







英文名称: True Knowledge Comes from Practice: Aligning LLMs with Embodied Environments via Reinforcement Learning 中文名称: 实践出真知:通过强化学习将LLMS与具体环境对齐 链接: https://arxiv.org/abs/2401.14151 代码: https://github.com/WeihaoTan/TWOSOME 作者: Weihao Tan, Wentao Zhang, Shanqi Liu, Longtao Zheng, Xinrun Wang, Bo An 机构: 新加坡南洋理工大学, 浙江大学, Skywork AI 日期: 2024-01-25 |
1 读后感
这篇论文试图解决的问题是:当自然语言模型与现实世界进行交互时所产生的问题。这种问题不仅可以应用于游戏和机器人等领域,可以说它可被应用在需要代理与环境进行多步交互以解决问题的各个领域,该方法主要用于优化每一步的决策。
在使用大模型时,常见的问题是将复杂问题分解为多个步骤来解决,而每一步动作在真实场景中会有多种可能的反馈,就像下棋一样,很容易出现一步错步步错的情况。通用自然语言模型(LLM)更擅长提出意见,但决策能力稍差,并且缺乏对具体环境的认知。因此,在具体场景下引导模型做出更好决策的方法很重要。
通用自然语言大模型(LLM)具备常识知识,但不了解当前情况;强化学习(RL)通过探索当前环境来学习,但缺乏常识。本论文讨论了如何将二者结合起来,在多步调用 LLM 时使用 RL 方法优化决策。
具体方法如图 -2 所示,将当前的状态和可选的动作放入 LLM。模型将计算每个动作中各个词的联合概率,作为该动作的得分。这种将 LLM 引入强化学习,应用于决策部分的方法有效地将 LLM 和 RL 连接起来。
我觉得具体实现中计算各词的生成概率可能不是最优方法,但对于中小型模型来说,还没有找到更好的方法。另外,在实现部分使用半精度的 LLAMA-7B 模型并用 Lora 进行调参,整体上经济高效,方便我们普通用户复现。
另外我还有一些思考:机器人在虚拟场景中行走、环境不完全可见且无法将复杂环境信息传递给模型作为提示时,使用大模型时经常遇到的问题是:如何选择传递给模型什么信息,来提升工具链的整体能力。这块可能也需要强化学习或者外接模型来实现。
2 摘要
目标:由于知识与环境不一致,通用的大型语言模型(LLMs)经常无法解决简单的决策任务。相反,强化学习(RL)智能体从头开始学习策略,与环境保持一致,但很难结合先验知识进行有效探索。本文旨在结合两个优势。
方法:提出了TWOSOME 在线框架。它使用 LLMs 作为决策 Agent,并通过 RL 与具体环境高效互动,实现知识与环境的对齐。该框架无需任何预先准备的数据集和对环境的先验知识。
