






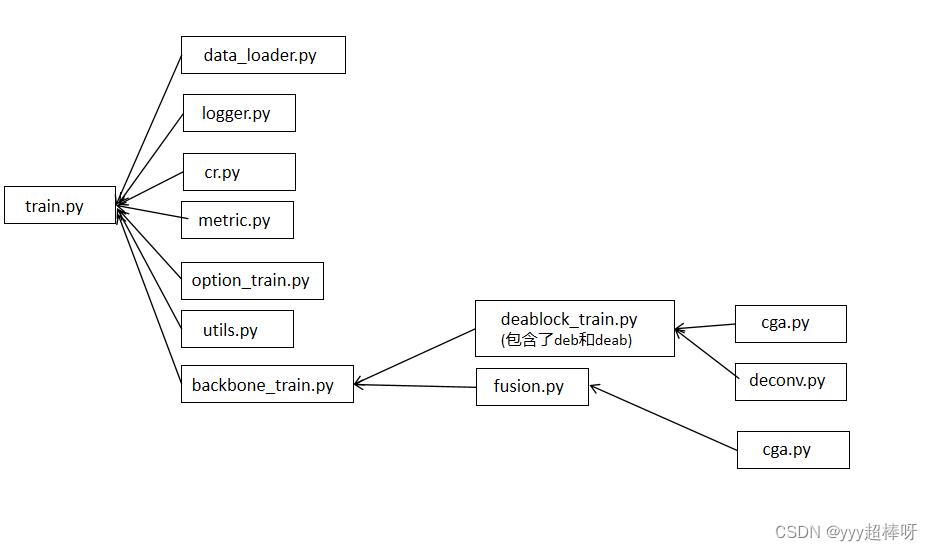
DEA-Net/code/data/data_loader.py
定义了三个数据集类: TrainDataset(训练)、TestDataset(测试)、 ValDataset(验证)。
每个类中__init__(self, hazy_path, clear_path):初始化函数接收两个路径参数,分别是雾霾图像和清晰图像的路径。它将这些路径保存为类的属性,并读取路径下的所有图像文件名。
__getitem__(self, index):该函数根据索引获取雾霾图像和对应的清晰图像,对它们进行裁剪和旋转操作,然后将它们转换为张量并返回。
__len__(self):返回数据集的大小,即雾霾图像的数量。
DEA-Net/code/logger/logger.py
用于绘制日志数据的函数: plot_loss_log和plot_psnr_log。这些函数使用Matplotlib库来生成损失和PSNR(峰值信噪比)的图表,并将图表保存为PDF文件。
DEA-Net/code/loss/cr.py
实现了一个基于VGG19网络的对比损失(Contrastive Loss)函数,用于训练图像去雾等任务中的深度学习模型。定义VGG19模型的特征提取部分。 定义对比损失函数。
DEA-Net/code/metric/metric.py
定义了两个图像质量评估指标:结构相似性(SSIM)和峰值信噪比(PSNR)。
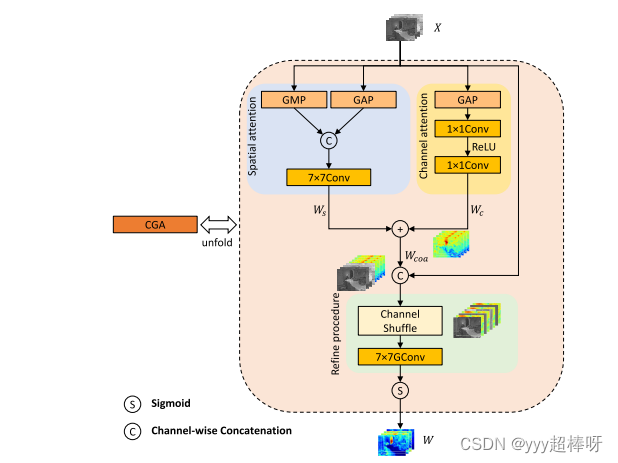
DEA-Net/code/model/modules/cga.py [CGA模块]
实现了三种注意力机制:空间注意力(Spatial Attention)、通道注意力(Channel Attention)和像素注意力(Pixel Attention)。

