









目录

知识扩展
Attention机制最早在视觉领域提出
2014年Google Mind 发表 Recurrent Models of Visual Attention
2015年,Bahdanau等人在论文《Neural Machine Translation by Jointly Learning to Align and Translate》中,将attention机制首次应用在nlp领域,其采用Seq2Seq+Attention模型来进行机器翻译,并且得到了效果的提升,Seq2Seq With Attention中进行了介绍。
2017 年,Google 机器翻译团队发表的《Attention is All You Need》中,完全抛弃了RNN和CNN等网络结构,而仅仅采用Attention机制来进行机器翻译任务,并且取得了很好的效果,注意力机制也成为了大家近期的研究热点。
本文首先介绍常见的Attention机制,然后对论文《Attention is All You Need》进行介绍,该论文发表在NIPS 2017上。
Attention 机制
注意力机制是一种模仿人类视觉系统的关注机制,允许模型在处理输入数据时专注于其中的重要部分,而忽略无关的部分。这种机制最初是在自然语言处理任务中引入的,但后来在计算机视觉、语音识别和其他领域也被广泛应用。
循环模型通常沿着输入和输出序列的符号位置进行计算。将位置与计算时间中的步骤对齐,通过先前的隐状态和位置时刻的输入生成当前时刻的隐状态ht 。(这种固有的顺序性质阻碍了训练实例中的并行化)
即:序列数据的本质是有序的,因此处理长序列时,模型无法在训练样本内部进行并行化处理。(处理长序列时,计算机的内存限制将限制跨样本进行批处理。模型无法同时处理序列中不同位置或时间步的信息,必须按顺序逐个处理。)
RNN无法实现并行,速度慢(递归的天然缺陷)。另外,RNN无法很好学习到全局结构信息,因为它类似是一个马尔科夫决策过程。
当前一些处理技巧:
Zhouhan Lin, Minwei Feng, Cicero Nogueira dos Santos, Mo Yu, Bing Xiang, Bowen Zhou, and Yoshua Bengio. A structured self-attentive sentence embedding. arXiv preprint arXiv:1703.03130, 2017. (分解技巧)
Noam Shazeer, Azalia Mirhoseini, Krzysztof Maziarz, Andy Davis, Quoc Le, Geoffrey Hinton, and Jeff Dean. Outrageously large neural networks: The sparsely-gated mixture-of-experts layer. arXiv preprint arXiv:1701.06538, 2017. (条件计算)
但仍无法改变模型顺序计算的本质。
RNN 逐步递归获得全局信息,因此一般要双向 RNN 才比较好;CNN 事实上只能获取局部信息,是通过层叠来增大感受野,实现全局特征获取;
注意力机制的优点
注意力机制提供了一种有效的方法,使模型能够在处理序列数据时聚焦与最相关的部分,而不必受制于固定窗口或固定的权重分配。允许模型在不考虑输入或输出序列中元素之间距离的情况下建模他们之间的依赖关系,即模型可以自适应地调整关注的焦点。
传统模型中(RNN、CNN)往往只考虑固定窗口内的信息,而注意力机制可以在全局范围内动态地捕获序列中的重要信息。
除了少数情况,注意力机制都和循环网络结合使用。
Transformer 结构
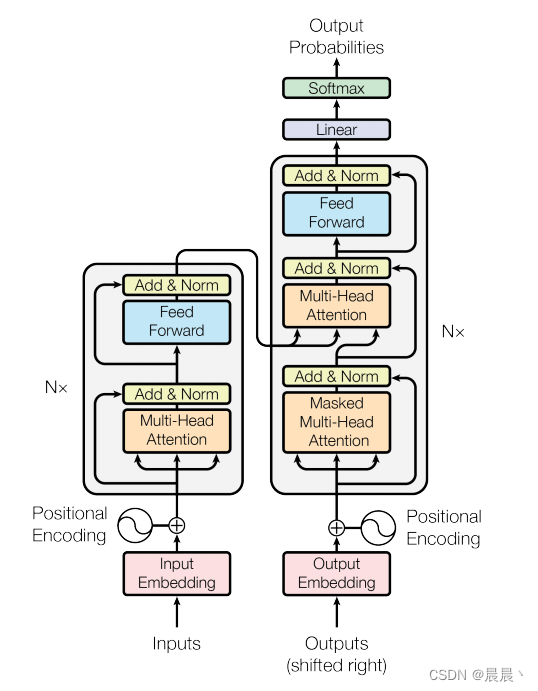
左:编码 右:解码
编码器
由6(N=6)个相同层的堆叠组成,每个层有两个子层组成(多头自注意力机制和位置智能的全连接前馈网络)。两个子层周围采用残差连接,每个子层间都进行归一化连接。
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 770–778, 2016.(残差连接)
每一个子层的输出都是 LayerNorm(x + Sublayer(x)),其中Sublayer(·)是层本身实现的函数。LayerNorm(·)为正则化
(作者:为了促进残差连接,模型中的所有子层(包括嵌入的层)都会生成维度为512的输出)
总结:编码模块由N个编码器层堆叠而成,每个编码器层由一个多头子注意力子层和一个前馈全连接子层构成。每个子层的输出处添一个正则化,表示为LayerNorm(x + Sublayer(x)),x表示该子层的输入,Sublayer(·)表示该子层的实现。
解码器
解码器也由6(N=6)个相同的层堆叠组成。除了编码层中的两个子层之外,解码器插入第三个层--掩蔽多头注意力。与之前相同,每个子层周围使用残差连接,每个子层的输出都添加层正则化。
掩蔽多头注意力层用来防止当前位置关注后续位置,以确保位置i处的预测只能依赖于位置小于i的已知输出。
注意力机制
注意力函数可以理解为将查询(query)和一组键和值(keys - values)对应到输出。query、keys和values都为向量。输出是作为values的加权和计算的,其中分配给每个值的权重是由查询与相应键的兼容性函数计算的。
具体来讲:
| 查询-query | 表示模型当前关注或查询的信息的向量 |
| 键-key | 一组表示上下文或其他信息片段的向量 |
| 值-value | 另一组表示与键关联的值或内容的向量 |
兼容性函数:用来衡量查询与每个键之间的匹配程度,该函数生成一个分数,表示查询和键之间的相似性或关联性。
加权求和:从兼容性函数得到的分数用于计算每个值的权重,较高的分数意味着更高的重要性。
最终的输出被计算为值的加权和,意味着与查询更相关或兼容的值对输出的贡献更大。
总体而言:注意力函数使模型能够基于查询与相应键之间的相似性选择性地关注输入(值)的不同部分。输出中分配给值的权重取决于键与查询的匹配程度,使模型能够有选择地关注相关信息。在涉及序列数据或处理数据中的长距离依赖性的任务中,这种机制非常重要。
各模块详解
单头注意力机制
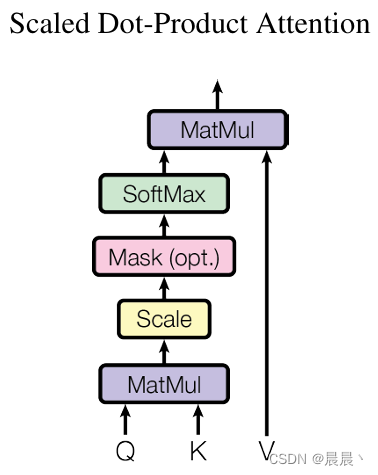
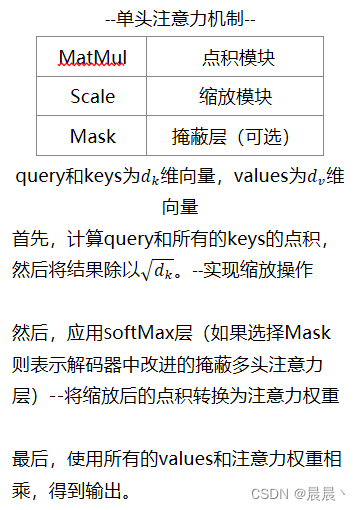
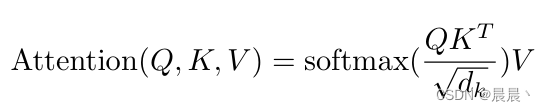

