







Training-Free Activation Sparsity in Large Language Models
目录
1. 引言
大型语言模型(LLMs)在参数数量和训练数据规模上的扩展使其具备了强大的下游任务能力。然而,由于参数量庞大,这些模型在推理阶段会面临计算和存储上的挑战。在小批量(small-batch)推理部署场景中,自回归推理主要受内存带宽限制,即受限于从离芯存储(off-chip)到片上存储(on-chip)的权重移动速度。相比之下,模型训练和预填充推理(prefill inference)通常受计算能力限制。
现有方法尝试通过 权重量化(weight quantization)和 稀疏化(sparsification)来克服这一内存瓶颈。权重量化可以减少内存需求,而稀疏化则可以减少计算量。然而,大多数稀疏化方法需要额外的训练,例如基于 ReLU 的方法,或者需要数千亿 token 的持续训练(continued pre-training)。这些限制了稀疏化方法的实际应用。
本研究提出 TEAL(Training-Free Activation Sparsity in LLMs),一种简单的、无训练的激活稀疏方法,采用基于幅度剪枝(magnitude pruning)的策略,在整个模型的隐藏状态中应用稀疏化。
TEAL 可在 Llama-2、Llama-3 和 Mistral 等模型系列(规模从 7B 到 70B)上实现 40%-50% 的全模型稀疏性,同时保持最小的性能损失。通过优化稀疏计算核,在 40% 和 50% 的模型稀疏性下分别实现了1.53× 和 1.8× 的推理加速。此外,TEAL 还可以与权重量化结合,实现更高效的推理。
2. 相关工作
2.1 条件计算
条件计算(Conditional Computation)通过选择性激活模型的部分参数来减少计算量。例如,Mixture-of-Experts(MoE) 采用条件计算,在语言模型的前馈网络(FFN)部分选择性激活一部分专家(experts),从而降低计算成本并优化模型扩展性。
