










Semi-Supervised Deep Regression with Uncertainty Consistency and Variational Model Ensembling via Bayesian Neural Networks
通过贝叶斯神经网络进行具有不确定性一致性和变分模型集成的半监督深度回归
Paper:https://ojs.aaai.org/index.php/AAAI/article/view/25890
Code:https://github.com/xmed-lab/UCVME
Abstract
深度回归是众多应用中的一个重要问题。这些范围从计算机视觉任务(例如根据照片估计年龄)到医疗任务(例如根据超声心动图估计射血分数以进行疾病跟踪)。然而,与分类和分割任务相比,深度回归的半监督方法尚未得到充分探索。与依赖阈值函数生成类伪标签的分类任务不同,回归任务直接使用实数目标预测作为伪标签,使得它们对预测质量更加敏感。
在这项工作中,我们提出了一种半监督回归的新方法,即不确定性一致变分模型集成(UCVME),它通过为异方差回归生成高质量的伪标签和不确定性估计来改进训练。
鉴于任意不确定性仅依赖于定义上的输入数据,并且对于相同的输入应该是相等的,我们为协同训练模型提出了一种新颖的不确定性一致性损失。我们的一致性损失显着改善了不确定性估计,并允许在异方差回归下为更高质量的伪标签分配更大的重要性。
此外,我们引入了一种新颖的变分模型集成方法来减少预测噪声并生成更稳健的伪标签。我们分析表明,我们的方法可以为未标记的数据生成更高质量的目标,并进一步改进训练。
实验表明,我们的方法在不同任务上优于最先进的替代方法,并且可以与使用完整标签的监督方法竞争。代码可在 https://github.com/xmed-lab/UCVME 获取。
1 Introduction
深度学习在分类(Dosovitskiy et al 2020)、分割(Chen et al 2021)、图像生成(Bodla、Hua 和 Chellappa 2018)等各种任务上取得了最先进的成果。然而,这些方法往往需要大量标记数据进行训练,而注释成本可能很高。例如,ViT 等最先进的图像分类器是在 JFT-300M 数据集上进行训练的,该数据集包含 3 亿张图像 (Dosovitskiy et al 2020)。对于医学图像分析来说,标记也可能非常昂贵,其中诸如医学疾病诊断 (Li et al 2021) 和肿瘤分割 (Li et al 2018a) 等挽救生命的任务需要领域专业知识。因此,训练具有减少标签的神经网络的能力非常有价值,也是一个活跃的研究领域。
