







随着《Attention Is All You Need》这篇文章的发表,基于注意力机制的Transformer模型火遍了世界,开始Transformer主要应用在自然语言处理领域,慢慢的拓展到了计算机视觉领域,一直到现在的大模型ChatGPT等等,其实背后的底层技术都用到了Transformer。而把Transformer应用到计算机视觉领域的重要代表性模型就是ViT。
第一个具有重大影响力的使用纯Transformer结构进行图像分类的模型就是VIT。VIT全名VisionTransformer,是2020年Google团队提出的将Transformer应用在图像分类的模型,虽然不是第一篇将transformer应用在视觉任务的论文,但是因为其模型“简单”且效果好,可扩展性强(scalable,模型越大效果越好),成为了transformer在CV领域应用的里程碑著作,也引爆了后续相关研究。ViT原论文中最核心的结论是,当拥有足够多的数据进行预训练的时候,ViT的表现就会超过CNN,突破transformer缺少归纳偏置的限制,可以在下游任务中获得较好的迁移效果。
ViT将输入图片分为多个patch(16x16),再将每个patch投影为固定长度的向量送入Transformer,后续encoder的操作和原始Transformer中完全相同。但是因为对图片分类,因此在输入序列中加入一个特殊的token,该token对应的输出即为最后的类别预测结果。ViT网络结构如下所示:
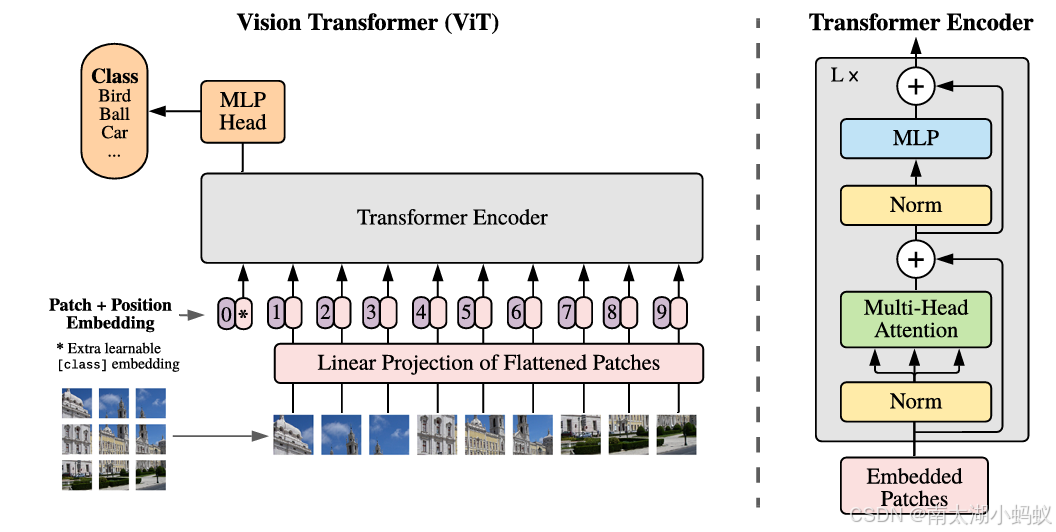
按照上面的流程图,ViT可以分为以下几个步骤:
(1) patch embedding:例如输入图片大小为224x224,将图片分为固定大小的patch,patch大小为16x16,则每张图像会生成224x224/16x16=196个patch,即输入序列长度为196,每个patch维度16x16x3=768,线性投射层的维度为768xN(N=768),因此输入通过线性投射层之后的维度依然为196x768,即一共有196个token,每个token的维度是768。这里还需要加上一个特殊字符cls,因此最终的维度是197x768。到目前为止,已经通过patchembedding将一个视觉问题转化为了一个seq2seq问题。
(2) positional encoding(standardlearnable 1D position embeddings):ViT同样需要加入位置编码,位置编码可以理解为一张表,表一共有N行,N的大小和输入序列长度相同,每一行代表一个向量,向量的维度和输入序列embedding的维度相同(768)。注意位置编码的操作是sum,而不是concat。加入位置编码信息之后,维度依然是197x768。
其中,前两个步骤是对输入数据的处理,后两个步骤是一个编码器Transformer Encoder。
(3) LN/multi-head attention/LN:LN(层归一化)输出维度依然是197x768。多头自注意力时,先将输入映射到q,k,v,如果只有一个头,qkv的维度都是197x768,如果有12个头(768/12=64),则qkv的维度是197x64,一共有12组qkv,最后再将12组qkv的输出拼接起来,输出维度是197x768,然后再经过一层LN(层归一化),维度依然是197x768。
(4) MLP:将维度放大再缩小回去,197x768放大为197x3072,再缩小变为197x768。
一个block之后维度依然和输入相同,都是197x768,因此可以堆叠多个block。最后会将特殊字符cls对应的输出作为encoder的最终输出 ,代表最终的image presentation输出。
(5)输出头:最后再拼接上一个全连接层,得到分类结果,也可以根据下游任务的要求拼接上合适的输出模块。