结论:TWOSOME 在经典决策环境(Overcooked)和模拟家庭环境(VirtualHome)中都表现出明显更好的样本效率和性能。这可能得益于 LLMs 的“开放词汇”特征,使 TWOSOME 对没见过的任务表现出卓越的泛化能力,在在线 PPO 微调过程中没有显著损失 LLMs 原始能力。
3 方法
论文提出了 True knoWledge cOmeS frOM practicE(TWOSOME)方法。
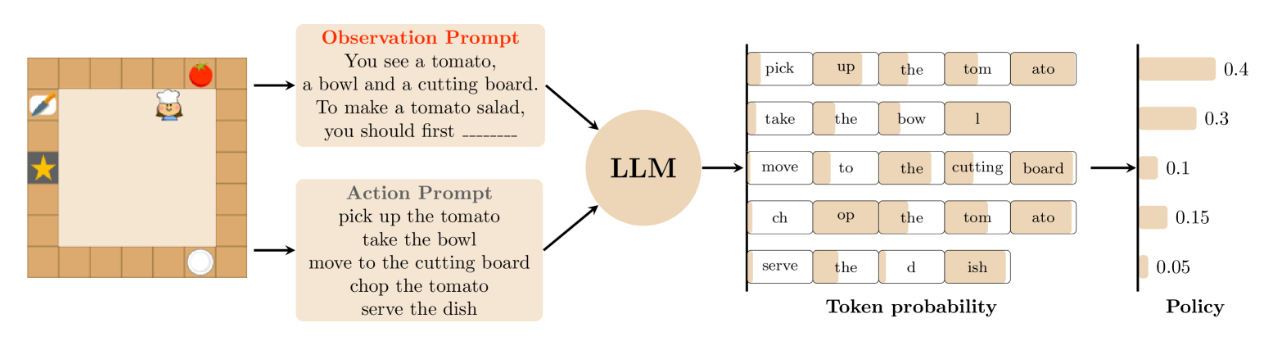
图 2:TWOSOME 使用联合概率生成策略的概述。token 中的颜色区域表示操作中相应令牌的概率。
3.1 有效策略生成
TWOSOME 不是直接让 LLMs 生成操作,而是从 LLMs 中查询所有可用操作的分数。这些分数用于确定执行动作的概率。由于目前大多数 LLMs 不能完全遵循指令,特别是中小型 LLMs(即小于 65B 的模型),需要采用其他方法。
具体方法如图 -2 所示:将环境的观察设为 s,可选的动作设为 a(共有 k 种),每个动作 a 包含 w 个单词。将它们连接起来送入 LLM。使用 LLMs 生成的 token 的概率来计算动作的概率。
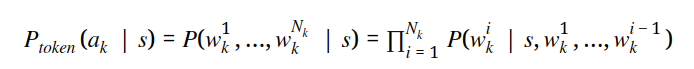
通常,提供的 LLMs 分数是每个 token 的对数似然(logits)。使用 softmax 对获取操作策略的 token 级概率进行归一化。
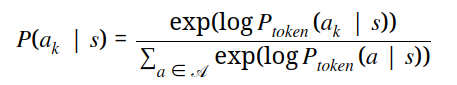
3.2 动作提示归一化
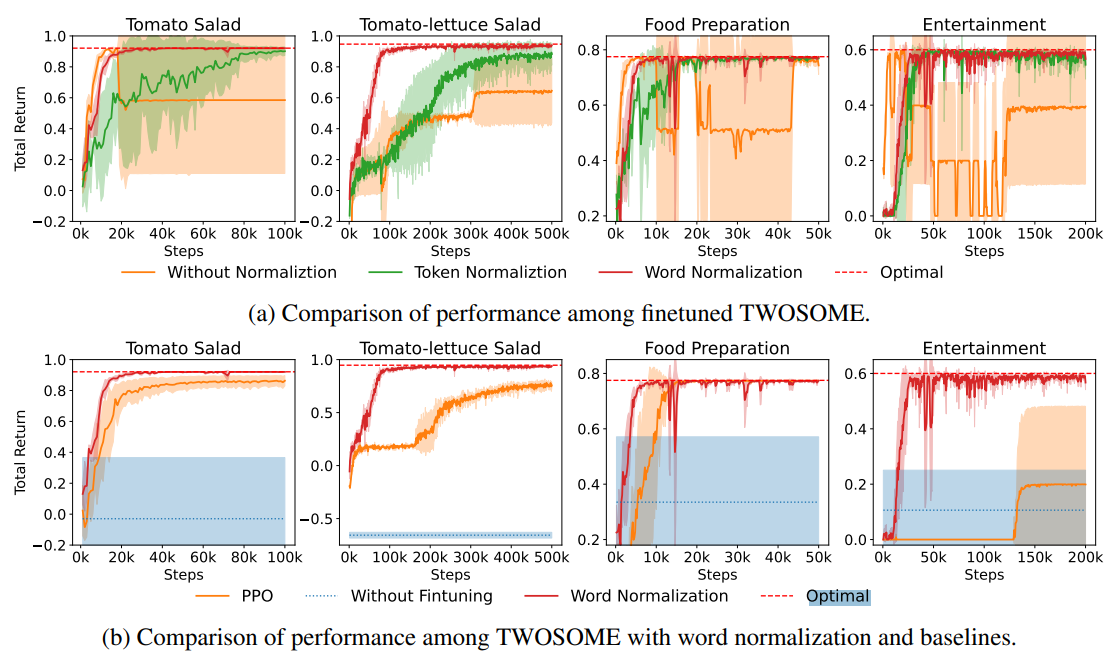
可选的动作单词序列长度通常不同。整体概率是通过连乘得到的,因此单词序列越长,得分越低。为了解决这个问题,作者提出了两种规范化方法:除以单词数或者除以 token 数。(我个人认为这些方法在一定程度上有效,但也有一些不合理之处)
3.3 参数高效的 PPO 微调
3.3.1 架构
|400
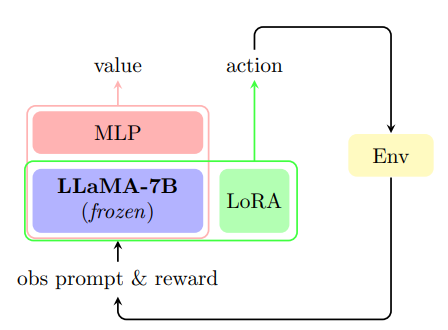
文中使用了 LLM 作为策略生成工具。图 3 展示了在 LLaMA-7B 模型的最后一个 Transformer 中增加了一个额外的 MLP 层作为批评者(critic)。评估者的 MLP 将观察提示的最后一个标记作为输入,并输出对观察提示的估计值。动作者(actor)由冻结的 LLaMA-7B 模型构成,并使用 LoRA 方法进行参数增强。此外,由于 dropout 层可能违反 PPO 中的 KL 发散约束并引入额外的训练不稳定性,在 LoRA 模块中不使用 dropout。在训练过程中,只更新 critic 的 MLP 和 actor 的 LoRA 参数,以提高训练效率。尽管文章讨论了只有解码器的模型,但这种方法可以无缝地扩展到编码器 - 解码器架构。
