






 本文提出了一种基于强化学习的时序知识图谱推理模型TITer,专注于外推未来事实。TITer通过时间路径建模和时间形状奖励处理看不见的时间戳,使用归纳均值表示来处理新实体,提高了模型的归纳推理能力。这种方法在预测未来链接和处理看不见的实体方面表现优越。
本文提出了一种基于强化学习的时序知识图谱推理模型TITer,专注于外推未来事实。TITer通过时间路径建模和时间形状奖励处理看不见的时间戳,使用归纳均值表示来处理新实体,提高了模型的归纳推理能力。这种方法在预测未来链接和处理看不见的实体方面表现优越。
(基于强化学习的TKG预测)EMNLP 2021
摘要:
大多数现存的方法都侧重于过去时间的推理(TKGC),以完成缺失的事实,只有少数已知的TKG推理工作可以预测未来的事实。
Temporal Knowledge Graph Forecasting(TKGF),面临着两大挑战:
(1)如何有效地对时间信息进行建模以处理未来的时间戳?
(2)如何进行归纳推理来处理随着时间的推移而出现的以前看不见的实体?(对未知实体的处理)
基于此,本文提出强化学习的方法来处理这两种挑战。具体而言:智能体在历史知识图谱快照上旅行以搜索答案。本文的方法定义了一个相对时间编码函数捕获信息的时间跨度,并设计了一种基于狄利克雷分布的新型时间形状奖励来指导模型学习。(1)
此外,我们提出了一种针对看不见的事物的新颖表示方法,以提高模型的归纳推理能力。(2)
1介绍:
时序知识图谱的表示。通常,我们将 TKG 表示为一系列静态 KG 快照。
TKG reasoning is a process of inferring new facts from known facts, which can be divided into two types, interpolation and extrapolation.
专注于插值 TKG 推理,以完成过去时间戳处缺失的事实。
外推 TKG 推理侧重于预测未来事实(事件)。在这项工作中,我们通过设计未来时间戳的链接预测模型来专注于外推 TKG 推理。例如,“勒布朗·詹姆斯将在2022年为哪支球队效力?”可以看作是对未来时间戳的链接预测的查询。(LeBron_James, plays_for, ?, 2022)【本文发表于2021年】。
