










卷积神经网络CNN 实战案例 GoogleNet 实现手写数字识别 源码详解 深度学习 Pytorch笔记 B站刘二大人 (9.5/10)
在上一章已经完成了卷积神经网络的结构分析,并通过各个模块理解在pytorch框架下卷积神经网络各个模块的底层运行原理和数据传输细节
传送门指路:
【卷积神经网络CNN 数学原理分析与源码实现 深度学习 Pytorch笔记 B站刘二大人 (9/10)】
在本章中将通过pytorch模块复现经典深度学习模型GoogleNet,并使用minist数据集实现手写数字的识别
模型结构
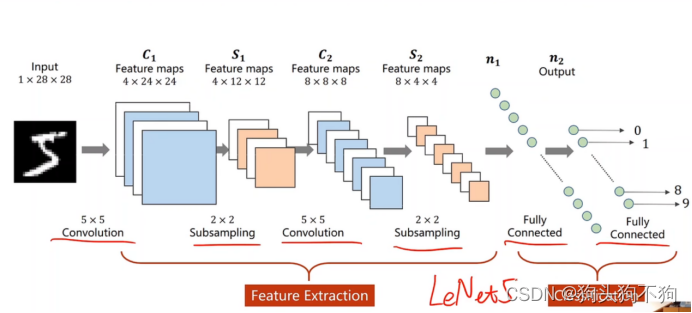
上图是经典模型LeNet5的结构图,显然网络结构仍然是顺序计算和传输,同时结构也仍然相对简单
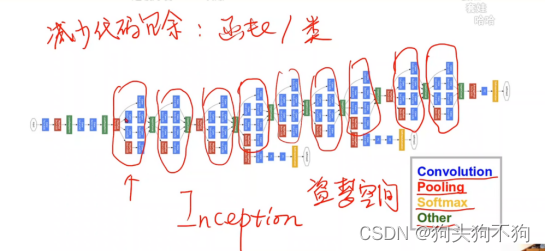
而GoogleNet的模型框架显然复杂的多,同时在内置的部分模块中出现了并行运算模块。
在面对这种情况时,通常构造类从而减少代码冗余,Googlenet inception(内嵌套,梦中梦),该逻辑与C++中类和函数的相互调用相似,通过提前构造结构类,在整体模型类中进行调用,能够较大的减少代码的重复编写。
此外,在实际实现中,很多超参数难以选择,例如卷积核大小kernel,Googlenet构造的出发点即是:不知道哪种kernel好用,提供多个kernel候选,通过训练找到最优卷积组合。
Concatenate,沿着通道数,将两个同类型的tensor进行连接,保证宽度和高度相同,因为在前文已经说过,输入数据Tensor的内参数(0,1,2,3)为(batch_size,channels,input_width,input_height),保证dim=0,2,3的参数相同可以让数据沿着channels的方向进行拼接,将多个tensor合并拼接成为一个,这也是inception模块的运算基础。
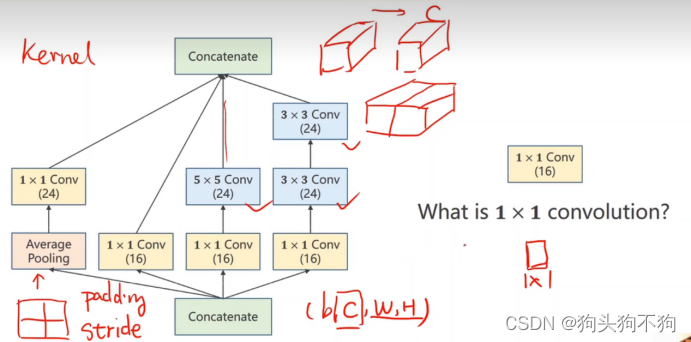
Convolution的个数取决于输入张量的通道
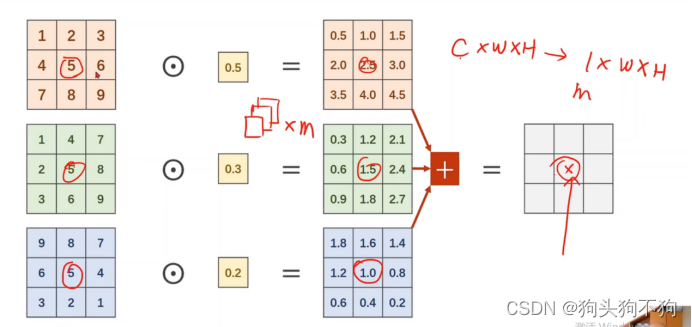
当三通道图像与三通道的单卷积核运算,最后得到1×w×h的feature maps,当有m×3组的卷积核,则得到m通道的feature maps。
显然该方法可以有效的降低运行数据的channel数,实现运算量的减少,并有效提取特征。至于各个channel的信息如何融合,最简单的方法是进行加权处理
下面,我们进行一下卷积过程的运算量计算,感受一下1×1卷积层的作用:
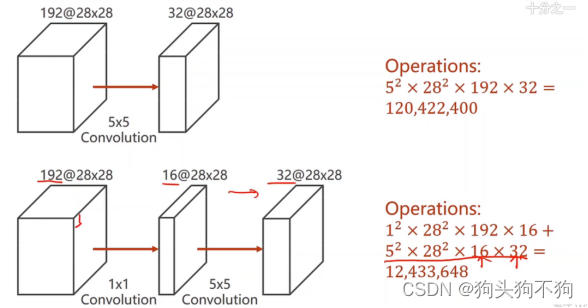
输入张量 192通道w28×h28 与5×5卷积核卷积,
总运算operation:5×5(单像素卷积)× 28×28(单层图像每个像素点卷积运算)×192(每个通道都进行卷积)×32(卷积核通道)=120,422,400 (120万运算)
改进:1×1的卷积核运算+5×5卷积,1×1卷积改变通道数量
总运算operation:1×1(第一层卷积的单个像素点卷积运算计算次数)28×28(第一层卷积的单层图像卷积运算)×192×(每个通道计算)×16(卷积核通道)+5×5(第二层单个像素点卷积运算计算次数)×28×28(第二层图像每个像素点卷积运算)×16(每个通道计算)×32(卷积核通道)=12,433, 648
