







本文的后作是:视觉Transformer(二):从稀疏剪枝到跨模态理解——当视觉模型学会「选择性思考」-CSDN博客
一、通俗解释:图像理解的范式转移
1.1 核心思想
视觉Transformer(ViT) 将自然语言处理中的自注意力机制引入计算机视觉,彻底颠覆了CNN的局部感知范式。其核心是将图像拆解为序列化碎片,通过全局关系建模理解整体语义——让每个像素块都能“看见”整个图像。
类比理解
- 传统CNN:像通过猫眼窥视房间(局部视野受限)
- ViT:如无人机航拍全景(全局关系尽收眼底)
- Swin Transformer:高精度卫星地图(分层缩放兼顾细节与全局)
1.2 关键术语解析
| 术语 | 解释 | 技术隐喻 |
|---|---|---|
| 图像分块 | 将224×224图像切为16×16的196个小块 | 把拼图拆成碎片 |
| 位置编码 | 为每个碎块添加位置标记 | 给拼图碎片编号 |
| 多头注意力 | 并行学习不同子空间关系 | 多组专家同时拼图 |
| 移位窗口 | Swin的创新性局部注意力机制 | 分区域组装再整体拼接 |
二、应用场景与优劣评估
2.1 典型应用场景
- 医疗影像分析:ViT在肺部CT结节检测中比CNN高4.3%召回率(全局上下文关联微小结节)
- 自动驾驶:Swin Transformer实时街景分割速度达45FPS(层次化设计优化计算)
- 工业质检:MobileViT在芯片缺陷检测部署至移动端(3ms/帧推理速度)
2.2 架构性能对比
| 模型 | ImageNet精度 | 参数量 | 计算量 | 适用场景 |
|---|---|---|---|---|
| ViT-B/16 | 84.5% | 86M | 33G FLOPs | 云端服务器 |
| Swin-T | 83.3% | 29M | 4.5G FLOPs | 边缘设备 |
| MobileViTv2 | 78.2% | 5.6M | 2.0G FLOPs | 手机端 |
| EdgeViT-XXS | 71.9% | 1.6M | 0.3G FLOPs | 物联网设备 |
优势:
✅ 全局建模能力打破图像边界限制
✅ 避免CNN的归纳偏置,数据驱动特征学习
✅ 统一框架兼容多模态任务(图像+文本)
缺陷:
❌ 需大量数据预训练(ViT在JFT-300M数据集预训练)
❌ 位置编码难以适应多尺度任务
❌ 注意力矩阵的O(n²)复杂度制约高分辨率处理
三、模型架构深度拆解
3.1 标准ViT架构
输入图像
↓
[分块嵌入] → 16×16碎片展平为向量 (196×768)
↓
[类别标记] + [位置嵌入] → 添加可学习分类符和位置编码
↓
[Transformer编码器]×L → 核心处理层堆叠
│ ├─ LayerNorm
│ ├─ 多头注意力 (12头, 768维度)
│ └─ MLP块 (3072维隐层)
↓
[MLP头] → 提取类别标记对应输出
↓
分类结果 模块详解:
-
分块嵌入层
- 卷积操作实现:核尺寸=16×16, 步长=16, 输出通道=768
- 等效于将图像视为196个单词的词序列
-
位置编码
- 可学习参数:随机初始化197×768矩阵(196碎片+1类别标记)
- 物理意义:防止碎片序列顺序混乱
-
Transformer编码层
[输入X] → [LayerNorm] → 多头注意力 → [残差连接] → ↓ ↑ └─────────── 相加 ←────────────────┘ ↓ [LayerNorm] → [MLP] → [残差连接] ↓ ↑ └── 相加 ←────┘
3.2 Swin Transformer创新架构
输入图像
↓
[分块嵌入] → 4×4碎片 (分辨率降为1/4)
↓
[阶段1] → 窗口注意力 + 下采样 → 特征图[H/4×W/4×C]
↓
[阶段2] → 移位窗口注意力 + 下采样 → [H/8×W/8×2C]
↓
[阶段3] → 移位窗口注意力 + 下采样 → [H/16×W/16×4C]
↓
[阶段4] → 全局注意力 → 分类输出 核心创新:
- 窗口划分:将特征图分割为M×M非重叠窗口(默认7×7)
- 移位窗口:
第L层:常规窗口划分 → 窗口内自注意力 第L+1层:窗口向右下偏移50% → 跨窗口信息交互 - 相对位置偏置:
B为可学习的相对位置编码矩阵
四、模型工作流程全景拆解(以ViT为例)
4.1 数据输入阶段