半监督学习使用未标记数据和较小的标记数据集进行模型训练。这些方法减少了对标记数据的依赖,有时在完全标记的数据集上优于最先进的技术。Chen等人(Chen et al 2021)提出了CPS,一种用于图像分割的半监督算法,该算法标记起来很耗时。 Li 等人 (Li et al 2021) 强制执行医学诊断转换输入之间的一致性,这需要专业知识进行注释。然而,对深度回归问题的关注相对较少,这些问题涵盖了实际应用,例如根据图像进行年龄估计(Berg、Oskarsson 和 O’Connor 2021)和姿势估计(Yang 等人 2019)。深度回归在医学领域尤其重要,因为它用于获取疾病诊断和进展跟踪的测量值,例如骨质疏松症的骨矿物质密度估计(Hsieh et al 2021)和心肌病的射血分数估计(Ouyang et al 2020)。
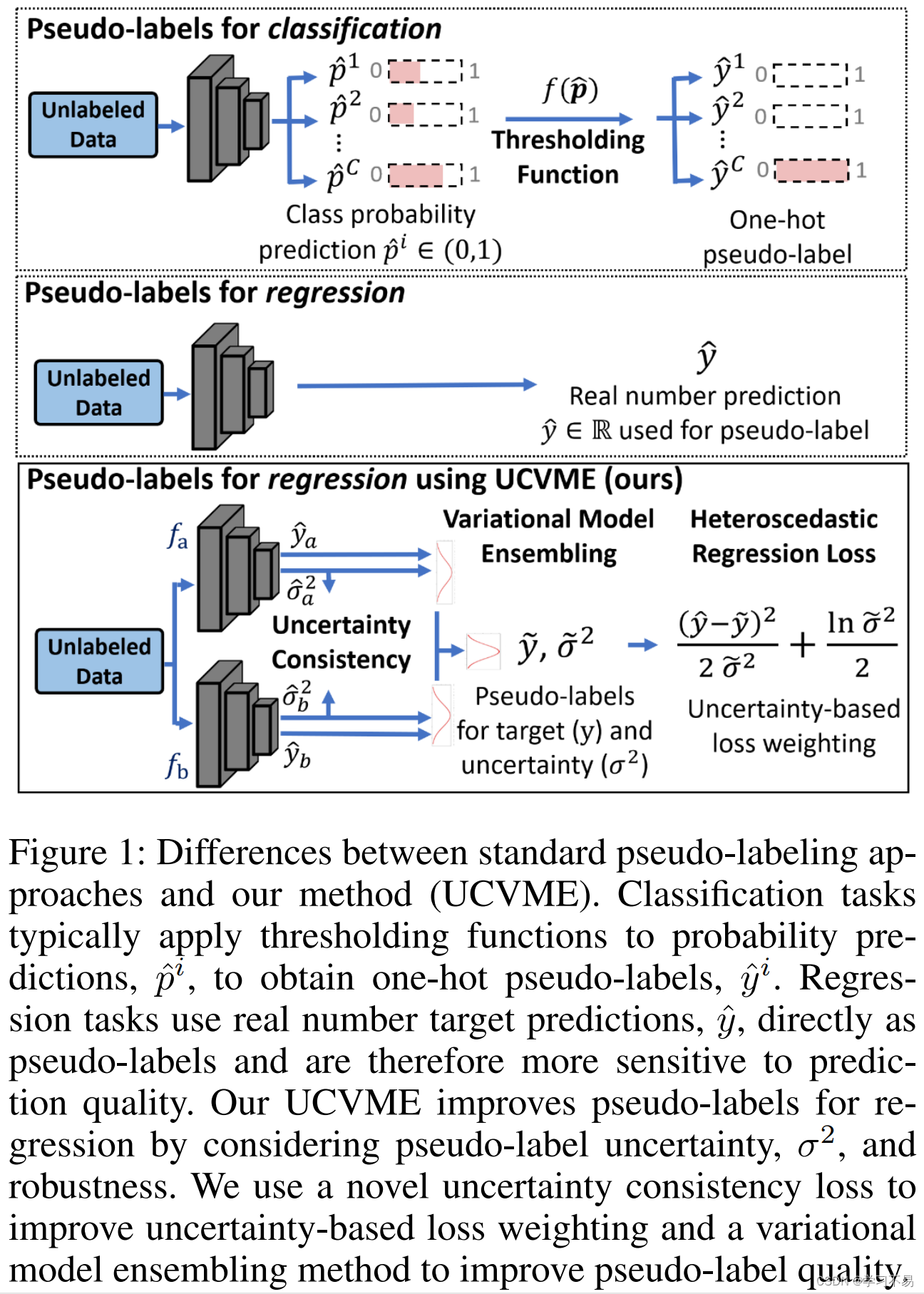
回归问题与分类问题有根本的不同,因为它们生成实数预测而不是类别概率。现有的半监督分类技术不能应用于半监督回归,因为它们依赖于类概率和阈值函数来生成伪标签(Zhang et al 2021;Sohn et al 2020)(见图1)。探索半监督深度回归方法的努力有限。 Jean 等人的最新作品(Jean、Xie 和 Ermon 2018)提出了用于半监督回归的深度核学习,但他们的方法是针对表格数据设计的。预训练的特征提取器用于图像输入,这会阻止特定于任务的特征学习并限制性能。 Wetzel 等人(Wetzel、Melko 和 Tamblyn 2021)提出了 TNNR,它估计深度网络输入之间的差异,并对未标记数据使用循环一致性。循环一致性调节训练,但低质量的预测仍然会降低约束的有效性(参见表 1 和表 4)。
与分类任务可以使用阈值函数进行类伪标签平滑预测不同,回归任务直接使用实数目标预测作为伪标签。 因此,模型性能很大程度上取决于伪标签(即预测)的质量。在本文中,我们提出了一种新颖的不确定性一致变分模型集成方法,即 UCVME,它可以在训练过程中调整伪标签的不确定性并提高伪标签的鲁棒性。我们的方法基于两个关键思想:强制共同训练模型之间的不确定性一致性以改进基于不确定性的损失权重,以及使用集成技术来减少预测方差以获得更高质量的伪标签。