所谓的ViTSeg,其实就是将ViT直接应用在分割任务上。简单来说,就是把ViT的分类头去掉,换成卷积层对各个类别打分,再拼上一个上采样层,得到分类的结果。第二个改进的地方就是,ViT中是把原始图像切片并输入Transformer编码器的,而我这里先把图像通过卷积神经网络提取特征图,再把特征图切成小片后,做线性投影为向量,并加入随机生成的位置编码信息,得到最终的输入数据输入Transformer编码器,对图像的编码结果进行大小变换以生成二维特征图,再进行卷积操作,把通道数转变成分类数量,得到分类结果。之后对分类结果进行上采样操作,恢复成原始图像大小,得到像素级语义分割的结果,也就是影像解译的结果。这样可以结合卷积神经网络权重共享,平移不变性的特点以及注意力机制的没有空间局部敏感性和适合学习归纳偏差的特点,达到更好的解译效果。
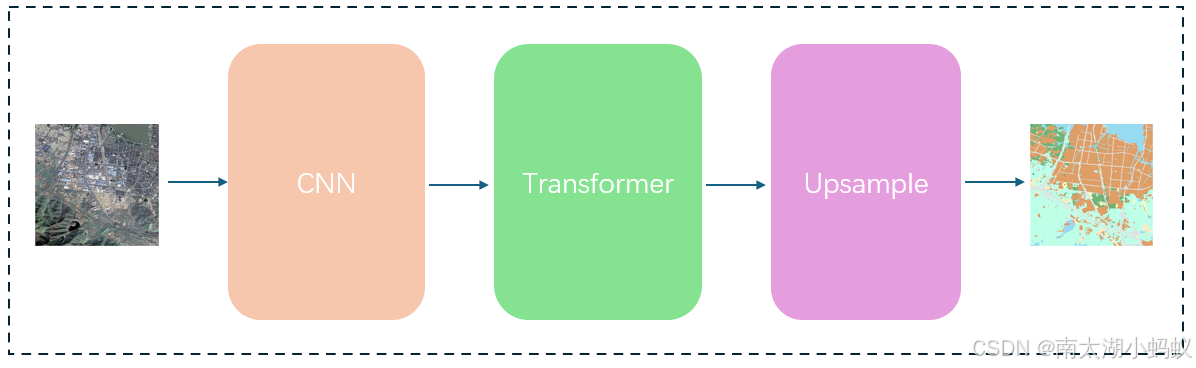
模型代码如下:
import torch
from torch import nn, Tensor
from torchvision.models import resnet50,resnet101
from torch.nn import functional as F
from timm.models.vision_transformer import vit_base_patch16_224_in21k as create_model
import math
# 位置编码
class PositionalEncoding(nn.Module):
def __init__(self, d_model: int, dropout: float = 0.1, max_len: int = 5000):
super(PositionalEncoding, self).__init__()
self.dropout = nn.Dropout(p=dropout)
# max_len表示最大序列长度
position = torch.arange(max_len).unsqueeze(1)
div_term = torch.exp(torch.arange(0, d_model, 2) * (-torch.log(torch.tensor(10000.0)) / d_model))
pe = torch.zeros(max_len, 1, d_model)
# 这只是一种方法,可以有别的获取位置信息的方法
pe[:, 0, 0::2] = torch.sin(position * div_term)
pe[:, 0, 1::2] = torch.cos(position * div_term)
# 在 PyTorch 中,register_buffer 是一个用于在模型中注册缓冲区的方法。
# 缓冲区是模型的一部分,但不会在训练过程中更新。
# 它们通常用于存储一些不需要梯度的常量或中间结果。
self.register_buffer('pe', pe)
def forward(self, x: Tensor) -> Tensor:
x = x + self.pe[:x.size(0)]
return self.dropout(x)
class TransformerSegmentation(nn.Module):
def __init__(self, num_classes: int, d_model: int = 256, nhead: int = 8, num_encoder_layers: int = 6,
num_decoder_layers: int = 6, dim_feedforward: int = 2048, dropout: float = 0.1,
activation: str = "relu"):
super(TransformerSegmentation, self).__init__()
# 现在要使用这种方式使用预训练的模型
backbone = resnet101(weights="IMAGENET1K_V1")
# 获取最终的特征层
self.backbone = nn.Sequential(*list(backbone.children())[:-2])
encoder_layer = nn.TransformerEncoderLayer(d_model=d_model, nhead=nhead, dim_feedforward=dim_feedforward,
