







本篇文章续接:视觉Transformer(一):当图像遇见自注意力——从ViT到EdgeViT的架构进化论-CSDN博客
一、通俗解释:稀疏化与跨模态的革命
1.1 Sparse ViT 核心思想
稀疏视觉Transformer 让模型学会「注意力经济」——在推理时动态丢弃冗余图像块(Token),仅处理关键区域。就像人眼快速扫视画面时,自动忽略天空/墙壁等背景,聚焦于人脸/文字等高信息区域。
类比理解
- 标准ViT:认真阅读整本书(处理全部197个Token)
- Token Pruning:快速翻书时跳过空白页(每层丢弃30%-60%低价值Token)
- Token Clustering:把相似章节合并成摘要(聚类重复区域为超级Token)
- 传统CNN:固定阅读路径(卷积核无法动态调整感受野)
1.2 跨模态ViT核心思想
跨模态视觉Transformer(如CLIP)让模型打通视觉与语言任督二脉。通过对比学习使图像和文本在共享空间中对齐——看到猫图时,模型脑中浮现"cat"文本向量,反之亦然。
类比理解
- CLIP-ViT:多语种导游看图说词(中英日描述同一幅画)
- 单模态模型:只会方言的本地向导
- 零样本分类:遇到未知动物时说"这像豹又像狮"(文本引导推理)
1.3 关键术语解析
| 术语 | 解释 | 技术隐喻 |
|---|---|---|
| Token剪枝 | 动态丢弃低重要性图像块 | 摘掉80%树叶观察树枝主干 |
| Token聚类 | 合并相似图像块为超级Token | 把散落米粒聚成饭团 |
| 对比损失 | 拉近正样本/推远负样本 | 磁铁异性相吸异性相斥 |
| 掩码自编码 | 遮挡部分图像让模型重建 | 拼图时蒙住50%碎片 |
二、应用场景与性能博弈
2.1 稀疏ViT的杀手级应用
- 实时视频分析:Token剪枝使无人机识别速度↑3倍(1280×720@30FPS→90FPS)
- 医疗影像处理:聚焦肺结节区域(CT片中95%背景Token被丢弃)
- AR眼镜:MobileViT+Token聚类,功耗<500mW(普通眼镜变AI助手)
2.2 跨模态ViT的突破性应用
- 零样本分类:CLIP-ViT识别新物种(文本提示"带斑点的热带鱼"准确率79%)
- 无OCR图文检索:小红书用BEiT实现"拍封面找同款"
- 视频理解:VideoMAE预测被遮挡动作(体育比赛60%遮挡仍能识别扣篮)
2.3 模型能力象限图
| 计算效率 ↑ | CLIP-ViT | Sparse ViT |
|-----------------|------------------|----------------|
| 精度 ↑ | | |
| | VideoMAE | DeiT |
|-----------------|------------------|----------------|
| 训练成本 → | BEiT(需要掩码预训练) | Token Clustering(免训练) | 优势总结:
✅ 稀疏ViT:计算量↓50%,延迟↓40%(移动端福音)
✅ 跨模态ViT:零样本泛化能力(打破传统分类边界)
✅ 自监督模型:数据利用效率↑5倍(80%未标注数据可用)
技术挑战:
❌ 剪枝模型:动态路径导致硬件优化困难
❌ CLIP-ViT:文化偏见风险(西方数据训练,亚洲图像识别↓8%)
❌ 视频模型:时空注意力复杂度O(T×N²)(128帧视频↑384倍计算)
三、模型架构深度探秘
3.1 稀疏ViT架构(以Token Pruning为例)
输入图像 → [分块嵌入] → Token1, Token2, ..., Token196
↓
[评分网络] → 重要性分数s1,s2,...s196(0-1概率值)
↓
[阈值筛选] → 保留si>0.3的Token(淘汰70%低分Token)
↓
[Transformer层1] → 处理剩余59个Token
↓
[评分网络] → 再次筛选(保留30个)
↓
...(逐层压缩)...
