









很久没有看分割方面的文章了,今天看到一篇记录一下,CC-SAM:改进的 SAM 用于超声图像分割~
论文:CC-SAM: SAM with Cross-feature Attention and Context for Ultrasound Image Segmentation
海报:ECCV poster
代码:https://github.com/xianlin7/SAMUS(CC-SAM 的代码未公布,但 CC-SAM 基于 SAMUS)
0、摘要
SAM 在自然图像分割领域取得了显著的成功,但其在医学成像领域的应用遇到了挑战。具体而言,SAM 在处理低对比度、边界模糊、形态复杂和小尺寸物体的医学图像时存在困难。
为了解决这些挑战,并提高 SAM 在医疗领域的性能,本文引入了一个全面的改进:
首先,将一个冻结的卷积神经网络(CNN)分支作为图像编码器,通过一个新的变分注意融合模块与 SAM 的原始的 Vision Transformer(ViT)编码器协同使用。这种集成增强了模型捕获局部空间信息的能力,这在医学图像中通常是至关重要的。此外,为了进一步优化 SAM 在医学成像中的应用,在 ViT 分支中引入了特征和位置 adapters,以改进编码器的表示。
与目前用于超声图像分割的微调 SAM 的提示策略相比,使用文本描述作为 SAM 的文本提示有助于显著提高性能。利用 ChatGPT 的自然语言理解能力,本文生成提示,为 SAM 提供上下文信息和指导,使其能够更好地理解超声医学图像的细微差别,并提高其分割精度。该方法整体上代表了使通用图像分割模型在医学领域更具适应性和效率的重要一步。
1、引言
1.1、医学图像分割与 SAM
(1)目前医学图像分割模型多为专项任务设计,新任务需要重新校准模型;
(2)SAM 作为一种通用分割模型,通过点、框、粗分割掩码的 prompt,可以将几个离散的医学图像分割任务合并为一个整体模型;
1.2、目前 SAM 在医学任务中的局限
(1)尽管 SAM 拥有庞大的数据集(SA1B),但由于缺乏全面的临床标注,其在医学领域的性能有所下降;
