







1、卷积神经网络在图片识别上的应用
(1)局部性:对一张照片而言,需要检测图片中的局部特征来决定图片的类别
(2)相同性:可以用同样的模式去检测不同照片的相同特征,只不过这些特征处于图片中不同的位置,但是特征检测所做的操作是不变的
(3)不变性:对于一张大图片,如果我们进行下采样,图片的性质基本保持不变
2、全连接神经网络处理大尺寸图像的缺点:
(1)首先将图像展开为向量会丢失空间信息;
(2)其次参数过多效率低下,训练困难;
(3)同时大量的参数也很快会导致网络过拟合。
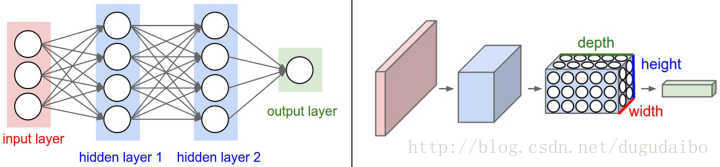
3、卷积神经网络
主要由这几类层构成:输入层、卷积层,ReLU层、池化(Pooling)层和全连接层
(1)卷积层的作用:做特征提取
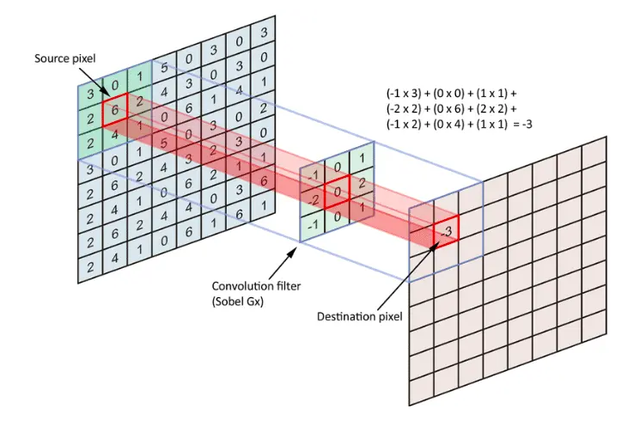
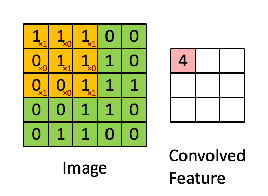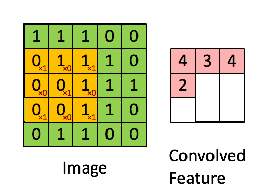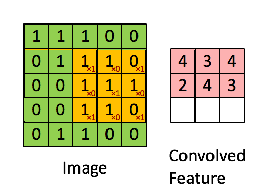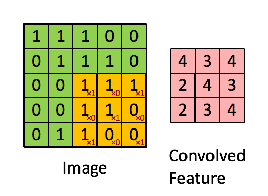
只需要定义移动的步长,我们就可以遍历图像中的所有点,比如定义步长为1,遍历过程如下图所示
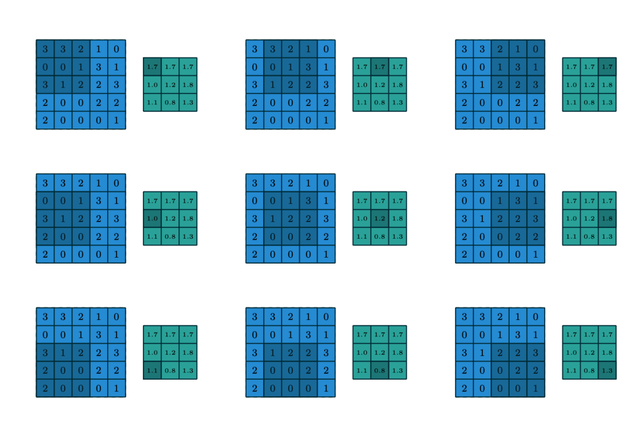
上述过程是基于无填充的情况,在有填充的情况下,对于图像边缘的点,会用0填充,示意如下
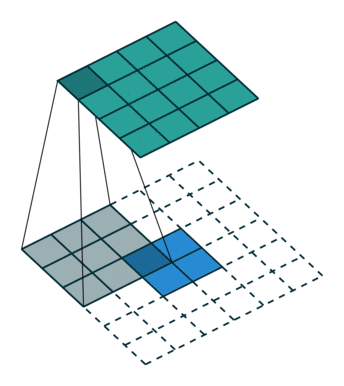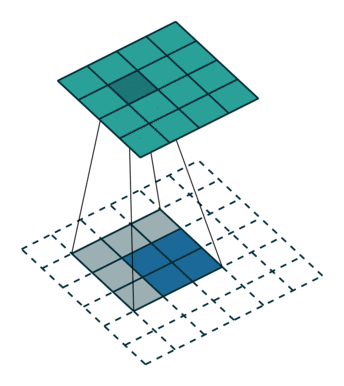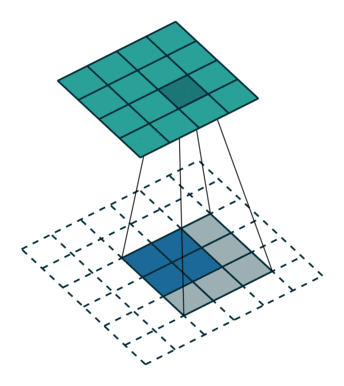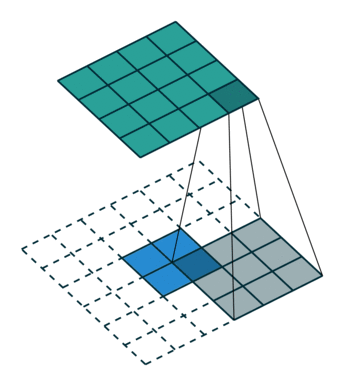
遍历所有点从而得到一张新的图,这样的图称之为特征图,示例如下
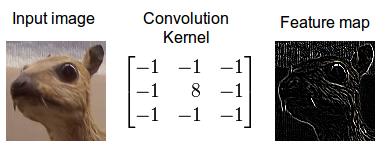
所以卷积层是用来做特征提取的。
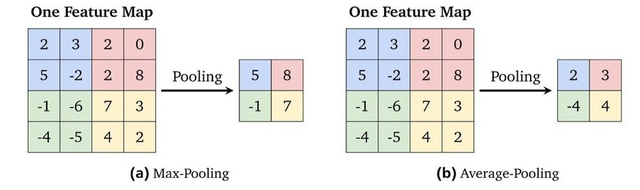
(2)池化层作用:(下采样计数)
去除特征图中的冗余信息,降低特征图的维度,减少网络中参数的数量,有效控制过拟合
4、卷积神经网络实现手写数字识别
(1)CNN
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torchvision import datasets, transforms
import torchvision
from torch.autograd import Variable
from torch.utils.data import DataLoader
import cv2
# 数据集加载
train_dataset = datasets.MNIST(
root='./num/',
train=True,
transform=transforms.ToTensor(),
download=True
)
test_dataset = datasets.MNIST(
root='./num/',
train=False,
transform=transforms.ToTensor(),
download=True
)
batch_size = 64
train_loader = torch.utils.data.DataLoader(
dataset=train_dataset,
batch_size=batch_size,
shuffle=True
)
test_loader = torch.utils.data.DataLoader(
dataset=test_dataset,
batch_size=batch_size,
shuffle=True
)
# 单批次数据预览
# 实现单张图片可视化
images, labels = next(iter(train_loader))
img = torchvision.utils.make_grid(images)
img = img.numpy().transpose(1, 2, 0)
std = [0.5, 0.5, 0.5]
mean = [0.5, 0.5, 0.5]
img = img * std + mean
print(labels)
cv2.imshow('win', img)
key_pressed = cv2.waitKey(0)
# 神经网络模块
class CNN(nn.Module):
def __init__(self):
super(CNN, self).__init__()
self.layer1 = nn.Sequential(
nn.Conv2d(1, 16, kernel_size=3),
nn.BatchNorm2d(16),
nn.ReLU(inplace=True)
)
self.layer2 = nn.Sequential(
