分割为两个独立的特征表示和。然后,使用两个1×1卷积将它们转换为与输入特征图相同数量的通道。具体操作如下:
其中,和随后被扩展并分别用作注意力权重。最后,CA块的结果可以表示为:
其中,表示最终的空间注意力图。
全局注意力单元(图7的第III部分)利用Swin Transformer块结构构建全局上下文依赖关系之间的相关性。该操作可以弥补空间和通道注意力单元的信息丢失。首先,输入特征图被划分为一系列图像块。由于图像块之间没有2D空间结构信息,因此需要将图像块输入到(S)W-MSA机制中,以计算图像块之间的相似性表示关系,并从中恢复位置信息。最后,增强的特征序列被转换为全局注意力图。该步骤的细节可以在公式(2)中找到。
最后,作者将和相乘,并进一步加上,得到混合多分支扩张注意力图:
其中,表示使用Python广播机制的乘法,表示逐元素求和。
E. 解码器
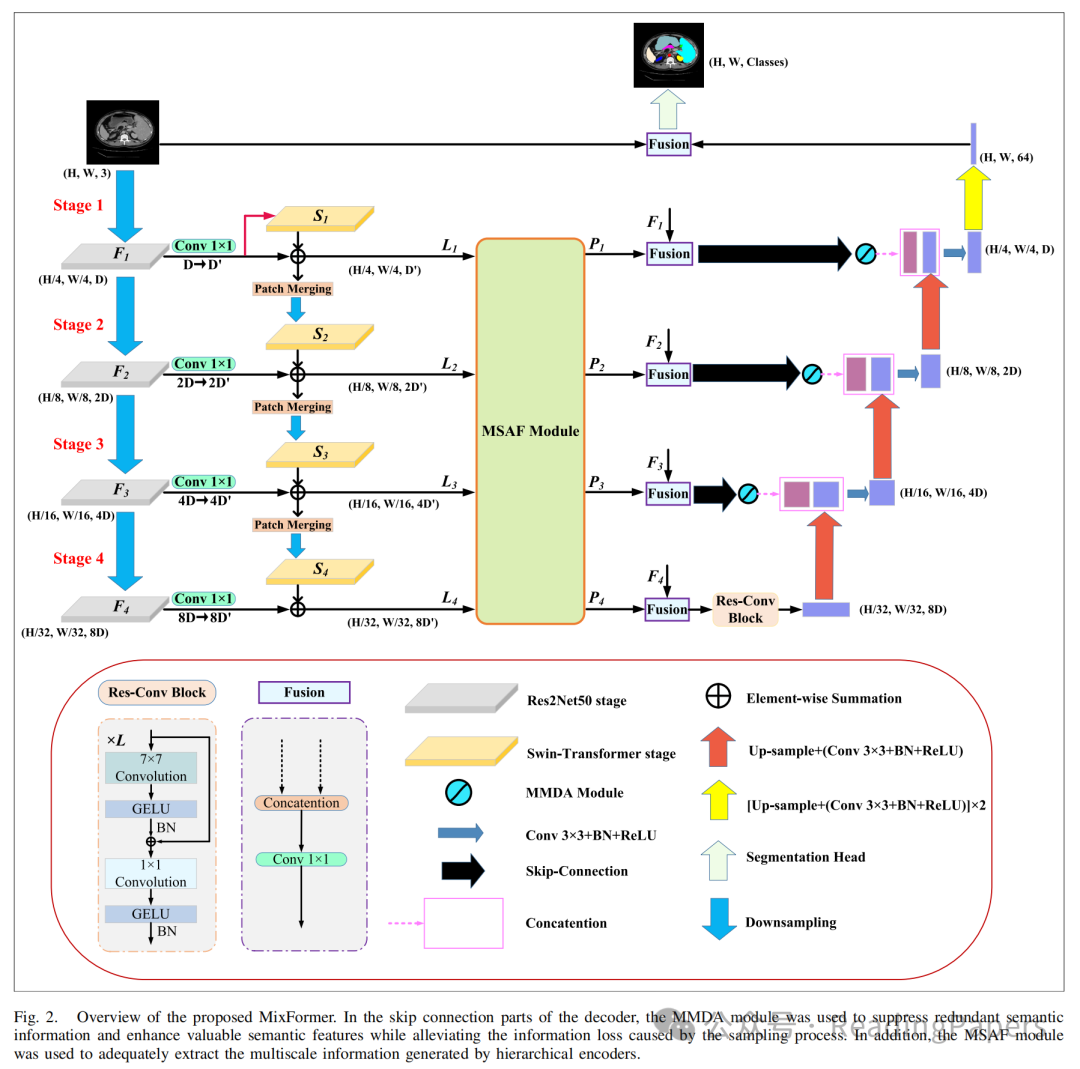
为了增强有效感受野并使其更容易混合远距离上下文信息,融合后的特征图被输入到最深层的下采样层的Res-Conv块中。如图2所示,Res-Conv块由层(本文中设置为7)组成,通过深度卷积(即核大小)和点卷积(即核大小)混合空间位置和通道位置,进一步获取上下文依赖关系。