(2)已有增强SAM在医学数据中的方法:调整 mask decoder、在 image encoder 中应用 LoRA 策略、通过 adapters 引入任务特定信息,这种标记化方法(tokenization)可能会掩盖重要的局部数据;(因为没有CNN结构么?)
(3)随后 SAMUS 的显著改进包括重新设计的 ViT 图像编码器、集成的并行 CNN 分支以及引入的跨分支注意力机制等;
1.3、本文贡献
本文介绍了 CC-SAM,这是一个基于 SAMUS 的新模型:
(1)CC-SAM:一种为通用医学图像分割定制的精细 foundation 模型,优化计算效率;
(2)引入了带有 adapters 的静态 CNN,补充了 SAMUS 的 ViT 编码器,并进一步降低了计算成本;
(3)变分注意融合的创新整合,增强了 CNN 和 ViT 分支特征之间的协同作用;
(4)使用来自 Chat-GPT 的基于文本的提示来阐明分割问题,这显著提高了医学环境中的分割性;
2、相关研究
2.1、医学图像分割
(1)医学图像分割历经从传统阈值分割、基于 Unet 分割以及基于 Transformer 分割的变迁;
(2)本文的方法合并了 CNN 和 Transformer,以同时利用局部和全局特征提取,创建了一个利用这两种范式优势的混合框架;
2.2、适配基础模型
(1)Adapter 模块用于在 Foundational models 中添加可学习层,以更少的开销增加了特定任务的能力,确保了有效的迁移学习;
(2)本文基于 Adapter 的想法,冻结 CNN 和 ViT 骨干,并且只使用 Adapter 对这两种模型进行有效的微调;
2.3、SAM适配医学图像
(1)已有将 SAM 适配于医学图像的研究:MedSAM 优化 mask decoder 进行有效的微调,SAMed 冻结了 image encoder,并在调整 prompt encoder 和 mask encoder 的同时采用了低秩的解码策略,MSA 在 ViT 图像编码器中使用 Adapter,SAMUS 集成了一个基于 CNN 的主干,以改进局部特征学习;