显然,当通过1×1卷积核将通道数进行减少后,分为两次计算,可以大幅减少运算量
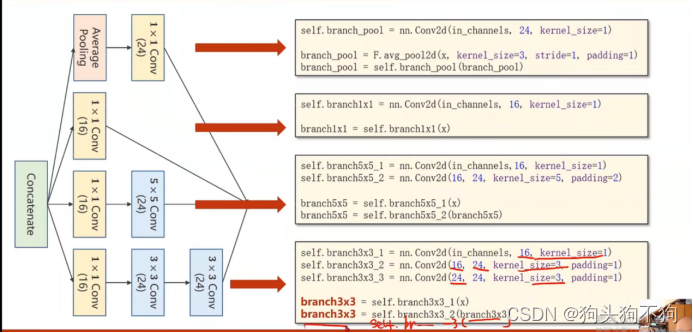
上图中1*1卷积核,用于降低通道数network in network
Pooling 参数,通道为1不改变输入输出通道量,padding=1在外界边界加扩展一层进行填充,同时使用kernel=3*3进行卷积,这样可以保证池化前后图像的通道和size的大小不变。
拼接运算:
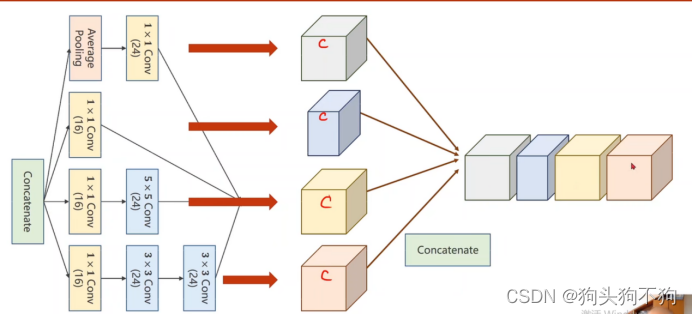
沿第一个维度进行拼接,tensor类型(batch 0,channel 1,width 2,height 3),沿1号参数的维度,及沿着通道数channel维度进行拼接
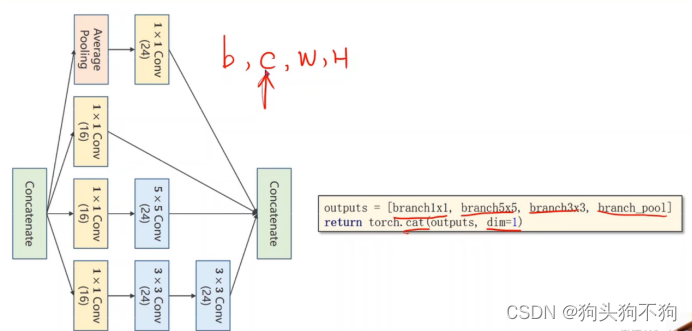
整体代码:
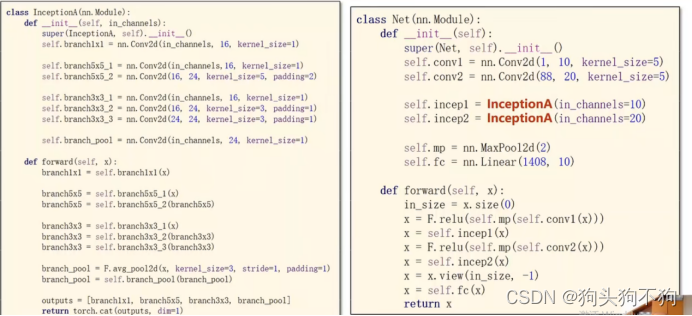
GoogleNet实例源码与详解
''' coding:utf-8 '''
"""
作者:shiyi
日期:年 09月 09日
通过pytorch模块实现Googlenet
"""
import torch
from torchvision import transforms
from torchvision import datasets
from torch.utils.data import DataLoader
import torch.nn.functional as F
import torch.optim as optim
# 参数设置
batch_size = 64
# 将数据类型转化为tensor
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.137, ), (0.3081, ))
])
# 构建训练集数据
train_dataset = datasets.MNIST(root='../dataset/minist/',
train=True,
download=True,
transform=transform)
train_loader = DataLoader(train_dataset,
shuffle=True,
batch_size=batch_size)
# 构建测试集数据
test_dataset = datasets.MNIST(root='../dataset/minist',
train=False,
download=True,
transform=transform)
test_loader = DataLoader(test_dataset,
shuffle=False,
batch_size=batch_size)
class InceptionA(torch.nn.Module):
def __init__(self, in_channels):
super(InceptionA, self).__init__()
# 构建第一卷积层分支
self.branch1x1 = torch.nn.Conv2d(in_channels, 16, kernel_size=1)
# 构建第二卷积层分支
self.branch5x5_1 = torch.nn.Conv2d(in_channels, 16, kernel_size=1)
