







Vision Transformers with Natural Language Semantics
公和众和号:EDPJ(进 Q 交流群:922230617 或加 VX:CV_EDPJ 进 V 交流群)

目录
0. 摘要
Token 或 patch 在 Vision Transformers(ViT) 中缺乏关键的语义信息,不像它们在自然语言处理(NLP)中的对应物。 通常,ViT token 关联着缺乏特定语义上下文的矩形图像 patch,使解释变得困难,并且未能有效地封装信息。 我们引入了一种新颖的 transformer 模型,Semantic Vision Transformers (sViT),它利用了最近在分割模型方面的进展设计新颖的 tokenizer 策略。sViT 有效地利用语义信息, 创建了一种类似于卷积神经网络的归纳偏差(inductive bias),同时捕获了图像中的全局依赖性和上下文信息。通过使用真实数据集进行验证,sViT 显示出比 ViT 更好的性能, 在保持类似或更优的性能的同时需要更少的训练数据。 此外,sViT 在超出分布的泛化和对自然分布的鲁棒性方面显示出显著的优势, 归因于其尺度不变的语义特性。值得注意的是, 语义 token 的使用显著增强了模型的可解释性。 最后,所提出的范式促进了新技术的引入,并且强大的增强技术在 token(或分割)级别, 增加了训练数据的多样性和泛化能力。就像句子由单词组成,图像由语义对象组成;我们提出的方法利用了对象分割方面的最新进展,并且迈出了可解释和鲁棒视觉 transformer 的重要而自然的一步。

2. 方法
2.1 sViT
为了构建语义标记,我们利用了Segment Anything Model(SAM)[19],该模型已经在 1100 万张图像上进行了分割任务的训练。每个分段被调整为 16×16 或 32×32 像素,我们利用匹配尺寸的卷积层将它们展平为向量嵌入,采用与原始 Vision Transformer(ViT)类似的方法。我们不使用补丁(patch)的位置或顺序进行位置编码,而是使用由 SAM 提供的边界框的水平和垂直(x,y)图像坐标以及每个分割的像素大小。
边界框的坐标提供了关于图像中对象的相对位置和上下文信息,这对于理解图像内容至关重要。例如,图像上有一个人骑在马上传达了与图像上有一个人站在马旁边传达的含义不同,分别表示可能的骑马或照顾马的动作。分割大小信息也很有价值,作为模型识别哪些对象可能对理解图像至关重要的信号。这些信息被添加到标记中,该过程的详细说明在附录中总结。
我们利用了原始 ViT 模型的基本架构,设计用于处理 196 个输入标记。与原始 ViT 不同,我们的模型适应了变长输入标记,因为 SAM 根据输入图像产生不同数量的分段。为了处理这种变异性,我们引入了一个称为 “背景标记(background token)” 的标记,它表示在对图像中的所有对象进行分段后剩余的像素。为了将其指定为背景标记,我们将边界框的 x 和 y 坐标赋值为 -1,类似于语言模型中的特殊标记的概念。对于包含 195 个以上分割(segment)的图像,我们使用前 195 个分割作为标记,并将剩余的分割分配给背景标记。这种方法确保了原始图像的所有元素都不会被丢弃。该模型在图 3 中进行了说明并与原始 ViT 进行了比较。

