







论文标题
MPC: Multi-View Probabilistic Clustering
论文作者、链接
作者:
Liu, Junjie and Liu, Junlong and Yan, Shaotian and Jiang, Rongxin and Tian, Xiang and Gu, Boxuan and Chen, Yaowu and Shen, Chen and Huang, Jianqiang
Introduction逻辑(论文动机&现有工作存在的问题)
多视图聚类——多视图聚类所面临的一些问题:1)可能会缺失一些视图的数据2)K-means和谱聚类往往用于多视图聚类的最后一步——这些存在的问题对通用的特征质量以及相似度矩阵特别敏感,如果有噪音则会导致聚类性能的下降——并且K-means和谱聚类对于预设定的聚类数目非常依赖
论文核心创新点
提出了MPC框架,可以等价的将 多视图两两匹配的后验概率转换成 每个视图各自的分布
提出的图上下文感知graph-context-aware算法有效地缓解了噪声和异常值的影响
提出的快速聚类算法fast probabilistic clustering减小了计算复杂度
相关工作
多视图聚类
无监督聚类
论文方法
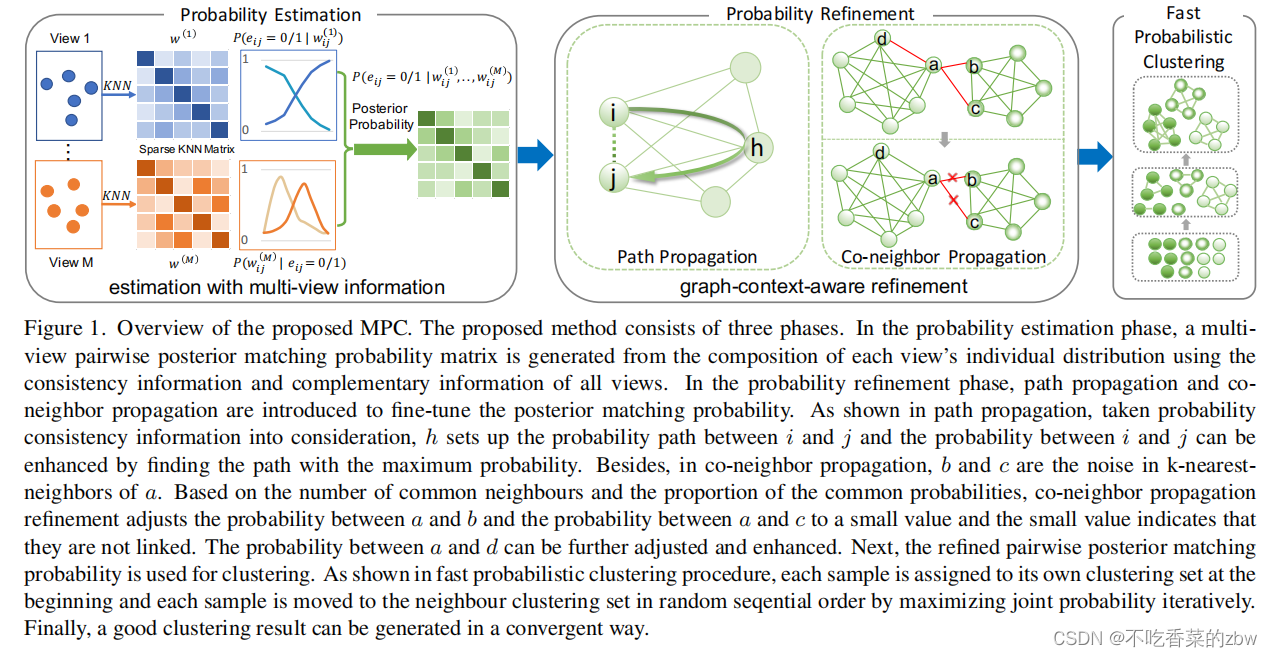
概率估计Probability Estimation
给定一个有个样本,每个样本有
个视图的数据集,记为
。
表示第
个视图的特征矩阵,其中
是第
个视图的特征维度。根据
通过余弦相似性计算出来的
来表示第
个视图的相似性矩阵。即使产生相似的聚类结果,不同视图的相似矩阵也可能不同。因此本文提出根据所有视图的相似性矩阵来评估逐对的后验相似性,而不是简单的将所有的相似性矩阵融合成一个单一的通用相似性矩阵。对于样本
和
的逐对后验相似性计算如下:
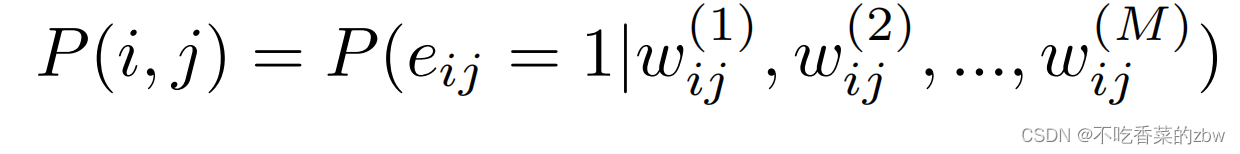
其中表示两个样本属于同一个类,
表示两个样本在第
个视图的相似性。
假设所有的视图都是有条件独立的,基于贝叶斯公式以及条件独立,上述公式可以解释为
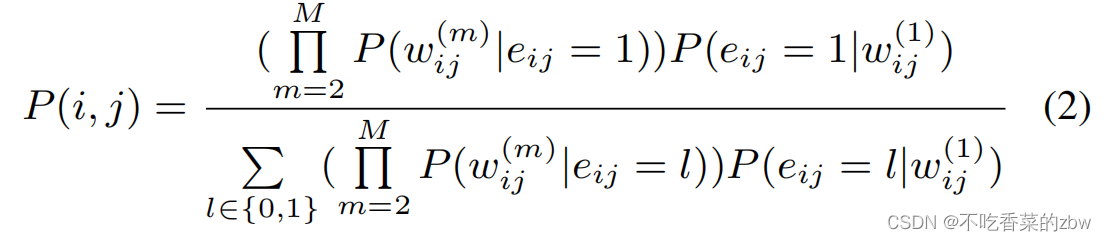
在公式2中,所有视图的相似性信息可以被考虑进这条公式中。这个公式的设计目的为:(1)可以独立的使用每一个视图的相似性信息,一个更大的或者
表示了一个更大的在第