(2)基于 SAMUS,本文优化了它的框架。使用冻结的预训练 CNN 和 Adapter。本文发现使用文本提示,特别是使用 Grounding DINO,显著提高了 SAMUS 的性能。这种方法不仅更有效,而且速度更快。本文使用 GPT-4 从类标签中生成文本提示;
Figure 1 | 使用SAM进行医学图像分割的方法比较:
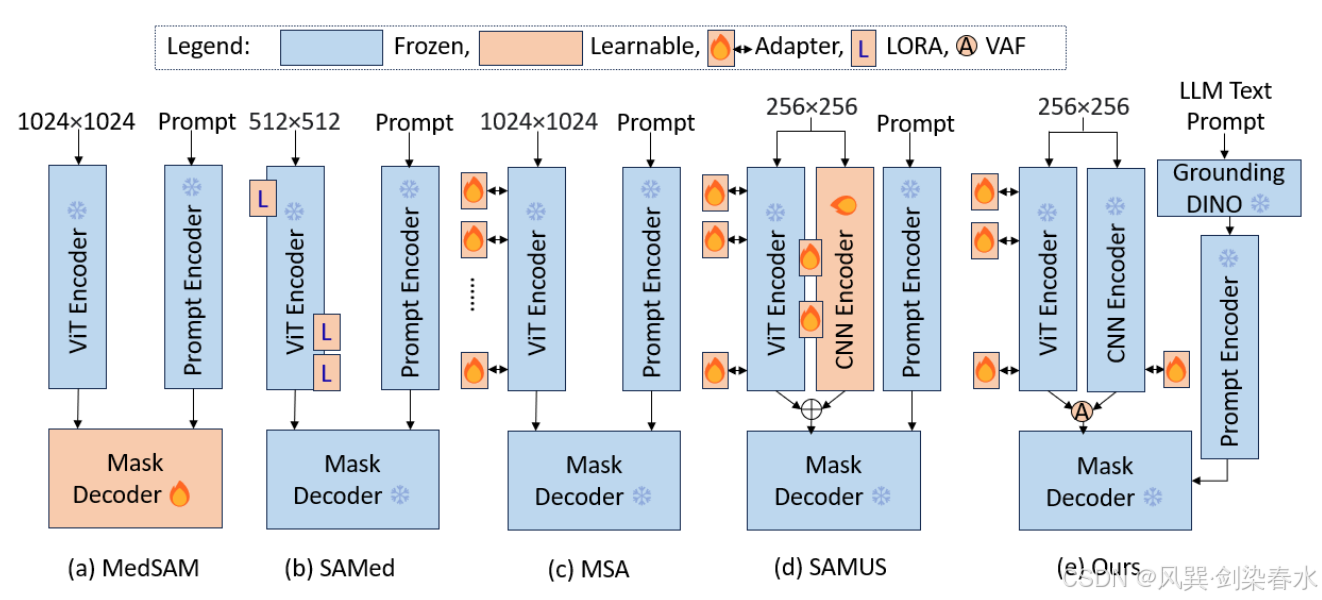
3、方法
本文使用 Adapter (在 CNN 的情况下使用全连接层)来增强超声分割的局部和全局特征。“OPaE” 指重叠的 patch 嵌入,“PE” 指位置嵌入。
Figure 2 | CC-SAM 的概述:
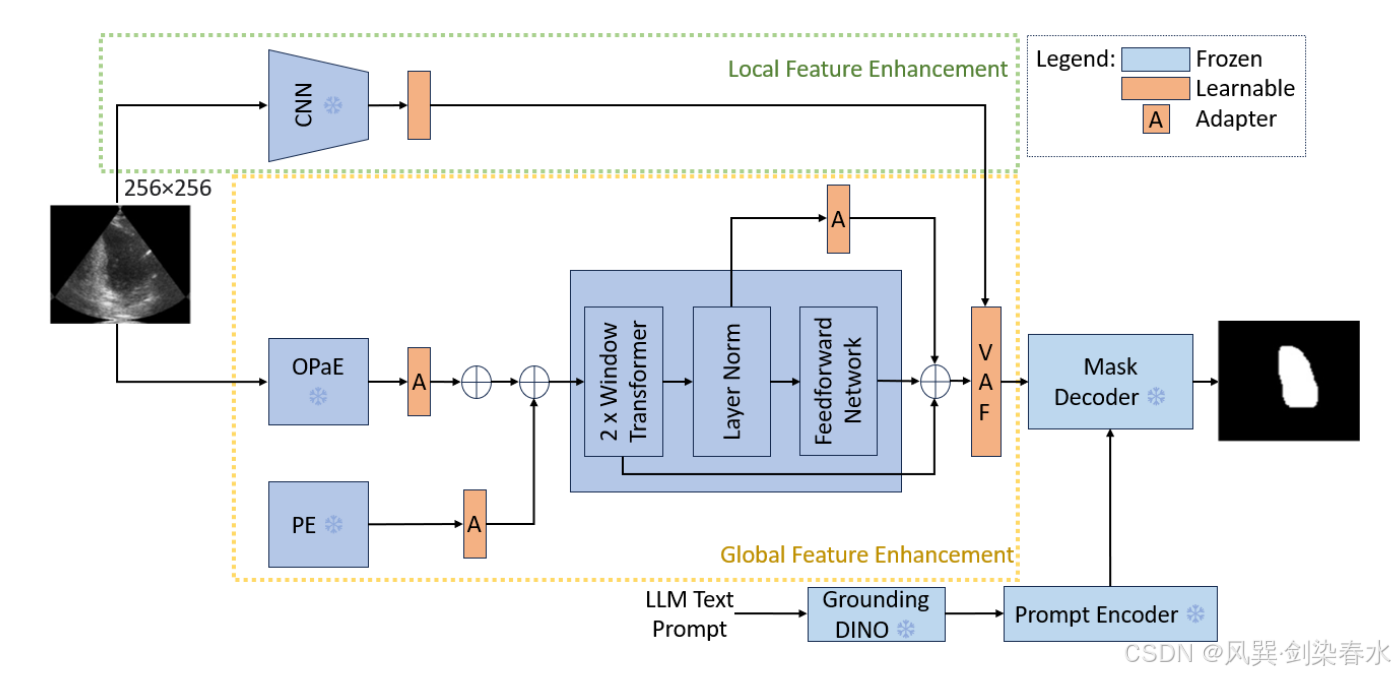
3.1、具有 Adapters 的冻结主干
本文增强了 SAM 的图像编码器(ViT分支),通过引入了一个位置 adapter 和五个特征 adapters,以更好地适应更小的输入和医疗图像。这些 adapters 可以用更少的参数有效地微调 ViT 分支。
位置 adapter:修改位置嵌入以匹配嵌入的序列分辨率,它首先使用最大池对这些嵌入进行降采样,然后通过卷积操作对它们进行细化,使ViT能够更好地管理更小的输入。
五个特征 adapters 都遵循一致的设计,即一个下采样线性投影、一个激活函数和一个上采样线性投影,在数学上可以表示为:
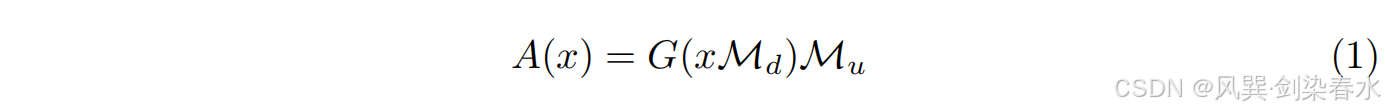
其中,
G
{G}
G 为 GELU 激活,
d
{d}
d 为特征嵌入维度,
M
d
∈
R
d
×
d
4
{M_d \in \mathbb{R}^{d×{ \frac {d}{4}}}}
Md∈Rd×4d 和
M
u
∈
R
d
×
d
4
{M_u \in \mathbb{R}^{d×{ \frac {d}{4}}}}
Mu∈Rd×4d 为投影矩阵。
与 SAMUS 的端到端 CNN 训练不同,本文使用一个静态的,RadImageNet 预训练的 ResNet-50 模型,在其分类层之前添加了一个可训练的全连接层,作为一个 adapter。来自这两个分支的输出特征被引入变分注意融合模块。
