







All Points Matter: Entropy-Regularized Distribution Alignment for Weakly-supervised 3D Segmentation
摘要:
伪标签被广泛应用于弱监督三维分割任务中,在这种任务中,只有稀疏的地面真实标签可供学习使用。现有方法通常依赖经验标签选择策略(如置信度阈值法)来生成有益的伪标签,用于模型训练。然而,这种方法可能会妨碍对无标签数据点的全面利用。我们假设,这种选择性使用的原因是在未标记数据上生成的伪标签中存在噪声。伪标签中的噪声可能会导致伪标签与模型预测之间存在显著差异,从而混淆模型并对模型训练造成很大影响。为了解决这个问题,我们提出了一种新颖的学习策略,对生成的伪标签进行正则化处理,有效缩小伪标签与模型预测之间的差距。更具体地说,我们的方法为三维分割任务中的弱监督学习引入了熵正则化损失和分布对齐损失,从而形成了 ERDA 学习策略。有趣的是,通过使用 KL 距离来制定分布对齐损失,它可以简化为一种基于交叉熵的损失,从而同时优化伪标签生成网络和三维分割网络。尽管简单,但我们的方法有望提高性能。代码和模型将在 https://github.com/LiyaoTang/ERDA 上公开。
介绍:
在探索弱监督[85]的过程中,一个重要的挑战是高度稀疏的标签所提供的训练信号不足。为了解决这个问题,有人提出了伪标签方法 [85、94、32],利用对未标签点的预测作为标签,促进分割网络的学习。尽管取得了一些很有前景的结果,但这些伪标签方法的性能已被最近一些基于一致性正则化的方法[47, 87]所超越。我们倾向于将其归因于在伪标签上使用的标签选择,如置信度阈值法、这可能会导致未标记点被浪费和探索不足。我们假设,标签选择的必要性来自于分配给未标注点的低置信度伪标签,众所周知,伪标签具有噪声[21]和潜在的意外偏差[60, 100]。这些可靠性较低、噪声较大的伪标签可能会造成伪标签与模型预测之间的差异,从而在很大程度上混淆和阻碍学习过程。
针对上述弱监督三维分割中的标签选择问题,我们在本研究中提出了一种基于学习的新方法。我们的方法旨在利用所有未标记点的信息,减轻伪标签噪声和分布差异的负面影响。
具体来说,我们为伪标签生成过程引入了两个学习目标。首先,我们引入了熵正则化(ER)目标,以减少伪标签中的噪声和不确定性。这种正则化可以促进生成信息量更大、更可靠和更有信心的伪标签,从而有助于减轻噪声和不确定性伪标签的局限性。其次,我们提出了一种分布对齐(DA)损耗,它能使伪标签与模型预测之间的统计距离最小化。这可以确保在对伪标签的熵进行正则化时,生成的伪标签的分布仍然接近模型预测的分布。
特别是,我们发现使用 KL 距离计算分布对齐损失可以将我们的方法简化为交叉熵式学习目标,从而同时优化伪标签生成器和三维分割网络。这使得我们的方法易于实施和应用。通过整合熵正则化和分布对齐,我们实现了 ERDA 学习策略,如图 1 所示。