我们利用贝叶斯神经网络(BNN),它可以与目标值一起预测观测值的任意不确定性。不确定性估计用于异方差回归,它根据不确定性分配样本权重,以减少噪声样本的影响(Kendall 和 Gal 2017)。我们观察到,任意不确定性(根据定义仅依赖于输入数据)对于相同的输入应该是相等的,并为联合训练模型的不确定性预测提出了一种新颖的一致性损失。 我们提出的损失显着改善了对未标记数据的任意不确定性估计,从而通过异方差回归赋予更高质量的伪标签更大的重要性(见图 5)。这并非易事,因为不可靠的不确定性估计可能导致不利的损失权重和不稳定的训练。 我们提出的方法是第一个解决回归不确定性估计质量的方法。
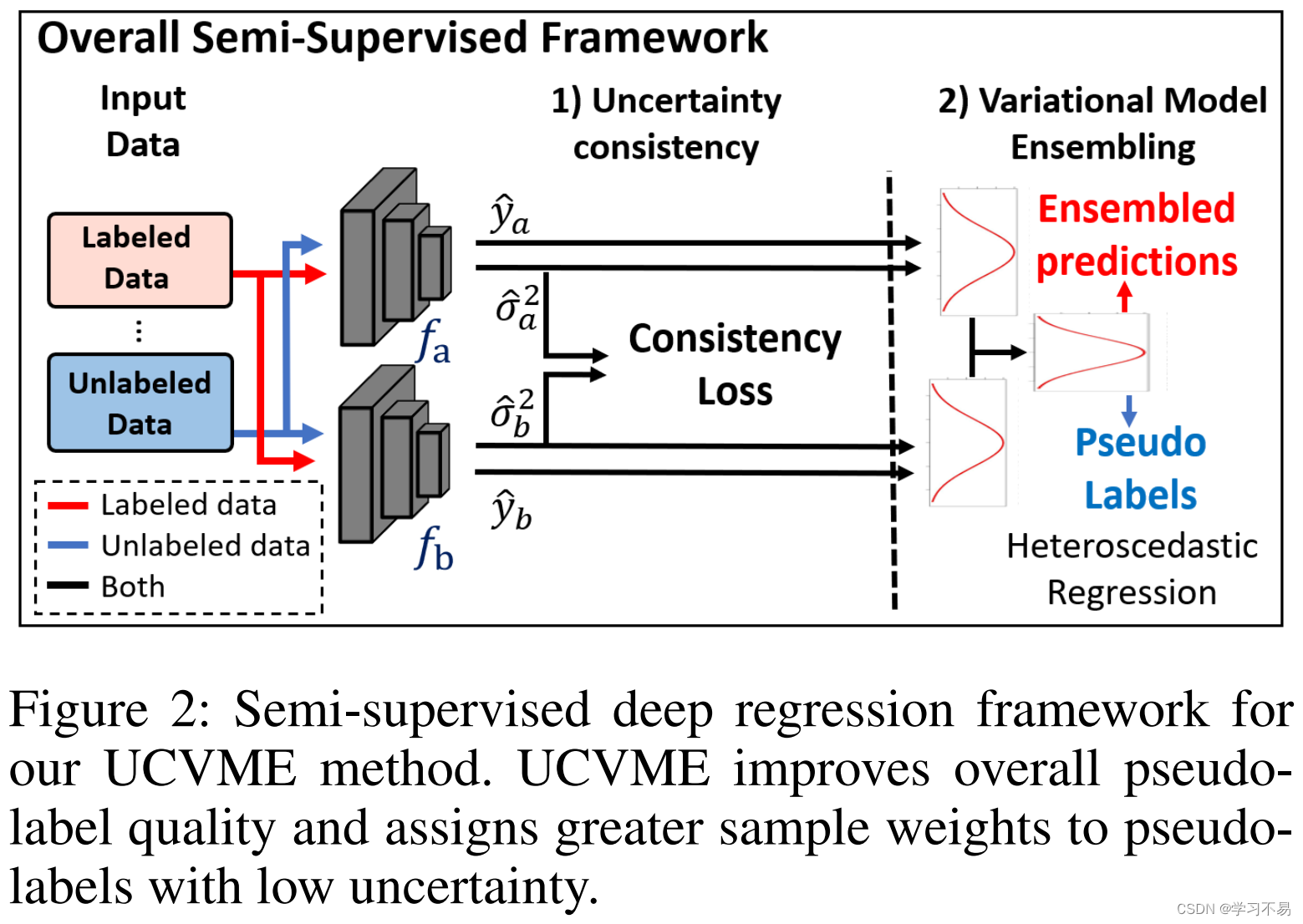
BNN 还在预测过程中使用变分推理来近似估计的基本分布。 为了提高伪标签的鲁棒性,我们引入了变分模型集成,它使用具有变分推理的集成方法来减少预测噪声。我们分析表明,我们的方法可以为未标记的数据生成更高质量的目标,并通过实验验证结果(参见表 2)。不确定性估计和伪标签质量的综合改进带来了最先进的性能。图2说明了总体框架。
我们在两个回归任务上展示了我们的方法:根据照片估计年龄和根据超声心动图视频估计射血分数。结果表明,我们的方法优于最先进的替代方法,并且与使用完整标签的监督方法具有竞争力(参见表 1 和表 4)。消融证明了不确定性一致性和变分模型集成的个体贡献(表 2)。我们的主要贡献总结如下:
- 我们提出了UCVME,一种新颖的半监督方法,可提高深度回归任务的不确定性估计和伪标签鲁棒性。
- 我们基于相同输入的估计值应该相等的见解,为联合训练模型的任意不确定性预测引入了一种新颖的一致性损失。
- 我们引入了变分模型集成,用于在未标记数据上生成伪标签,我们分析表明,它比确定性方法更准确。
- 结果表明,我们的方法在两个独立的回归任务上优于现有的最先进的替代方法。
2 Related Works
在本节中,我们回顾了从未标记数据中学习的工作、半监督学习的一般方法、半监督回归的最先进方法以及现有的不确定性估计方法。
2.2 Semi-Surprised Learning
