







目录
1 集群基础概念
1.1 什么是Elasticsearch集群?
Elasticsearch集群是由多个相互协作的节点(Node)组成的分布式系统,具有以下核心特征:
- 统一命名空间:所有节点共享相同的cluster.name配置
- 自动数据分布:索引数据通过分片(Shard)机制分布在多个节点
- 自管理能力:自动节点发现、故障检测和恢复
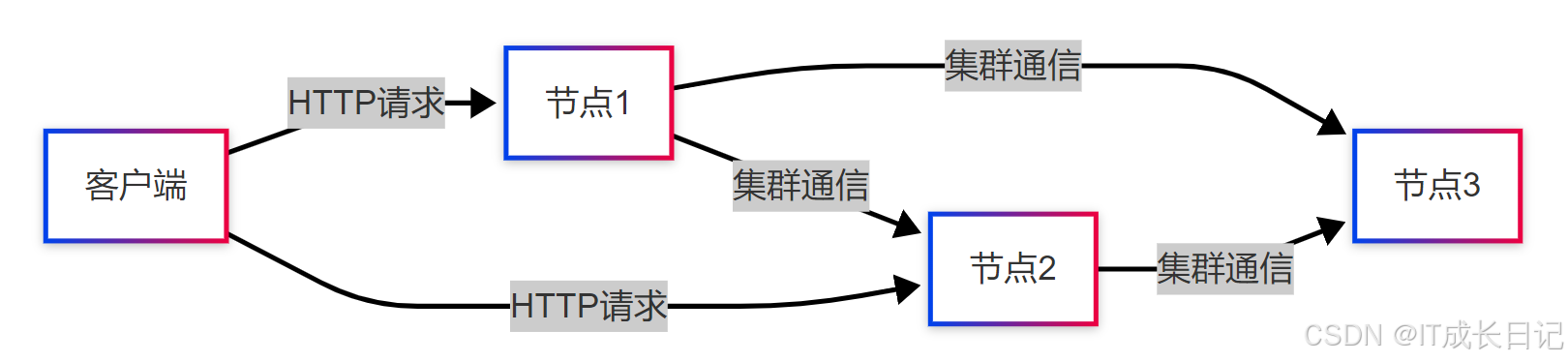
关键组件说明:
- 节点(Node):集群的基本工作单元,承担不同角色(数据/主节点等)
- 索引(Index):逻辑数据分组(类似数据库表)
- 分片(Shard):索引的物理存储单元(主分片+副本分片)
1.2 集群健康状态
- 通过GET _cluster/health可获取关键指标:
{
"cluster_name": "my-cluster",
"status": "green", // green/yellow/red
"number_of_nodes": 3,
"active_primary_shards": 10,
"active_shards": 20
}状态解读:
- Green:所有主分片和副本分片正常
- Yellow:主分片正常但存在未分配的副本
- Red:存在不可用的主分片(数据不完整)
2 集群高可用性保障机制
2.1 多节点容错架构