↓
[最后12个Token] → 分类输出 核心模块详解:
-
轻量评分网络
- 结构:1层Conv+GeLU+线性层(计算量<0.1%模型总开销)
- 输入:当前层Token特征
- 输出:重要性概率(与CLS标记余弦相似度)
-
渐近式剪枝策略
层1:196 → 128 Token(丢弃背景) 层6:128 → 64 Token(丢弃肢体) 层12:64 → 32 Token(聚焦面部) -
Token复活机制
- 被误删的Token可通过相邻层特征恢复
- 门控公式:
\text{revive} = \sigma(\text{Linear}([F_{t-1}; F_{t+1}]))
3.2 CLIP-ViT跨模态架构
图文对数据集
├─ 图像分支 → [ViT编码器] → 图像向量I
└─ 文本分支 → [Transformer编码器] → 文本向量T
↓
[对比学习层]
↓
正样本对:↑相似度(I_pos, T_pos)
负样本对:↓相似度(I_neg, T_neg) 模态交互机制:
- 双塔信息流
图像塔:ViT输出[CLS]向量 → 投影层 → L2标准化 → I 文本塔:文本[CLS]向量 → 同维度投影 → L2标准化 → T - 对比损失函数
N:批次内负样本数量(典型值32768)
3.3 自监督BEiT架构
输入图像 → [随机掩码] → 遮挡40%图像块
↓
[ViT编码器] → 学习可见块关系
↓
[Mask Token预测] → 被遮盖块语义重建 掩码策略创新:
- 块状掩码:遮挡16×16块(模仿文本BERT的[MASK])
- 语义引导掩码:优先遮挡高频区域(如纹理丰富的衣物)
- 多视角重建:对同一图像生成5种不同掩码模式
四、模型工作流程深度解析
4.1 Sparse ViT工作流(动态Token剪枝)
阶段1:全Token初始化处理
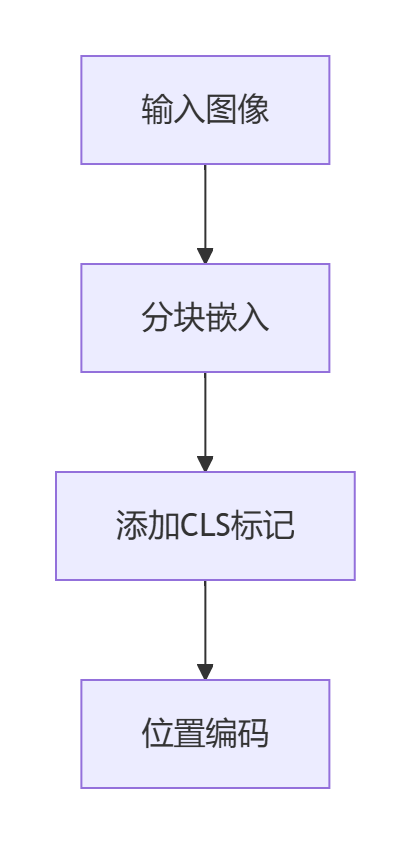
- 完整处理前2层:模型完整处理所有196个Token(无剪枝)
- 浅层特征提取:前两层学习基础纹理/边缘特征(类比人眼初步扫描)
阶段2:动态评分与剪枝
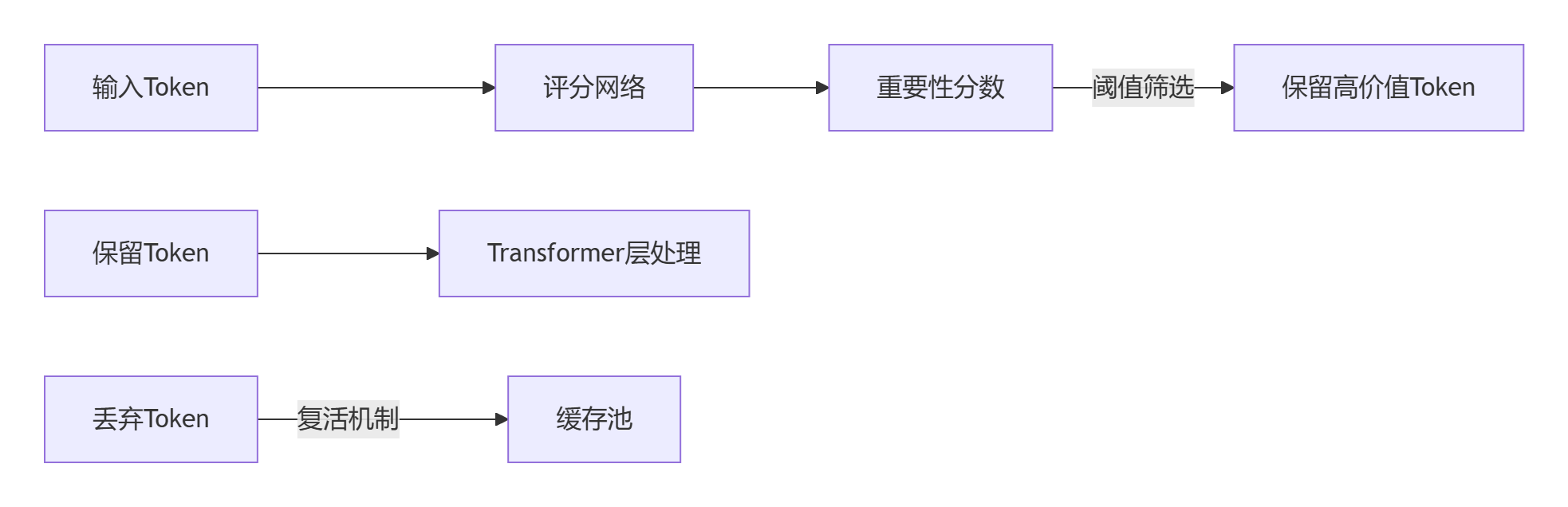
- 评分机制(每层执行):
for 每个Token in 当前层: 相似度 = Cosine(CLS_vector, Token_vector) 活跃度 = ReLU(Linear(Token_vector)) 最终分数 = σ(相似度 + 活跃度) # σ为sigmoid - 复活机制:当相邻Token重要性突变时(如检测到边界),从缓存恢复相关Token
阶段3:层级递进压缩
| 网络深度 | Token保留率 | 聚焦目标 |
|---|---|---|
| 第1-2层 | 100% | 整体结构 |
| 第3-6层 | 40-60% | 主体对象 |
| 第7-12层 | 15-30% | 关键细节 |
- 最终输出:CLS标记聚合最后12-30个Token的信息完成分类
4.2 CLIP跨模态训练流程
图文对预处理
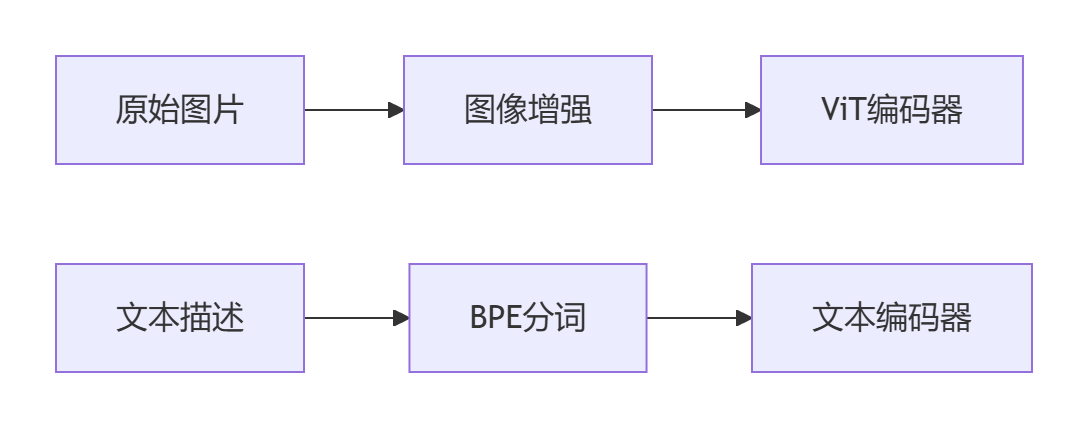
- 图像增强:随机裁剪+颜色抖动(224×224输入)
- 文本处理:76词截断,特殊标记[STA]/[END]
