






论文精读-SUNet: Swin Transformer UNet for Image Denoising
SUNet:用于图像去噪的Swin Transformer UNet
Swin Transformer:使用移位窗口的分层视觉Transformer
UNet:用于生物医学图像分割的卷积网络
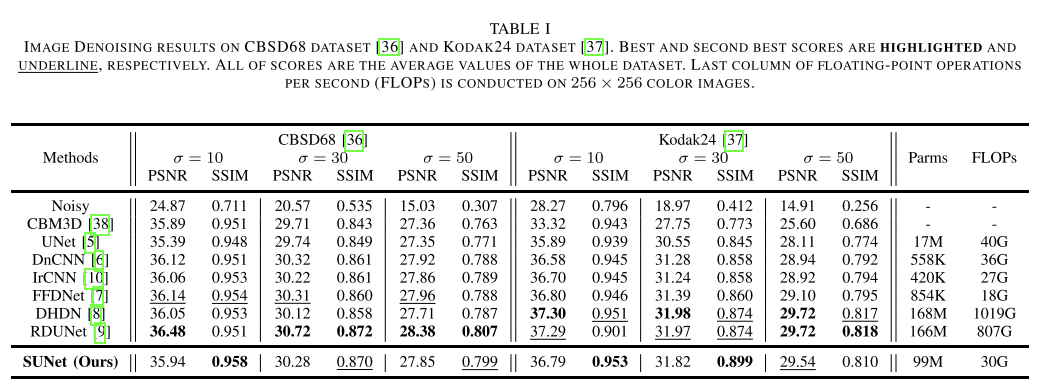
参数量:99M,计算量:30GFLOPs
优点:
1、结合了传统目标检测的方案,将yolox中的网络结构修改,通过将conv替换为STB,提出了新的网络结构SUNet,在图像处理-图像恢复去噪任务中获得了不错的效果。(本文实际结合的UNet)
2、使用双线性和亚像素上采样的双上采样模块避免了棋盘伪影问题。
如果图看不了,请查看:论文精读-SUNet Swin Transformer UNet for Image Denoising
概述
图像恢复是一个具有挑战性的病态问题,也是一个长期存在的问题。在过去的几年里,卷积神经网络(cnn)几乎统治了计算机视觉,并在包括图像恢复在内的不同层次的视觉任务中取得了相当大的成功。然而,最近基于Swin变压器的模型也显示出令人印象深刻的性能,甚至超过了基于cnn的方法,成为高级视觉任务的最先进方法。本文提出了一种以Swin Transformer层为基本块的复原模型SUNet,并将其应用于UNet结构中进行图像去噪。
背景介绍
图像恢复是一种重要的底层图像处理方法,它可以提高物体检测、图像分割和图像分类等高级视觉任务的性能。在一般的恢复任务中,损坏的图像Y可以表示为:
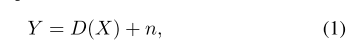
其中X为干净图像,D(.)表示退化函数,n表示加性噪声。一些常见的恢复任务是去噪、去模糊和去块。
传统的图像恢复方法通常是基于算法的,称为基于先验或基于模型的方法,如BM3D[1]、WNNM[2]用于去噪;反卷积[3],图像先验[4]用于去模糊。虽然大多数基于卷积神经网络(CNN)的方法都取得了[5]-[10]的优异性能,但朴素卷积层存在一些问题。首先,卷积核与图像是内容无关的。使用相同的卷积核来恢复不同的图像区域可能不是最好的解决方案[11],[12]。其次,因为卷积核可以看作是一个小补丁,其中获取的特征是局部信息,换句话说,当我们做远程依赖建模时,会丢失全局信息。虽然在一些论文中提出了克服自适应卷积[13]、[14]、非局部卷积[15]、全局平均池化[16]等缺陷的方法,但直到Swin Transformer的出现才有效地解决了这些问题。
最近,[11]提出了一种基于变压器的新型骨干—SwinTransformer,并在图像分类方面取得了令人瞩目的成绩。此外,在越来越多的计算机视觉任务中,包括图像分割[11]、[17]-[19]、目标检测[11]、绘制[20]、超分辨率[12]、[21]等,使用Swin Transformer作为主干已经超越了基于cnn的方法,达到了最先进的水平。在本文中,我们还将Swin Transformer作为我们的主干网,并将其集成到UNet体系结构SUNet中进行图像去噪。
相关工作
传统的图像恢复方法是基于图像先验或通常称为基于模型的方法的算法,如自相似[1]、[22]、备用编码[23]、[24]和总变异[25]。这些方法在病态问题上的性能都是可以接受的,但是它们存在一些缺点,比如耗时、计算量大、难以恢复复杂等。
与传统的恢复方法相比,基于学习的方法,特别是卷积神经网络(convolutional neural networks, cnn)以其优异的性能成为包括图像恢复在内的计算机视觉领域的主流。
UNet[5]是一种被广泛应用于图像处理领域的结构,它通过层次化的特征映射来获取丰富的多尺度上下文特征。此外,它使用编码器和解码器之间的跳过连接来增强图像的重建过程。
直接将transformer用于视觉任务的两个主要问题是:
1)图像和序列之间的尺度差异较大。变压器由于需要一维序列参数的平方倍左右,存在对长序列进行建模的缺陷。
2)Transformer不擅长解决密集的预测任务,如实例分割,这是一个逐像素级的任务[34]。然而,Swin变压器[11]通过移动窗口来减少参数,解决了上述问题,并在许多像素级视觉任务中达到了最先进的性能。
方法
网络结构
类似于yolox中的网络结构,包括上采样+下采样,只不过,因为在yolo 目标检测中有三个任务,1.偏移量 2.框尺寸 3.图像类型判断,所以有三个输出,需要三个head。