- 初始化函数:
- 定义了一个7x7卷积层
sa,输入通道数为2,输出通道数为1,使用反射填充。
- 定义了一个7x7卷积层
- 前向传播函数:
- 计算输入张量
x在通道维度上的平均值和最大值,分别得到x_avg和x_max。 - 将
x_avg和x_max在通道维度上拼接,得到x2。 - 通过卷积层
sa处理x2,得到空间注意力图sattn。 
- 初始化函数:
- 定义了一个自适应平均池化层
gap,将输入张量池化到1x1大小。 - 定义了一个由两层卷积层和ReLU激活函数组成的序列
ca,用于计算通道注意力。
- 定义了一个自适应平均池化层
- 前向传播函数:
- 对输入张量
x进行自适应平均池化,得到x_gap。 - 通过
ca处理x_gap,得到通道注意力图cattn。
- 初始化函数:
- 定义了一个7x7卷积层
pa2,输入通道数为2*dim,输出通道数为dim,使用反射填充,组卷积。 - 定义了一个Sigmoid激活函数。
- 定义了一个7x7卷积层
- 前向传播函数:
- 获取输入张量
x的形状B, C, H, W。 - 在第二个维度(通道维度)上扩展
x和pattn1,以增加一个维度。 - 将扩展后的
x和pattn1在新的维度上拼接,得到x2。 - 使用
Rearrange将x2的形状重排为B, (C * 2), H, W。 - 通过卷积层
pa2处理x2,得到像素注意力图pattn2。 - 使用Sigmoid激活函数对
pattn2进行激活,得到最终的像素注意力图。
- 获取输入张量
- 对输入张量
- 计算输入张量
DEA-Net/code/model/modules/deablock_train.py [DEABlockTrain模块][DEBlockTrain模块]
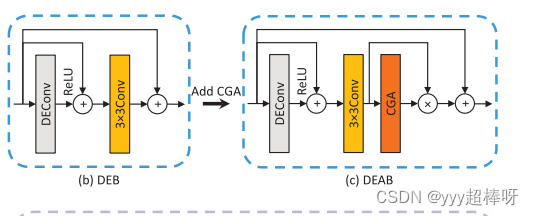
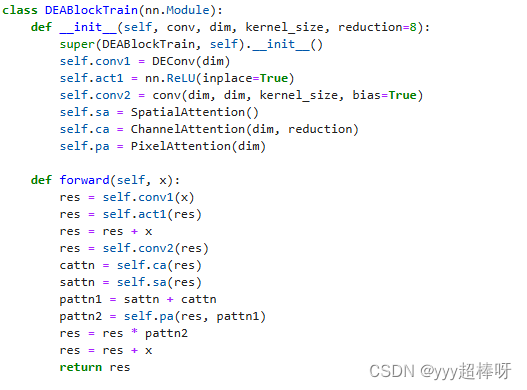
DEABlockTrain 类:带有注意力机制
- 初始化函数:
conv1和conv2:两个卷积层,第一个卷积层使用了自定义的DEConv,第二个卷积层使用传入的卷积函数。act1:ReLU激活函数。sa:空间注意力机制。ca:通道注意力机制。pa:像素注意力机制。
- 前向传播函数:
- 输入张量
x首先通过第一个卷积层和ReLU激活函数。 - 然后将结果与原始输入相加,形成残差连接。
- 通过第二个卷积层处理后,应用通道注意力和空间注意力,得到
cattn和sattn。 - 将这两个注意力图相加后,输入到像素注意力机制中,得到最终的像素注意力图
pattn2。 - 输入张量乘以这个注意力图,然后再次与原始输入相加,形成最终的输出。
- 输入张量

DEBlockTrain 类:不带有注意力机制

- 初始化函数:
conv1和conv2:两个卷积层,第一个卷积层使用了自定义的DEConv,第二个卷积层使用传入的卷积函数。act1:ReLU激活函数。
- 前向传播函数:
- 输入张量
x首先通过第一个卷积层和ReLU激活函数。 - 然后将结果与原始输入相加,形成残差连接。
- 通过第二个卷积层处理后,再次与原始输入相加,形成最终的输出。
- 输入张量
DEA-Net/code/model/modules/deablock.py
和deablock_train.py内容一样。
DEA-Net/code/model/modules/deconv.py[DEConv模块]
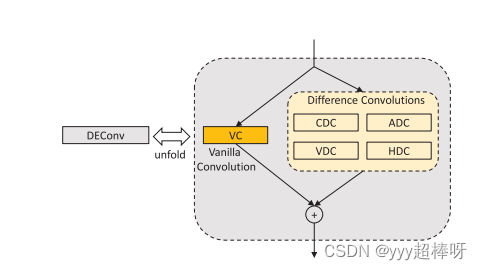
Conv2d_cd(nn.Module):定义中心差分卷积;
Conv2d_ad(nn.Module):定义反差分卷积;
Conv2d_rd(nn.Module):定义径向差分卷积;
Conv2d_hd(nn.Module):定义水平差分卷积;
Conv2d_vd(nn.Module):定义垂直差分卷积。
DEA-Net/code/model/modules/fusion.py[Fusion模块]
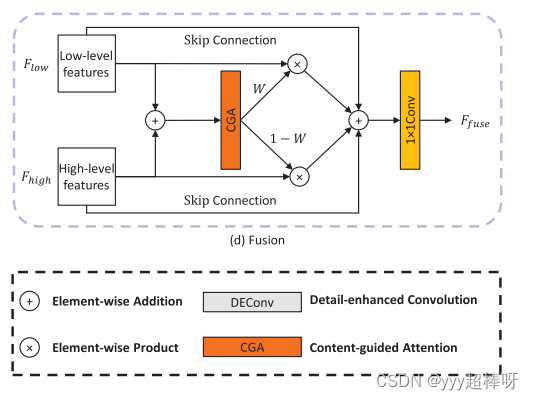