- 块分割:图像被切割为196个16×16碎片(如切豆腐块)
- 向量化:每个碎片按RGB通道展平为768维向量(16 * 16 * 3)
- 序列构建:在碎片序列头部插入特殊标记
[CLS](最终用于分类) - 位置注入:为每个碎片添加"位置身份证",使模型理解空间关系
4.2 Transformer编码器工作流
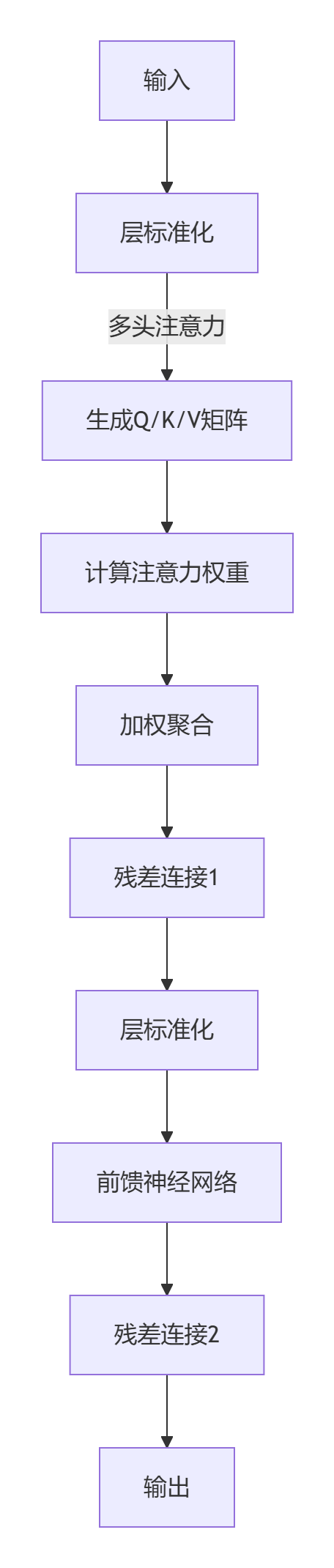
-
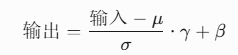
层标准化(LayerNorm)
- 对每个向量独立归一化(类比统一碎片亮度)
- 公式:
-
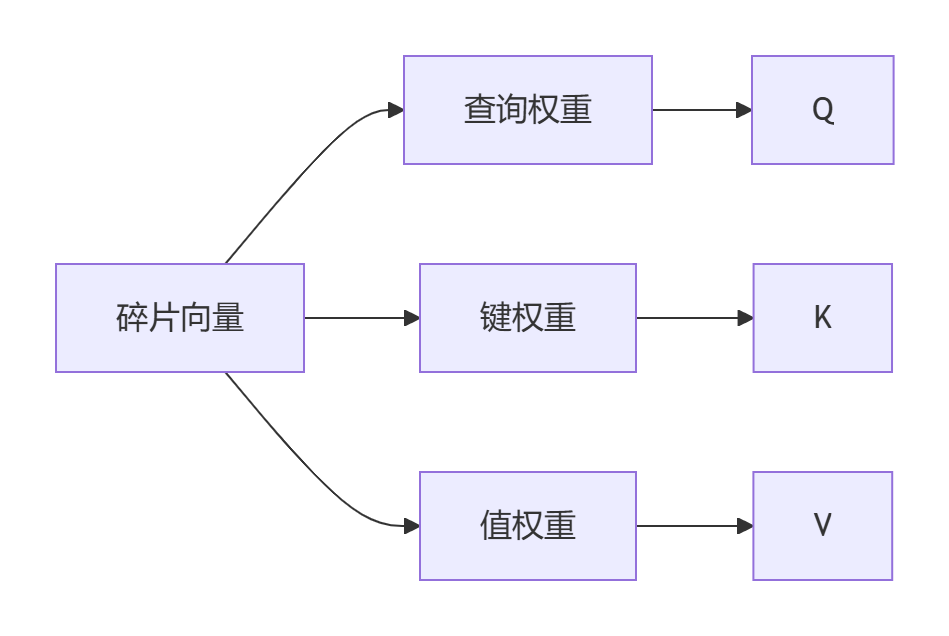
多头注意力计算
- 查询-键值生成:每个碎片生成三组向量
- 注意力权重:计算碎片间相关性(如"猫耳碎片"关注"胡须碎片")
- 查询-键值生成:每个碎片生成三组向量
-
信息聚合与残差连接
- 用注意力权重对V向量加权求和(关键信息融合)
- 保留原始信息:输出 = 注意力结果 + 输入向量
-
前馈神经网络
- 两层的MLP进行非线性变换(维度扩展4倍再压缩)
- 每个碎片独立处理(并行计算加速)
4.3 分类输出阶段