相较于interpolation,extrapolation的难度在于:(1)看不见的时间戳:待预测事实的时间戳在训练集中不存在。(2)看不见的实体:随着时间的推移,新的实体可能出现,要预测的事实可能包含以前看不见的实体。因此,插值方法不能处理外推任务。
受到基于路径的方法的启发(Das等人,2018;Lin等人,2018【使用强化学习对知识库中的路径进行推理】)对于静态KG,我们提出了一种新的基于时间路径的强化学习(RL)模型,用于外推TKG推理。模型的名称为“TIme Traveler”(TITer),它在历史KG快照上移动,为将来的查询找到答案。
TITer 从查询主题节点开始,根据与当前节点相关的时态事实依次传输到新节点,预计在应答节点处停止。
1.为了处理看不见的时间戳质询,TITer 使用相对时间编码函数在做出决定时捕获时间信息。我们进一步设计了一种基于狄利克雷分布的新颖时间形状(time-shape)奖励,以指导模型捕获时间信息。
2.为了解决看不见的实体,我们引入了一种基于时间路径的框架工作,并提出了一种新的看不见实体的表示机制,称为归纳均值(IM)表示,以提高模型的归纳能力。
本文贡献如下:
1.这是第一个用于外推TKG推理的基于时间路径的强化学习模型,它是可解释的,可以处理看不见的时间戳和看不见的实体。
2.我们提出了一种对时间信息进行建模的新方法。我们利用相对时间编码函数为代理捕获时间信息,并使用时间形状奖励来指导模型学习。
3.我们为看不见的实体提出了一种新的表示机制,它利用查询和训练的实体嵌入来表示未训练(看不见)的实体。这可以稳定地提高归纳推理的性能,而不会增加计算成本。
4.优于现有的模型。
2相关工作
2.1静态知识图谱推理:
映射到低维复数空间,CNN,GNN等。此外,基于路径的方法也广泛用于 KG 推理。 使用 RNN 来组合路径的含义。强化学习方法 (Xiong et al., 2017; Das et al., 2018; Lin et al., 2018) 将任务视为寻找实体对之间路径的马尔可夫决策过程 (MDP),这比嵌入更具解释性-基于方法。
2.2时序知识图谱推理:
大部分的工作是讲SKG的内容拓展到TKG中。这些模型重新设计了嵌入模块和与时间相关的评分函数。一些作品是利用消息传递网络(RNN系列)来捕获图形快照邻里信息,而这些作品是为插值而设计的。
对于外推,Know-Evolve(Trivedi等人,2017)和GHNN(Han等人,2020b)使用时间点过程来模拟在连续时域中演变的事实。此外,TANGO (Ding et al., 2021) 探索神经常微分方程以构建连续时间模型。 RE-NET (Jin et al., 2020) 考虑了快照图的多跳结构信息,并使用 RNN 对不同时间的实体交互进行建模。CyGNet(Zhu 等人,2021 年)发现,许多事实往往表现出重复的模式,并参考了历史上的已知事实。这些方法无法解释他们的预测,也无法处理以前看不见的实体。解释模型 xERTE(Han 等人,2021 年)使用子图抽样技术来构建推理图。尽管引用GraphSAGE的表示方法(Hamilton等人,2017)使得处理看不见的节点成为可能,但推理图的连续扩展也严重限制了推理速度。
3具体方法
与之前关于KG的工作(Das等人,2018)类似,我们将RL公式构建为时序图上的“基于移动(walk-based)的查询应答”:代理从源节点(查询的主题实体)开始,并按顺序选择传出边以遍历到新节点,直到到达目标。在本节中,本文首先定义任务,然后描述强化学习框架以及我们如何将时间信息整合到政策强化学习模型中。最后,针对以前看不见的实体提供了优化策略和归纳均值代表方法。
3.1任务描述
本节定义外推的任务,这里将分别表示的是实体、关系、时间、事实。一个事实可以使用四元组来表示
。通过随时间变化的图来表示TKG。文章中描述
,其中
,这里的实体和事实表示的都是在时间t存在的。文章中将一个实体表示为二元组。
,在文章中
将其看成是为初始节点到目标节点
在时间t的过程。
3.2强化学习框架
因为典型的 TKG 快照之间没有边,代理(agent)不能从一个快照转移到另一个快照。因此,我们依次添加三个类型的边。
1)反转边。对于每个事件,添加四元组
,
表示的是r的倒数关系。其目的是将我们要预测的主体
转化为
,将主题放到前面,而不失普遍性。
2)自环边。自循环边可以允许代理停留在一个位置,并在代理搜索展开固定数量的步骤时充当停止操作。