3.2、变分注意融合模块
本文一个主要贡献是变分注意融合模块,它巧妙地融合了局部 CNN 特征和全局 ViT 特征。虽然 SAMUS 引入了一个跨分支注意模块,但本文的方法,围绕这些特征建模不确定性并应用变分注意融合,优于 SAMUS。
Figure 3 | 所提出的变分注意力融合块的概述:每个“模式”都有一个模态内不确定性学习编码器(在图中表示为 E’ 或 E’'),这些编码器在潜在子空间中获得稳健的模态特定特征。随后,VAF 结合这些输入,并通过估计特定于每个模态的权重来构建多模态表示,有效地捕捉它们之间的依赖关系。

(1)不确定性学习(Uncertainty Learning)
结合不确定性学习,对于输入图像
I
{I}
I,从 ViT 获得特征
s
v
s^v
sv,从 ResNet-50 获得特征
s
c
s^c
sc。
s
v
s^v
sv 和
s
c
∈
R
d
h
s^c \in \mathbb{R}^{d^h}
sc∈Rdh 表示潜在空间中的一个固定维数。在每个网络的末端使用潜在编码器 Ev,Ec 来获得一致大小的输出。
为解决数据的不确定性,本文为每个样本的内容设计了一个潜在的分布,帮助捕获语义关系。这个分布呈参数化的对角高斯分布。这在数学上可以表示为:
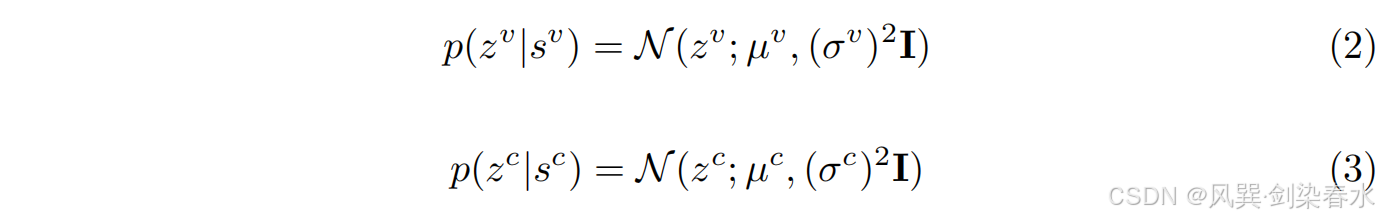
此处,
z
v
z^v
zv 和
z
c
z^c
zc 是重构向量。均值
μ
v
{\mu^v}
μv,
μ
c
{\mu^c}
μc 捕获了每个模式的核心特征,而方差
σ
v
{σ^v}
σv,
σ
c
{σ^c}
σc 表示在预测这些均值时存在噪声引起的不确定性。方差越大,意味着对观察到的内容的不确定性越大。这两个高斯参数都依赖于输入,并通过 MLP 进行预测。
例如,对于 ViT 特征:
μ
v
=
f
θ
v
1
(
s
v
)
{\mu^v = fθ_{v1}(sv)}
μv=fθv1(sv),
σ
v
=
f
θ
v
2
(
s