dropout=dropout, activation=activation, batch_first=True)
self.transformer_encoder = nn.TransformerEncoder(encoder_layer, num_layers=num_encoder_layers)
self.positional_encoding = PositionalEncoding(d_model=d_model, dropout=dropout)
# 解码模块
self.decoder = nn.Sequential(
nn.ConvTranspose2d(d_model, d_model // 2, kernel_size=4, stride=2, padding=1),
nn.ReLU(True),
nn.ConvTranspose2d(d_model // 2, num_classes, kernel_size=4, stride=2, padding=1)
)
def forward(self, img):
img = self.backbone(img) # [B, C, H/32, W/32]
h,w = img.shape[2], img.shape[3]
B, C, H, W = img.shape # 批次大小,通道,宽,高
# 维度调整,调整为[H*W, B, C]
img = img.view(B, C, -1).permute(2, 0, 1)
# 位置编码
img = self.positional_encoding(img)
# 经过transformer编码器
features = self.transformer_encoder(img)
# 改变特征图形状,变成[B, C, H/32, W/32]
features = features.permute(1, 2, 0).view(B, C, H, W)
# 解码模块,先分类,其实在解码模块中通过转置卷积,大小已经变大了4倍,恢复成了H/8,W/8
out = self.decoder(features)
# 上采样,恢复成原图大小
out = F.interpolate(out, size=(h*32,w*32), mode='bilinear', align_corners=False)
return out
model = TransformerSegmentation(num_classes=21, d_model=2048) #
x = torch.randn([1, 3, 320, 320])
out = model(x)
print(out.shape)
# 输出:[1, 21, 320, 320]将该模型应用到VOC2012数据集,学习率0.01,batch_size设置为32,训练1000个epoch,总体精度达到0.975,各类精度如下,可以看到自行车的精度较低,我们识别图中也可以看到自行车比较不准确,这可能是因为VOC2012数据集中,有的自行车标签自行车轮胎是空洞的,有的标签自行车轮胎是一个整体的圆形,造成了学习的困扰:
2024-12-19 12:46:15,503 - __main__ - DEBUG - --------------------------------------
2024-12-19 12:46:15,503 - __main__ - DEBUG - |0|background|0.98|
2024-12-19 12:46:15,503 - __main__ - DEBUG - |1|aeroplane|0.69|
2024-12-19 12:46:15,503 - __main__ - DEBUG - |2|bicycle|0.32|
2024-12-19 12:46:15,504 - __main__ - DEBUG - |3|bird|0.87|
2024-12-19 12:46:15,504 - __main__ - DEBUG - |4|boat|0.72|
2024-12-19 12:46:15,504 - __main__ - DEBUG - |5|bottle|0.6|