3)时序边。这代理可以从节点遍历到节点
通过边。边通过过去事实表示对实体的影响,并帮助主体在历史事实中找到答案。
本文的使用方法是马尔可夫分解过程,下面是方法详解。
State:设 S 表示状态空间,状态由五元组 sl =(el,tl,eq,tq,rq)表示∈ S,其中 (el,tl) 是在步骤 l 访问的节点,(eq,tq,rq)是查询中的元素。(eq,tq,rq)可以看作是全局信息,而(el,tl)是局部信息。代理从查询的源节点启动,因此初始状态为 s0 =(eq,tq,eq,tq,rq)。
Action:A表示的是动作空间,表示的是在时间步骤
的可选动作集,由当前节点e的出边组成(个人理解文章中将当前实体的关系和尾实体,就是要对谁做啥为动作A)。但一个实体通常有许多相关的历史事实,导致大量的可选操作。因此,从上述传出边的集合中抽取最后一组可选
。
![]() 这是A的表示。
这是A的表示。
Transition:传输环境状态(state)通过代理选择上面的虚边到新节点。定义函数:
。具体来说
,其中
是
采样输出的边。
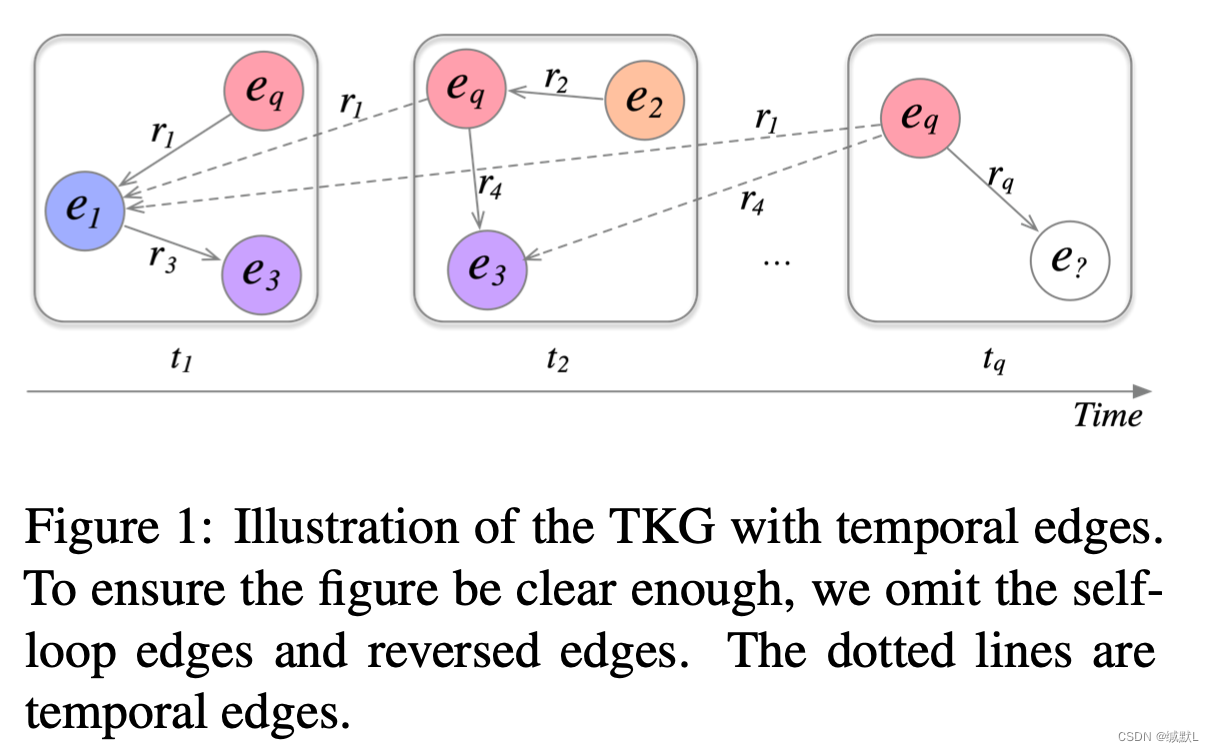
Rewards with shaping:如果代理在搜索结束时到达正确的目标实体,则代理将获得 1 的最终奖励,否则将获得 0。如果 sL = (eL,tL,eq,tq,rq) 是最终状态,(eq,rq,egt,tq) 是基本事实(往上看每个单位的意义,个人理解表示的是查询的事实实体),则奖励公式为:
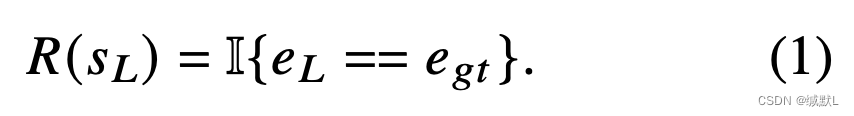
通常,具有相同实体的四元组集中在特定时期,这会导致时间变化性和时间稀疏性。由于这种属性,查询的答案实体随时间分布,我们可以将此先验知识引入奖励函数中以指导代理学习。时间形状的奖励可以让代理知道哪个快照更有可能找到答案。根据训练集,我们估计每个关系的狄利克雷分布。然后,我们用狄利克雷分布塑造原始奖励:
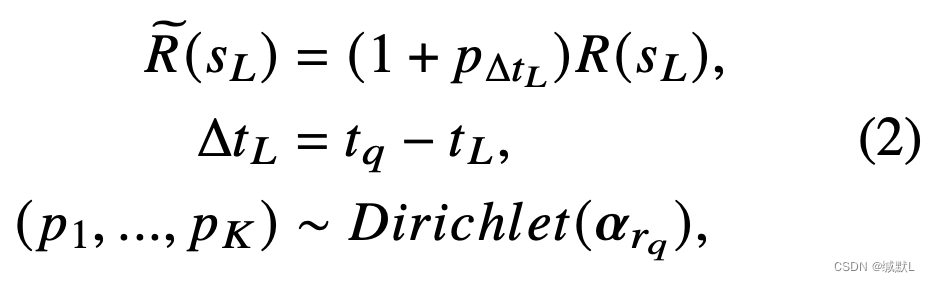
其中是关于关系
狄利克雷分布的参数。这个