2.2 激活稀疏性
激活稀疏性指的是模型隐藏状态中大部分单元值为零的情况。在基于 ReLU 的模型中,这种稀疏性自然存在。例如,在 ReLU 变体的 Transformer 模型中,中间状态的稀疏度可达 95%。DejaVu 通过预测未来层的激活稀疏模式,在 OPT-175B 模型上实现了 2× 的推理加速。然而,由于现代 LLM 逐渐采用 SwiGLU 代替 ReLU,使得原生激活稀疏性大幅降低,这些方法在新模型上难以适用。
2.3 无训练激活稀疏性
近期研究试图在新架构中重新引入激活稀疏性。例如:
- ReLUfication:将 SiLU/GELU 替换为 ReLU,并进行大规模的继续预训练,以恢复模型的高激活稀疏性。
- CATS(Context-Aware Thresholding for Sparsity):在 SwiGLU 结构中,对 Wgate 层的输出进行剪枝,从而实现无训练的稀疏化,但整体模型的稀疏度仅 25%。
相比之下,TEAL 方法的优势在于:
- 无需任何训练即可应用稀疏性。
- 针对 LLaMA 结构的激活分布特性,采用幅度剪枝来控制稀疏化程度。
- 适用于所有层的稀疏化,而非仅限于 MLP 结构。
3. 背景:神经网络中的激活稀疏性
神经网络的激活稀疏性可分为:
1)输入稀疏性(Input Sparsity):当计算 y = x·W^T 时,若 x 中某些元素为零,则对应的权重列 W_{:,i} 不会被使用。
2)输出稀疏性(Output Sparsity):当计算 y = s⊙(x·W^T) 时,若 s 中某些元素为零,则对应的权重行 W_{i,:} 不会被使用。
最近的研究利用了 GLU 变体上的输出稀疏性,将
![]()
视为掩码,并将输出稀疏性应用于 x·W^T 上。直觉上 σ(·) 充当门控机制。