v
)
{σ^v = fθ_{v2}(sv)}
σv=fθv2(sv),其中
θ
v
1
{θ_{v1}}
θv1 和
θ
v
2
{θ_{v2}}
θv2 分别为模型参数。CNN 特征也是如此。现在,每个样本的特征表示从确定性转移到一个随机的高斯绘制的嵌入在潜在空间中。
由于采样的不可微性质,本文使用重新参数化技巧来维持梯度流。从独立于模型参数的正态分布中绘制随机噪声
η
η
η,并使用它产生
z
v
z^v
zv,如等式 4 所示。对
z
c
z^c
zc 进行同样的操作。
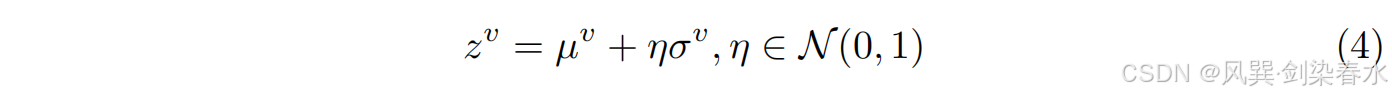
(2)变分注意融合(Variational Attentional Fusion)
CNN 和 ViT 从图像(局部和全局)中捕获不同的特征方面。本文认为这是两种模式:
v
v
v 表示 ViTs,
c
c
c 表示 CNNs。由于不同的置信水平,将它们组合起来并不简单。从数据中获得权重的标准方法,忽略了每种模式的独特特征。为了解决这个问题,本文开发了一个变分注意融合(VAF)模块。该模块旨在通过确定特定的权重来捕获模式之间的细微差别。
简言之,使用每个模式的特征,一个标准的注意方法创建一个概率
a
k
a^k
ak(其中
k
k
k 是
v
v
v 或
c
c
c ),如等式 5 所示。
a
k
a^k
ak 表示每种模式的贡献程度,
W
m
W_m
Wm 和
b
m
b_m
bm 是可训练的因素。通过设置权重,它可以选择正确的特征,而不受不同模式之间不同置信水平的影响。
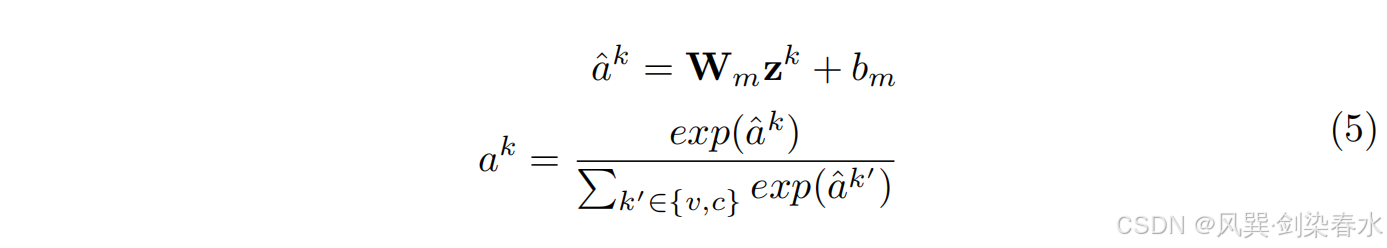
本文的 VAF 模块使用变分注意权值,而不是点估计的注意向量
a
^
k
\hat a^k
a^k。这种方法,基于一个概率分布(等式 6),更好地解释了不同模式之间的不确定性。
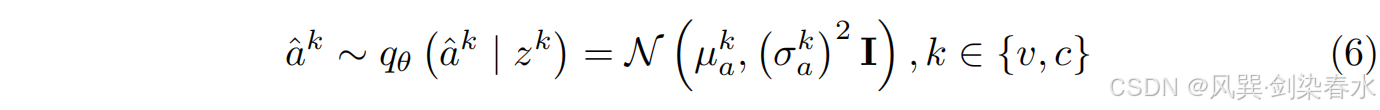
本文使用了一个变换来保持在变分注意中的模态特征。均值和方差参数由 MLPs 从输入中预测。
σ
a
k
σ_a^k