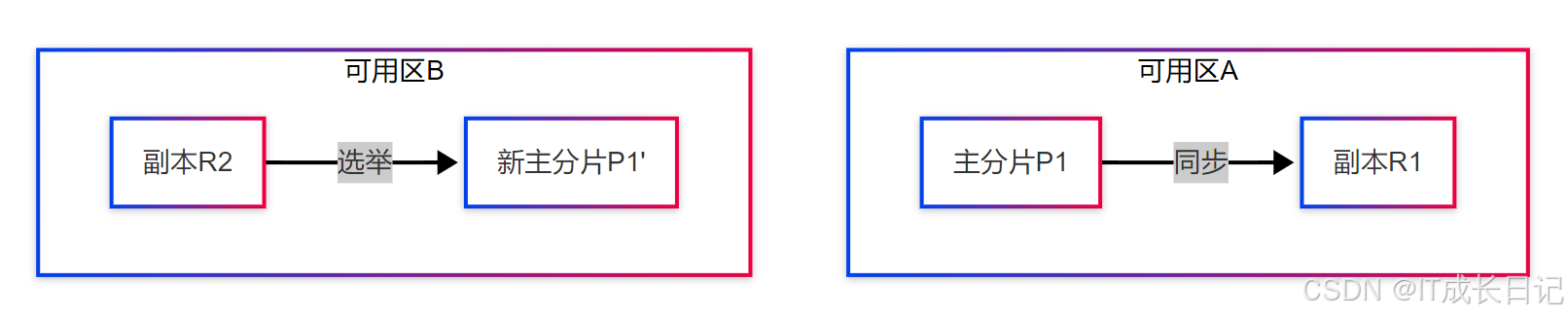
故障恢复流程:
- 节点监测到主分片P1不可用(心跳超时)
- 集群重新选举,副本R2被提升为新主分片
- 自动创建新的副本分片(维持配置的副本数)
- 数据恢复后集群状态转为Green
2.2 分片分配策略
- 分片分布规则:
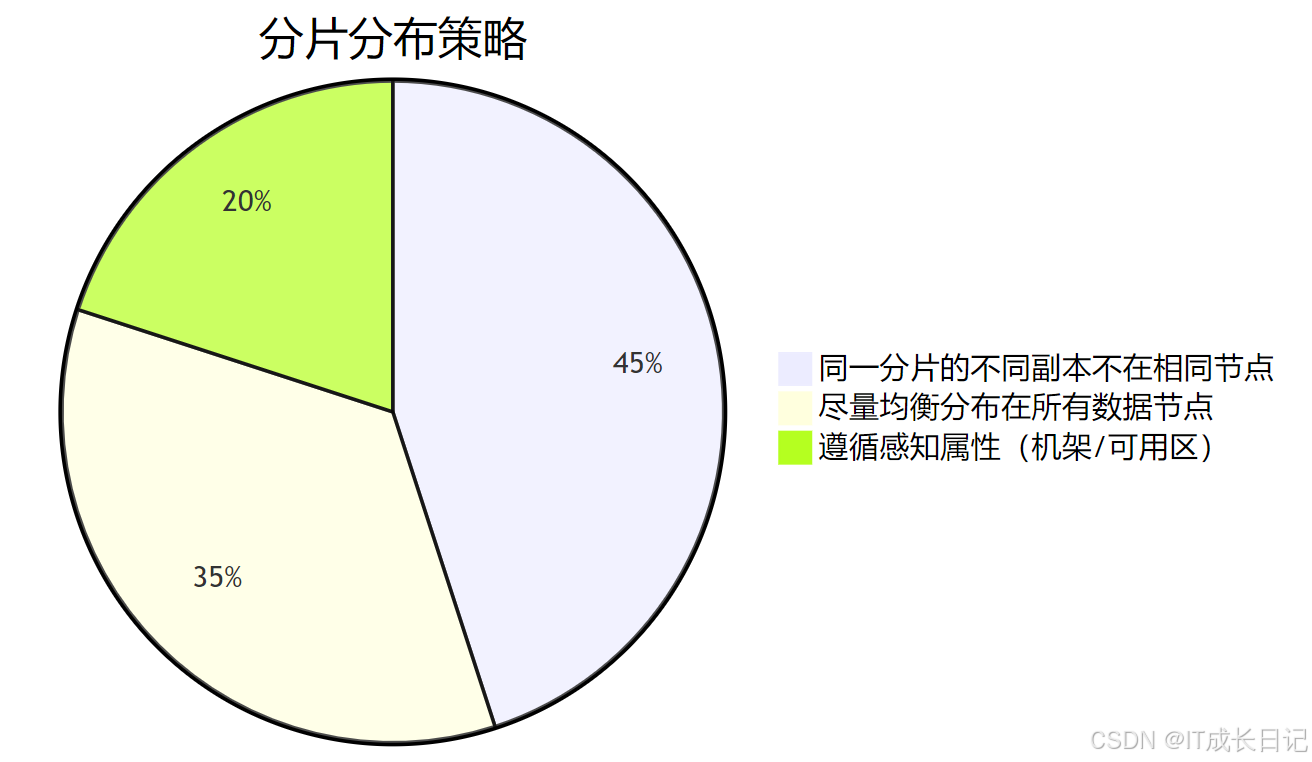
- 通过API强制跨机架分布:
PUT _cluster/settings
{
"persistent": {
"cluster.routing.allocation.awareness.attributes": "rack_id"
}
}2.3 防脑裂(Split-brain)设计
- 主节点选举约束:
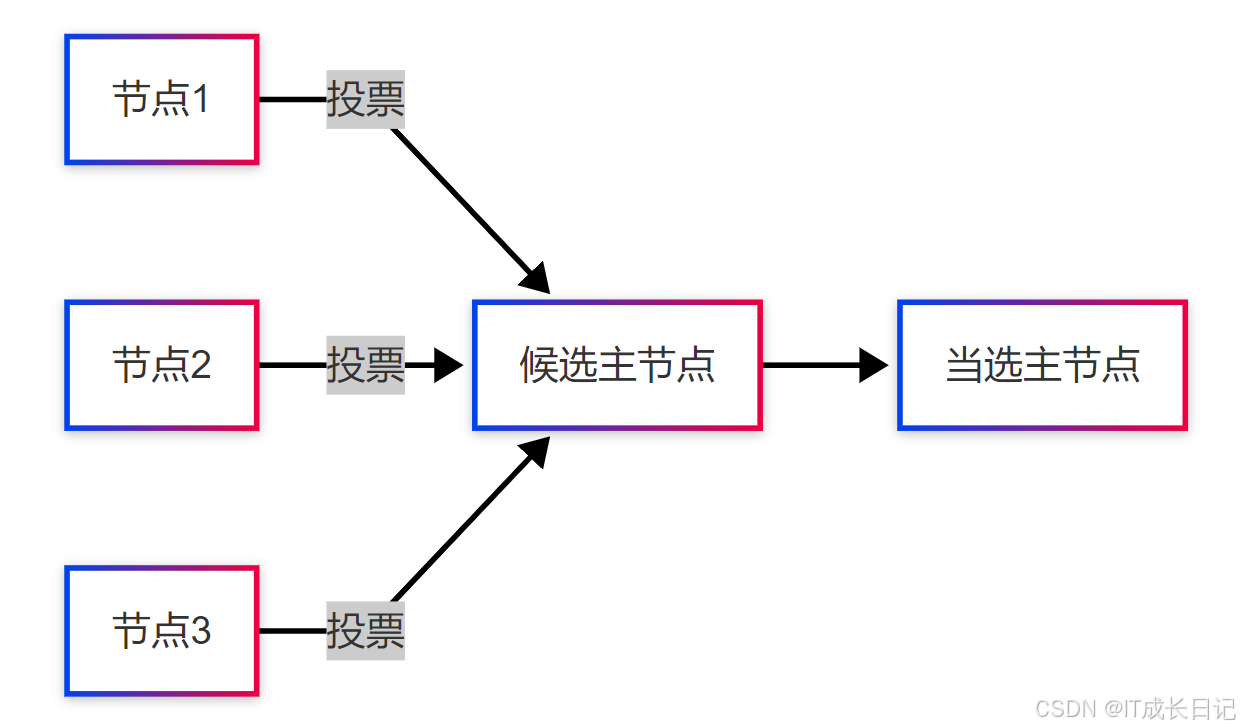
- 关键配置:
# 建议配置为 (master_eligible_nodes / 2) + 1
discovery.zen.minimum_master_nodes: 2
cluster.initial_master_nodes: ["node1", "node2", "node3"]3 生产环境集群规划
3.1 节点角色规划
| 节点类型 | 数量 | 部署建议 |
| 专用主节点 | 3(奇数) | 独立服务器,不运行数据分片 |
| 数据节点 | ≥2 | 高配CPU/内存/SSD存储 |