注:相比于加性注意力(使用前馈网络计算兼容函数),乘性注意力在计算上更具优势(使用矩阵乘法)
注意力机制的总结
注意力机制允许模型在处理输入(如一句话中的单词或一篇文章中的句子)时,对不同部分赋予不同的重要性。简单来说,它可以让模型“关注”对当前任务最相关的信息部分。在这个过程中,所谓的“单头注意力”机制通过计算查询(query)、键(key)和值(value)之间的关系来实现,这三个概念是注意力机制的核心。每个元素对于其它元素的重要性通过一个权重分数来表示,这个分数决定了在输出中应该给予每个元素多少“注意力”。
多头注意力机制
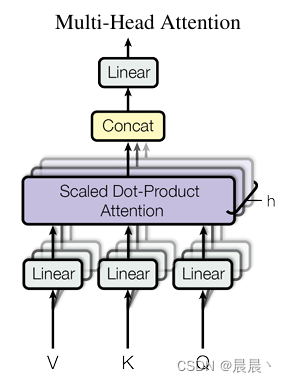
在原有单头注意力机制的基础上,Google提出了多头注意力的概念。
优点:多头注意允许模型共同注意来自不同表示的信息不同位置的子空间。单头注意力机制中的平均会抑制这个问题。
对于多头注意力机制的一些理解:在单注意力头的情况下,模型只能学习到一种固定的查询-键(Q-K)的关系映射方式。这意味着只能捕获一种类型的信息或依赖(例如只捕获到单词之间的语法关系)。
引入多头注意力,模型可以同时学习到多种不同的Q-K映射关系,每个“头”关注输入数据的不同方面或表示子空间,从而获取更丰富的信息。
同理,多头也意味着模型可以捕捉到数据不同位置间的复杂关系。
平均化问题:在使用单头注意力机制时,模型需要在计算最终输出时对不同位置的注意力权重进行平均化处理,平均化的过程会淡化或抹去某些重要信息。
多头注意力机制的流程:首先,将Q、K、V矩阵通过线性投影映射一下。然后,同单头Attention一样,将这个过程重复h次。最后,将结果拼接起来再进行以此线性投影得到映射后的结果。
具体来说:
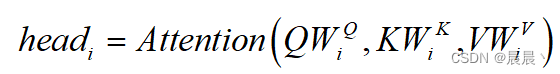
![]()
小结
- 在编码-解码器注意层中,Q来自前一个解码器,而记忆的键和值来自编码器的输出。(允许解码器中的每个位置都参与输入序列中的所有位置--模仿Seq to Seq中的编码-解码器注意力机制)
- 编码器中自注意力层:Q,K,V都来自同一个地方,即编码器前一层的输出。此时,编码器中的每个位置都能关注到编码器前一层中的所有位置。
- 解码器的自注意力层:类似地,解码器的自注意力层允许每个位置关注到解码器中直到该位置为止的所有位置。为了保持自回归属性,需要防止信息在解码器中向左流动。通过在缩放点积注意力中屏蔽(设置为-∞)softmax输入中对应于非法连接的所有值来实现这一点。
自回归属性:确保在生成序列的每一步中,模型只能使用之前的输出作为输入。
注意力机制:无论是自注意力还是编码器-解码器注意力,核心思想都是通过计算“查询”与“键”的相似度,来决定如何组合“值”,这使得模型能够动态地聚焦于输入数据的不同部分。
Position Embedding
目前为止,Attention模型还无法捕捉序列的顺序。(即将K,V按行打乱顺序,Attention的结果还是一样的)
为此,引入Position Embedding,即位置向量,将每个位置编号,然后每个编号对应一个向量。通过结合位置向量和词向量,实现为每个词引入位置信息,这样Attention就可以分辨出不同位置的词。
与FaceBook的 Convolutional Sequence to Sequence Learning 中用到的位置向量不同,Google有几点区别:
- 以前在 RNN、CNN 模型中其实都出现过 Position Embedding,但在那些模型中,Position Embedding 是锦上添花的辅助手段,也就是“有它会更好、没它也就差一点点”的情况,因为 RNN、CNN 本身就能捕捉到位置信息。而Attention中,Position Embedding是位置信息的唯一来源,因此为核心成分。
- 在以往的 Position Embedding 中,基本都是根据任务训练出来的向量。而 Google 直接给出了一个构造 Position Embedding 的公式。
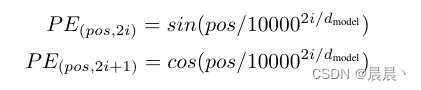