2.2 数据增强
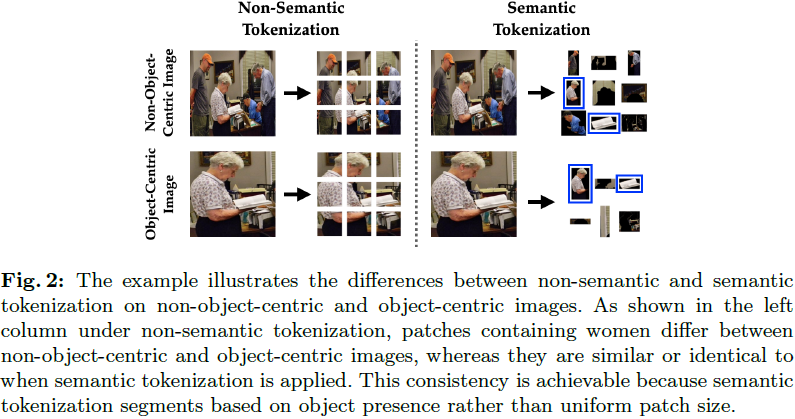
数据增强技术已经显示出良好的泛化性能。大多数这些增强都应用于整个图像,从而限制了它们鼓励给定场景的相对(语义)组件多样性的能力。例如,当我们对整个图像应用水平翻转时,图像中的所有对象都会被翻转并保持它们的相对关系。为了从单个图像获得更广泛的数据增强,至关重要的是在分割级别应用增强。在分割级别应用增强还增强了裁剪和调整大小技术。当我们对整个图像应用裁剪和调整大小技术时,这种裁剪有可能丢失对象。例如,在图 4 中,聚焦于裁剪图像中的女性可能导致一些对象被裁剪掉。然而,当我们在分割级别应用裁剪和调整大小技术时,我们可以保留所有对象并创建更多样化的数据增强。

通过在标记级别执行增强,我们进一步避免了重新呈现完整场景的复杂任务。此外,我们的新标记器引入了用于位置嵌入的附加输入,即图像分割的位置和大小。这些输入使我们能够实施一种创新的增强方法,即向每个语义标记的位置和大小输入引入噪声。考虑一张草原上奔跑的一群马的图像。马的相对位置微小变化或其大小的变化可能源于相机角度或距离的变化。为每个语义标记的位置和大小数据引入噪声有助于视觉模型对这些变化进行泛化,这是当前全局数据增强方法未能解决的一个特征。
为了整合这些概念,sViT 的增强函数接受以下输入:分割列表、分割的位置和大小、增强采样的最大百分比以及增强函数的详细信息,如算法 1 中所述。与在每个时期对相同数量的分段应用增强的方法不同,我们通过对增强采样的百分比进行抽样引入了变异性。这种方法通过在训练过程中使图像暴露于不同强度的增强水平,增强了多样性。