self.branch5x5_2 = torch.nn.Conv2d(16, 24, kernel_size=5, padding=2)
# 构造第三卷积层分支
self.branch3x3_1 = torch.nn.Conv2d(in_channels, 16, kernel_size=1)
self.branch3x3_2 = torch.nn.Conv2d(16, 24, kernel_size=3, padding=1)
self.branch3x3_3 = torch.nn.Conv2d(24, 24, kernel_size=3, padding=1)
# 构造池化层分支
self.branch_pool = torch.nn.Conv2d(in_channels, 24, kernel_size=1)
def forward(self, x):
branch1x1 = self.branch1x1(x)
branch5x5 = self.branch5x5_1(x)
branch5x5 = self.branch5x5_2(branch5x5)
branch3x3 = self.branch3x3_1(x)
branch3x3 = self.branch3x3_2(branch3x3)
branch3x3 = self.branch3x3_3(branch3x3)
branch_pool = F.avg_pool2d(x, kernel_size=3, stride=1, padding=1)
branch_pool = self.branch_pool(branch_pool)
# debug
# print("brach1x1 shape ", branch1x1.shape,
# "branch5x5 shape ", branch5x5.shape,
# "branch3x3 shape ", branch3x3.shape,
# "branch_pool shape ", branch_pool.shape)
outputs = [branch1x1, branch5x5, branch3x3, branch_pool]
return torch.cat(outputs, dim=1) # 将返回值进行拼接,注意,dim=1意味着将数据沿channel方向进行拼接,要保证b,w,h的参数都相同
class Net(torch.nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = torch.nn.Conv2d(1, 10, kernel_size=5)
self.conv2 = torch.nn.Conv2d(88, 20, kernel_size=5)
self.incep1 = InceptionA(in_channels=10)
self.incep2 = InceptionA(in_channels=20)
self.mp = torch.nn.MaxPool2d(2)
self.fc = torch.nn.Linear(1408, 10)
def forward(self, x):
in_size = x.size(0)
x = F.relu(self.mp(self.conv1(x))) # 按照计算图构造前向函数结构1