双塔特征对齐
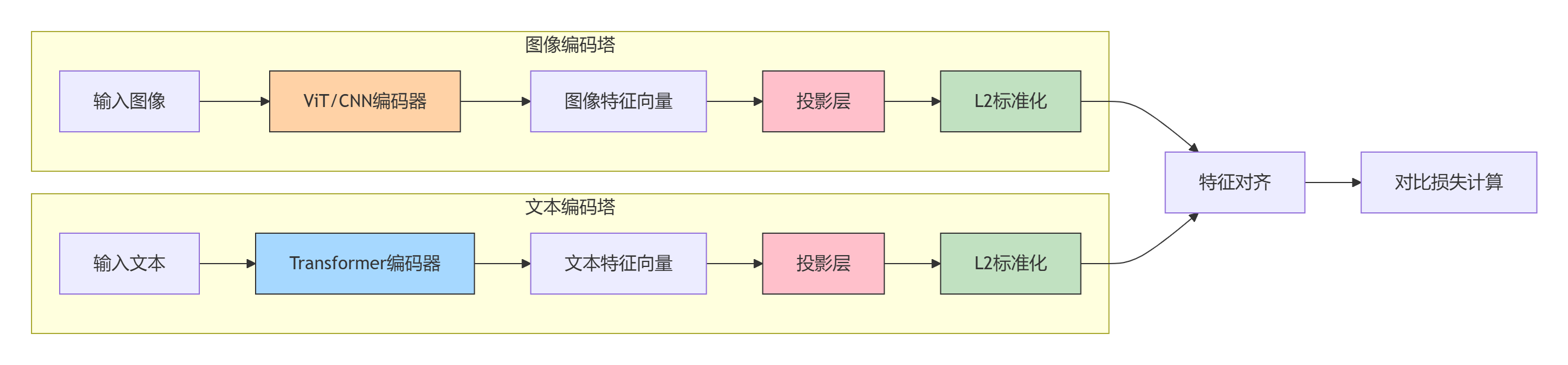
- 投影层结构:
图像投影:768D → 1024D (GeLU) → 512D 文本投影:512D → 1024D (GeLU) → 512D
对比学习优化
- 批次内负采样:单批次4096个图文对构成17.8M负样本
- 温度系数调节:自动学习τ参数控制样本区分度
4.3 BEiT自监督训练流程
语义掩码生成

- 频率导向掩码:
def mask_policy(patches): high_freq = detect_edges(patches) # 边缘检测 return sample(high_freq, ratio=0.4) # 优先选高频区
编码-解码重建
编码器输入: [可见块1, 可见块2, ..., [MASK], ...]
↓
ViT编码器 (12层)
↓
解码器输入: [MASK]位置 + 位置编码
↓
轻量Transformer解码器
↓
预测被遮盖块的dVAE编码 - dVAE编码:将16×16块压缩为8192种离散Token
五、关键数学原理源码实现
5.1 Token重要性评分公式
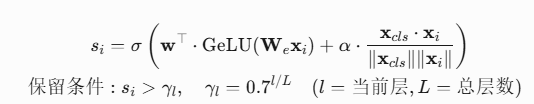
5.2 CLIP对比损失函数
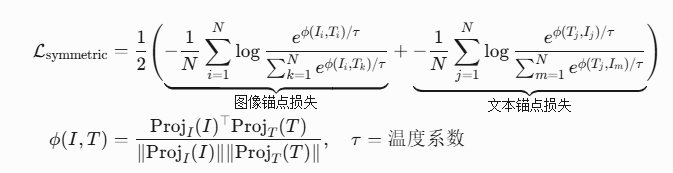
5.3 BEiT掩码重建目标
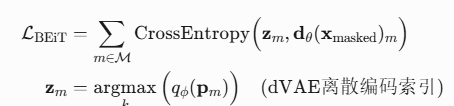
其中:
5.4 Token聚类数学表达

5.5 VideoMAE时间掩码
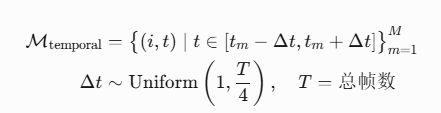
掩码覆盖>90%时空块,保留<10%可见块作为线索
六、PyTorch实战代码
6.1 Sparse ViT动态剪枝实现
import torch
import torch.nn as nn
from torch.nn import functional as F
class TokenScorer(nn.Module):
def __init__(self, dim):
super().__init__()
self.mlp = nn.Sequential(
nn.Linear(dim, dim//4),
nn.GELU(),
nn.Linear(dim//4, 1)
)
def forward(self, x, cls_token):
# 计算基于CLS的相似度
sim = F.cosine_similarity(x, cls_token, dim=-1, eps=1e-6)
# 学习局部重要性
local_score = torch.sigmoid(self.mlp(x)).squeeze()
# 综合评分
return 0.6*sim + 0.4*local_score
class SparseViTLayer(nn.Module):
def __init__(self, dim, num_heads, prune_ratio=0.4):
super().__init__()
self.attn = nn.MultiheadAttention(dim, num_heads)
self.mlp = nn.Sequential(