-
初始化函数:
sa:空间注意力机制(Spatial Attention)。ca:通道注意力机制(Channel Attention)。pa:像素注意力机制(Pixel Attention)。conv:一个1x1的卷积层,用于调整特征图的通道数。sigmoid:Sigmoid激活函数,用于归一化像素注意力图。
-
前向传播函数:
- 输入两个张量
x和y,首先将它们相加得到initial。 - 对
initial应用通道注意力机制,得到cattn。 - 对
initial应用空间注意力机制,得到sattn。 - 将通道注意力图和空间注意力图相加,得到
pattn1。 - 将
pattn1输入到像素注意力机制中,得到pattn2,并通过 Sigmoid 激活函数归一化。 - 将
pattn2应用于x和y,并与initial相加,得到加权融合结果result。 - 对融合结果应用1x1卷积,调整通道数,得到最终输出。
- 输入两个张量
DEA-Net/code/model/backbone_train.py [DEANet模块]
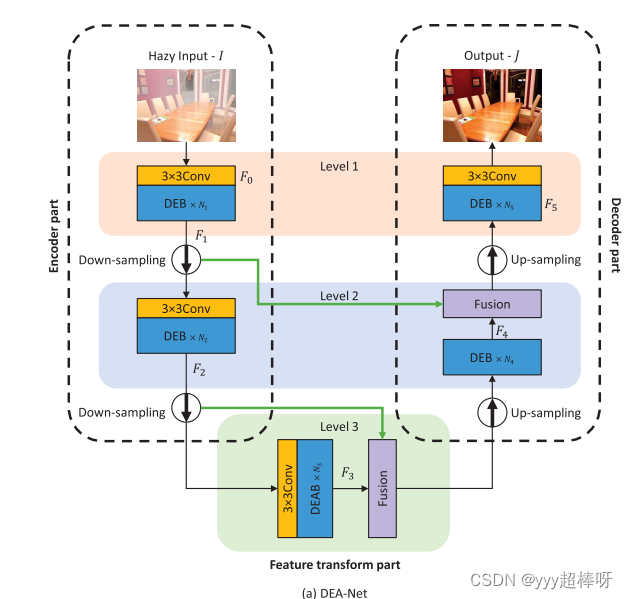
DEA-Net/code/model/backbone.py
和DEA-Net/code/model/backbone_train.py [DEANet模块]一样。
DEA-Net/code/option/option.py【评估过程】
该代码主要功能包括解析命令行参数、设置默认路径、创建必要的目录结构,以及将参数保存到文件中。
DEA-Net/code/utils/metric.py
和DEA-Net/code/metric/metric.py里的内容一样。
DEA-Net/code/utils/utils.py
这段代码实现了一些用于图像处理和统计的实用工具函数和类。

- 功能:根据给定的patch size对输入图像进行填充,使其尺寸能够被patch size整除。
- 参数:
x:输入图像(张量)。patch_size:填充到能够被该值整除的尺寸。
- 返回值:填充后的图像。
DEA-Net/code/eval.py
它加载预训练模型,对验证数据集进行推理,计算并输出PSNR和SSIM两个图像质量指标。
DEA-Net/code/option_train.py【训练过程】
它解析命令行参数,设置默认路径,创建必要的目录结构,并将参数保存到文件中。
DEA-Net/code/reparam.py
这段代码用于将复杂的卷积神经网络权重转换为简化形式。具体来说,它将四种不同类型的卷积权重(中心差分卷积CDC、水平差分卷积HDC、垂直差分卷积VDC、和角差分卷积ADC)重新组合成单一的卷积权重,并将其保存为一个新的简化模型。
convert_cdc(w):中心差分卷积
convert_hdc(w):水平差分卷积
convert_vdc(w):垂直差分卷积
convert_adc(w):角差分卷积
DEA-Net/code/train.py
这段代码实现了一个训练深度学习模型的脚本,具体应用于图像去雾任务。主要包括设置训练环境、定义模型、加载数据、训练和评估模型等步骤。















 839
839

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