- CLS标记演化:经过所有编码层后,
[CLS]向量蕴含全局信息 - MLP头结构:
- 隐层:768维 → 3072维(GeLU激活)
- 输出层:3072维 → 1000维(对应ImageNet类别)
- 概率生成:Softmax函数输出分类概率分布
五、关键技术的数学原理解析
5.1 自注意力机制
查询-键值映射:
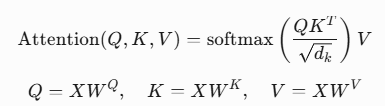
- Softmax归一化为概率分布
多头并行计算:

h个头独立学习不同子空间关系(如形状/颜色/纹理)
5.2 移位窗口注意力(Swin核心)
窗口划分公式:

- W-MSA:常规窗口自注意力
- SW-MSA:窗口右移50%的移位注意力
相对位置偏置:
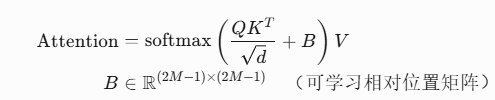
M:窗口尺寸(默认7×7)B编码碎片间相对距离(行差i-j,列差k-l)
5.3 轻量化设计(MobileViT)
MobileNet融合模块:

5.4 层标准化与残差连接
层标准化:
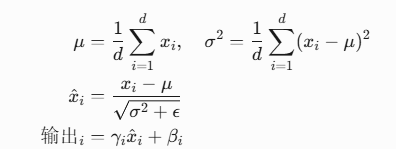
残差连接:
f表示任意变换层(注意力或MLP)- 确保深层网络仍能学习恒等映射
六、PyTorch实战:从零实现到HuggingFace调用
6.1 ViT核心模块实现(PyTorch原生)
import torch
import torch.nn as nn
class PatchEmbedding(nn.Module):
def __init__(self, img_size=224, patch_size=16, in_chans=3, embed_dim=768):
super().__init__()
# 图像切块与线性投影层
self.proj = nn.Conv2d(
in_channels=in_chans,
out_channels=embed_dim,
kernel_size=patch_size,
stride=patch_size
)
self.num_patches = (img_size // patch_size) ** 2
def forward(self, x):
x = self.proj(x) # [B, C, H, W] -> [B, E, H/p, W/p]
x = x.flatten(2) # [B, E, (H/p * W/p)]
return x.transpose(1, 2) # [B, N, E]
class ViTBlock(nn.Module):
def __init__(self, dim, num_heads=12, mlp_ratio=4.0):
super().__init__()
self.norm1 = nn.LayerNorm(dim)
self.attn = nn.MultiheadAttention(
embed_dim=dim,
num_heads=num_heads,
batch_first=True
)
self.norm2 = nn.LayerNorm(dim)
self.mlp = nn.Sequential(
nn.Linear(dim, int(dim * mlp_ratio)),
nn.GELU(),
nn.Linear(int(dim * mlp_ratio), dim)
)
def forward(self, x):
# 自注意力模块
attn_input = self.norm1(x)
attn_output, _ = self.attn(
query=attn_input,
key=attn_input,
value=attn_input
)
x = x + attn_output # 残差连接
# 前馈网络
mlp_input = self.norm2(x)
mlp_output = self.mlp(mlp_input)
return x + mlp_output # 残差连接
class ViT(nn.Module):
def __init__(self, num_classes=1000, depth=12):
super().__init__()
self.patch_embed = PatchEmbedding()
self.cls_token = nn.Parameter(torch.randn(1, 1, 768))
self.pos_embed = nn.Parameter(torch.randn(1, 197, 768))
self.blocks = nn.ModuleList([
ViTBlock(dim=768) for _ in range(depth)
])
self.head = nn.Linear(768, num_classes)
def forward(self, x):
# 输入处理
x = self.patch_embed(x) # [B, 196, 768]