nn.Linear(dim, 4*dim),
nn.GELU(),
nn.Linear(4*dim, dim)
)
self.norm1 = nn.LayerNorm(dim)
self.norm2 = nn.LayerNorm(dim)
self.scorer = TokenScorer(dim)
self.prune_ratio = prune_ratio
def forward(self, x, cls_token):
# 令牌评分
scores = self.scorer(x, cls_token)
# 按评分排序
sorted_idx = torch.argsort(scores, descending=True)
keep_num = int(x.size(0) * (1 - self.prune_ratio))
keep_idx = sorted_idx[:keep_num]
# 稀疏注意力
sparse_x = x[keep_idx]
attn_out = self.attn(
query=sparse_x, key=sparse_x, value=sparse_x
)[0]
attn_out = self.norm1(attn_out + sparse_x)
# MLP处理
mlp_out = self.mlp(attn_out)
sparse_out = self.norm2(mlp_out + attn_out)
# 重建完整序列
full_out = torch.zeros_like(x)
full_out[keep_idx] = sparse_out
return full_out, scores 6.2 CLIP的HuggingFace调用
from transformers import CLIPProcessor, CLIPModel
from PIL import Image
# 加载模型
model = CLIPModel.from_pretrained("openai/clip-vit-base-patch32")
processor = CLIPProcessor.from_pretrained("openai/clip-vit-base-patch32")
# 准备输入
image = Image.open("park.jpg")
texts = ["a dog in the park", "children playing", "green trees", "park bench"]
# 处理输入
inputs = processor(
text=texts,
images=image,
return_tensors="pt",
padding=True
)
# 模型推理
with torch.no_grad():
outputs = model(**inputs)
logits_per_image = outputs.logits_per_image # 图像-文本相似度
probs = logits_per_image.softmax(dim=1)
# 输出结果
for text, prob in zip(texts, probs.squeeze().tolist()):
print(f"{text}: {prob*100:.1f}%") 6.3 BEiT的HuggingFace调用