相关工作:
点云分割。点云语义分割旨在为三维点分配语义标签。最先进的方法基于深度学习,可分为基于投影的方法和基于点的方法。基于投影的方法将三维点投影到网格状结构,如二维图像 [84, 55, 39, 12, 4, 45] 或三维体素 [15, 71, 67, 28, 22, 23, 76]。另外,基于点的方法可直接对三维点进行操作 [56, 57]。最近的研究重点是增强点特征的新型模块和骨干,如三维卷积[3, 48, 78, 68, 51, 58]、注意力[34, 26, 97, 79, 42, 59]、基于图的方法[74, 44]以及其他模块,如采样[18, 86, 88, 7]和后处理[54, 35, 66]。虽然这些方法已经取得了重大进展,但它们依赖于大规模数据集的点式注释,在标签较少的情况下很难发挥作用[85]。为了满足点标注的苛刻要求,我们的工作探索了三维点云分割的弱监督学习。
弱监督点云分割。与弱监督二维图像分割[99, 49, 75, 1, 64]相比,弱监督三维点云分割的探索较少。一般来说,弱监督三维分割任务的重点是高度稀疏的标签:在大型点云场景中只有少数零散的点被标注。Xu 和 Lee [85] 首次提出使用少 10 倍的标签来实现与全监督点云分割模型相当的性能。后来的研究探索了更先进的方法,以利用不同形式的弱监督 [77, 14, 40] 和人类注释 [53, 69]。最近的方法倾向于引入扰动自馏分[95]、一致性正则化[85, 62, 80, 81, 43],并利用基于对比学习[29, 10]的自监督学习[62, 37, 47, 87]。伪标签是利用无标签数据的另一种方法,其方法包括在着色任务中预先训练网络[94],使用迭代训练[32],采用单独的网络在学习伪标签和训练三维分割网络之间进行迭代[53],或使用超级点图[44]与图注意模块在超级点上传播有限标签[13]。然而,这些现有方法往往需要昂贵的训练费用,因为需要手工制作三维数据增强[95, 87, 80, 81]、迭代训练[53, 32]或附加模块[87, 32],从而使骨干模型从完全监督学习到弱监督学习的适应性变得复杂。相比之下,我们的工作旨在通过直接的动机和简单的实现,为三维分割任务实现有效的弱监督学习。
伪标签细化。伪标签法[46]是熵最小化[24]的一种通用方法,已在各种任务中得到广泛研究,包括半监督二维分类[82, 60]、分割[64, 89]和领域适应[98, 73]。为了产生高质量的监督,人们提出了基于学习状态[72, 91, 20]、标签不确定性[60, 98, 73, 50]、类平衡[100]和数据增强[64, 89, 100]的各种标签选择策略。我们的方法与解决监督偏差的工作关系最为密切,在这些工作中,讨论了相互学习 [20, 70, 92] 和分布对齐 [100, 31, 41]。不过,这些研究通常侧重于类不平衡 [100, 31],并依赖于迭代训练 [70, 20, 92, 41]、标签选择 [20, 31]和强数据增强 [100, 31],而这些方法可能并不直接适用于三维点云。例如,常见的图像增强[64],如裁剪和调整大小,可能会转化为点云上采样[96],这仍然是相关研究领域的一个未决问题。我们认为,与其引入复杂的机制,不如使用一种专为弱监督三维点云分割任务设计的非常简洁的学习方法,对伪标签进行适当的正则化处理,并将其与模型预测相匹配,从而带来显著的优势。
此外,相互学习中的数据扩充和重复训练[70, 38]对于避免特征坍塌(即生成的伪标签与模型预测一致或相同)非常重要。我们怀疑原因可能来自于他们使用原始统计距离的经验结果中的熵项,这可能会使伪标签与噪声和混乱的模型预测相匹配,这将在第 3.2 节中讨论。此外,在基于聚类[5]和蒸馏[6]的自我监督学习中,也有研究表明,如果与具有高熵的接近均匀分布的聚类分配或教师输出相匹配,就会导致特征崩溃,这与我们的ER项的直觉是一致的。
模型方法:
Formulation of ERDA
如前所述,我们提出了 ERDA 方法来减轻生成的伪标签中的噪声,并减少它们与分割网络预测之间的分布差距。一般来说,我们的ERDA引入了两个损失函数,包括用于伪标签学习的熵正则化损失和分布对齐损失。我们将这两个损失函数分别记为 LER 和 LDA。那么,ERDA 的总体损失如下:
Lp = λLER + LDA
在详细介绍 LER 和 LDA 的公式之前,我们首先介绍一下术语。虽然损失是针对所有未标记点计算的,但为了便于讨论,我们只关注一个未标记点。我们用 p 表示分配给这个未标记点的伪标记,用 q 表示相应的分割网络预测。
熵正则化损失。我们假设伪标签的质量可能会受到噪声的影响,而噪声反过来又会影响模型学习。具体来说,我们认为当伪标签无法提供有把握的伪标签结果时,伪标签可能更容易受到噪声的影响,从而导致 p 中出现高熵分布。
为了缓解这一问题,我们建议通过最小化 p 的香农熵来降低其噪音水平,这也有助于获得信息量更大的标注结果 [61]。因此,我们有:
LER = H(p)
其中,H(p) = 求和 -pi log pi,i 在向量上迭代。通过最小化上述定义的伪标注熵,我们可以提高标注结果的可信度,帮助抵御标注过程中的噪声 。
分布对齐损失。除了伪标签中的噪声,我们认为伪标签与分割网络预测之间的显著差异也会混淆学习过程,导致不可靠的分割结果。一般来说,差异可能来自多个方面,包括噪声导致的伪标签不可靠、已标注数据和未标注数据之间的差异 [100],以及伪标签方法和分割方法的差异 [92,20]。虽然熵正则化可以减轻伪标签中噪声的影响,但伪标签与分割网络的预测之间仍可能存在显著差异。为了缓解这一问题,我们建议对伪标签和网络进行联合优化,以缩小这种差异,使生成的伪标签不会与分割预测相差太远。因此,我们引入了分布对齐损失。
为了正确定义分布对齐损失(LDA),我们测量了伪标签(p)与分割网络预测(q)之间的 KL 发散,并力求将该发散最小化。具体来说,我们对分布对齐损失的定义如下:
LDA = KL(p||q)
其中 KL(p||q) 指的是 KL 分歧。使用上述公式有几个好处。例如,KL 发散可以将整体损失 Lp 简化为一种具有欺骗性的简单形式,这种形式不仅具有理想的特性,而且比其他距离测量方法性能更好。下文将介绍更多细节。
简化的 ERDA。根据上述 LER 和 LDA 的计算公式,考虑到 KL(p||q) = H(p, q) - H(p) 其中 H(p, q) 是 p 和 q 之间的交叉熵,我们可以简化 ERDA 的计算公式:
Lp = H(p, q) + (λ − 1)H(p).
特别是,当 λ = 1 时,我们得到最终的 ERDA 损失:
Lp = H(p, q) = 求和 −pi log qi
上述简化的 ERDA 损失说明,熵正则化损失和分布对齐损失可以用单一的基于交叉熵的损失来表示,该损失可以同时优化 p 和 q。
我们要强调的是,公式 (5) 与传统的交叉熵损失不同。传统的交叉熵损失利用一个固定标签,只优化对数函数内的项,而公式 (5) 中提出的损失同时优化 p 和 q。
Delving into the Benefits of ERDA
除了 KL 发散外,还有其他距离测量方法,如用于替换的均方误差 (MSE) 或詹森-香农 (JS) 发散。虽然许多互学方法 [20, 92, 41, 38] 已经证明了 KL 发散的有效性,但目前文献中还缺乏 KL 发散与其他测量方法的详细比较。在本节中,在提出的 ERDA 学习框架下,我们通过比较表明 KL(p||q) 是更好的选择,而且 ER 对于弱监督三维分割是必要的。
为了研究不同距离测量(包括 KL(p||q)、KL(q||p)、JS(p||q)和 M SE(p||q))的特点,我们研究了 ERDA 损失 Lp 的形式及其在训练过程中两种情况下对伪标签生成网络学习的影响。
更正式地说,我们假设总共有 K 个类别,并定义伪标签 p = [p1, ..., pK] 基于置信度分数 s = [s1, ..., sK],且 p = softmax(s)。类似地,我们对同一个点也有一个分割网络预测 q = [q1, ..., qK ]。我们以各种形式重写 ERDA 损失 Lp,并从梯度更新的角度研究学习,如表 1 所示。