3.3.2 训练
与 PPO 的训练过程相似,但作者发现使用相同数据多次更新 actor 时训练不稳定。因此,每个采样数据在训练一次后都会被丢弃。此外,新添加的 MLP 在 critic 中是随机初始化的,而 actor 中的 LoRA 参数初始化为零,即 actor 的输出与 LLaMA-7B 模型完全相同。因此,critic 的学习率设置较高,而 actor 的学习率设置较小。
3.3.3 推理
在推理过程中,只使用 actor。此外,将与具体环境相关的 LLMs 完全编码到 Lora 参数中。通常,Lora 参数的大小是 LLMs 的 1/20,例如 LLaMA-7B 的 Lora 仅为 4.2M。LoRA 参数可以作为一个即插即用的模块。
3.4 提示设计
优化提示设计的目的是让 LLMs 更好地理解观察和操作,从而改善环境和模型之间的对齐。设计基于以下原则:
- 观察和行动提示应连贯,以便于连接。观察提示以 " 你应该 " 和 " 下一步是 " 结束,标志着行动提示的开始。
- 冠词(如 "the"、"a" 和 "an")对于行动提示很重要。大多数行动提示由动词和名词组成,例如 " 捡起番茄 "。由于语言模型是用高质量语料库训练的,它们对冠词很敏感。因此," pick up the tomato " 比 " pick up tomato " 更好,后者在 " 番茄 " 上的概率极低。
- 优选的行动应出现在观察提示中。通过在观察提示中多次出现名词,可以鼓励语言模型对优选行动赋予更高的概率。例如,如果观察提示是 " 我看到一个番茄。我的任务是做一个番茄沙拉。我应该 ",那么 " 番茄 " 将有相对高的概率。
- 在不同的观察下,同一行动可以有不同的行动提示。例如,当 agent 手中拿着碗时," 捡起番茄 " 可以被替换为 " 把番茄放在盘子里 ",这两个行动提示在环境中有相同的功能,但后者更符合上下文,因此概率更高。
4 实验
以将上述的方法应用在半精度 LLaMA-7B 模型上。一个 NVIDIA Tesla A100 40GB GPU 中完成所有实验。
实验环境。图 3(a)和 3(b)显示了 Overcooked 中的两个任务。图 3(c)和 3(d)显示了 VirtualHome 中的两个任务。

主实验结果如下:















 3153
3153

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