nn.Conv2d(16, 32, kernel_size=3),
nn.BatchNorm2d(32),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=2, stride=2)
)
self.layer3 = nn.Sequential(
nn.Conv2d(32, 64, kernel_size=3),
nn.BatchNorm2d(64),
nn.ReLU(inplace=True)
)
self.layer4 = nn.Sequential(
nn.Conv2d(64, 128, kernel_size=3),
nn.BatchNorm2d(128),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=2, stride=2)
)
self.fc = nn.Sequential(
nn.Linear(128 * 4 * 4, 1024),
nn.ReLU(inplace=True),
nn.Linear(1024, 128),
nn.ReLU(inplace=True),
nn.Linear(128, 10)
)
def forward(self, x):
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
x = x.view(x.size(0), -1)
x = self.fc(x)
return x
# 训练模型
if torch.cuda.is_available():
device = 'cuda'
else:
device = "cpu"
net = CNN().to(device)
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(params=net.parameters(), lr=1e-3)
epoch = 1
if __name__ == '__main__':
arr_loss = []
for epoch in range(epoch):
sum_loss = 0.0
for i, data in enumerate(train_loader):
inputs, labels = data
inputs, labels = Variable(inputs).to(device), Variable(labels).to(device)
optimizer.zero_grad() # 将梯度归零
outputs = net(inputs) # 将数据传入网络进行前向运算
loss = criterion(outputs, labels) # 得到损失函数
loss.backward() # 反向传播
optimizer.step() # 通过梯度做一步参数更新
# print(loss)
sum_loss += loss.item()
if i % 100 == 99:
arr_loss.append(sum_loss)
print('[%d,%d] loss:%.03f' %
(epoch + 1, i + 1, sum_loss / 100))
sum_loss = 0.0
x = [1,2,3,4,5,6,7,8,9]
y = arr_loss
plt.plot(x, y)
plt.show()
net.eval() # 将模型变换为测试模式
correct = 0
total = 0
for data_test in test_loader:
images, labels = data_test
images, labels = Variable(images).to(device), Variable(labels).to(device)
output_test = net(images)
_, predicted = torch.max(output_test, 1)
total += labels.size(0)
correct += (predicted == labels).sum()
print("correct1: ", correct)
print("Test acc: {0}".format(correct.item() /
len(test_dataset)))
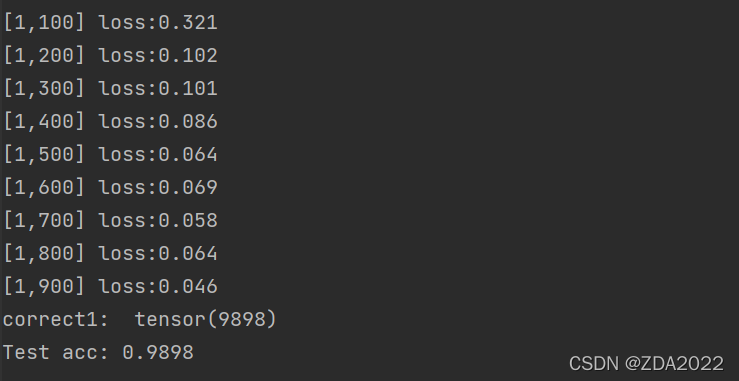
准确率98.98%
(2)LeNet
class LeNet(nn.Module):
def __init__(self):
super(LeNet, self).__init__()
self.layer1 = nn.Sequential(
nn.Conv2d(1, 6, 3, padding=1),
nn.MaxPool2d(2, 2)
)
self.layer2 = nn.Sequential(
nn.Conv2d(6, 16, 5),
nn.MaxPool2d(2, 2)
)
self.layer3 = nn.Sequential(
nn.Linear(400, 120),