σak 的值表示不同模式之间的置信水平。使用 VAF 方法,增强了更自信的模态特征,而减少了更不自信的模态特征,优化了多模态数据融合并捕获了互补特征。最终的表示法结合了特定模态的输出,
z
v
z^v
zv 和
z
c
z^c
zc ,使用了如等式 7 所示的加权聚合,其中
W
h
{W_h}
Wh 是一个可学习的权重矩阵。
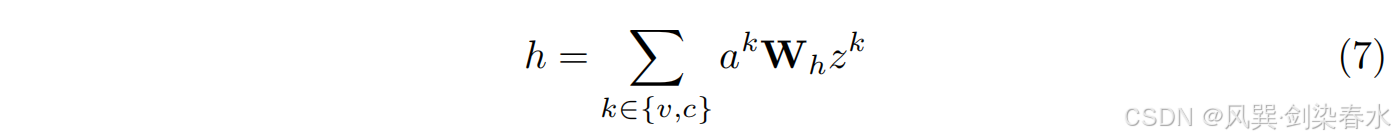
3.3、引导 prompt encoder
SAM 的 mask decoder 需要 h h h 和一个来自 prompt encoder 的输入。虽然过去 SAM 对医学成像的调整使用了 point prompts,但我们的结果显示,一个好的 bounding box 可以提高性能。创建此边界框需要一个专用的模型。使用随机的边界框可能会阻碍结果,因此需要有特定的提示。
本文使用 Grounding-DINO 来生成 bounding box,其虽不是专门用于医学图像,但是一种有效的目标检测器。本文使用 GPT-4 为特定的类标签编写文本提示,然后用 MedBERT 为 bounding box 生成一个嵌入输入。虽然与使用 point prompts 相比,这确实提高了我们的性能,但本文在补充中表明,使用相同的随机点提示集,本文亦优于所有其他医学基础模型(foundational models)。
3.4、损失函数
整体损失函数如下,这里,
L
B
C
E
{\mathcal L_{BCE}}
LBCE 和
L
D
{\mathcal L_D}
LD 分别是分割损失:binary cross entropy 和 dice loss。
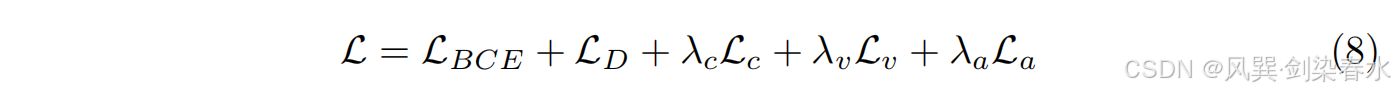
L
c
{\mathcal L_c}
Lc 和
L
v
{\mathcal L_v}
Lv 是不确定性学习的正则化术语,受变分信息 bottleneck 的启发。为了掌握模态中的不确定性,在学习过程中引入了一个成分。它确保了数据的分布,
N
(
z
v
;
μ
v
,
(
σ
v
)
2
)