半监督学习使用标记和未标记数据进行训练。这反映了现实的设置,其中原始数据很容易获得,但注释可能成本高昂。最先进的方法包括强制增强输入的一致性以及对未标记样本使用伪标签。例如,CCT (Ouali、Hudelot 和 Tami 2020)在扰动中间特征后应用预测一致性。 CPS (Chen et al 2021) 强制协同训练模型之间分割预测的一致性。Temporal ensembling(Laine 和 Aila 2016)和 Mean Teacher(Tarvainen 和 Valpola 2017)方法分别使用预测和模型权重集成来生成伪标签。 FixMatch (Sohn et al 2020) 和 FlexMatch (Zhang et al 2021) 使用类别概率阈值进行伪标记,以在半监督分类上实现最先进的结果。类似的技术已应用于视频动作识别(Xu et al 2021)、图像生成(Bodla、Hua 和 Chellappa 2018)、医学图像分割(Li et al 2020, 2018b;You et al 2022;Lin et al 2022),和其他任务。
2.4 Uncertainly Estimation
不确定性估计通常用于半监督学习,以调整未标记样本的伪标签质量。
UA-MT (Yu et al 2019) 和 UMCT (Xia et al 2020) 都使用蒙特卡罗 dropout 来估计伪标签不确定性,然后用于过滤伪标签或对分割任务中的未标记样本进行加权。
Yao 等人 (Yao, Hu, and Li 2022) 和 Lin 等人 (Lin et al 2022)根据用于医学图像分割的共同训练模型之间的预测差异来估计不确定性。
FixMatch (Sohn et al 2020) 和 FlexMatch (Zhang et al 2021) 等半监督分类方法通过设置预测的置信度阈值隐式过滤掉不确定的伪标签。
AAAI2022:Enhancing Pseudo Label Quality for Semi-Supervised Domain-Generalized Medical Image Segmentation
MICCAI2022:Calibrating Label Distribution for Class-Imbalanced Barely-Supervised Knee Segmentation
Nips2020:FixMatch: Simplifying Semi-Supervised Learning with Consistency and Confidence
Nips2021:FlexMatch: Boosting Semi-Supervised Learning with Curriculum Pseudo Labeling