2.3 增强模型可解释性
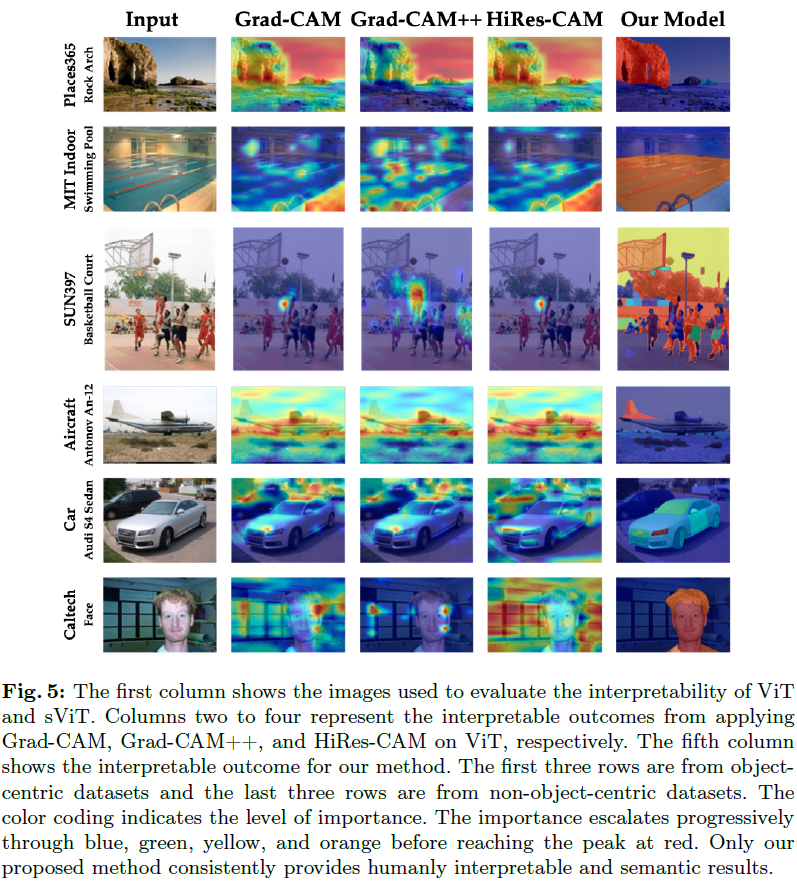
与其他基于梯度的方法一样,我们利用梯度传播来识别图像中预测特定类别的关键语义分割。与现有方法不同的是,我们不仅仅依赖于视觉模型最后一层的梯度信息,而是使用语义(可解释的)标记的梯度信息。sViT 标记器(tokenizer),一个分割模型,以监督的方式训练,学习人类如何将图像分成不同且可理解的部分。
要确定每个标记(token) i 的基于梯度的重要性水平(I^c_i),用于预测类别 c,初始步骤涉及计算关于语义标记 i(T_i)的嵌入的梯度,与预测类别 c(y^c)相关,即 ∂y^c / ∂T_i。随后的过程包括将梯度与标记嵌入进行逐元素相乘,然后计算相乘张量的平均值。与其他基于梯度的方法类似,我们对计算得到的平均值应用 ReLU 函数,将所有负值转换为零。完整的方程变为:
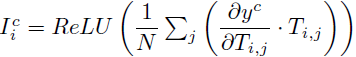
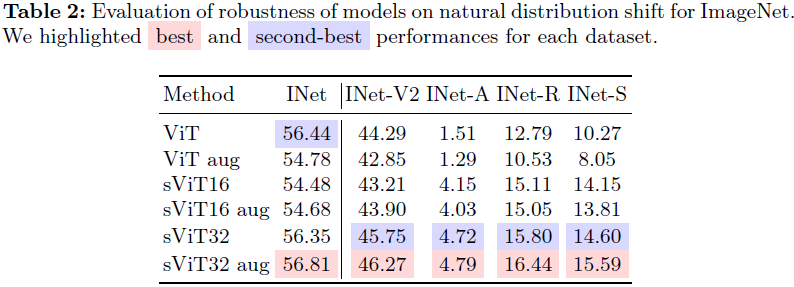
3. 实验
5. 限制
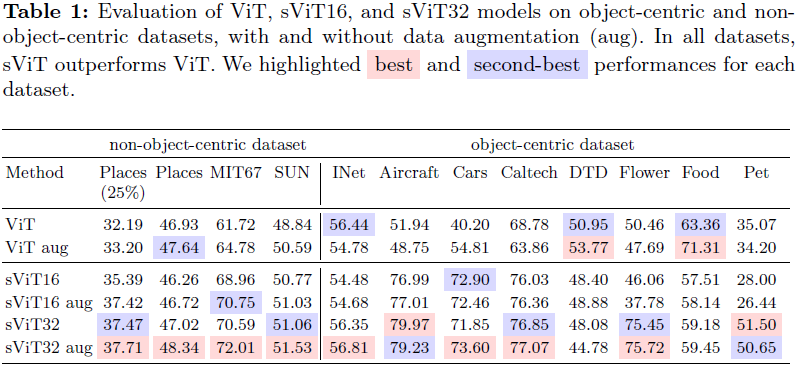
我们的方法与 ViT 相比存在计算上的限制。与 ViT 相比, sViT 需要额外的计算来进行一次数据集的预处理分割, 相当于额外的训练时期,如果分割模型和训练模型大小相似的话。然而,在推断过程中,与 ViT 相比,sViT 的计算成本翻倍,因为它在推断过程中执行了分割。这突显了一个明显的权衡:虽然 ViT 更高效,但 sViT 在处理分布之外的情况和分布转变以及增强可解释性方面具有更强的鲁棒性。提升分割模型效率可能有望弥补这一差距,这是未来研究的一个有前途的方向。

















 6695
6695

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