{\mathcal N(z^v ; \mu^v ,(σ^v)^2)}
N(zv;μv,(σv)2),类似于一个标准的钟形曲线,
N
(
ϵ
;
0
,
I
)
{\mathcal N(ϵ; 0, I)}
N(ϵ;0,I)。这种相似性是通过在分布之间的 KL 散度(KLD)来衡量的,促进模型多样性和减少不确定性,从而产生鲁棒特征。等式 9 显示了如何计算
L
v
{\mathcal L_v}
Lv,
L
c
{\mathcal L_c}
Lc 和
L
a
{\mathcal L_a}
La 用类似的方法,用
z
c
z^c
zc 和
a
^
k
\hat a^k
a^k 替换
z
v
z^v
zv。
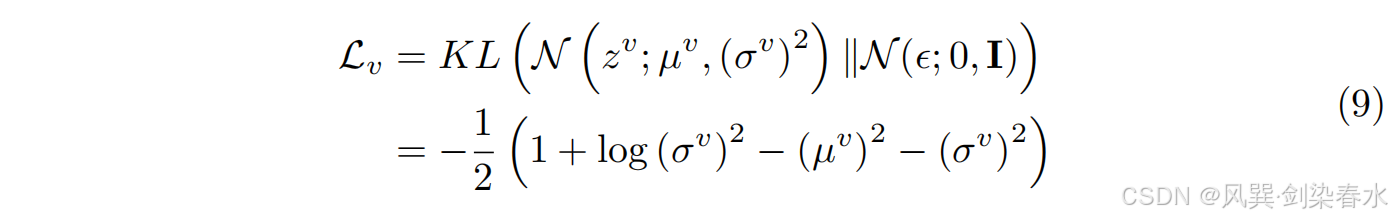
4、实验分析
4.1、数据集
(1)7 个公开数据集:TN3K,DDTI,TG3K,BUSI,UDIAT,CAMUS,HMC-QU,此外还从SAMUS中重建了 US30K 数据集,以进行更广泛的比较;
(2)TN3K 和 TG3K 数据集划分与 TRFE 分割相同,BUSI 按 7:1:2 随机划分,CAMUS 按挑战赛划分训练测试集,训练集后 10% 用于验证;
(3)为验证模型泛化性,US30K 不可见数据集(DDTI, UDIAT, HMC-QU)用于评估模型泛化性,通过对完整的 US30K 数据集进行训练,并跨不同的任务进行测试,将 CC-SAM 与其他基本模型进行了对比;
4.2、实施细节
(1)遵循 SAMUS 来设置超参数和 adapter 的大小;
(2)Adam 优化器,学习率 0.01,每 50 个 epoch 减少为原来的 0.1,共 200 个 epoch;
(3)所有全连接层具有 Leaky RELU 激活,dropout 概率为 0.5;
(4)1xA100 GPU 40GB,3090 Ti 24GB 也够用,batch size 为 32;
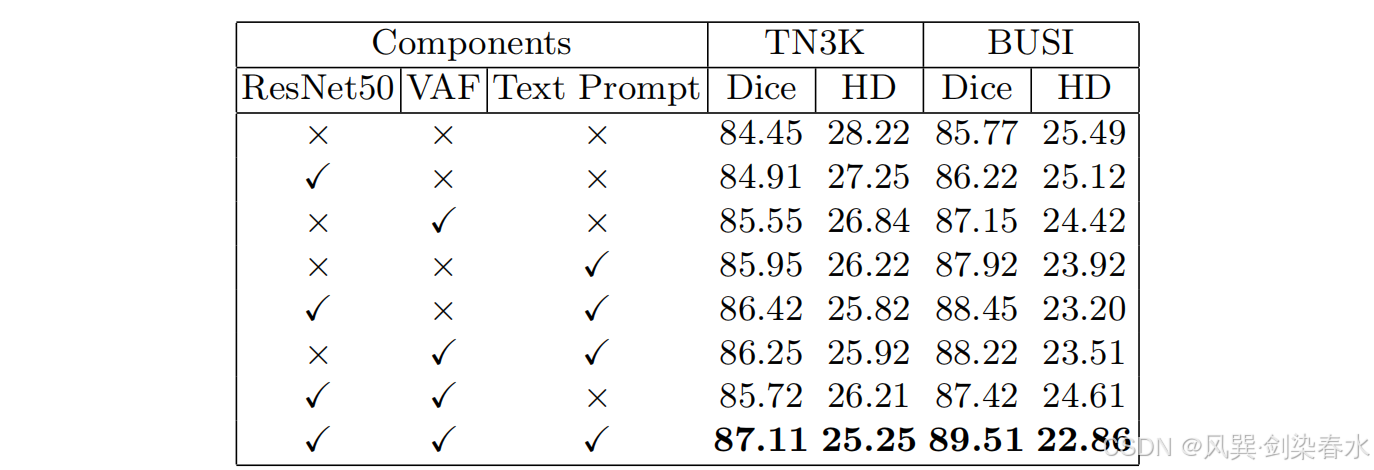
4.3、消融实验
Table 1 | 添加不同成分的消融研究:第一行对应于基线SAMUS
4.4、与最先进的比较