然而,现有的工作尚未探索为半监督深度回归设计的不确定性估计方法。虽然异方差回归等方法可以用来估计不确定性,但只能通过与目标标签的联合预测来完成(Kaufman 2013)。使用伪标签的简单实现给出了不可靠的估计,这可能导致不准确的伪标签被分配更大的权重(见图 5)。在这项工作中,我们提出了一种新颖的不确定性一致性损失,可以显着提高未标记数据的不确定性估计的质量。这导致了更有效的基于不确定性的样本加权,并在不同的半监督深度回归任务上实现了最先进的性能。
3 Methodology
Uncertainty-Consistent Variational Model Ensembling ——UCVME
UCVME 基于两个新颖的想法:强制任意不确定的一致性以改进基于不确定性的损失权重,以及用于生成高质量伪标签的变分模型集成。
我们利用贝叶斯神经网络,它与常规神经网络的不同之处在于它们使用任意不确定性预测和变分推理(Kendall 和 Gal 2017)。我们将
D
:
=
{
(
x
i
,
y
i
)
}
i
=
1
N
\mathcal{D} := \left\{(x_i , y_i)\right\}^N_{i=1}
D:={(xi,yi)}i=1N 表示为由
N
N
N 个样本组成的标记数据集,其中
x
i
x_i
xi 是输入数据,
y
i
y_i
yi 是其相应的标签。我们将
D
′
:
=
{
x
i
′
′
}
i
′
=
1
N
′
\mathcal{D}^\prime := \left\{x^\prime_{i^\prime}\right\}^{N^\prime}_{i^\prime=1}
D′:={xi′′}i′=1N′ 表示为仅由输入数据组成的未标记数据集。我们在协同训练框架中训练两个 BNN,
f
m
f_m
fm,其中
m
∈
{
a
,
b
}
m \in \left\{a, b\right\}
m∈{a,b},并使用蒙特卡罗 dropout 进行训练和推理。我们将
y
^
i
,
m
\hat{y}_{i,m}
y^i,m 表示为模型
m
m
m 对目标标签
y
i
y_i
yi 的预测。我们将
σ
i
2
\sigma^2_i
σi2 表示为任意不确定性,但在实践中预测对数不确定性
l
n
σ
i
2
ln \sigma^2_i
lnσi2,这样做总是为了避免获得方差的负预测。我们使用
z
^
i
,
m
\hat{z}_{i,m}
z^i,m 表示预测的对数不确定性。