个视图的逐对概率,并且可以反映在多视图的逐对概率中。(2)该公式可以融合所有视图的概率信息。当所有视图的相似性信息是一致的时候(在所有视图中大的
和
,或者是在所有视图中小的
和
)该公式可以反映一致性信息。当在一些视图中的相似性信息是模糊的时候,该公式能反映在其他视图中得到的互补信息。不同与学习一个权重参数将多个相似性矩阵融合的做法,公式2可以自适应的从多视图中评估后验匹配的概率。
为了评估 和
,我们通过聚类算法来生成每一个视图的伪标签,并且通过KNN来找到每一个样本的成对相关性。有很多算法可以生成伪标签,我们选择使用我们提出的聚类算法。对这些成对的数据打上0/1的伪标签,用来表示这两个样本是否属于同一个类。然后,我们使用简单的等渗回归和直方图统计去分别评估
和
,这个估计只用计算一次。每一个视图的所有观测到的数据都将用于计算,无论是完整视图还是缺失视图。我们的目标是完全利用每一个视图的信息,包括不完全视图中的独特的信息以及完全视图中的一致性信息。使用
和
的估计值生成的伪标签只要大概正确就可以,从以下三个方面可以将其丢弃。(1)因为公式2由每一个视图的独立分布组成,多视图的逐对后验概率不会被某一个特定的视图所影响,并且可以自适应的去放缩估计值来消除干扰,增强鲁棒性。(2)逐对的概率是用于我们提出的快速概率聚类算法,该算法可以在稠密概率中对于簇进行成功的分类。相应的,配对概率只需要能够粗略地表示配对关系即可。(3)概率精炼是用来进一步精调逐对的概率。给定所有视图的
和
,一个多视图的逐对后验匹配概率矩阵可以被生成并且用来去获得聚类结果。
图上下文注意力精炼Graph-context-aware Refinement
概率估计是基于样本关系计算的,忽略了图的上下文信息。因此,我们使用路径传播和共同邻居传播来进行图-上下文感知的细化。
路径传播Path Propagation
因为每一个视图存在数据扰动,于是数据集中存在一些异常值,这些异常值会影响聚类的性能。扰动的概率估计不能通过公式2计算,因此我们尝试使用路径传播对其进行精调。
收到信息传播的启发,结点之间的信息是可以传播的,于是提出路径传播(path propagation ,PP)传递样本之间的概率,形式如下
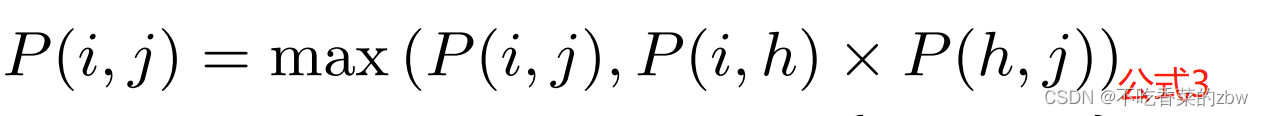
其中,,
,
,
,
并且
是样本
的第
个视图。在公式3中,样本
建立了样本
之间的路径,并且样本