nn.Linear(120, 84),
nn.Linear(84, 10)
)
def forward(self, x):
x = self.layer1(x)
x = self.layer2(x)
x = x.view(x.size(0), -1)
x = self.layer3(x)
return x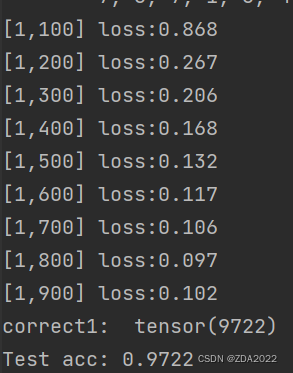
准确率:97.22%
(3)AlexNet
class AlexNet(nn.Module):
def __init__(self):
super(AlexNet, self).__init__()
self.layer1 = nn.Sequential( # 输入1*28*28
nn.Conv2d(1, 32, kernel_size=3, padding=1), # 32*28*28
######################################################
# in_channels:输入数据深度
# out_channels:输出数据深度
# kernel_size:卷积核大小,也可以表示为(3,2)
# stride: 滑动步长
# padding: 是否零填充
######################################################
# nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=2, stride=2), # 32*14*14
nn.Conv2d(32, 64, kernel_size=3, padding=1), # 64*14*14
# nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=2, stride=2), # 64*7*7
nn.Conv2d(64, 128, kernel_size=3, padding=1), # 128*7*7
# nn.ReLU(inplace=True),
nn.Conv2d(128, 256, kernel_size=3, padding=1), # 256*7*7
# nn.ReLU(inplace=True),
nn.Conv2d(256, 256, kernel_size=3, padding=1), # 257*7*7
# nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2) # 256*3*3
)
self.layer2 = nn.Sequential(
nn.Dropout(),
nn.Linear(256 * 3 * 3, 1024),
nn.ReLU(inplace=True),
nn.Dropout(),
nn.Linear(1024, 512),
nn.ReLU(inplace=True),
nn.Linear(512, 10)
)
def forward(self, x):
x = self.layer1(x)
x = x.view(x.size(0), 256 * 3 * 3)
x = self.layer2(x)
return x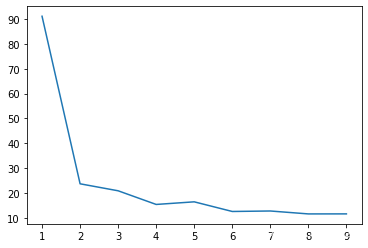

准确率:98.25%
(4)VGG
class VGG(nn.Module):
def __init__(self):
super(VGG, self).__init__()
self.layer1 = nn.Sequential( # 输入1*28*28
nn.Conv2d(1, 32, kernel_size=3, padding=1), # 32*28*28
nn.ReLU(inplace=True),
nn.Conv2d(32, 32, kernel_size=3, padding=1), # 32*28*28
nn.ReLU(True),
nn.MaxPool2d(kernel_size=2, stride=2), # 32*14*14
nn.Conv2d(32, 64, kernel_size=3, padding=1), # 64*14*14
nn.ReLU(True),
nn.Conv2d(64, 64, kernel_size=3, padding=1), # 64*14*14
nn.ReLU(True),
nn.MaxPool2d(kernel_size=2, stride=2), # 64*7*7
nn.Conv2d(64, 128, kernel_size=3, padding=1), # 128*7*7
nn.ReLU(True),
nn.Conv2d(128, 128, kernel_size=3, padding=1), # 128*7*7
nn.ReLU(True),
nn.Conv2d(128, 256, kernel_size=3, padding=1), # 256*7*7
nn.ReLU(True),