cls_tokens = self.cls_token.expand(x.shape[0], -1, -1) # [B, 1, 768]
x = torch.cat([cls_tokens, x], dim=1) # [B, 197, 768]
x = x + self.pos_embed # 位置编码
# Transformer编码
for block in self.blocks:
x = block(x)
# 分类输出
cls_out = x[:, 0] # 提取CLS标记
return self.head(cls_out) 6.2 HuggingFace Transformers调用(ViT/Swin)
from transformers import ViTImageProcessor, ViTForImageClassification
from transformers import SwinImageProcessor, SwinForImageClassification
# ----------------- ViT调用示例 -----------------
# 加载预训练模型
vit_processor = ViTImageProcessor.from_pretrained('google/vit-base-patch16-224-in21k')
vit_model = ViTForImageClassification.from_pretrained('google/vit-base-patch16-224-in21k')
# 处理输入图像
from PIL import Image
image = Image.open("cat.jpg")
inputs = vit_processor(images=image, return_tensors="pt")
# 推理预测
with torch.no_grad():
outputs = vit_model(**inputs)
logits = outputs.logits
pred_class = logits.argmax().item()
print("ViT预测类别:", vit_model.config.id2label[pred_class])
# ----------------- Swin Transformer调用示例 -----------------
swin_processor = SwinImageProcessor.from_pretrained('microsoft/swin-tiny-patch4-window7-224')
swin_model = SwinForImageClassification.from_pretrained('microsoft/swin-tiny-patch4-window7-224')
inputs = swin_processor(images=image, return_tensors="pt")
with torch.no_grad():
outputs = swin_model(**inputs)
swin_class = outputs.logits.argmax().item()
print("Swin预测类别:", swin_model.config.id2label[swin_class]) 总结:视觉Transformer的进化与启示
核心突破
- 架构革命:ViT首次证明纯Transformer结构在视觉任务中可超越CNN,颠覆了“卷积不可或缺”的传统认知
- 全局建模:自注意力机制突破局部感受野限制,实现像素级全局关系建模
- 统一框架:Swin等层次化设计弥合了NLP与CV的结构鸿沟,为多模态融合铺平道路
技术演进趋势
| 时期 | 代表模型 | 核心创新 |
|---|---|---|
| 2020 | ViT | 图像分块+位置编码+标准Transformer |
| 2021 | Swin | 移位窗口+分层特征金字塔 |
| 2022 | MobileViT | CNN与Transformer的混合架构 |
| 2023 | EdgeViT | 动态稀疏注意力+硬件感知压缩 |
未来挑战
- 计算效率:高分辨率图像仍面临O(n²)复杂度瓶颈
- 数据依赖:需数十倍于CNN的标注数据才能达到同等精度
- 解释性弱:注意力图难以直观解释,不利于医疗等敏感领域
- 动态适应:当前架构缺乏人类视觉系统般的动态资源分配能力
终极启示:视觉Transformer不是替代CNN的终结者,而是开启了“架构融合”新纪元。未来的计算机视觉模型将兼具CNN的局部归纳偏置、Transformer的全局建模能力,以及生物视觉的动态适应性,最终迈向通用视觉智能的终极目标。

















 471
471

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