2024-12-19 12:46:15,504 - __main__ - DEBUG - |6|bus|0.77|
2024-12-19 12:46:15,504 - __main__ - DEBUG - |7|car|0.87|
2024-12-19 12:46:15,504 - __main__ - DEBUG - |8|cat|0.85|
2024-12-19 12:46:15,504 - __main__ - DEBUG - |9|chair|0.78|
2024-12-19 12:46:15,504 - __main__ - DEBUG - |10|cow|0.64|
2024-12-19 12:46:15,504 - __main__ - DEBUG - |11|diningtable|0.71|
2024-12-19 12:46:15,504 - __main__ - DEBUG - |12|dog|0.86|
2024-12-19 12:46:15,504 - __main__ - DEBUG - |13|horse|0.65|
2024-12-19 12:46:15,504 - __main__ - DEBUG - |14|motorbike|0.76|
2024-12-19 12:46:15,504 - __main__ - DEBUG - |15|person|0.96|
2024-12-19 12:46:15,504 - __main__ - DEBUG - |16|potted plant|0.56|
2024-12-19 12:46:15,504 - __main__ - DEBUG - |17|sheep|0.68|
2024-12-19 12:46:15,504 - __main__ - DEBUG - |18|sofa|0.74|
2024-12-19 12:46:15,504 - __main__ - DEBUG - |19|train|0.79|
2024-12-19 12:46:15,504 - __main__ - DEBUG - |20|tv/monitor|0.73|
2024-12-19 12:46:15,504 - __main__ - DEBUG - --------------------------------------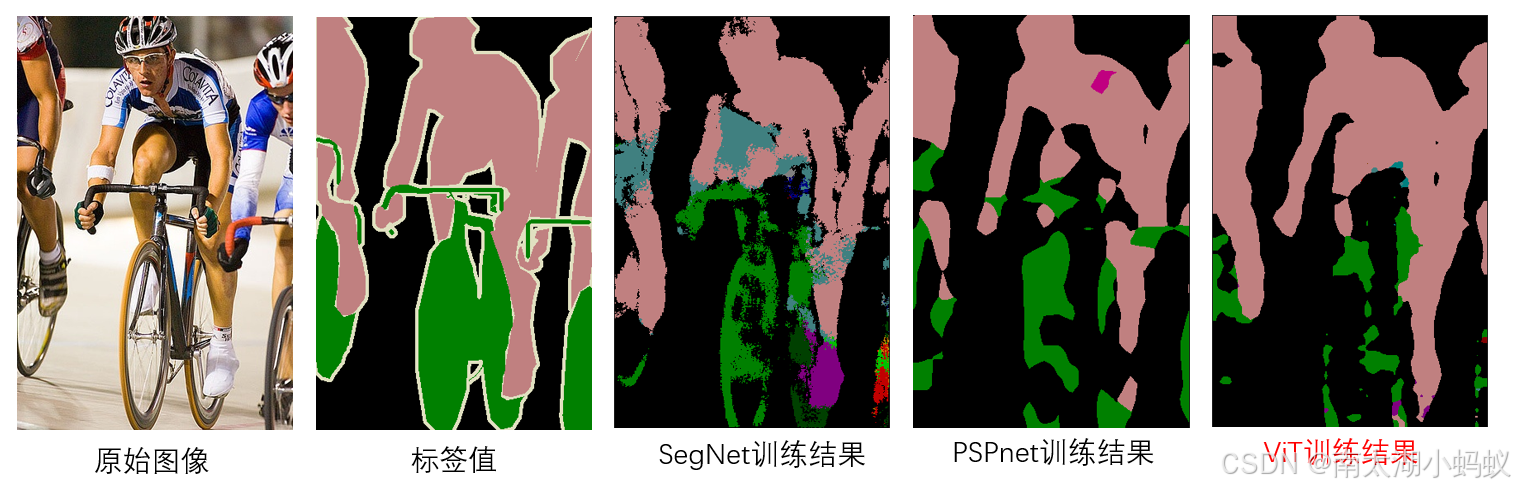
对遥感影像解译数据集GID进行训练,学习率0.01,batch_size设置为8,训练100个epoch,总体精度达到0.927,各类别精度如下:
2024-12-19 09:24:29,863 - __main__ - DEBUG - --------------------------------------
2024-12-19 09:24:29,863 - __main__ - DEBUG - |0|background|0.91|
2024-12-19 09:24:29,863 - __main__ - DEBUG - |1|building|0.87|
2024-12-19 09:24:29,863 - __main__ - DEBUG - |2|farmland|0.94|
2024-12-19 09:24:29,863 - __main__ - DEBUG - |3|tree|0.22|
2024-12-19 09:24:29,863 - __main__ - DEBUG - |4|grass|0.54|
2024-12-19 09:24:29,864 - __main__ - DEBUG - |5|water|0.85|
2024-12-19 09:24:29,864 - __main__ - DEBUG - --------------------------------------由于林地和草地训练样本比较少,所以精度不佳,但是对于大片的如农田,建成区和水系,总体精度还是不错的,解译图如下,可以看到VitSeg的边界完整度其实是优于前面的几个模型的:


















 1131
1131

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