x = self.incep1(x)
x = F.relu(self.mp(self.conv2(x))) # 按照计算图构造前向函数结构2
x = self.incep2(x)
x = x.view(in_size, -1)
x = self.fc(x)
return x
model = Net() # 实例化
criterion = torch.nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=0.01, momentum=0.5)
# 将训练移植到GUP上进行并行运算加速
device = torch.device("cuda:0" if torch.cuda.is_available() else "CPU") # 定义显卡设备0
model.to(device) # 将模型迁移搭配device0 及显卡0上
# 定义训练函数
def train(epoch):
running_loss = 0.0
for batch_idx, data in enumerate(train_loader, 0): # 将索引从1开始
inputs, target = data
inputs, target = inputs.to(device), target.to(device) # 将训练过程的数据也迁移至GPU上
optimizer.zero_grad()
# forward + backward + update
outputs = model(inputs)
loss = criterion(outputs, target)
loss.backward()
optimizer.step()
running_loss += loss.item()
if batch_idx % 300 == 299:
print('[%d, %5d] loss: %.3f' % (epoch+1, batch_idx+1, running_loss / 2000))
running_loss = 0.0
def test():
correct = 0
total = 0
with torch.no_grad():
for data in test_loader:
inputs, target = data
inputs, target = inputs.to(device), target.to(device) # 将测试过程的数据也迁移至GPU上
# print("input shape", input.shape)
outputs = model(inputs)
_, predicted = torch.max(outputs.data, dim=1)
total += target.size(0)
correct += (predicted == target).sum().item()
print('Accuracy on test set: %d %% [%d/%d]' % (100 * correct/total, correct, total))
if __name__ == '__main__':
for epoch in range(10):
train(epoch)
test()
题外拓展/梯度消失问题
基本上,深度学习模型的主流研究方向还是在不停的做加分,用一句话阐释就是:
We need to go deeper!!