在 LLM 推理阶段,计算 x·W^T 的时间主要受内存带宽限制。因此,减少不必要的数据传输可实现加速。GPU 读取数据时通常按列存储,因此输入稀疏性适用于列优先存储(column-major storage),而输出稀疏性适用于行优先存储(row-major storage)。
4. TEAL 方法
4.1 关键观察
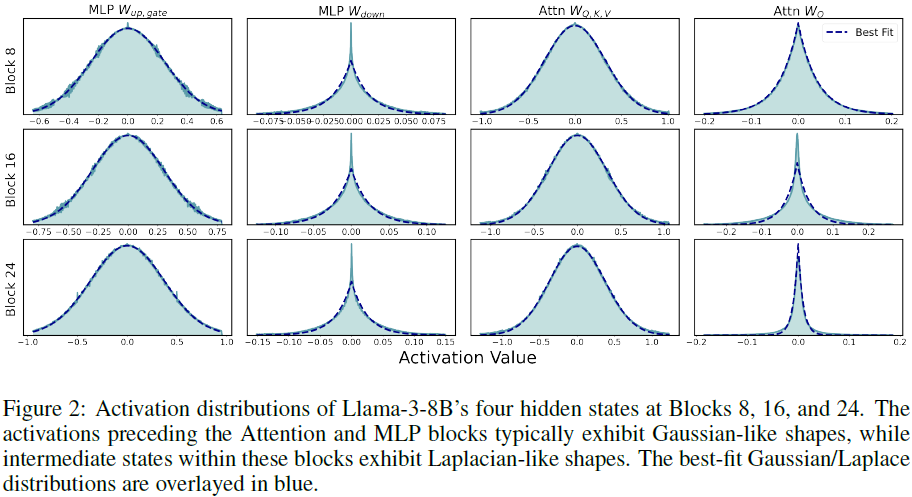
LLaMA 架构的隐藏状态通常是零均值单峰分布。
在注意力层和 MLP 层前的激活通常呈高斯分布,而在这些层内部的激活呈拉普拉斯分布。
这些分布的中心区域可以安全地剪枝,从而减少计算量。
4.2 幅度剪枝
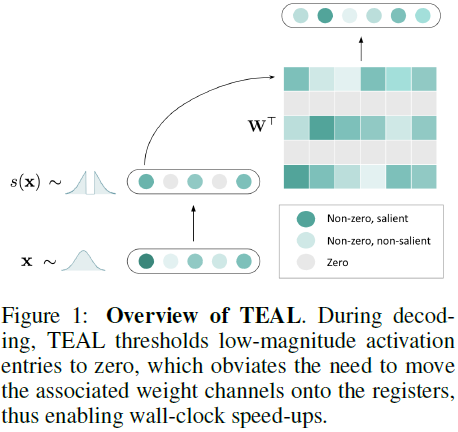
TEAL 采用幅度剪枝(magnitude pruning)策略,即移除低幅度的激活值。具体步骤如下:
1)设定目标稀疏度 p。
2)计算阈值 t_p,使得满足
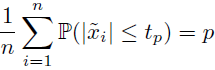
其中,˜x = (˜x_1, . . . , ˜x_n) 是随机向量。
3)采用剪枝函数:
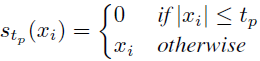
令 W 为模型的 MLP 和 Attention 块中的矩阵集,N = |W|。我们将模型级稀疏化配置定义为 p = (p_1, ..., p_N),其中 p_i ∈ [0, 1] 表示相应矩阵 W_i 的稀疏度级别。
4.3 块级贪心优化

使用基于梯度的方法来基于直通估计器(straight through estimator)学习阈值时,面临优化问题。因此,TEAL 采用块级(block-wise)贪心搜索来优化稀疏度分配:
- 初始化所有层的稀疏度为 0。
- 逐步增加每层的稀疏度,将每层的稀疏度增加与其内存占用成反比的量,并计算相应的误差。
- 增加具有最低误差的层的稀疏度,并记录块级稀疏度和相关的层级稀疏度