| 协调节点 | ≥2 | 部署在应用服务器同机房 |
| 机器学习节点 | 按需 | 需要GPU支持时独立部署 |
3.2 跨数据中心部署
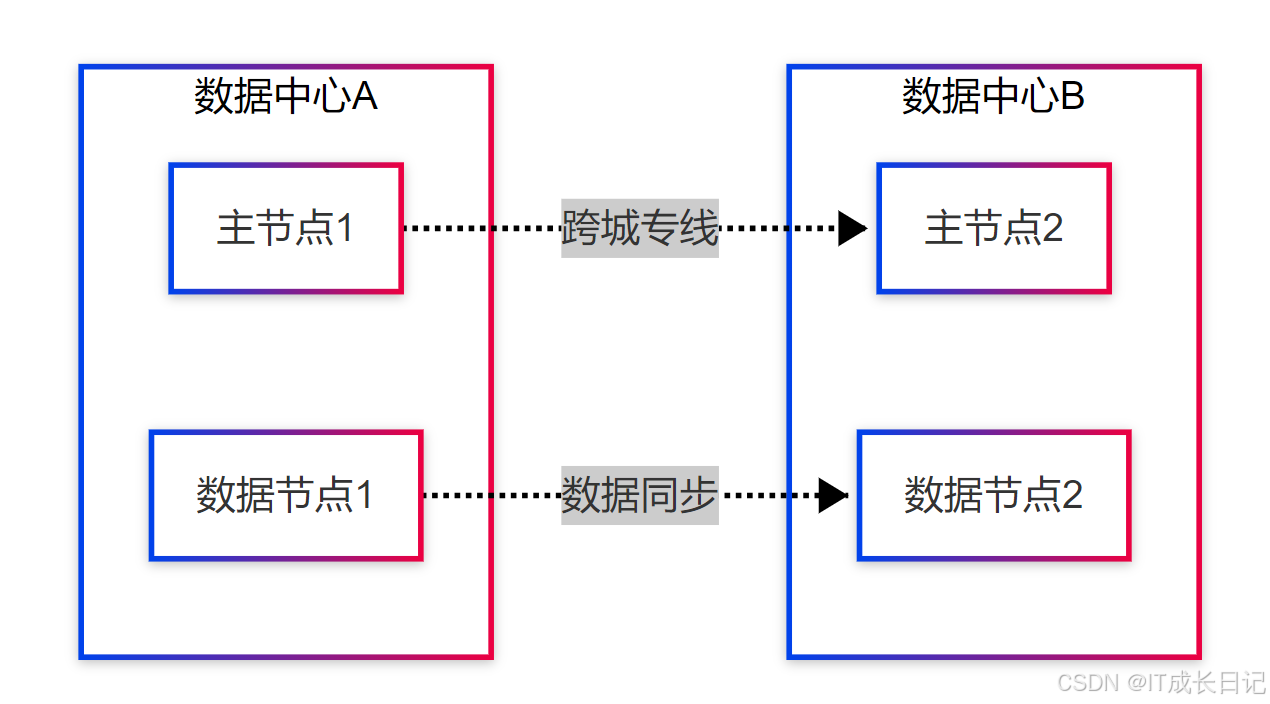
- 配置要点:
PUT _cluster/settings
{
"persistent": {
"cluster.remote.dc2.seeds": ["dc2-node1:9300"],
"cluster.routing.allocation.awareness.attributes": "dc"
}
}3.3 容量规划公式
所需数据节点数 = ⌈总数据量 / (单节点存储容量 × 0.7)⌉
其中:
- 单节点存储容量建议不超过5TB
- 保留30%空间用于合并/扩容4 高可用性运维实践
4.1 集群监控体系
- 关键指标看板:

核心监控项:
- 节点存活状态
- JVM堆内存使用率
- 未分配分片计数
- 索引延迟时间
4.2 滚动重启流程
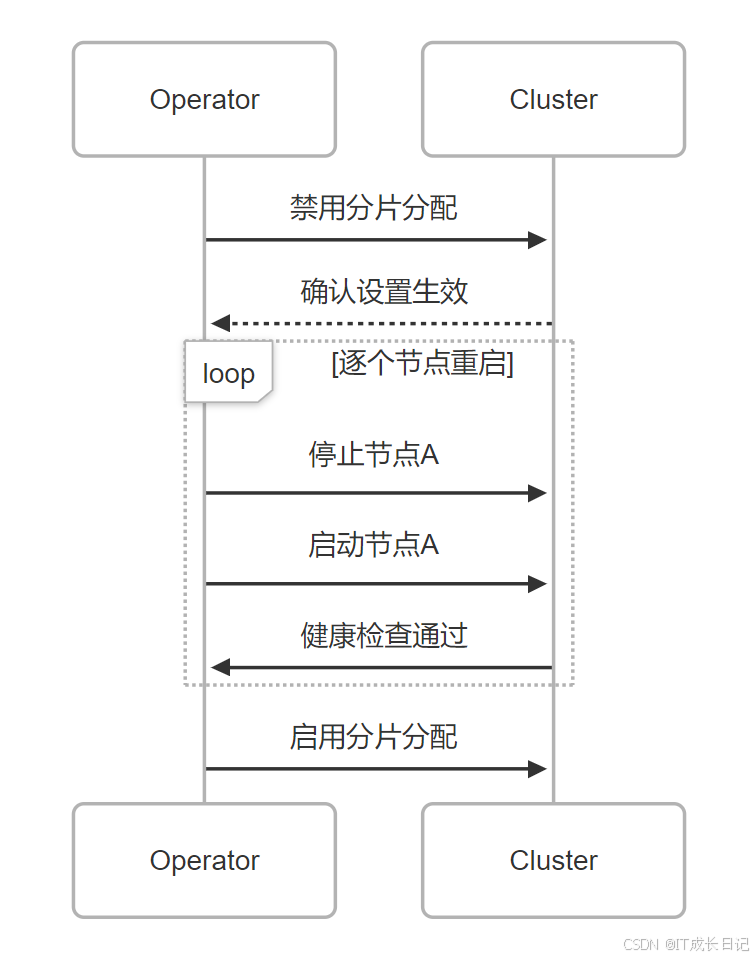
- 具体命令:
# 禁用分配
PUT _cluster/settings
{
"persistent": {
"cluster.routing.allocation.enable": "none"
}
}
# 重新启用
PUT _cluster/settings