此外,深度卷积中的组通道数等于输入特征图的通道数,并且每个卷积操作都应用了高斯误差线性单元(GeLU)激活和批归一化,如下所示:
其中,表示Res-Conv块中第层的输出特征图,表示GeLU激活,表示批归一化。和表示深度可分离卷积的两个主要阶段,其网络架构如图8所示。
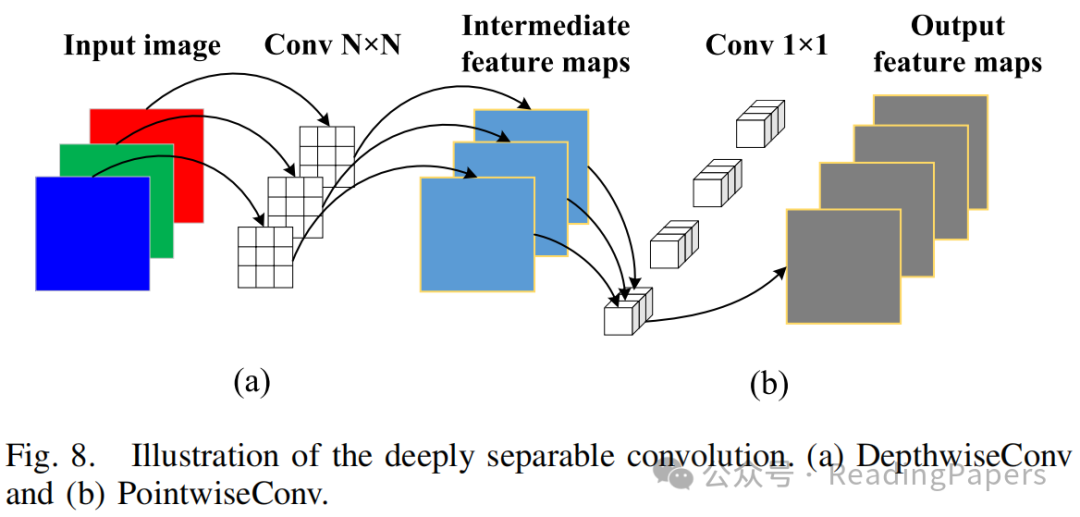
在阶段(图8的(a)部分),每个卷积核被指定处理输入图像的单个通道,生成与输入通道数匹配的中间特征图。例如,当处理的彩色图像时,该过程生成三个大小为的中间特征图。