所有 Transformer 块分配相同的块级稀疏度;因此,所有块都具有相同的目标稀疏度,但不同块之间的各个层级稀疏度可能不同。
4.4 硬件加速
我们开发了一个专门的稀疏 GEMV 内核来实现加速,该内核基于 DejaVu 引入的基于 Triton 的内核。该内核接受输入 x、布尔稀疏掩码 s 和矩阵 W,并返回 (x ⊙ s)·W^⊤。
加速通过三种方式实现:
- W 以列为主的格式存储,以实现最佳内存合并;
- 根据 s_i 的真值选择性地加载列 W_{:,i};
- 使用 SplitK 工作分解,实现跨线程块的更细粒度并行性,通过原子添加组合部分结果。
5. 实验结果
5.1 准确率评估
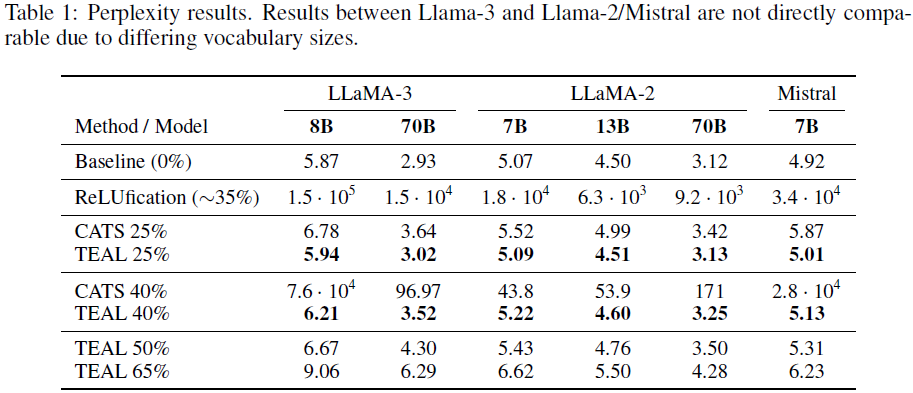
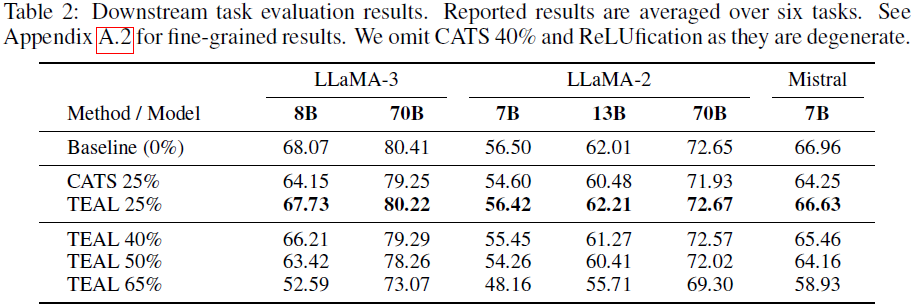
在 40% 稀疏度下,LLaMA-3-8B 的 PPL(困惑度)仅从 5.87 上升到 6.21,损失极小。
TEAL 比 CATS 精度更高,因其稀疏性分配更均衡。
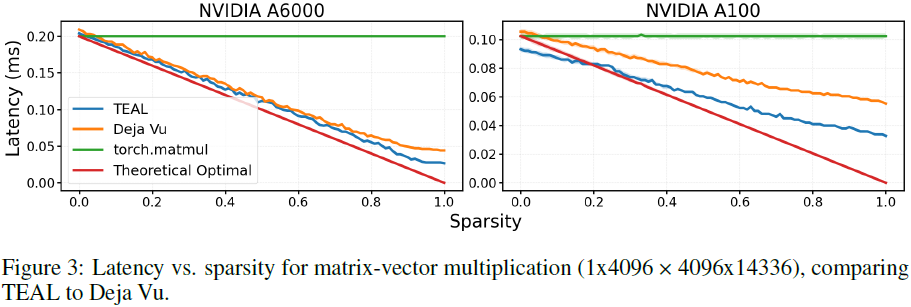
5.2 端到端解码加速
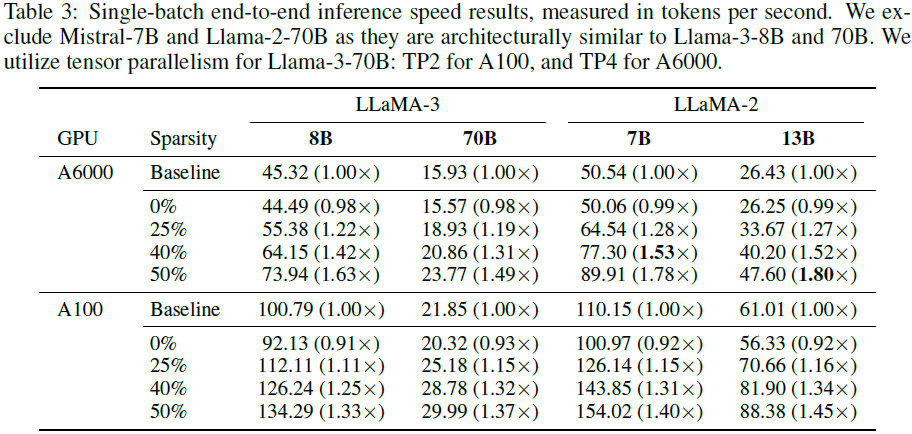
在 A100 GPU 上:
- 40% 稀疏度加速 1.53×
- 50% 稀疏度加速 1.8×
A6000 上速度更快,因其内存带宽较低。
5.3 量化兼容性
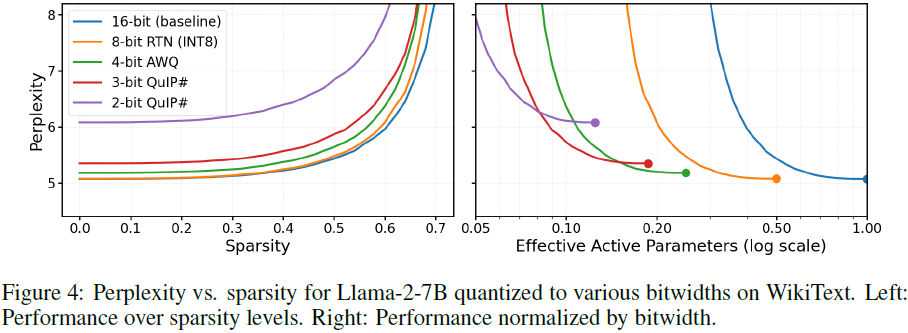
TEAL 可与 8-bit、4-bit、2-bit 量化结合,进一步提升效率。
5.4 详细分析
5.4.1 W_up 层的稀疏性选择
TEAL 采用输入稀疏性,而 CATS 采用输出稀疏性。实验结果表明,TEAL 误差更低,因为 SiLU 输出不会严格等于 0,而 CATS 可能错误剪枝低幅值但重要的值。
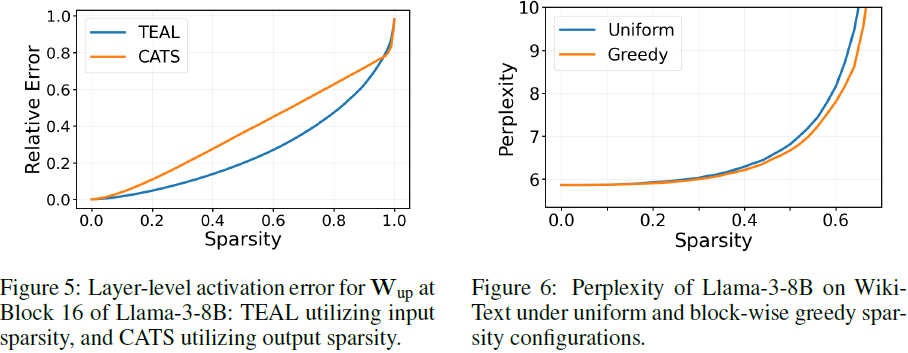