详细理解
位置嵌入(Position Embedding)的目的
在处理语言或者任何序列数据时,理解序列中每个元素(例如单词)的位置是非常重要的。比如,在句子“我不喜欢苹果,我喜欢香蕉。”中,单词“不喜欢”和“喜欢”出现的顺序改变了句子的意思。但是,一些深度学习模型,特别是 Transformer,它们本身并不会关注输入序列中的顺序信息。为了让模型理解这种顺序信息,我们需要一种方法来表达每个单词的位置,这就是位置嵌入的用途。
表达方式
位置嵌入的一个常见方法是用一组数学公式来创建一种模式,这种模式可以唯一地表示每个位置。在 Transformer 模型中,用一种特殊的方式使用正弦(sin)和余弦(cos)函数来创建这样的模式。
为什么使用这两个函数?因为它们有一个很好的性质:即使序列很长,它们的输出值也会周期性地变化。这意味着我们可以用它们来生成一种模式,这种模式随着序列的位置变化而变化,但又不会随着序列的增长而失去效果。
使用正余弦函数位置编码的好处:
唯一性:序列中的每个位置都会有一个独特的编码。
周期性:对于非常长的序列,这些函数仍然能够生成有效的位置信息。
连续性:位置编码在多维空间中是连续的,有助于模型了解位置之间的相对关系。
代码实现:
https://github.com/bojone/attention/blob/master/attention_tf.py
参考资源:
论文解读:Attention is All you need - 知乎
一文读懂「Attention is All You Need」| 附代码实现 | 机器之心
欢迎大家讨论交流,共同进步!!

















 2124
2124











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