是通过训练集来估计的。对于训练集中具有关系 rq 的每个四元组,我们计算对象实体在每个最近的 K 个历史快照中出现的次数。然后,我们得到一个多项式样本 xi 和 D = {x1, ..., xN }。最大化可能性:
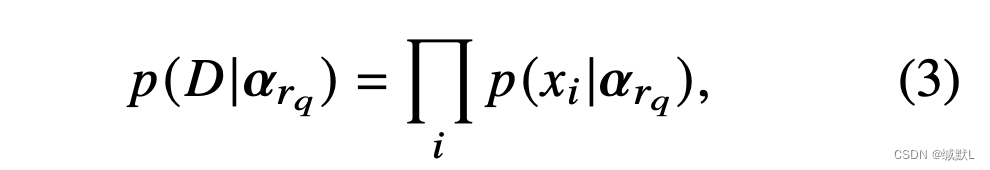
可以估计的值,最大值可以通过定点迭代计算,具体有附录的推导。因为狄利克雷分布有一个共轭先验,所以当我们有更多的观察事实训练模型时,我们可以很容易地更新它(详见上方关于狄利克雷分布的超链接)。
TITer的概览图
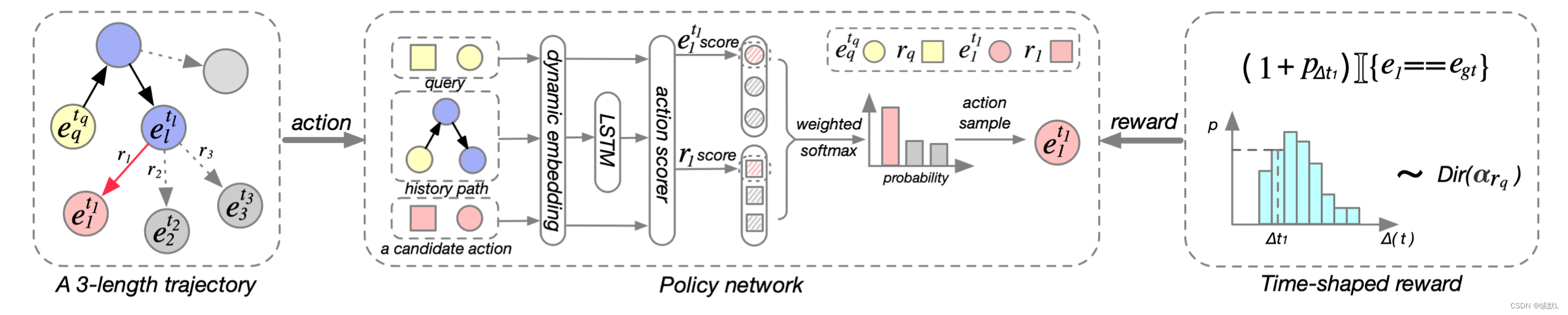
给定查询(这里可以看到反转边的定义),TITer从节点
开始。在每一步,TITer
对传出边进行采样,并根据 πθ(策略网络)遍历到新节点。
3.3策略网络
我们设计了一个策略网络来在连续空间中对代理进行建模,其中al∈Al和θ是模型参数。策略网络由以下三个模块组成。
1)Dynamic embedding(动态嵌入):
我们分配每个关系r ∈ R 一个密集向量嵌入.由于实体的特征可能随时间而变化,因此我们对实体采用相对时间表示方法。我们使用动态嵌入来表示在图中的每个节点,并使用 e∈Rde 来表示实体的潜在不变特征。然后,我们定义一个相对时间编码函数 Φ(Δt) ∈ Rdt 来表示时间信息。Δt = tq − t 和 Φ(Δt) 公式如下:
![]()
其中 w、b ∈ 是具有可学习参数的向量,σ 是激活函数。
分别表示嵌入的维度。然后,我们可以得到节点
的表示:
![]()
2)Path encoding(路径编码):
搜索历史是所执行操作的顺序。
代理使用 LSTM 对历史记录 hl 进行编码:
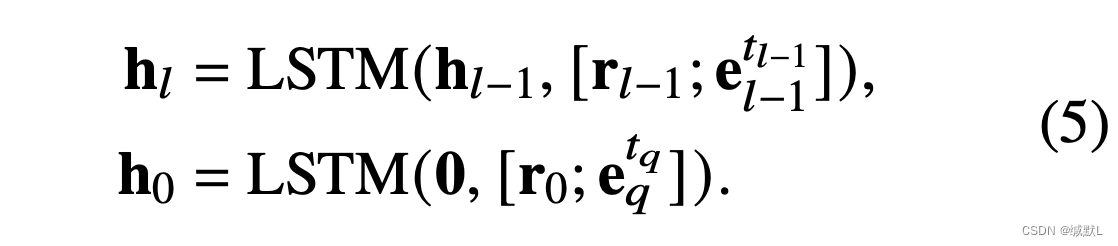
在这里,r0 是一个开始关系,当最后一个动作是自循环(结束标志),我们保持 LSTM 状态不变。
3)Action scoring(动作评分):
我们对每个可选操作进行评分,并计算状态转换的概率。我们对每个可选操作进行评分,并计算状态转换的概率。设 表示步骤 l 中的可选操作。未来事件通常是不确定的,对于某些查询通常没有很强的因果逻辑链,因此实体和查询之间的相关性有时更为重要,所以,我们使用加权动作评分机制来帮助代理更加关注目标节点的属性或边类型。两个多层感知器(MLP)用于对状态信息进行编码,并输出预期的目标节点