然而,这种每个通道独立进行卷积的方法未能充分利用通道间特征相关性。因此,它忽略了同一空间位置上通道之间的有价值信息交互。为了解决这一局限性并获得最终输出特征图,阶段(图8的(b)部分)是一个关键操作。在这里,使用大小为的卷积核,其中表示前一层特征图的通道数。通过过程,每个卷积核沿通道维度组合中间特征图,有效地生成新的特征图。该方法显著减少了参数数量和计算复杂度,同时保持了令人满意的网络性能。
最后,作者采用双线性插值方法对特征图进行上采样。解码器由四个阶段组成,每个阶段包括一个典型的卷积块、一个上采样操作和ReLU激活函数。解码器首先接收低分辨率()的融合特征图,经过四次连续的上采样操作后生成高分辨率()的特征图。然后,重建的特征图通过分割头中的卷积生成最终的分割结果,其中通道数与预测类别数相同。
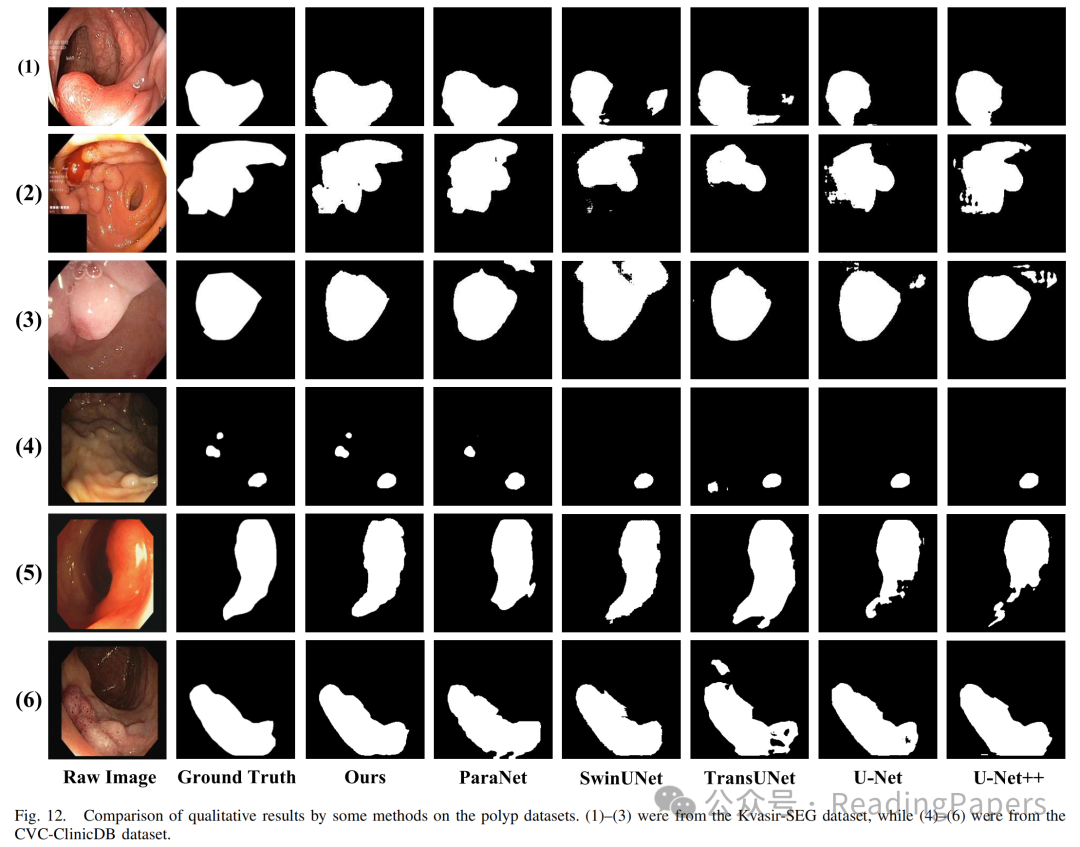
IV. 实验
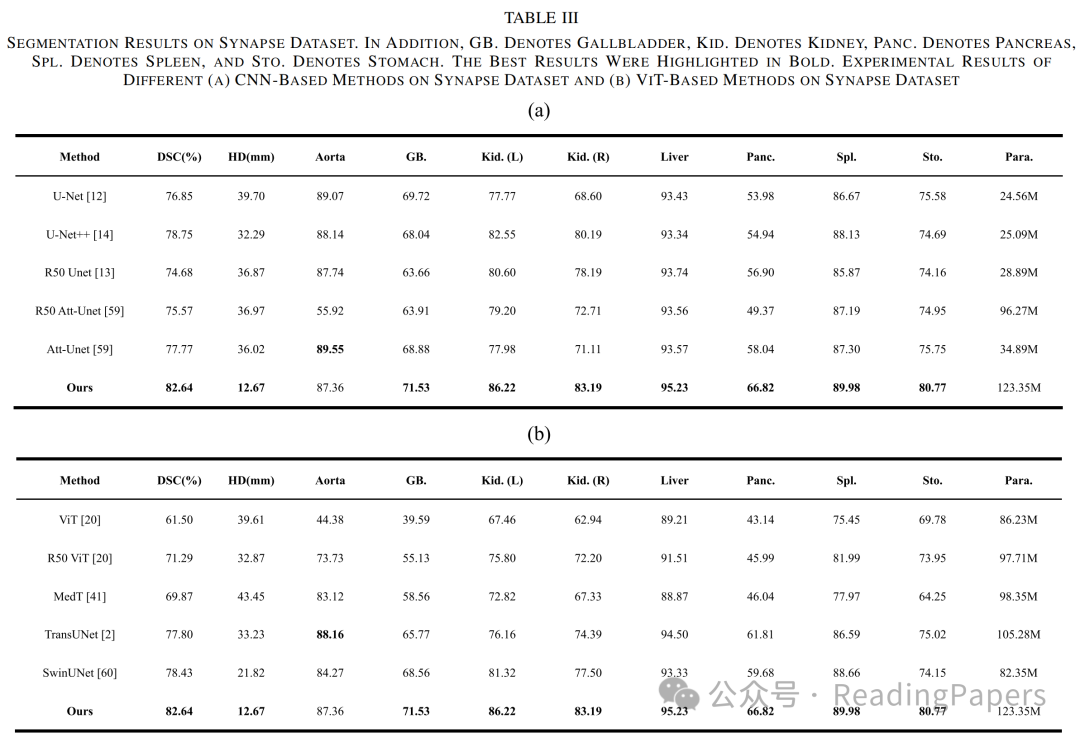
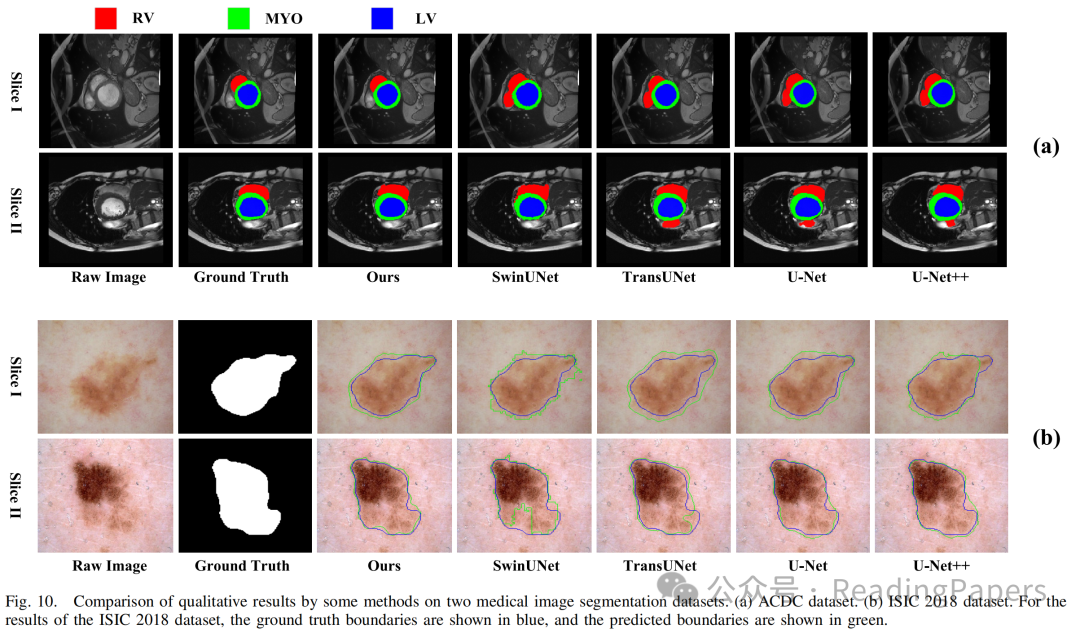
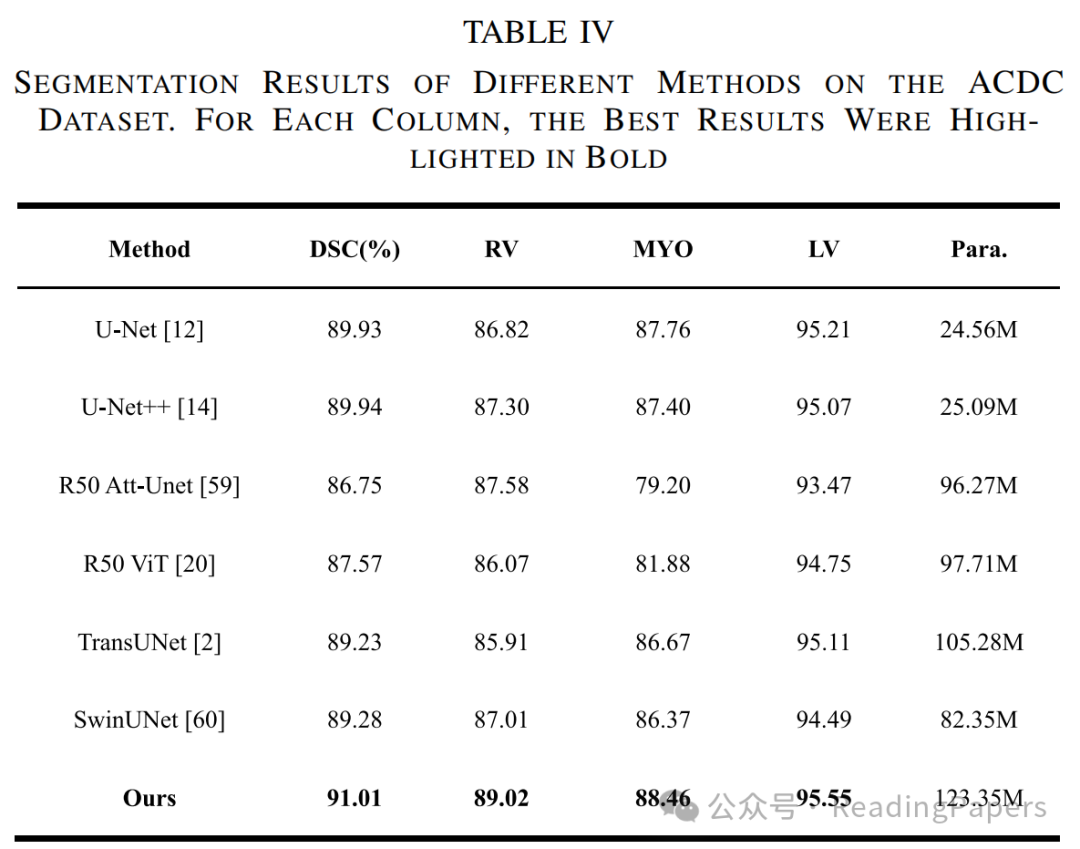