{
"persistent": {
"cluster.routing.allocation.enable": "all"
}
}4.3 灾难恢复方案
- 快照备份策略:
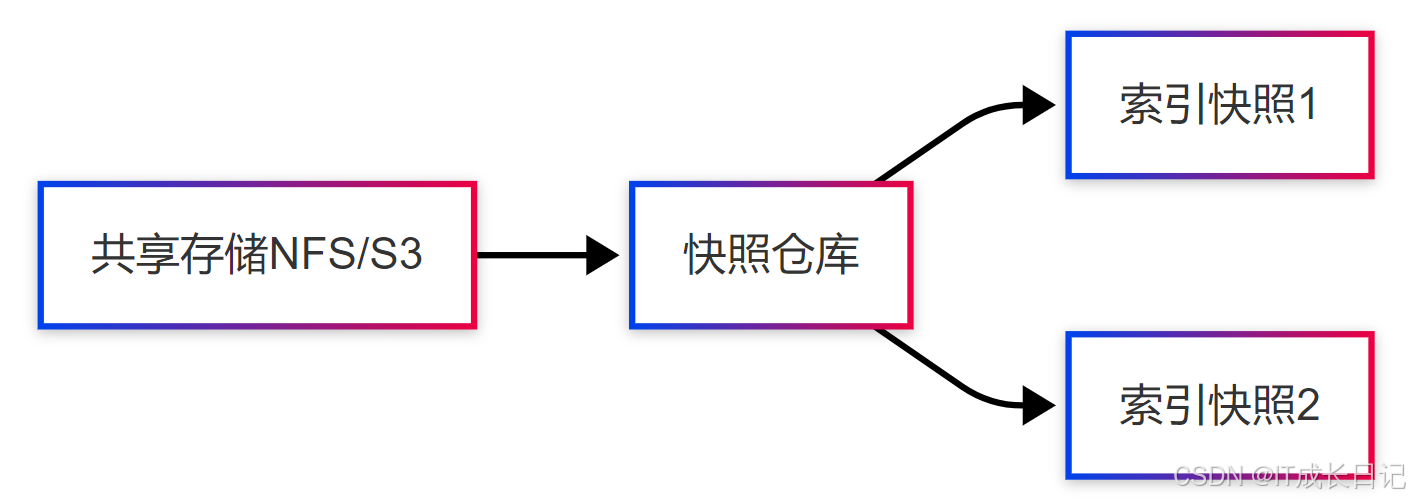
- 备份命令:
PUT _snapshot/my_backup
{
"type": "fs",
"settings": {
"location": "/mnt/backups"
}
}
PUT _snapshot/my_backup/snapshot_1?wait_for_completion=true
{
"indices": "index_1,index_2"
}5 常见问题解决方案
Q1: 集群状态持续为Red怎么办?
- 检查未分配分片原因:
GET _cluster/allocation/explain?pretty- 手动分配主分片(数据丢失风险):
POST _cluster/reroute
{
"commands": [
{
"allocate_empty_primary": {
"index": "my_index",
"shard": 0,
"node": "node-1",
"accept_data_loss": true
}
}
]
}Q2: 如何优化分片分配速度?
- 调整恢复参数:
PUT _cluster/settings
{
"transient": {
"cluster.routing.allocation.node_initial_primaries_recoveries": 4,
"indices.recovery.max_bytes_per_sec": "200mb"
}
}Q3: 节点加入集群失败?
检查网络和配置:
- 确认cluster.name一致
- 验证防火墙规则(9300/TCP开放)
- 检查发现协议配置:
discovery.seed_hosts: ["host1:9300", "host2:9300"]
cluster.initial_master_nodes: ["node1", "node2"]6 总结
高可用集群黄金法则:
- 奇数个专用主节点(3/5/7)防止脑裂
- 每个索引配置≥1副本(生产环境建议2副本)
- 跨机架/可用区部署数据节点
进阶建议:
- 使用index.unassigned.node_left.delayed_timeout控制自动恢复延迟
- 定期执行_cluster/reroute?retry_failed=true清理失败分片
- 通过_cat/shards?v监控分片分布均衡性
掌握Elasticsearch集群的运作原理,才能构建出既可靠又高性能的搜索系统!


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











