







 本文介绍了如何通过强化学习(RLHF)让大模型的行为与人类偏好对齐,特别是使用PPO算法优化策略。文章详细阐述了PPO原理、模块构成以及训练流程,包括Actor-Critic架构、KL惩罚、奖励模型和在线迭代的使用。针对训练过程中的问题,如奖励曲线抖动,提供了优化策略建议。
本文介绍了如何通过强化学习(RLHF)让大模型的行为与人类偏好对齐,特别是使用PPO算法优化策略。文章详细阐述了PPO原理、模块构成以及训练流程,包括Actor-Critic架构、KL惩罚、奖励模型和在线迭代的使用。针对训练过程中的问题,如奖励曲线抖动,提供了优化策略建议。
1.为什么需要强化学习
强化学习的目的是在大模型指令微调后,让LLM的行为与人类“对齐”,使其能够理解人类指令并做出对人有帮助的回答,纠正错误和有害的知识。RLHF本质上是通过人类的反馈来优化模型,生成的文本会更加的自然。
具体而言,这些工作通过一个反馈模型(RM)模拟一个人对LLM输出的偏好程度打分,并让LLM利用这一反馈优化其输出策略,进而得到一个能输出“令人满意”的内容的LLM。那么如何让LLM根据RM的反馈优化策略?这便是强化学习所擅长解决的问题,下文将介绍其使用的主要方法;而这一利用“人”的反馈进行强化学习的思路也被称为RLHF。
2.PPO 强化学习原理
2.1 PPO
以SFT为初始策略,基于RM对策略打分,使用强化学习优化策略,得到强化版本的模型PPO。
- 训练的目标是使得PPO生成的答案能够获得高回报。
- 训练的方法是根据RM的打分来更新PPO的参数。
- 为了防止模型被RM过度优化,需要在奖励中增加了一个KL惩罚,保持学到的模型PPO与初始策略SFT模型相差不至太远。
- 同时,可以在优化目标的梯度中混入一些预训练梯度,进一步保证学习到的模型保留SFT的通用能力。具体的方法可以参考论文instructGPT。
2.2 在线PPO训练
随着SFT被优化,得到的PPO模型生成的回复越来越符合人类偏好,最开始训练得到的奖励模型在这种高质量回复上不够鲁棒。为了缓解这个问题,参考论文Anthropic LLM,可以进一步采用在线迭代训练:使用每一轮强化学习得到的最好的PPO模型生成比较数据进行人工标注。将新的比较数据与已有的数据混合,重新训练一个新的奖励模型,最后用新的奖励模型进行新一轮的PPO训练。
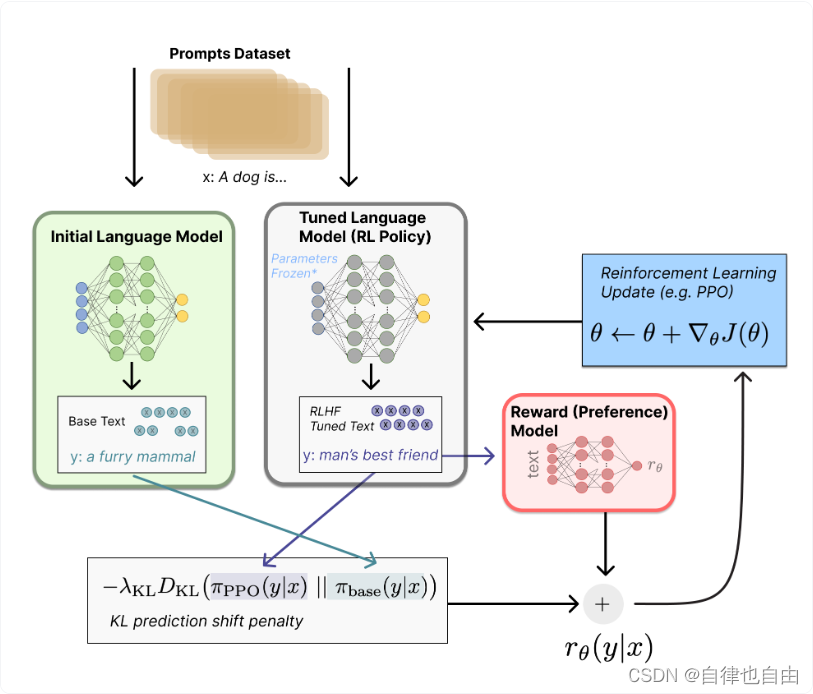
3.模块构成
PPO是强化学习中一种基于AC架构(Actor-Critic)的优化方法,其前身是TRPO,PPO通过引入重要性采样(Importance Sampling)来缓解 on policy 模型一次采样数据只能更新一次模型的问题,提升了数据利用率和模型训练速度。
在 LLM 的训练中,使用 PPO 需要同时载入 4 个模型:
Actor Model:Actor模型是用于进化训练的生成模型。它负责生成策略,根据当前状态选择动作的概率分布。
Critic Model:Critic模型是用于进化训练的评判模型。它负责估计状态值函数或状态-动作值函数,提供对策略的评估和指导。
Ref Model:Ref模型是参照模型,用于通过KL散度来限制Actor模型的训练方向。它的作用是提供一个参考策略,确保Actor模型的更新在一定的范围内,避免过大的策略变化。
Reward Model:Reward模型是奖励模型,用于指导Actor的进化。它可以提供额外的奖励信号或指导信息,帮助Actor模型更好地优化策略。
其中Actor model和Ref model是RLHF第一个阶段有监督微调模型的两个副本,Reward model和Critic model是奖励模型的两个副本。
为了节省显存,通常会将 actor / critic 共享一个 backbone,这样只用同时载入 3 个模型。
4.强化学习训练流程
- 使用Actor模型根据输入的prompt生成一个answer。Actor模型是待微调的大模型,用于生成对话回复。
- 引入奖励模型(reward model)和参考模型(ref model)来对生成的prompt+answer进行评分。奖励模型根据预先定义的评价指标对生成的对话进行评估,而参考模型是一个不会更新参数的模型,用于提供参考答案。
- 使用KL散度度量参考模型和Actor模型输出的分布之间的差异。这是为了约束Actor模型的输出不要偏离参考模型太远。将KL散度纳入损失函数中,以限制两者之间的分布差异。
- 在PPO训练过程中,综合考虑KL散度和奖励模型的输出,计算最终的奖励值。这个奖励值将作为PPO更新公式中的一个部分,用于调整Actor模型的参数。
- 使用PPO算法计算优势值(advantage),优势值是衡量某个动作相对于平均水平的好坏程度。具体公式如下:
Advantage = 实际奖励值 - 价值估计,价值估计就是critic model的输出。 - 进行Actor模型的训练,使用PPO算法的优势值和Actor模型的输出来更新参数。
- 同样的,对Critic模型进行训练和更新,使用均方误差(MSE)损失函数。
- 整个强化学习微调流程涉及了Actor模型、参考模型、奖励模型和Critic模型四个模型,但只有Actor模型和Critic模型的参数被更新。
问题:在训练过程中,如果奖励曲线出现剧烈抖动,可以考虑以下几个因素对此进行优化:
KL Penalty:适当调大 KL可以帮助稳定训练(可使用动态调整 KL 系数策略)。
Reward Model:使用一个更稳定的 RM 能够有效缓解这种问题。
Reward Scaling:reward 的归一化对训练稳定有着很重要的作用。
Batch Size:适当增大 batch_size 有助于训练稳定。


















 1016
1016

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