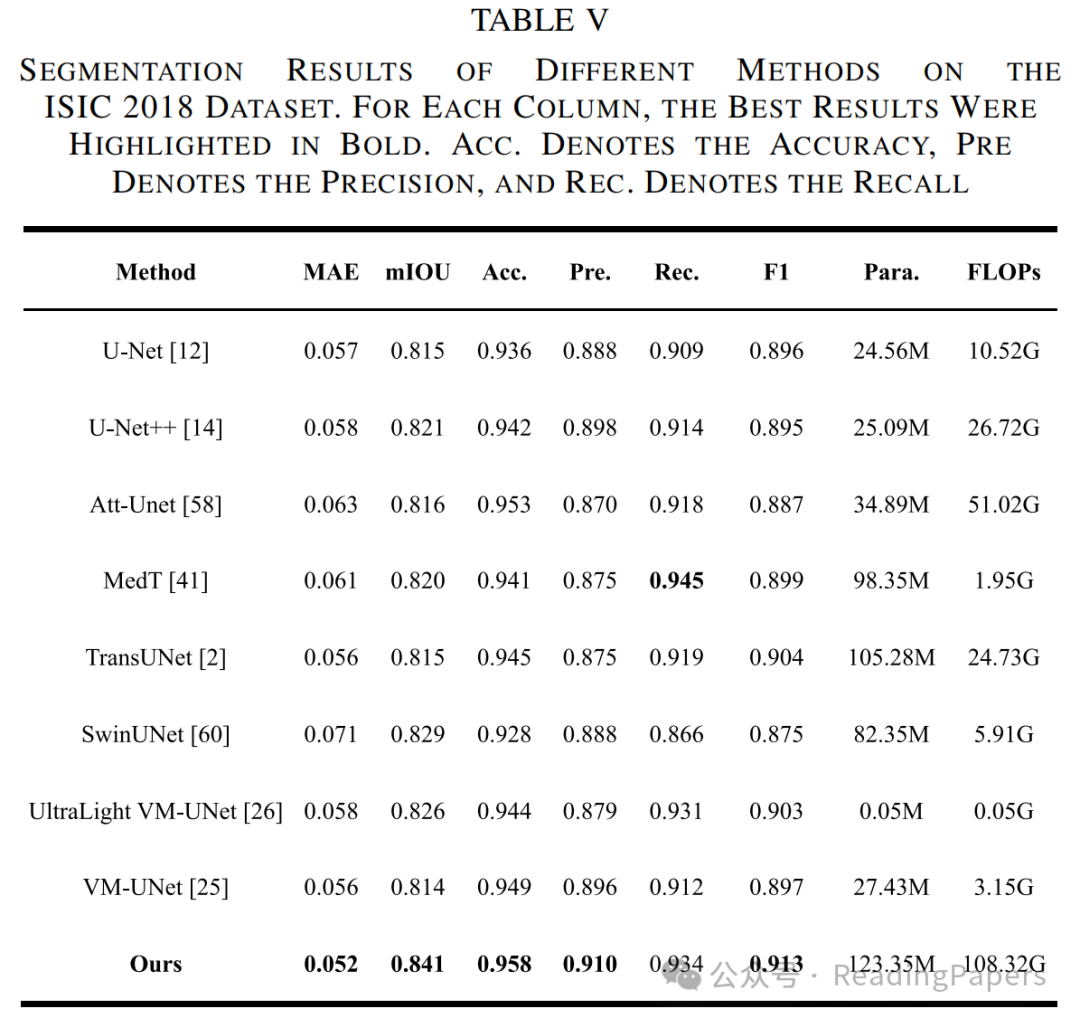
声明
本文内容为论文学习收获分享,受限于知识能力,本文对原文的理解可能存在偏差,最终内容以原论文为准。本文信息旨在传播和学术交流,其内容由作者负责,不代表本号观点。文中作品文字、图片等如涉及内容、版权和其他问题,请及时与我们联系,我们将在第一时间回复并处理。


















 371
371

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