5.4.2 贪心优化的稀疏性分布
相比均匀(Uniform)稀疏,贪心优化(Greedy)的 PPL 更低,说明方法有效。
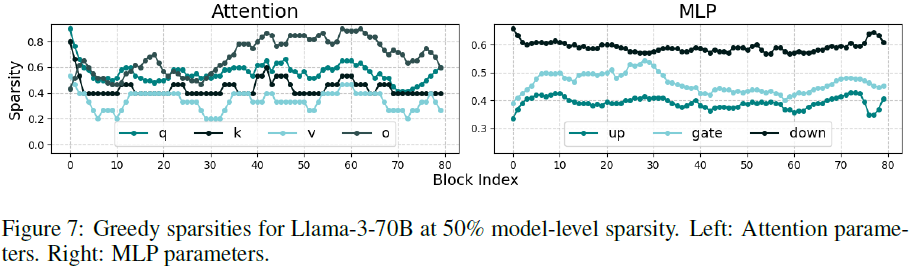
注意力模块 W_o 在模型中间层的稀疏性最高(80-90%),可能与注意力机制的不同层次重要性有关。
MLP 组件中,W_down 稀疏性最高,W_up 稀疏性最低。
5.4.3 预填充稀疏化
稀疏化后半部分预填充(prefill)对 PPL 影响较小,但对初始 tokens 进行剪枝会导致性能下降,这是由于初始 tokens 在注意力机制中占据重要位置。建议在 log-likelihood 任务中应用此优化,而生成任务不适用。
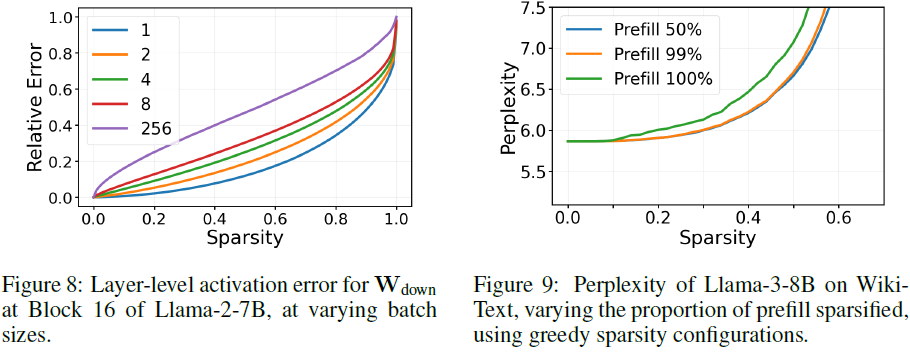
5.4.4 批量稀疏化
TEAL 适用于单批量(single-batch)推理,但在多批量推理中,由于不同样本的激活模式不同,稀疏模式难以统一。可以采用基于批量均值的剪枝策略,在 batch 维度上计算平均激活值并剪枝。初步实验表明,小批量情况下仍然有较高的稀疏性,但大批量推理需要进一步优化。
6. 结论
本研究提出 TEAL 方法,无需训练即可在 LLM 中实现 40-50% 的激活稀疏性,同时保证性能稳定。TEAL 兼容权重量化,可进一步提升推理效率。未来研究可探索在小批量推理场景中的应用,如边缘计算设备。
局限性: 大批量推理效果有限,但可通过训练增强进一步优化。
论文地址:https://arxiv.org/abs/2408.14690
项目页面:https://github.com/FasterDecoding/TEAL
进 Q 学术交流群:922230617 或加 V:CV_EDPJ 进 V 交流群

















 2084
2084

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