nn.MaxPool2d(kernel_size=3, stride=2), # 256*3*3
)
self.layer2 = nn.Sequential(
nn.Linear(256 * 3 * 3, 1024),
nn.ReLU(True),
nn.Dropout(),
nn.Linear(1024, 1024),
nn.ReLU(True),
nn.Dropout(),
nn.Linear(1024, 10)
)
def forward(self, x):
x = self.layer1(x)
x = x.view(x.size(0), 256 * 3 * 3)
x = self.layer2(x)
return x 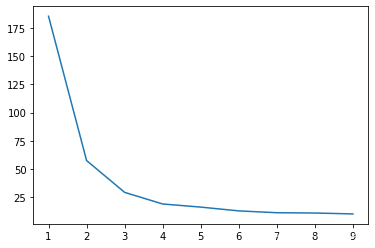

准确率98.52%
(5)GoogLeNet
class InceptionA(torch.nn.Module):
def __init__(self,in_channels):
super(InceptionA,self).__init__()
self.branch1x1 = torch.nn.Conv2d(in_channels,16,kernel_size=1)
self.branch5x5_1 = torch.nn.Conv2d(in_channels,16,kernel_size=1)
self.branch5x5_2 = torch.nn.Conv2d(16,24,kernel_size=5,padding=2)
self.branch3x3_1 = torch.nn.Conv2d(in_channels,16,kernel_size=1)
self.branch3x3_2 = torch.nn.Conv2d(16,24,kernel_size=3,padding=1)
self.branch3x3_3 = torch.nn.Conv2d(24,24,kernel_size=3,padding=1)
# self.branch_pool_1 = torch.nn.functional.avg_pool2d(in_channels,kernel_size=3,stride=1,padding=1)
self.branch_pool_2 = torch.nn.Conv2d(in_channels,24,kernel_size=1)
def forward(self,x):
branch1x1 = self.branch1x1(x)
branch5x5_1 = self.branch5x5_1(x)
branch5x5_2= self.branch5x5_2(branch5x5_1)
branch3x3_1 = self.branch3x3_1(x)
branch3x3_2 = self.branch3x3_2(branch3x3_1)
branch3x3_3 = self.branch3x3_3(branch3x3_2)
branch_pool_1 = F.avg_pool2d(x, kernel_size=3, stride=1, padding=1)
branch_pool_2 = self.branch_pool_2(branch_pool_1)
outputs = torch.cat([branch1x1,branch5x5_2,branch3x3_3,branch_pool_2],dim=1)
return outputs
class Net(torch.nn.Module):
def __init__(self):
super(Net,self).__init__()
self.conv1 = torch.nn.Conv2d(1,10,kernel_size=5)
self.conv2 = torch.nn.Conv2d(88,20,kernel_size=5)
self.incep1 = InceptionA(in_channels=10)
self.incel2 = InceptionA(in_channels=20)
self.mp = torch.nn.MaxPool2d(2)
self.fc = torch.nn.Linear(1408,10)
def forward(self,x):
batch_size = x.size(0)
x = F.relu(self.mp(self.conv1(x)))#1 =》10
x = self.incep1(x) #10 => 88
x = F.relu(self.mp(self.conv2(x)))
x = self.incel2(x)
x = x.view(batch_size,-1)
x = self.fc(x)
return x
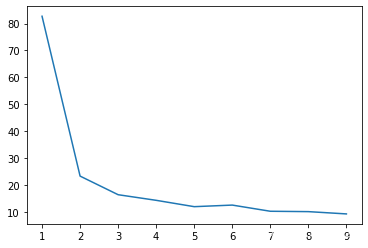
![]()
准确率:97.35%















 6271
6271











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