3.1 改进异方差回归的任意不确定性一致性损失
任意不确定性 σ i 2 \sigma^2_i σi2 是指与输入数据相关的不确定性。它在 BNN 中用作异方差回归损失的方差参数:
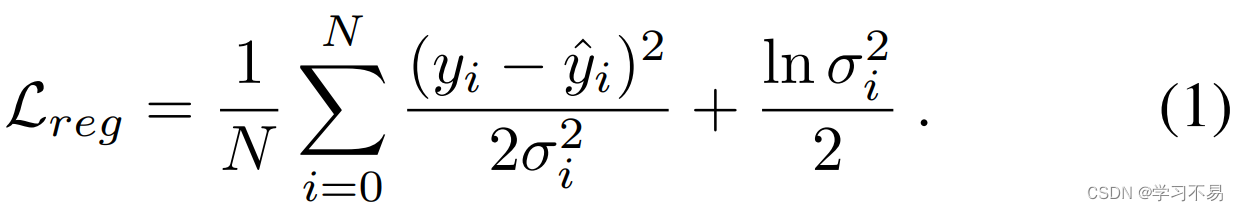
其中 y ^ i \hat{y}_i y^i 是目标标签 y i y_i yi 的预测。直观上,损失函数根据任意不确定性动态权衡误差值。具有高不确定性的样本被认为具有较低质量的标签和较高的噪声,与具有较高确定性的样本相比,这些样本的重要性较低(Kendall 和 Gal 2017)。它的形式推导基于最大似然估计,假设观测误差分布有不同程度的方差(Kaufman 2013)。相反,标准均方误差(MSE)损失假设同方差,即不确定性值 σ i 2 \sigma^2_i σi2 具有相等的方差,这是一个更具限制性且不切实际的假设。我们建议感兴趣的读者参阅补充材料的 Sup-1,以回顾形式推导和比较。
异方差回归对于未标记的数据可能是有益的,因为它允许基于伪标签不确定性对样本进行加权。 然而在实践中,不确定性预测很困难,因为不确定性没有真实标签,必须与目标值联合预测。不反映标签质量的不稳定预测可能会通过分配具有较大权重的噪声样本来对训练产生不利影响。对于未标记的数据来说,稳定的训练更加困难,因为目标地面真值也无法获得,这就是为什么异方差回归尚未成功地应用于现有的半监督工作中。我们在图 5 中展示了这种效应,其中我们看到仅使用异方差回归获得的不确定性预测可能是不可靠的。
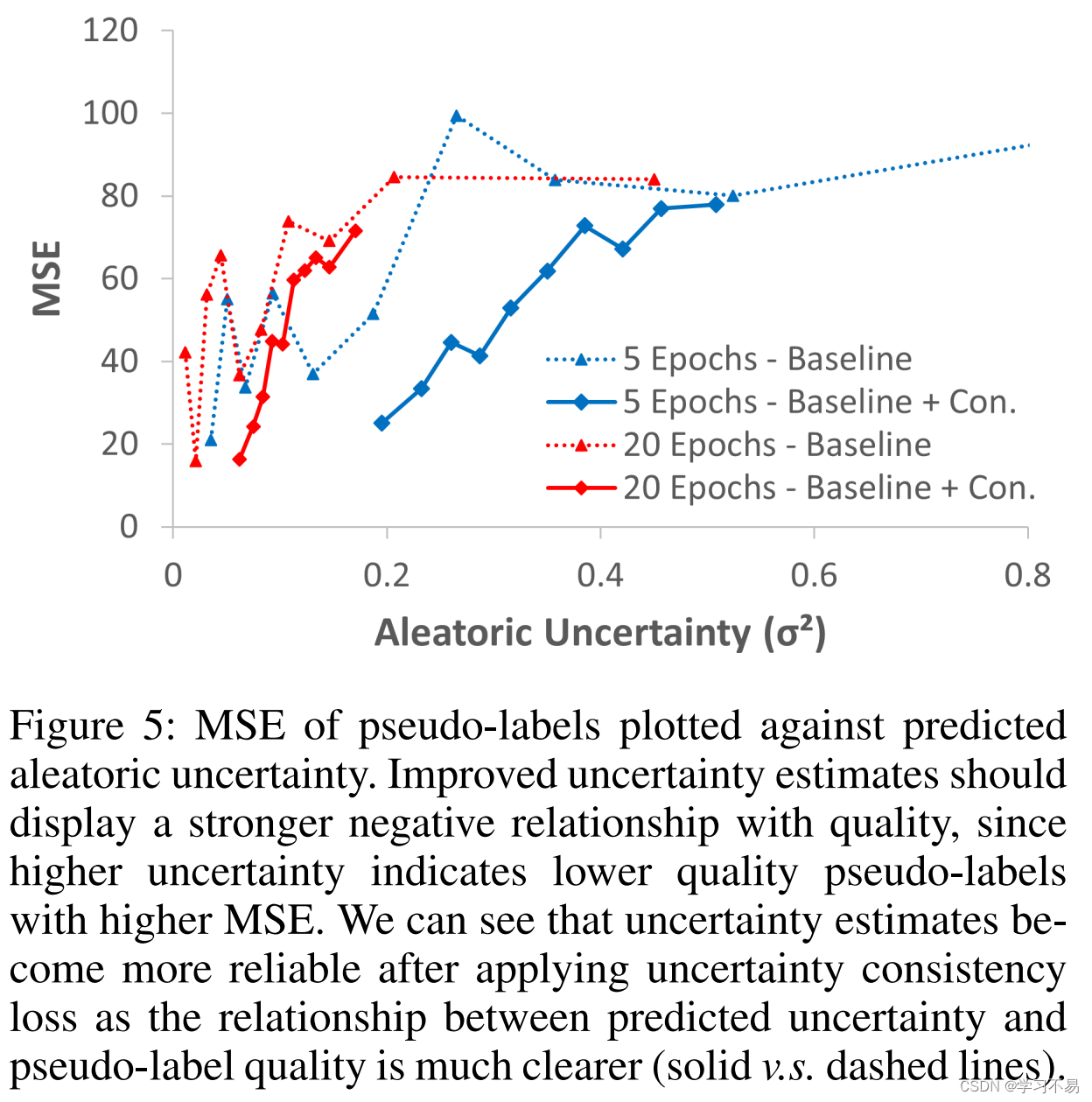
我们观察到,根据定义,相同输入数据的任意不确定性应该相等,并引入一种新颖的一致性损失来强制共同训练模型之间一致的不确定性预测。众所周知,预测一致性是一种有效的正则化器(Chen et al 2021),并且可以应用于标记和未标记数据以改进估计。通过确保共同训练模型的不确定性预测一致,除了与目标标签的联合估计之外,我们还提供额外的训练信号,这有助于模型学习更可靠的预测。对于标记输入,我们引入一致性损失 L u n c l b L^{lb}_{unc} Lunclb:
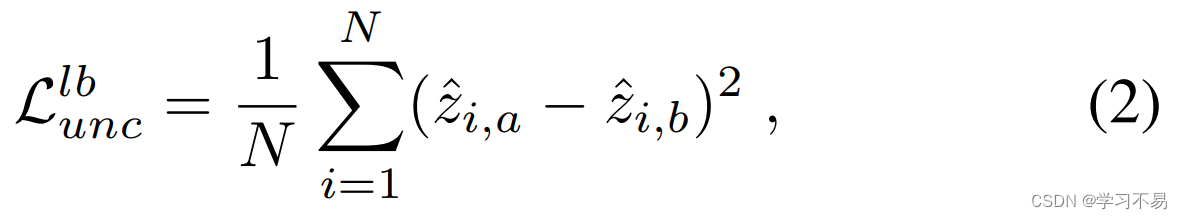
这是基于 L2 距离的。使用不确定性预测计算异方差回归损失:
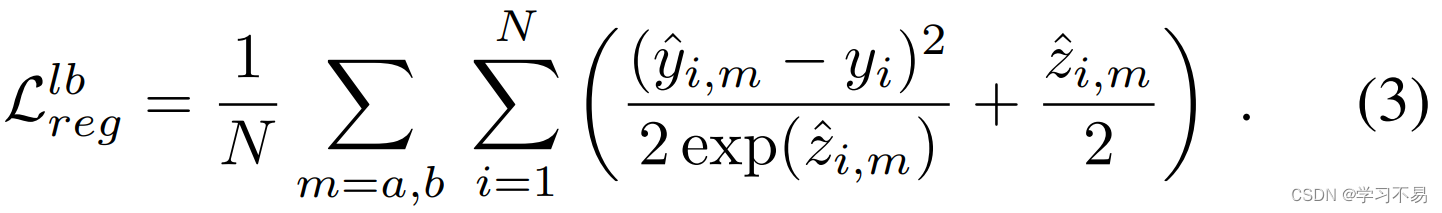
