







文章地址
原作者解读
B导解析
作者提出HRNet来全程保持高分辨率的图片,传统的结构会通过下采样来减少图片的尺寸,同时增大感受野,再通过上采样进行尺寸的恢复,然而在恢复时候,下采样丢失掉的信息就不能够很好的恢复出来,但是为了获得图像的高层语义特征就必须要通过不断的下采样,为了缓和这个矛盾,作者提出通过保持图像高分辨率的时候,进行下采样,然后将不同尺度的分辨率进行融合,即向低分辨率图片借语义信息。
看一下文章的框架:
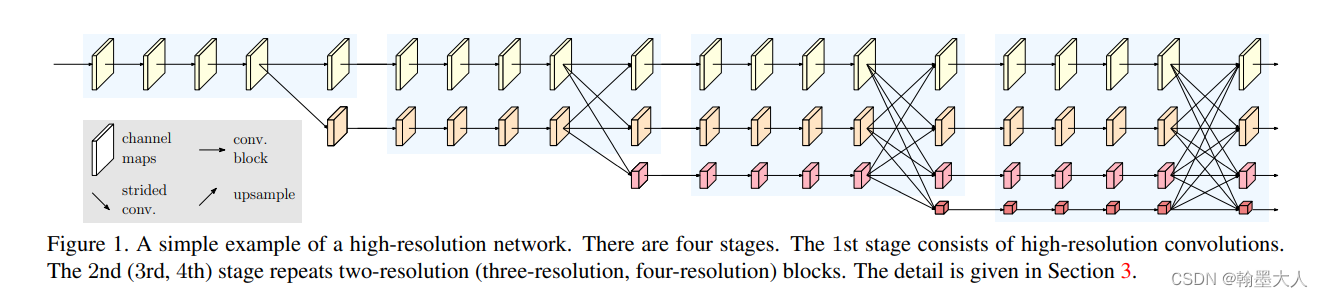
作者在文章和视频中说到,设计网络的初衷就是要保持高分辨率,因此并没有使用分类的框架,因为图像分类任务图片的分辨率比较低,而语义分割是精细度比较高的任务,所以使用分类的框架效果会有损失,而语义分割广泛使用的框架就是分类的框架,比如resnet,vit等,作者这里重新设计了backbone。
看框架分为四个阶段,第一个阶段是高分辨率卷积,即通过3x3卷积,图像大小不变,然后最后一个块有两个支路,下面的支路开始进行下采样。即通过3x3,步长为2的卷积。橙色的块就是resnet的basicblock。
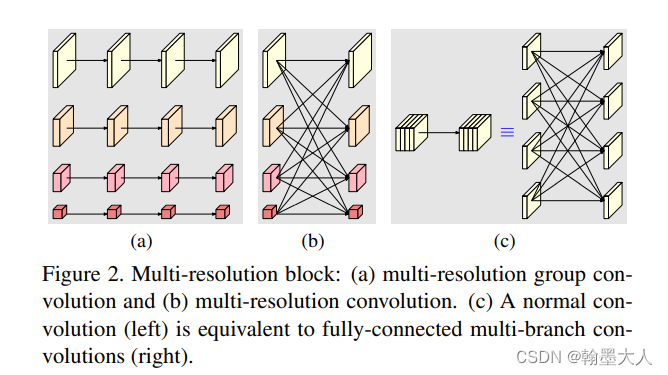
多分辨率块:a可以看做并行的多分辨率支路,b可以看做不同的分辨率进行交互融合,c左边为正常的卷积,可以看做一个全连接的多支路卷积。
根据样子很像全连接层,每一个线条看做卷积的话,那么这就是深度可分离卷积中的逐深度卷积:

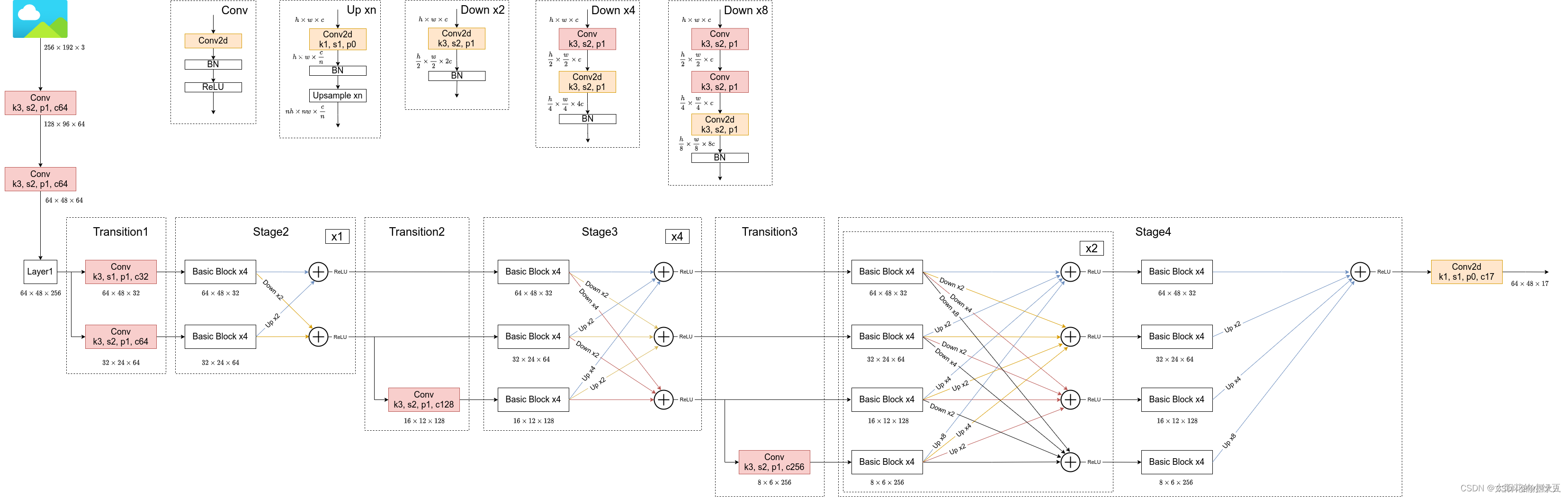
模型的具体设置:图片参考
B站主页
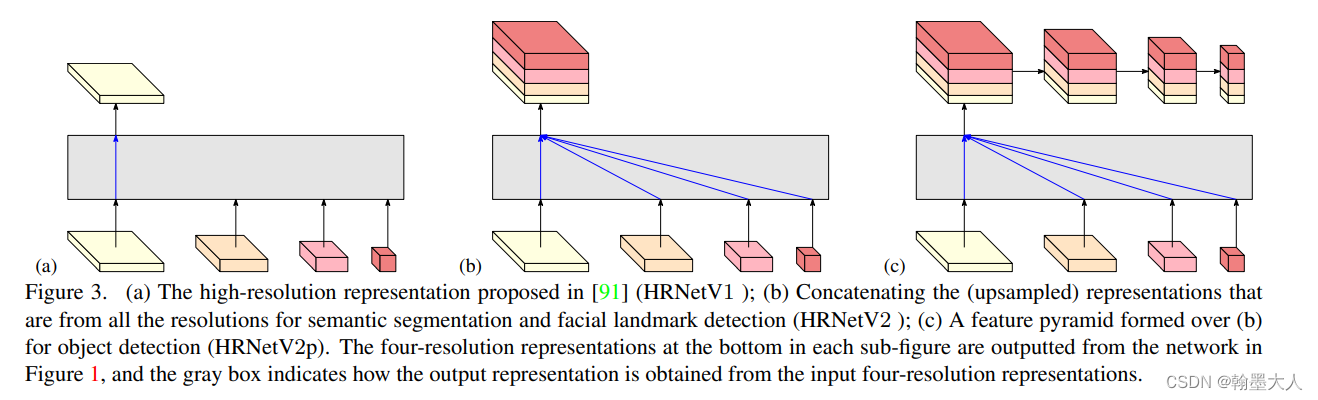
最后生成的四个block我们将它上采样,然后拼接起来。
结果:(只看语义分割)相比deeplabv3和v3+的话,参数量近似的时候,miou有提升的主要是gflops减少了三分之一。相比于pspnet参数量相同的情况下gflops减少了三分之一,miou也有提升。
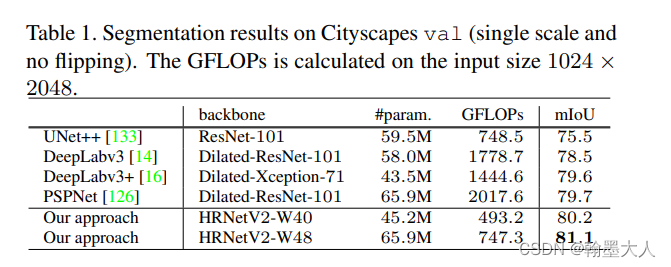
和最新的方法相比:
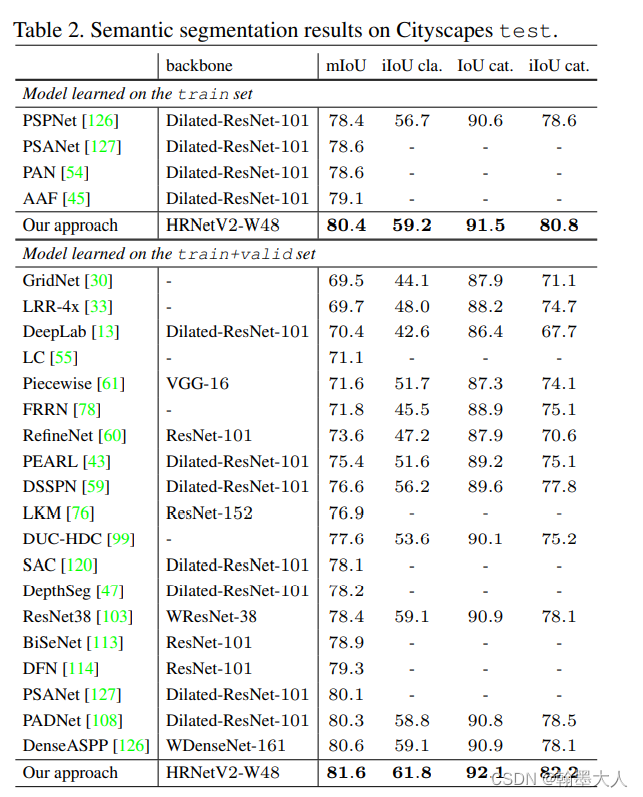
总结:HRNet设计很简单但是很巧妙,对于语义分割来说作为backbone是一个比较好的选择,因为HRnet全程保持了高分辨率,并且也不缺少语义信息,因此避免了信息的丢失,和在上采样时候造成的锯齿和信息恢复不完全。虽然在提取语义信息时候使用了双线性上采样,但是是作为信息的补充,对于原始的图片信息没有任何的降分辨率的操作。















04-08
 7387
7387
7387
09-24
7176
7176
12-24
1616
1616
09-13
“相关推荐”对你有帮助么?
-

 非常没帮助
非常没帮助 -

 没帮助
没帮助 -

 一般
一般 -

 有帮助
有帮助 -

 非常有帮助
非常有帮助
提交

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