之间的概率可以通过找到最大概率的路径从而进行增强。通过路径传播,在异常值和其邻居之间的概率一致性信息将会被纳入考虑,于是异常值会被检测到,可以提高异常值与其相邻值之间的成对概率。
共同邻居传播Co-neighbor Propagation
概率估计是在欧式空间中计算的,与此同时,视觉特征通常存在于低维流形中。仅仅使用欧式空间中的信息,会忽视图的信息,可能会导致样本之间的逐对的后验概率的不准确。为了利用图的信息,我们提出了共同邻居传播(co-neighbor prpagation,CP),公式如下:
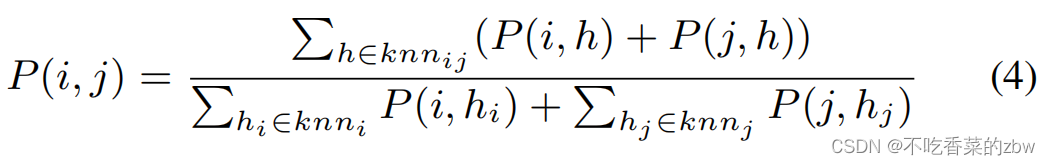
其中,是样本
的k近邻,由
和
计算得出。在这条公式中,局部的图是由两个样本的k近邻构成的。我们取得共同邻居的数目,考虑公共概率的比例,以进一步细化基于局部图的概率。公式4中所示,可获得的基于图的概率信息可以被尽可能挖掘出来。使用共同邻居传播,KNN中的噪音会被检测到,并且可以高效的增强异常值。
快速概率聚类Fast Probabilistic Clustering
快速聚类算法用于生成聚类结果。给定个样本,以及聚类集合
,快速聚类算法的优化目标为:
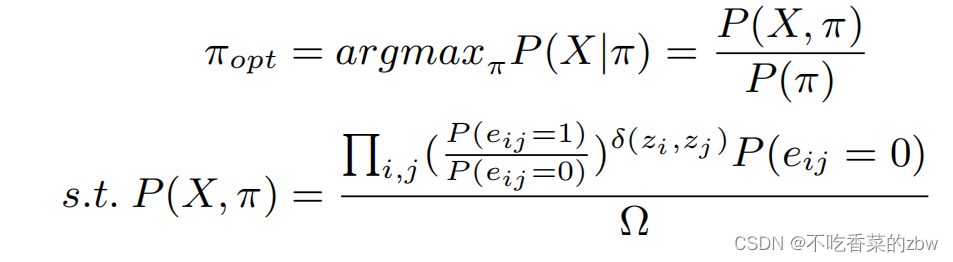
其中, 是克罗内克函数Kronecker function,
是正则化参数。有了以上定义,目标函数
可以被解释为:

其中是一个常量。只有类内的概率需要用公式6进行计算,这可以降低计算复杂度。
整个算法如下所示。

首先,使用精炼的多视图成对后验匹配概率来构建KNN。然后,每一个样本被分配到其自己的聚类集合中。最后,在随机的序列顺序中,每一个样本被移动到其邻居的聚类集合中,通过公式6来最小化目标函数值。这个移动过程会在每一个样本上重复直到没有移动步骤。该算法可以以一个可以收敛的方式来生成聚类结果。
在不完全多视图聚类中,我们先用上述的方法生成聚类结果。对于不完全样本,在拥有完整视图的样本上构造k近邻。使用共同邻居传播来精炼不完全样本及其邻居的匹配概率。最后,最大化不完全样本及其KNN在邻居聚类集合中的概率。此外,还存在所有不完整样本都有两个共同视图的情况,我们也可以利用完整的多视图聚类过程来产生聚类结果。
消融实验设计
概率估计方法的消融
精炼结构的消融
聚类方法的消融

















 1126
1126

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