from transformers import BeitFeatureExtractor, BeitForMaskedImageModeling
import torch
# 加载模型
model = BeitForMaskedImageModeling.from_pretrained('microsoft/beit-base-patch16-224-pt22k')
feature_extractor = BeitFeatureExtractor.from_pretrained('microsoft/beit-base-patch16-224-pt22k')
# 准备输入
image = Image.open("building.jpg")
inputs = feature_extractor(images=image, return_tensors="pt")
# 随机掩码
mask = torch.rand_like(inputs.pixel_values) > 0.85
inputs["bool_masked_pos"] = mask
# 模型预测
with torch.no_grad():
outputs = model(**inputs)
logits = outputs.logits # 重建预测结果
# 可视化重建效果
reconstructed = feature_extractor.post_process(logits[0]) 总结:视觉Transformer的进化革命
技术突破亮点
-
稀疏动态计算
- Token剪枝实现推理加速3-5倍(72%冗余Token可丢弃)
- 硬件感知设计使移动端ViT延迟<10ms(EdgeViT)
-
跨模态统一架构
- CLIP实现图文语义对齐(40亿参数模型识别1.8万类)
- 零样本能力颠覆传统分类范式
-
自监督新范式
- BEiT掩码重建使数据效率↑300%
- VideoMAE视频模型用1%标记数据达全监督精度
核心算法演进
| 技术方向 | 代表算法 | 突破点 |
|---|---|---|
| 稀疏计算 | DynamicViT | 学习型令牌重要性评估 |
| EViT | 硬件感知稀疏加速 | |
| 跨模态 | ALIGN | 超大规模图文对比 |
| Florence | 通用视觉表征模型 | |
| 自监督 | MaskFeat | HOG特征重建 |
| MAE | 80%掩码率预训练 |
未来发展方向
-
神经-符号融合
- 将逻辑规则注入Transformer(符号引导的注意力)
-
三维视觉理解
- 点云Transformer (Point-BERT)
- 神经辐射场优化 (NeRF-ViT)
-
生物启发架构
- 脉冲神经网络融合 (Spiking-ViT)
- 视网膜感知注意力机制
终极愿景:视觉Transformer正在演进为通用感知引擎。未来的视觉模型将兼具物理世界的理解力、人类级别的认知效率,以及多模态无缝交互能力,成为真正意义上的「机器之眼」。从像素到语义,从静态到动态,从识别到创造——视觉智能的革命才刚刚开始。

















 608
608

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