SUNet网络结构:
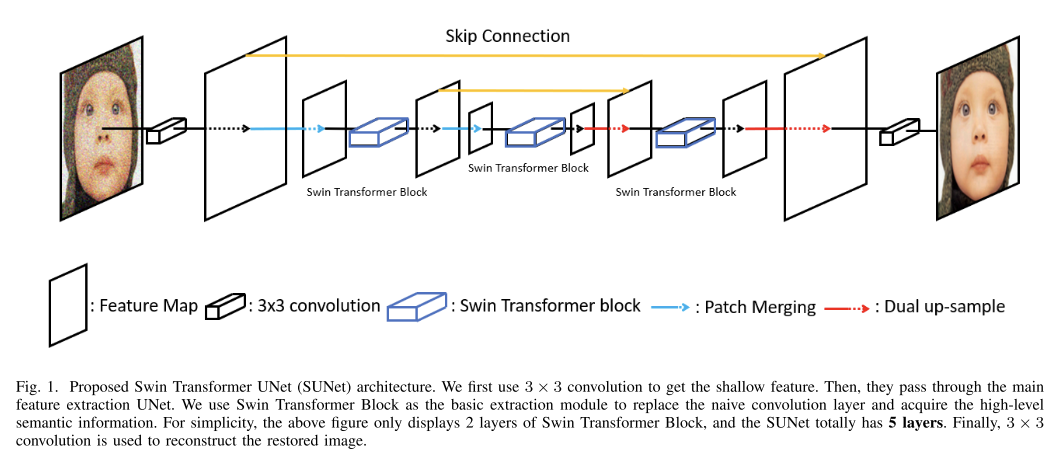
区别在于将原来的CNN替换为了Swin transformer block。SUNet使用的是5层STB(上+下采样,实际9层),每个STB使用2个STL层。
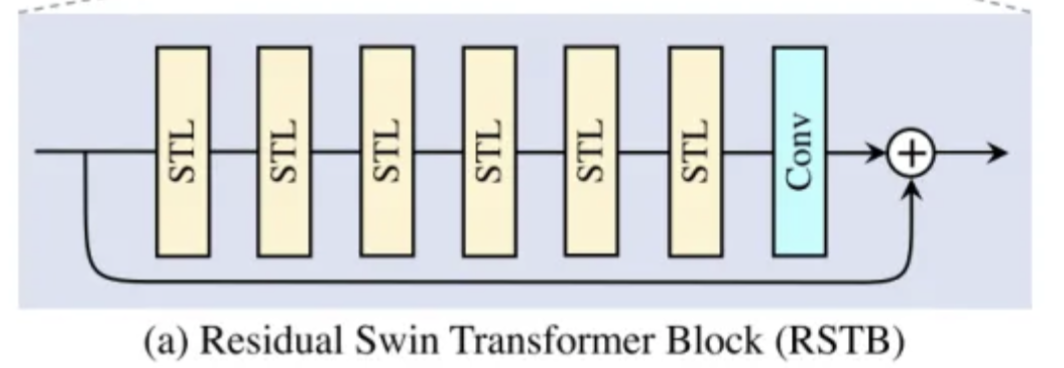
在后面工作中,出现了RSTB,它使用6个STL+一个CONV作为一个RSTB。(STL设置通常为偶数,其中一个用于窗口多头自注意(W-MSA),另一个用于移位窗口多头自注意(SW-MSA))
SUNet包括三个模块:1)浅层特征提取;2) UNet特征提取;3)重构模块。
浅特征提取模块。对于有噪声的输入图像Y∈RH×W×3,其中H, W是损坏图像的分辨率。我们使用单个3 ×3卷积层MSFE(.)来获取输入图像的颜色或纹理等低频信息。浅层特征Fshallow∈RH×W ×C可以表示为:
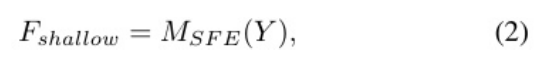
UNet特征提取模块。然后,将浅层特征Fshallow输入到UNet特征提取MUF E(.)中,提取高阶多尺度深层特征Fdeep∈RH×W ×C:
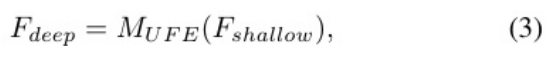
其中MUFE(.)是Swin变压器块的UNet架构,它在单个块中包含8个Swin变压器层来代替卷积。Swin变压器块(STB)和Swin变压器层(STL)将在下一小节中详细说明。重构模块。最后,我们仍然使用3 ×3卷积MR(.)从深度特征Fdeep生成无噪声图像Xˆ∈RH×W×3,其公式为:

需要注意的是,X´是将噪声图像Y作为SUNet的输入得到的,X是(1)中Y的图像的真值和干净版本。

损失函数:使用L1像素损失
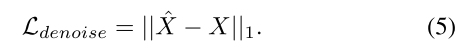
单STL计算流程:
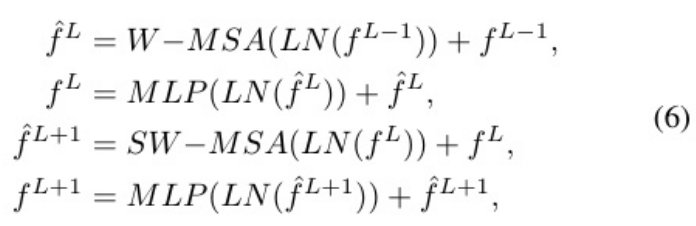
上采样:(双上采样+拼接)

1、对于双线性映射:将每组相邻两个patch输入特征拼接(H * W * C + H * W * C=>H * W * 2C=>bilinear layer=>2H * 2W * C/2)
2、对于像素混合:…(待补充) 2H * 2W * C/2
3、concat:通道拼接 2H * 2W * C
4、通道融合 2H * 2W * C/2
实验

QA
(待补充…)
卷积核与图像是内容无关的。使用相同的卷积核来恢复不同的图像区域可能不是最好的解决方案[11],[12]。其次,因为卷积核可以看作是一个小补丁,其中获取的特征是局部信息,换句话说,当我们做远程依赖建模时,会丢失全局信息。虽然在一些论文中提出了克服自适应卷积[13]、[14]、非局部卷积[15]、全局平均池化[16]等缺陷
的方法,但直到Swin Transformer的出现才有效地解决了这些问题。
亚像素和双线性上采样?
基于学习的方法在执行速度和性能上都击败了传统的基于模型的方法?自相似[1]、[22]、备用编码[23]、[24]和总变异[25]?基于学习,卷积神经网络???
UNet?
图像和序列之间的尺度差异较大。变压器由于需要一维序列参数的平方倍左右,存在对长序列进行建模的缺陷?
不擅长解决密集的预测任务,如实例分割,这是一个逐像素级的任务[34]。然而,Swin变压器[11]通过移动窗口来减少参数?
感受野与层之间关系的平移不变性、旋转不变性和大小不变性?循环移位技术,以减少计算时间并保持卷积的特征.
高斯误差线性单元(GELU)激活函数?
窗口多头自注意(W-MSA),另一个用于移位窗口多头自注意(SW-MSA)?
Bilinear和PixelShuffle?棋盘伪影?
转置卷积?
真实世界噪声和真实世界模糊?
PixelShuffle?怎么得到4倍通道的?
[Ref:Fan C M, Liu T J, Liu K H. SUNet: swin transformer UNet for image denoising[C]//2022 IEEE International Symposium on Circuits and Systems (ISCAS). IEEE, 2022: 2333-2337.]
















 394
394











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