情况 1:给定可信伪标签 p 的梯度更新。我们首先专门研究了 p 非常确定且可信的情况,即 p 接近于one-hot向量。如表 1 所示然而,在这种情况下,KL(q||p),而不是我们方法中的 KL(p||q),会产生非零梯度,这实际上会在其学习过程中增加伪标签之间的噪声,这对我们的动机不利。
此外,我们还感兴趣的是,如果分割模型产生了令人困惑的输出,即 q 趋于一致,那么距离和 λ 的不同选择会如何影响伪标签的学习。与 ERDA 学习的动机一致,我们的目标是对伪标签进行正则化处理,以减少潜在的噪声和偏差,同时抑制信息量小的不确定标签。然而,如表 1 所示,大多数实现方法都会产生非零标签。1 中,大多数实现都会对伪标签生成网络进行非零梯度更新。这种更新会使 p 更接近混淆的 q,从而增加噪声并降低训练性能。相反,只有 KL(p||q) 与 λ = 1 的熵正则化整合时才会产生零梯度。此外,当 q 的噪声较小但仍接近于均匀向量时,表明 ERDA 的梯度面上有一个很大的近零高原,这有利于通过抵抗 q 中噪声的影响来学习 p。
除上述情况外,公式(5)中的ERDA梯度一般可被视为同时了解伪标签p和相应预测q的噪声水平和可信度。因此,我们的方案在实现同时降噪和分布对齐的动机方面显示出了其优越性,在这种情况下,LER 和基于 KL 的 LDA 都是必要的。我们将在补充资料中提供更多的消融实证研究(第 4.3 节)和详细分析。
Implementation Details on Pseudo-Labels
在我们的研究中,我们使用原型伪标签生成过程,因为它既流行又简单[94]。具体来说,原型 [63] 表示特征空间中的类中心点,伪标签是根据未标记点与类中心点之间的特征距离估算的。
如图 2 所示,我们使用了基于动量的原型伪标签生成过程,因为它既流行又简单[94, 85, 93]。具体来说,原型[63]表示特征空间中的类中心点,它是根据标记数据计算得出的,而伪标签则是根据未标记点与类中心点之间的特征距离估算得出的。为了避免昂贵的计算成本和每个语义类的折衷表示[94, 87, 47],动量更新被用作全局类中心点的近似值。