对于未标记的数据, y y y 的地面真实目标标签不可用,这使得联合不确定性预测具有挑战性。相反,我们利用变分模型集成来获取对数不确定性 z ~ i \tilde{z}_i z~i 的伪标签,将其用作训练目标。我们在下面的小节中描述未标记样本的变分模型集成。
3.2 用于伪标签生成的变分模型集成
BNN 使用蒙特卡罗 dropout 和变分推理来估计预测变量 y ^ \hat{y} y^ 的分布。为了减少预测噪声,我们可以使用减少预测变量方差的集成技术,这可以通过偏差方差分解来证明。预测器 y ^ \hat{y} y^ 的性能可以使用预期 MSE 进行评估,我们使用偏差方差分解将其分解如下:
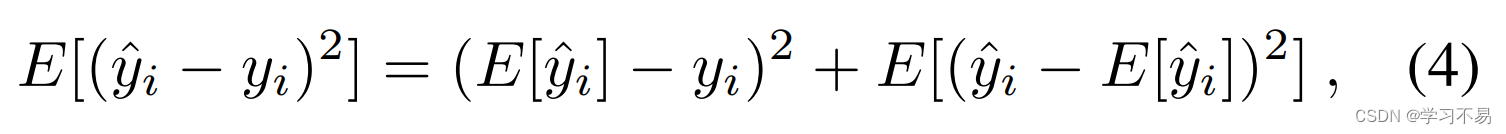
其中第一个右侧项是偏差,第二个是方差。如果我们从变分推理中获取单个样本预测 y ^ i t \hat{y}_i^t y^it,并获得一个集合来形成新的预测器 y ~ \tilde{y} y~ ,我们有:

其中 T T T 是使用的样本数。预测变量 y ~ i \tilde{y}_i y~i 的预期 MSE 损失为:
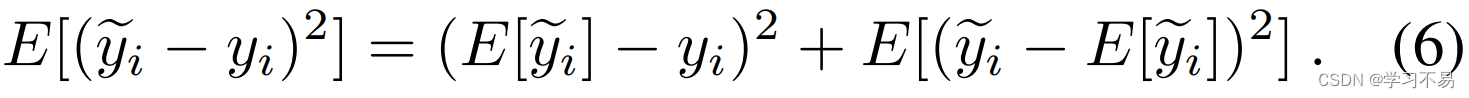
预测变量的偏差项相等,但方程 6 中的方差项不能大于方程 4 中的方差项,因为观察到的样本更多(有关更详细的推导,请参阅补充材料的 Sup-2)。这意味着预测器 y ~ i \tilde{y}_i y~i 的预期 MSE 低于或等于 y ^ i \hat{y}_i y^i 并且始终具有更高的质量。
基于这种效应,我们提出了变分模型集成,用于在目标值 y ~ i \tilde{y}_i y~i 和对数任意不确定性 z ~ i \tilde{z}_i z~i 上生成伪标签。虽然协同训练模型的伪标签通常依赖于最先进方法中的交叉监督(Xu et al 2021;Chen et al 2021),但我们集成了协同训练模型的平均估计并应用变分推理:
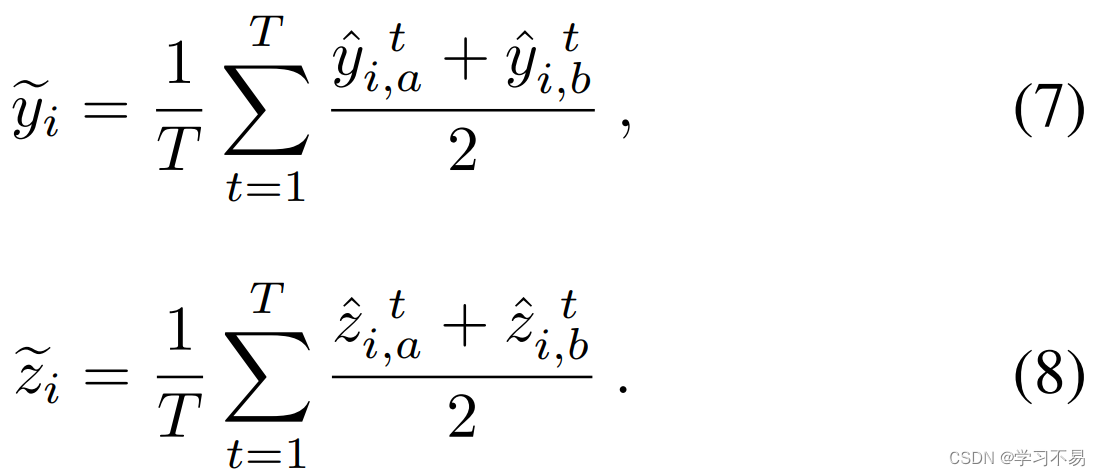
并将其用作训练的伪标签。与交叉监督相比,使用变分模型集成计算的伪标签由于预测方差减少而更加准确,并且更好地反映真实目标和不确定性值。 这对于回归目标尤其重要,因为伪标签直接使用实数预测并且不依赖阈值函数进行平滑。然后使用 z ~ i \tilde{z}_i z~i 作为训练目标来计算未标记数据的不确定性一致性:
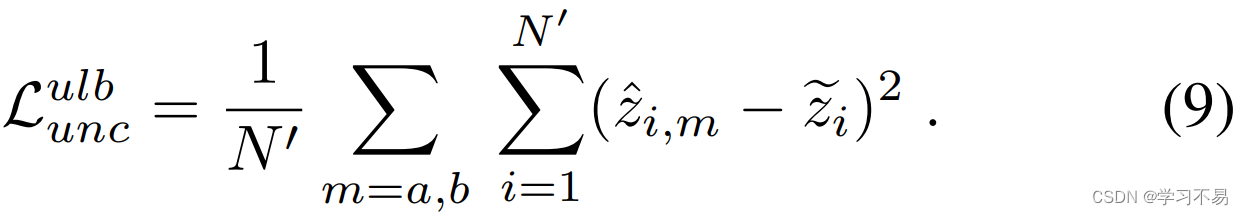