和传出边
表示。然后,代理通过计算相似性来获取候选操作的目标节点分数和传出边缘分数。使用两个分数的加权和,代理获得最终候选操作分数
:

其中 是可学习矩阵。<a,b>这个符号是求两个节点的相似性。在
中对所有候选动作进行评分后,
可以通过softMax函数来获得。总而言之,LSTM、MLP 和 Φ 的参数,关系和实体的嵌入矩阵构成了 θ 中的参数。
3.4优化和训练
我们将搜索路径长度固定为 L,并且将从策略网络 πθ: {a1,a2,...,aL} 生成 L 长度轨迹其中。通过最大化所有训练样本的预期奖励来训练策略网络
:
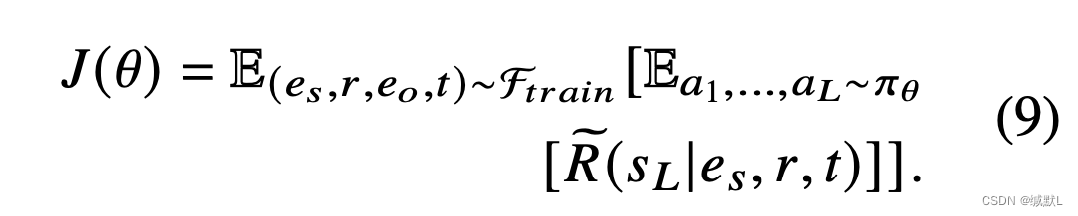
强化算法(Williams,1992)将遍历中的所有四元组,文章中没有提到
个人的经验来看是能量函数,用于优化,并使用以下随机梯度更新θ:
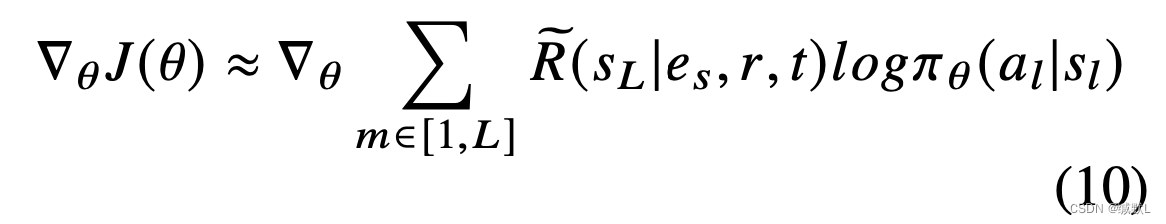
3.5归纳均值表示
由于随着时间的推移,新的实体总是会出现,我们为以前看不见的实体提出了一种新的实体表示方法。之前的工作(鲍米克和德梅洛,2020;Han 等人,2021 年)可以通过邻居信息聚合来表示看不见的实体。然而,新出现的实体的链接通常很少,这意味着可用的信息有限。
对于查询(Evan_Mobley,plays_for,?,2022),实体“Evan_Mobley”在以前不存在,但我们可以通过关系“plays_for”推断该实体是玩家,并为“Evan_Mobley”分配更合理的初始嵌入,以促进推理(意味着可以在问题中得到信息,以便优化结果,使其变得更合理)。
在这里,我们提供了另一种方法来表示看不见的实体,方法是利用查询信息和训练实体的嵌入,称为归纳平均值 (IM),如图 3 所示。
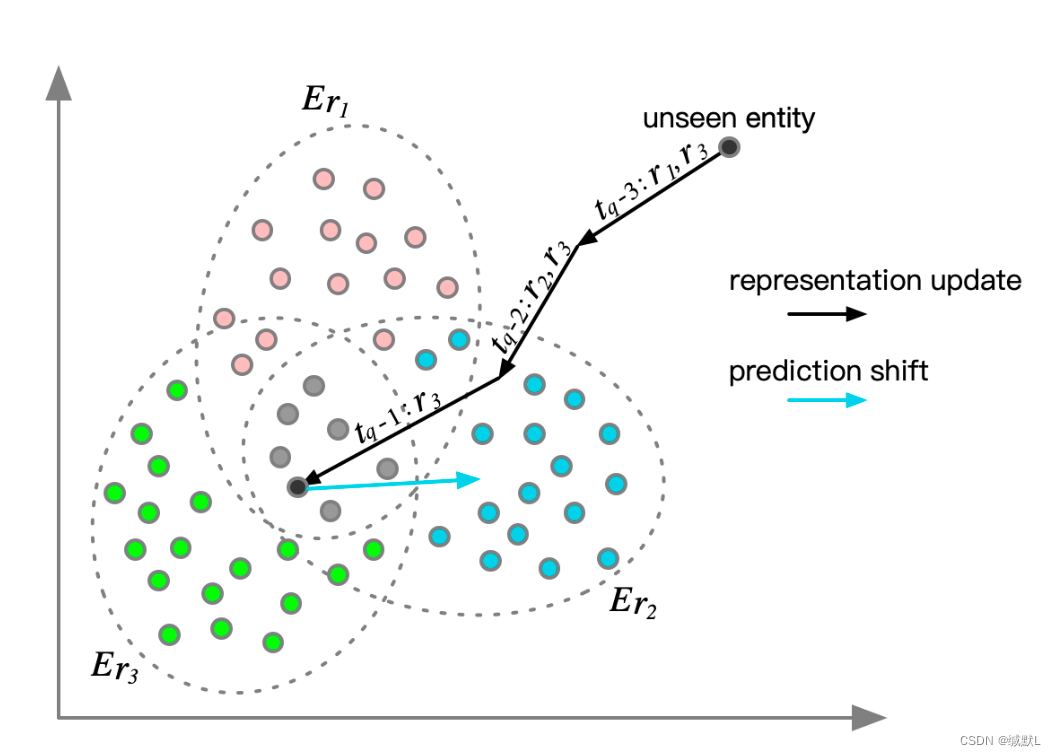
IM 机制的图示。对于一个看不见的实体方程,“tq − 3 : r1,r3” 表示 eq 在 tq − 3 处具有共现关系 r1,r3,并基于 Er1、Er3 更新其表示,最后在 tq − 1 处得到 IM 表示。然后为了回答一个查询(eq,r2,?,tq),我们基于 Er2 进行预测偏移。简言之就是,就是从最底层的时间往上,一步步随着时间偏移到具体的实体集。