本文考虑了两种场景来与遵循 SAMUS 的最先进的模型进行比较。将 CC-SAM 与特定于任务的方法和基础模型(Foundational models)进行了比较。
(1)任务的特定方法:
Table 2 | CC-SAM 方法与 SOTA 任务特异性技术分割甲状腺结节(TN3K)、乳腺癌(BUSI)、左心室(LV)、心肌(MYO)和左心房(LA)的定量比较:使用 Dice 评分(%)和 Hausdorff 距离(HD)来评估其表现,表现最好的结果用粗体突出显示。
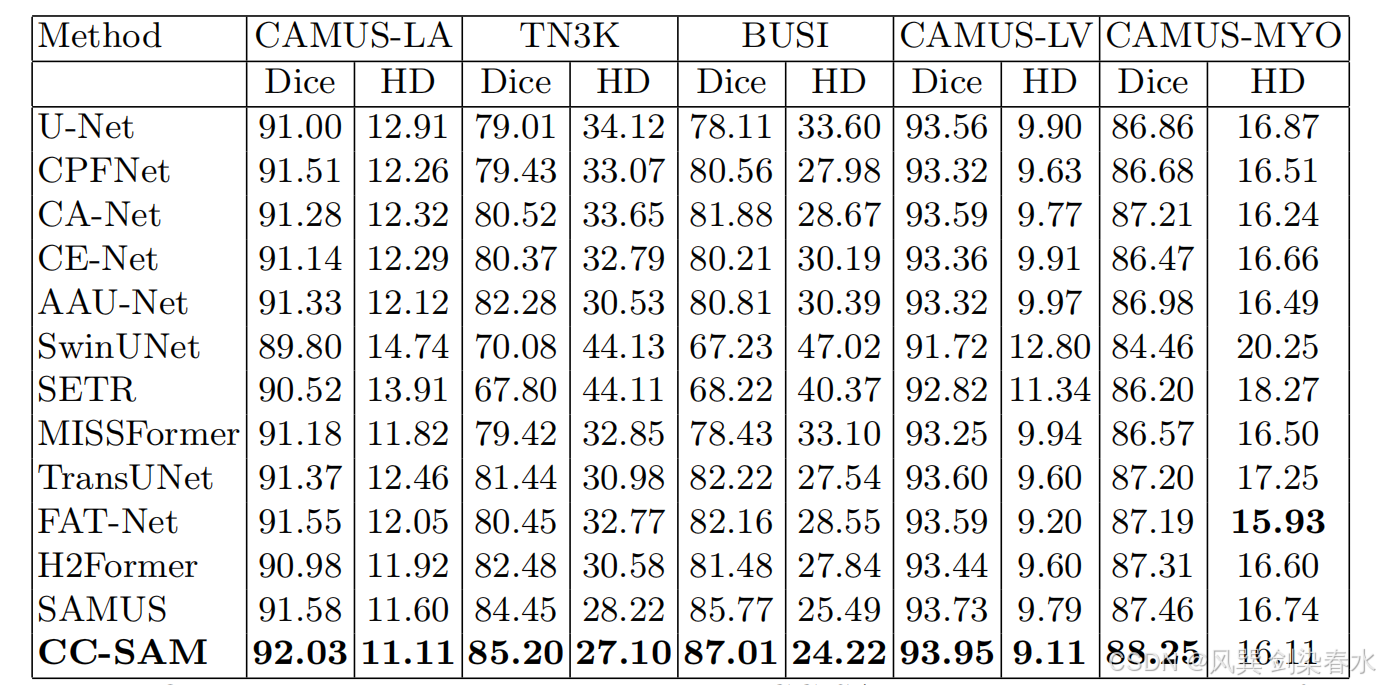
Figure 4 | CC-SAM 与 SOTA 任务特定技术之间的定性比较:
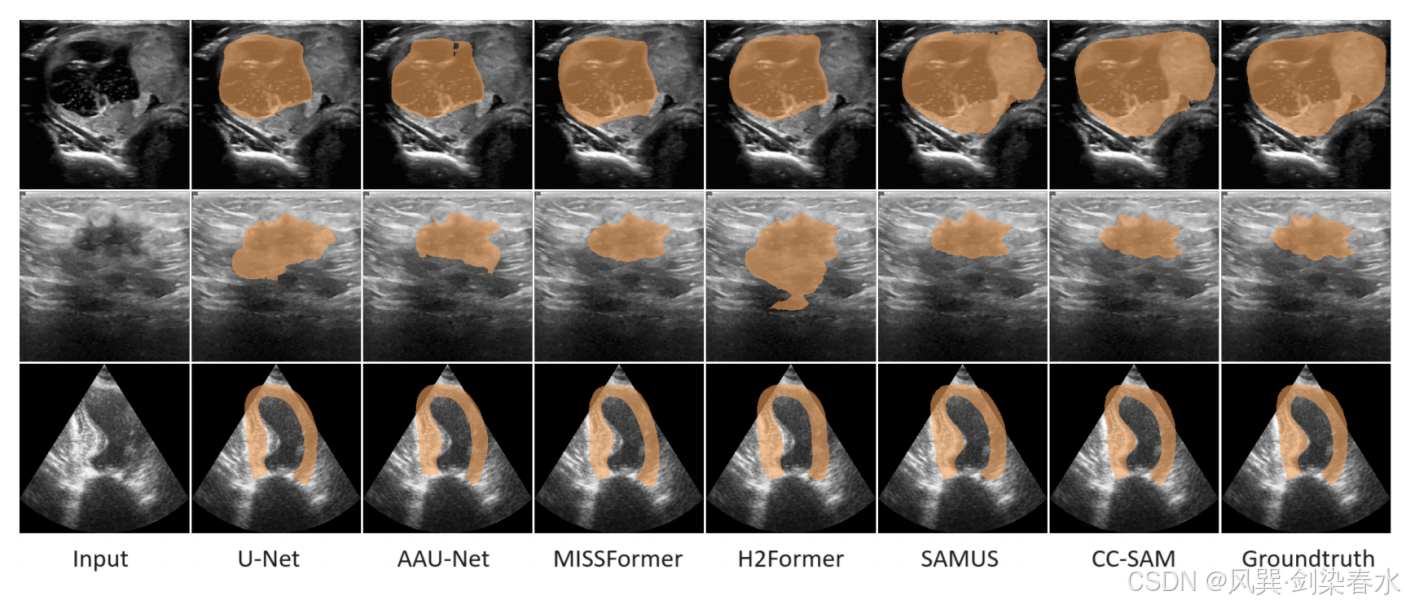
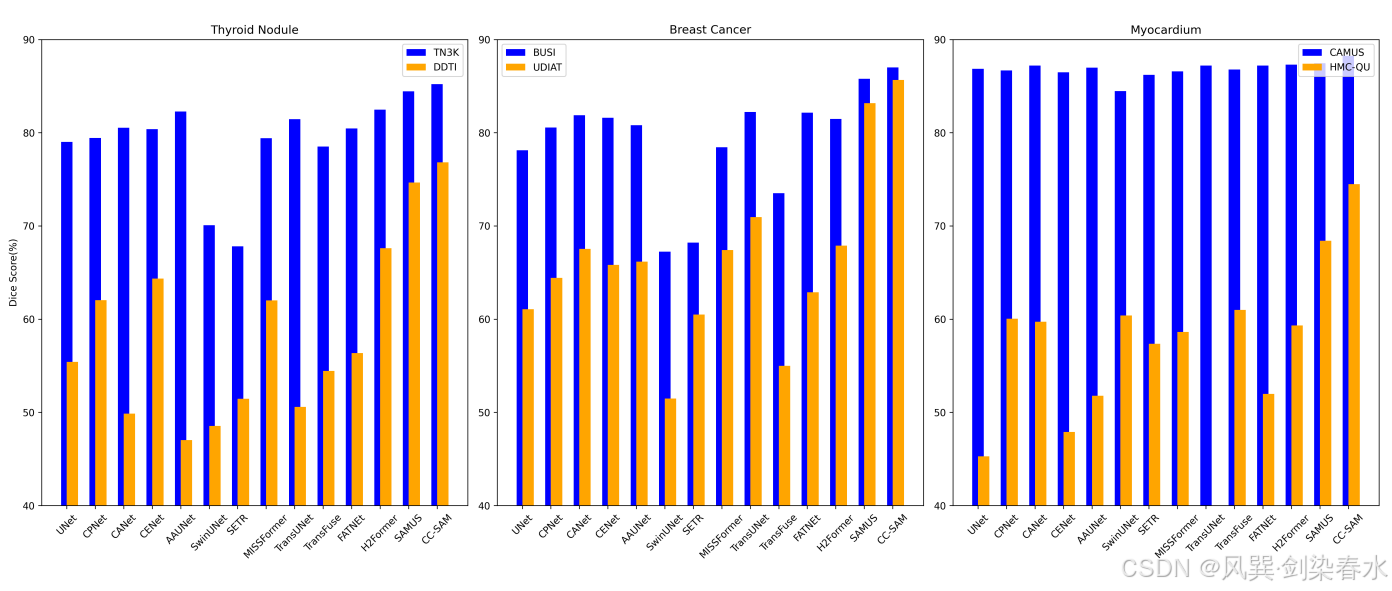
Figure 5 | CC-SAM 在可以看到的数据集(用蓝色高亮显示)和以前没有遇到过的未见数据集(用橙色表示)上与特定任务 SOTA 技术进行比较:橙色条越高,表示泛化能力越强。
(1)基础模型:
Table 3 | CC-SAM 和其他基础模型在可观察的 US30K 数据上的定量比较:
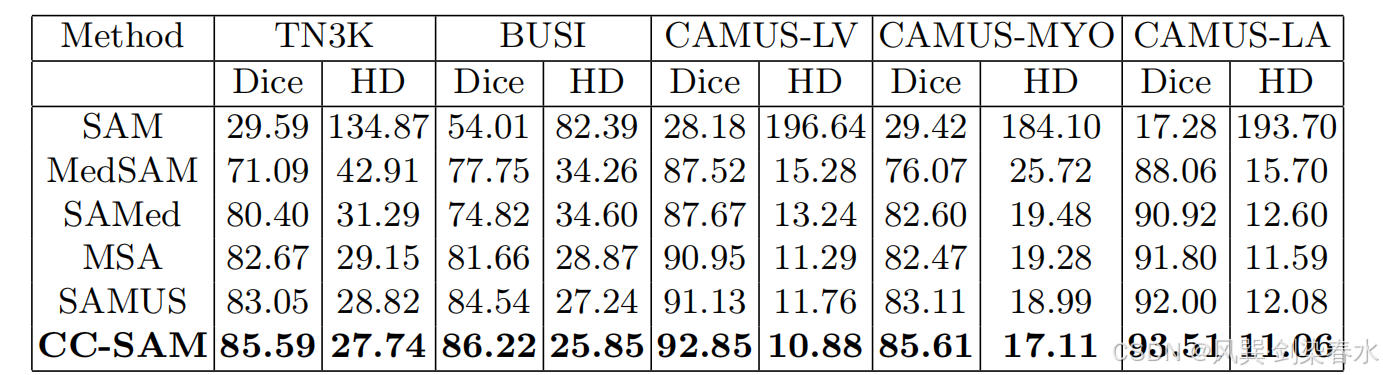
Figure 6 | CC-SAM 与 SOTA 基础医学分割模型之间的定性比较:
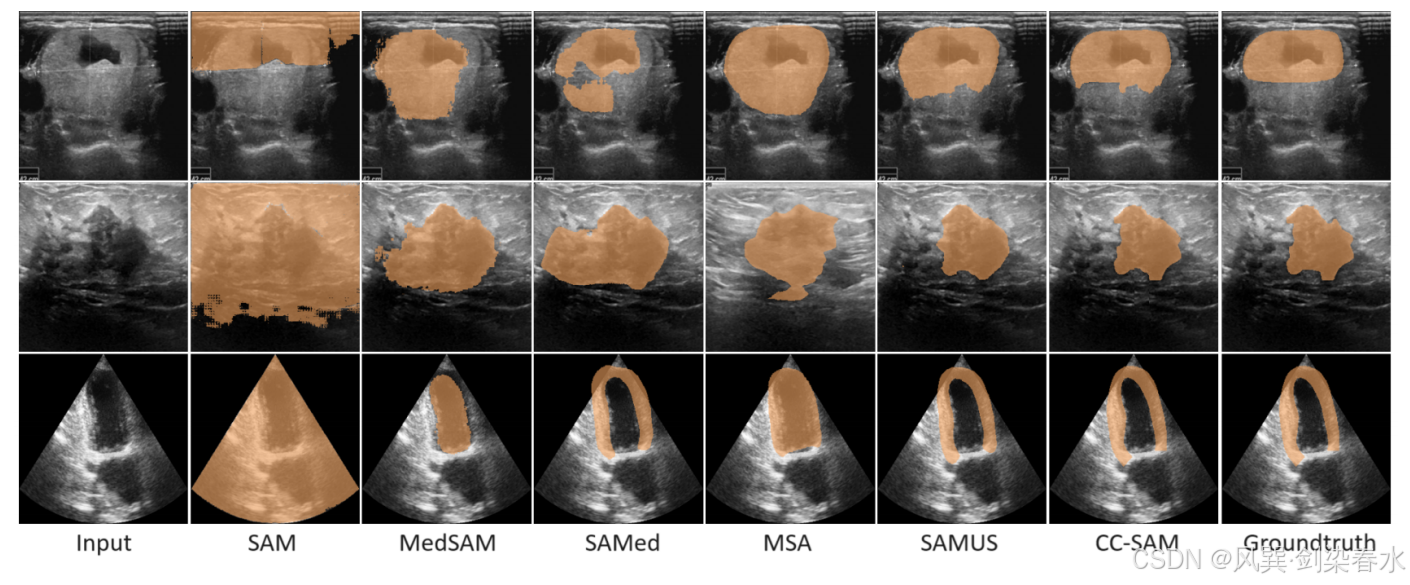
Figure 7 | CC-SAM 和其他基础模型的分割泛化能力比较:
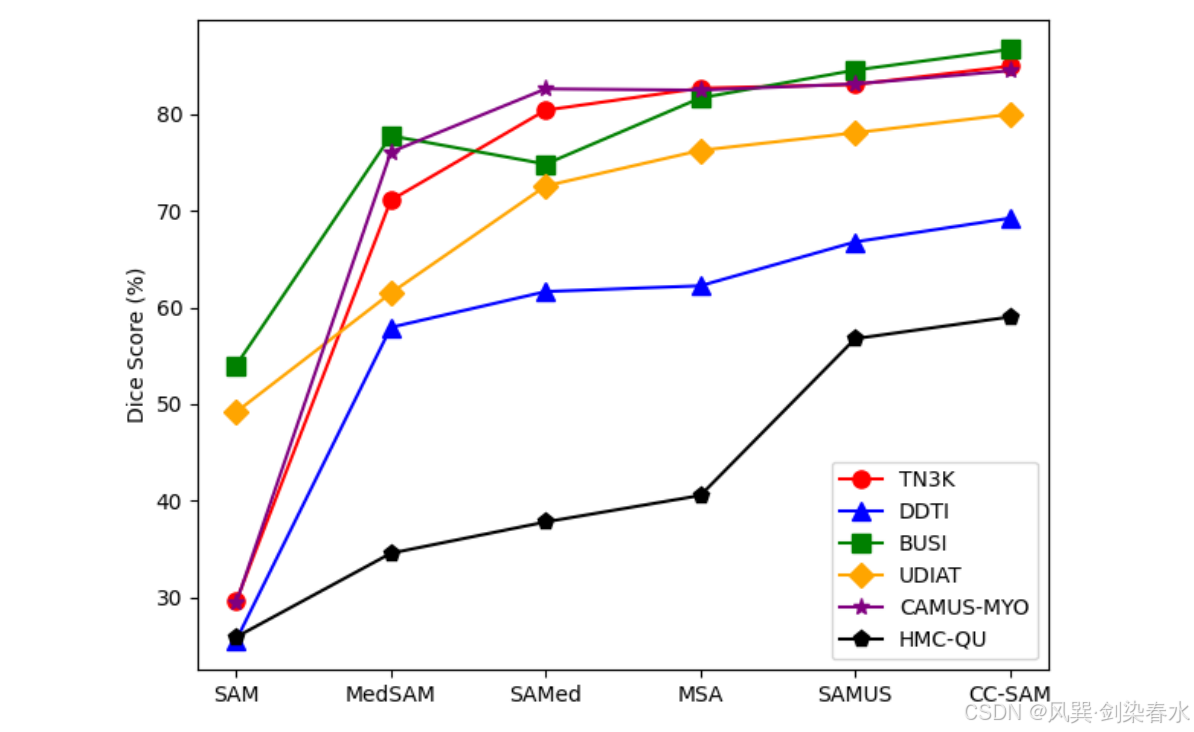
Figure 8 | 蜘蛛图,与所有基础模型比较效率和分割性能:
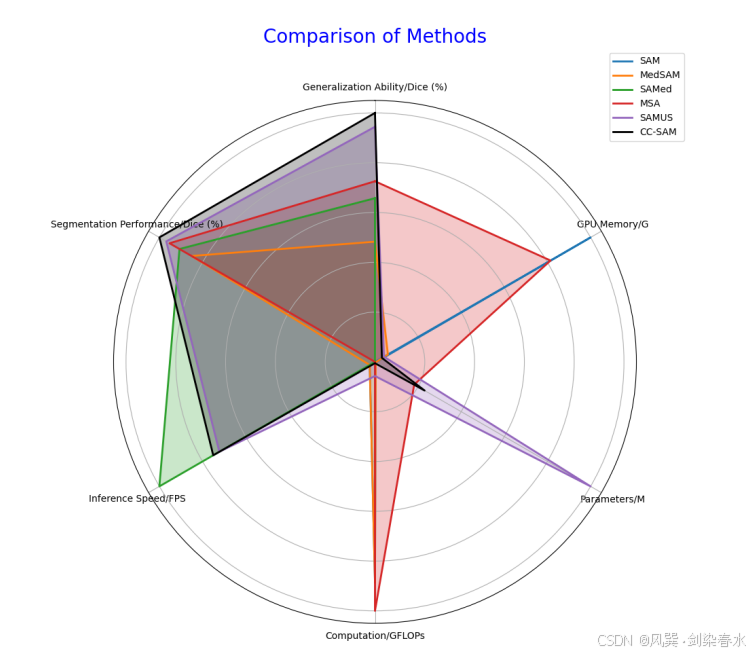
比较的还是太全面了~

















 556
556

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}