未标记数据的异方差回归损失是使用 y ~ i \tilde{y}_i y~i 作为目标和 z ~ i \tilde{z}_i z~i 作为对数不确定性来计算的:
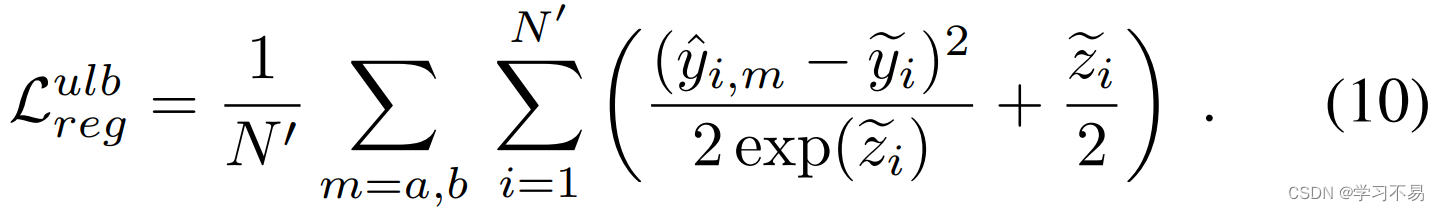
改进的伪标签导致更稳定的异方差回归,从而在未标记的数据上生成更好的训练信号。
3.3 整体半监督框架
在训练过程中,我们使用标记样本计算异方差回归损失 L r e g l b L^{lb}_{reg} Lreglb 和任意不确定性一致性损失 L u n c l b L^{lb}_{unc} Lunclb。未标记数据的伪标签是使用等式生成的。 7 和 8 在每次训练迭代开始时使用最新的模型权重。 L r e g u l b L^{ulb}_{reg} Lregulb 和 L u n c u l b L^{ulb}_{unc} Lunculb 的损失值是针对未标记数据计算的,并使用总损失与标记数据联合优化:
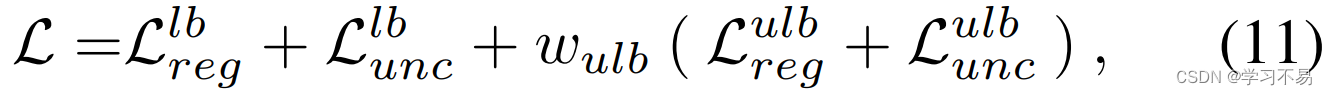
其中 w u l b w_{ulb} wulb 是未标记数据的加权参数。变分模型集成也用于测试时推理以获得 y ~ i \tilde{y}_i y~i 作为最终预测。补充材料的 S-算法 1 中给出了伪代码。
4 Experiments
我们在两个半监督深度回归问题上展示了我们的方法:根据照片估计年龄和根据超声心动图视频估计射血分数。
5 Conclusion
在这项工作中,我们介绍了一种用于半监督深度回归的新颖的不确定性一致变分模型集成(UCVME)方法。我们的方法通过调整伪标签质量和提高伪标签鲁棒性来改进对未标记数据的训练。 我们在不确定性估计上引入了一种新颖的一致性损失,我们证明它可以显着改善异方差损失权重,特别是对于未标记的样本。我们还使用变分模型集成来减少预测噪声并为未标记数据生成更好的训练目标。 我们的方法具有强大的理论支持,可以应用于不同的任务和数据集。我们使用两个基于图像和视频数据的深度回归任务来演示这一点,并为这两个任务实现了最先进的性能。结果也与使用完整标签的监督方法相比具有竞争力。因此,UCVME 是减少深度回归任务所需标签数量的一种有价值的方法。















 306
306











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