共现关系:在当前时间上第一次出现的实体,按文章的意思就是在当前时间上实体可能有多个四元组,多个四元组中的关系组成就叫做共现关系。
设 G(tj,tq−1) 表示测试集中 TKG 的快照。查询实体 eq 首先出现在 Gtj 中,并得到一个随机初始化的表示向量。如果存在包含 (eq,r) 的四元组,我们将 r 视为 eq 的共现关系。请注意,随着时间的推移,实体 eq 可能具有不同的共生关系。
我们将 Rt (eq) 表示为实体 eq 在时间 t 处的共现关系集。设 Er 表示包含具有共现关系 r 的所有已训练实体的集合。然后,我们可以得到具有相同共现关系 r 的实体的归纳均值表示。
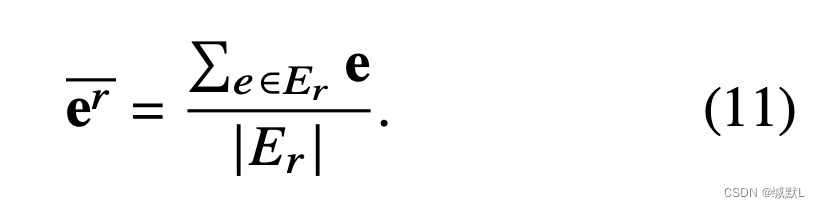
具有相同共现关系r的实体具有相似的特征,因此IM可以利用根据时间流逐渐更新
的表示。0 ≤ μ ≤ 1 是一个超参数:
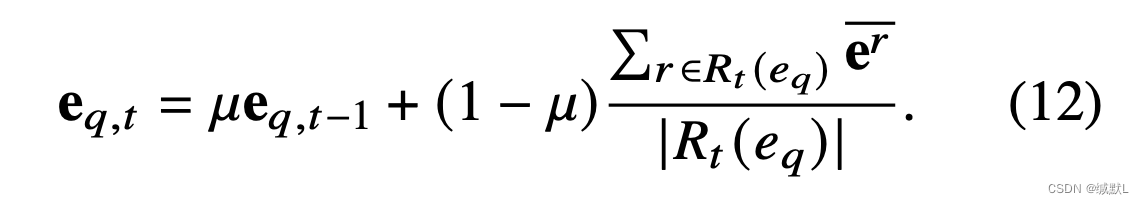
对于关系 rq,我们基于 erq 进行预测偏移,以使实体表示更适合当前查询。
为了回答查询 (eq,rq,?,tq),我们使用时间 tq − 1 的 eq 表示和归纳平均表示 erq 的组合:
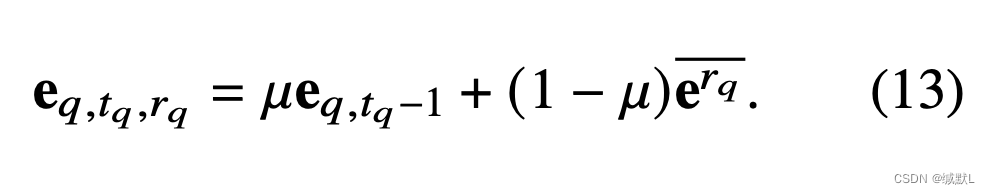
4实验
直接上结果:
表1:未来链路预测的比较。MRR 和 Hits@1/3/10 的结果乘以 100。最佳结果以粗体显示。我们对五次运行的指标进行平均。
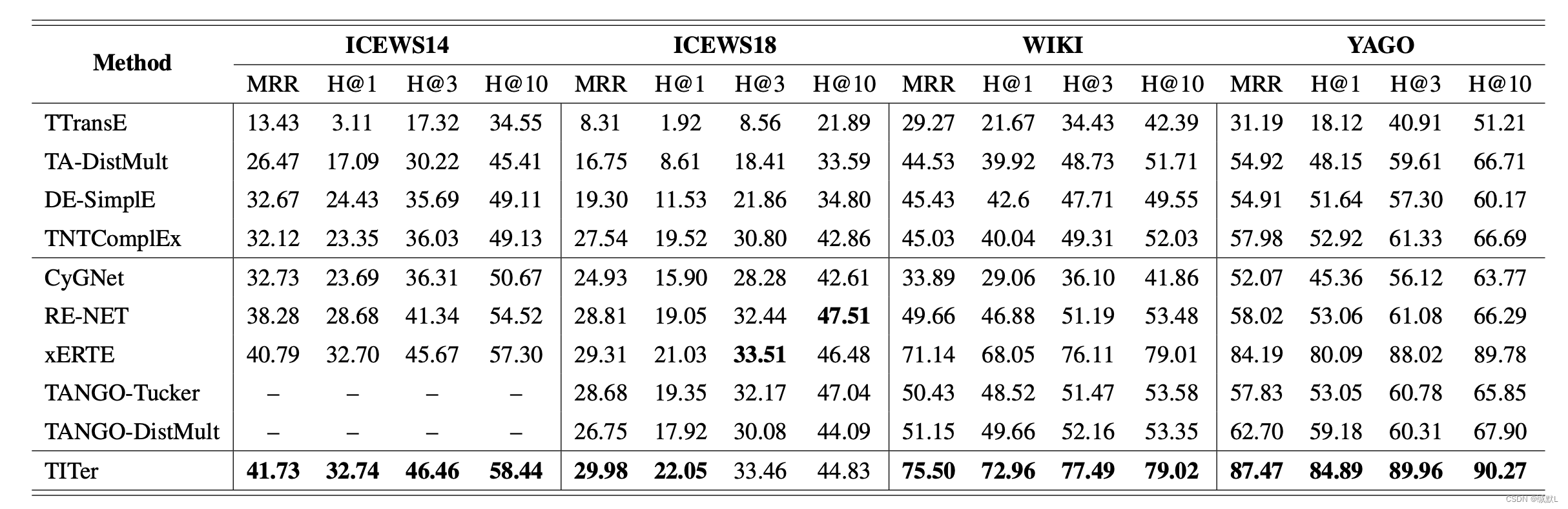
表 2:包含所用测试数据集中未见过的实体的四倍的百分比。

表3:参数数量和计算的比较(M 表示百万)。

当查询包含看不见的实体时,模型应归纳推断答案。对于ICEWS14测试集中包含看不见的实体的所有此类查询,我们在图4和表6中提供了经验结果。与整个ICEWS14测试集的结果相比,RE-NET和CyGNet的性能显着下降(见表1)。