在动量更新原型的基础上,我们附加了一个基于 MLP 的投影网络,以帮助生成伪标签,并使用我们的方法进行学习。与我们的动机一致,我们没有引入基于阈值的标签选择或单次转换[46, 94]来处理生成的伪标签。更多详情请参见补充资料。
更正式地说,我们将点云 X 作为输入,其中有标签的点为 X l,无标签的点为 X u。对于有标签的点 x∈X l,我们用 y 表示其标签:

其中,Ck 表示第 k 个类别的全局类别中心点,N l k 是第 k 个类别的标记点数,g ◦ f = g(f (-)) 是通过骨干网络 f 和投影网络 g 进行的变换,m 是动量系数,我们使用余弦相似度 d(-, -) 来生成分数 s。默认情况下,投影网络 g 使用 2 层 MLP,并设置 m = 0.999。
此外,由于ERDA的简单性,我们可以按照基线的设置进行训练,这样就可以在各种骨干模型上直接实施和轻松适应,而开销很小。
总体目标最后,通过公式(5)中的 ERDA 学习,我们可以最大化有标签和无标签点、分割任务和伪标签生成的相同损失,其中我们允许梯度通过(伪)标签反向传播。最终损失为:
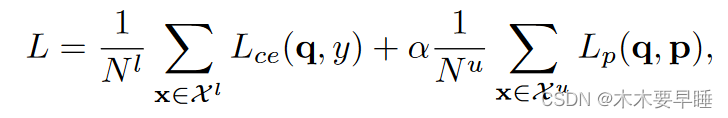

















 628
628

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