但是很多时候我们也发现,并不是多构造卷积层就会获得更好的效果:
比如用3*3核不停累积构建更复杂的网络并不会导致模型效果更好,可能导致梯度丧失
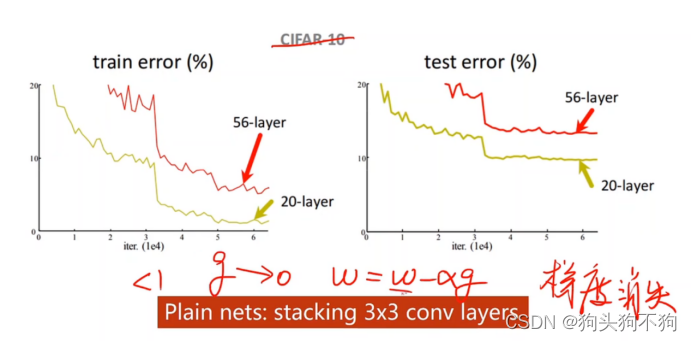
梯度小时解决方法:冻结训练,残差解决的其实是网络退化问题,BN是解决梯度消失的
Residual net:
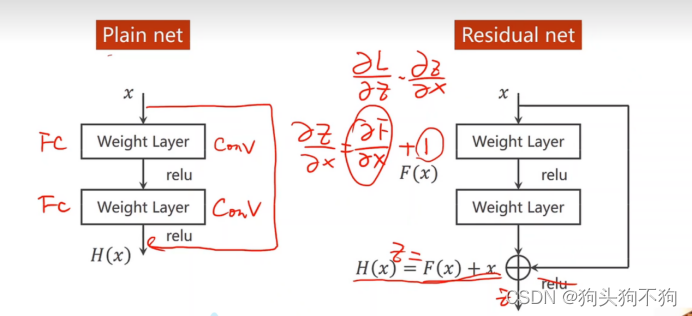
先相加再激活后,在进行梯度求解,在当梯度非常小,趋近于零的情况下将梯度趋近于1而不是趋近于零,保证了在梯度非常小的时候也不会趋近于0
Residual net/residual block
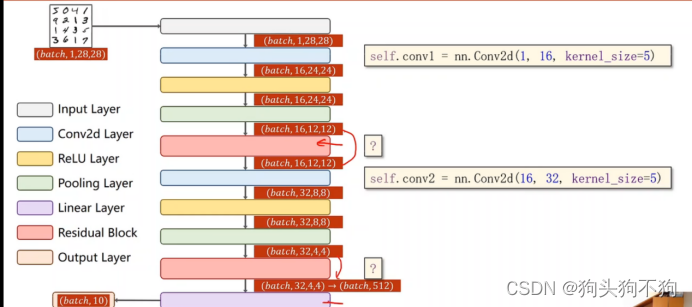
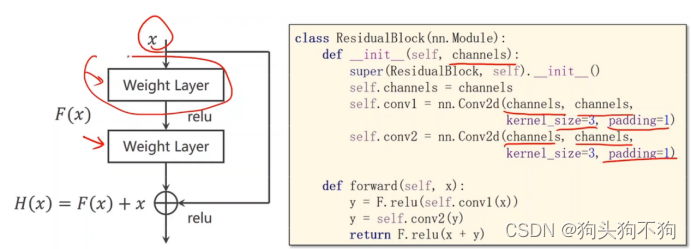

测试神经网络,逐步式的网络层数递增调试,验证网络层传递数据的张量是否于计划中的size相符
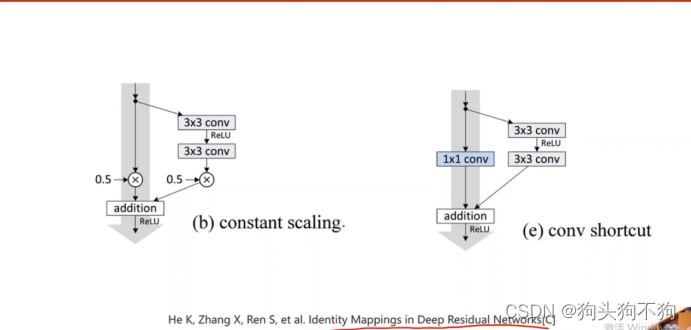
作业1
作业1:论文,其中有非常多的块的设计,实现集中不同的residual black ,minist测试查看效果
作业2

















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