由于缺乏对看不见的实体嵌入和所有实体的分类层的培训,RE-Net 和 CyGNet 无法达到 3 跳邻域随机搜索基线的性能,如图 4 中的虚线所示。
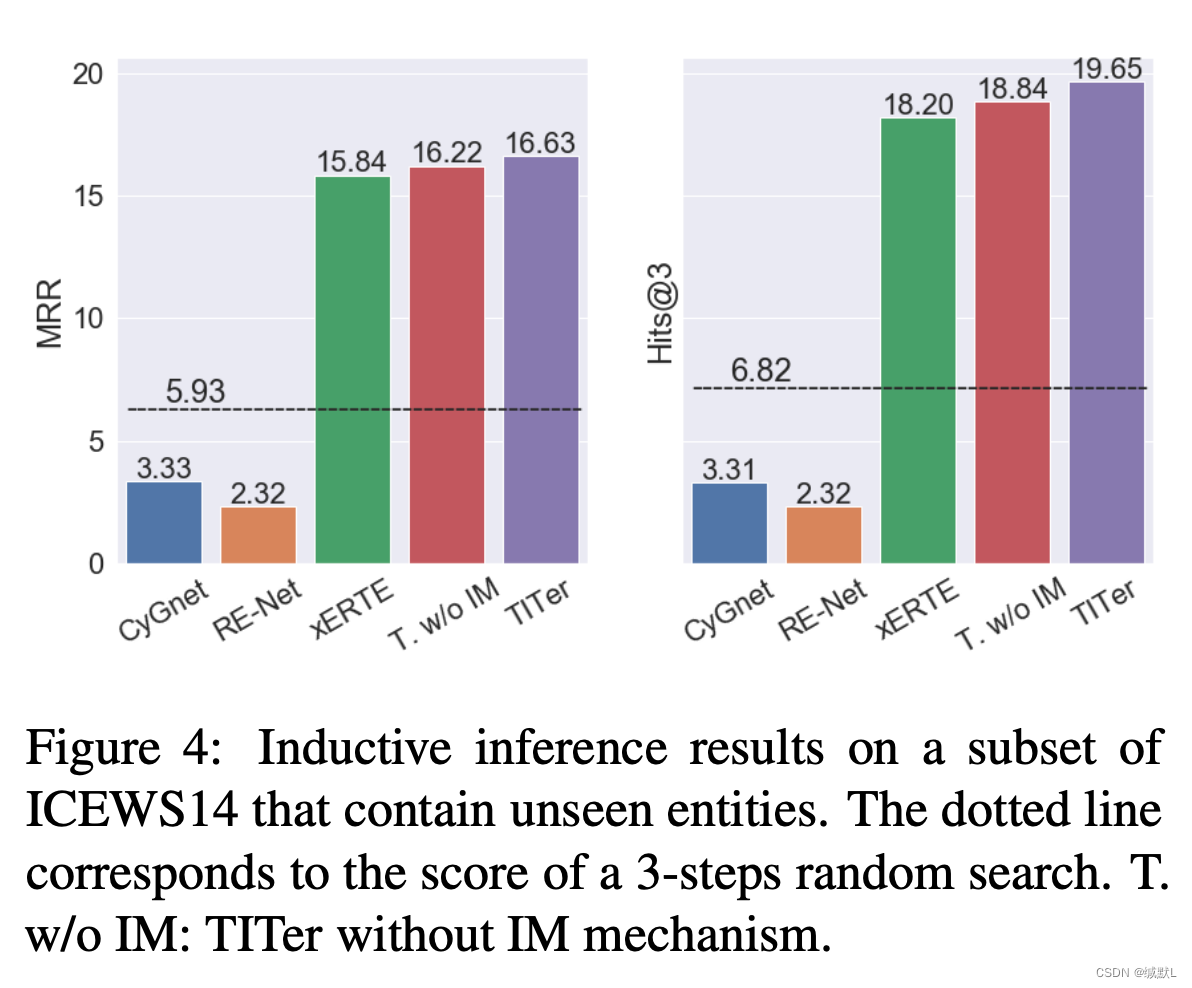
相比之下,xERTE 可以通过基于时间消息聚合动态更新新实体的表示来解决此类查询,而 TITer 可以通过基于时间路径的 RL 框架来处理此类查询。
我们还观察到,无论 TITer 是否采用 IM 机制,TITer 的性能都优于 xERTE。IM机制可以进一步提高性能,提示未见实体的准确率。
Case study。表4可视化了ICEWS18测试集中几个示例的具体推理路径。我们注意到,TITer 倾向于选择最近的事实(传出边缘)来搜索答案。
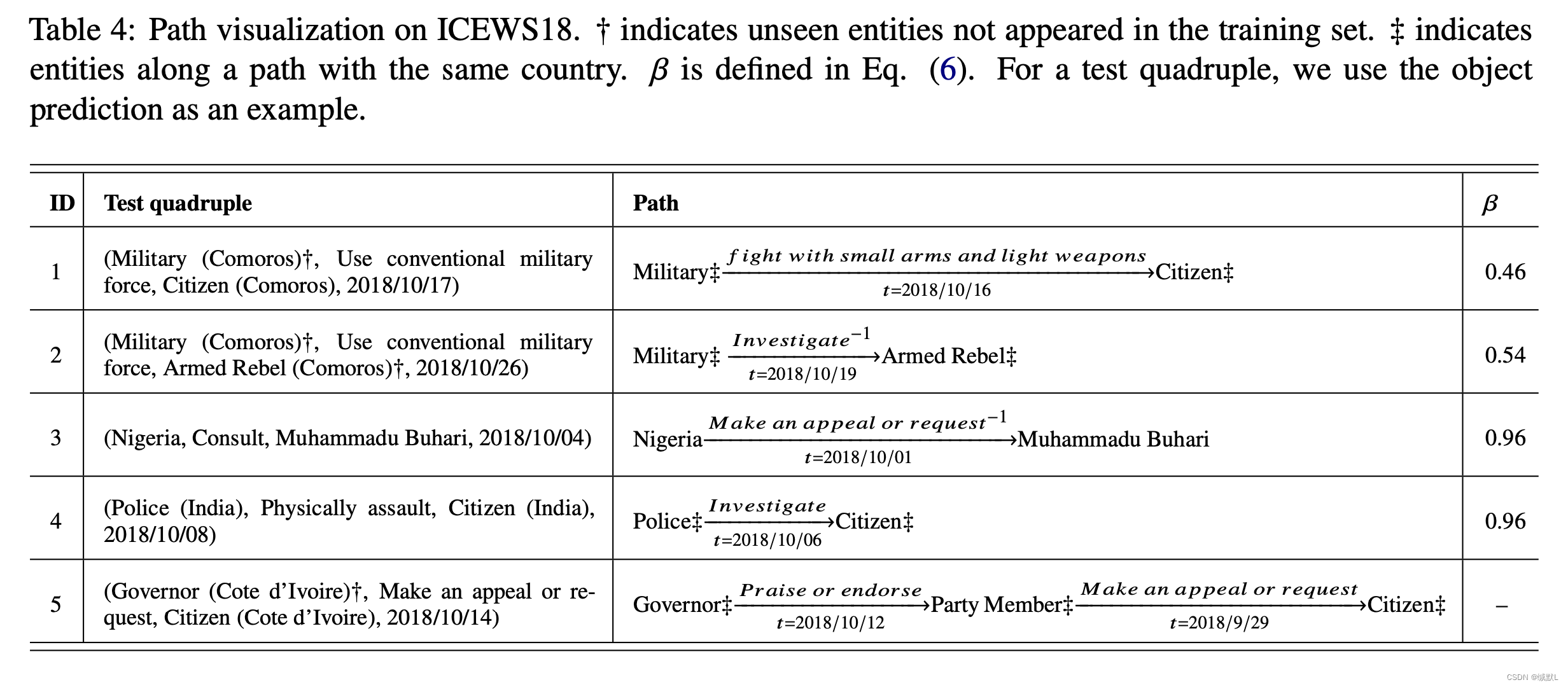
经过训练后,实体的表示积累了大量的语义信息,这有助于 TITer 直接选择答案,而查询 3 和 4 的额外信息更少。相比之下,当看不见的实体出现时,TITer需要更多的历史信息。查询 5 是多跃点推理的一个示例。这表明TITer可以解决组合逻辑问题。
4.4Ablation Study(消融实验)
在本小节中,我们通过消融研究研究TITer的不同成分的影响。结果如表5和图5所示。
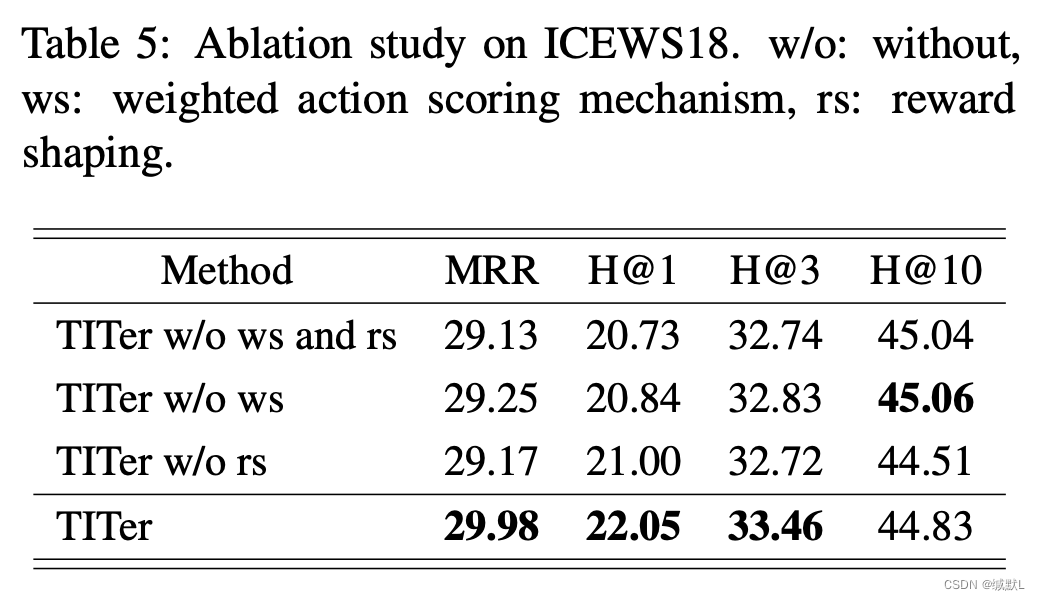
加权动作评分机制。我们观察到,β恒定的0.5可以导致Hits@1下降5.49%,这表明TITer在进行推断时可以更好地选择证据来源。经过训练,TITer学习实体之间的潜在关系。如表4所述,TITer更倾向于关注节点进行推断,何时存在更多信息来做出决策,而TITer选择关注边缘(历史关系)来辅助推断复杂的查询或看不见的实体。
奖励塑造。我们观察到,在都没有奖励塑造的情况下,TITer优于其变体,这意味着Hits@1提高了5%。通过使用狄利克雷先验分布来指导决策过程,TITer获得了有关目标在整个时间跨度内出现的概率分布的知识。(主要说狄利克雷先验分布牛)


















 160
160

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









