







Eagle: Exploring The Design Space for Multimodal LLMs with Mixture of Encoders

目录
1. 引言
随着大语言模型(LLM)的成功,人们对其视觉感知能力的兴趣大幅增加,希望使其能够 “看见”、理解和推理真实世界的视觉信息。目前的多模态大语言模型(MLLM)主要采用视觉编码器将图像转换为视觉 token,并与文本 embedding 结合。然而,大多数现有模型受限于预训练的视觉编码器和 LLM 的序列长度,导致输入分辨率较低,影响了对复杂视觉信息(如光学字符识别 OCR、文档分析等)的处理能力。
本研究系统地探索了 MLLM 中 混合视觉编码器(Mixture of Vision Encoders)的设计空间,分析不同的编码器选择及其组合方式。研究表明,仅通过简单的视觉 token 拼接即可获得与复杂融合策略相当的效果。此外,引入 预对齐(Pre-Alignment)策略,可有效减少视觉编码器与 LLM 语言 token 的差距,提升模型一致性。最终,我们提出了 Eagle 模型系列,该模型在多个 MLLM 基准测试中超越了当前最先进的开源模型。
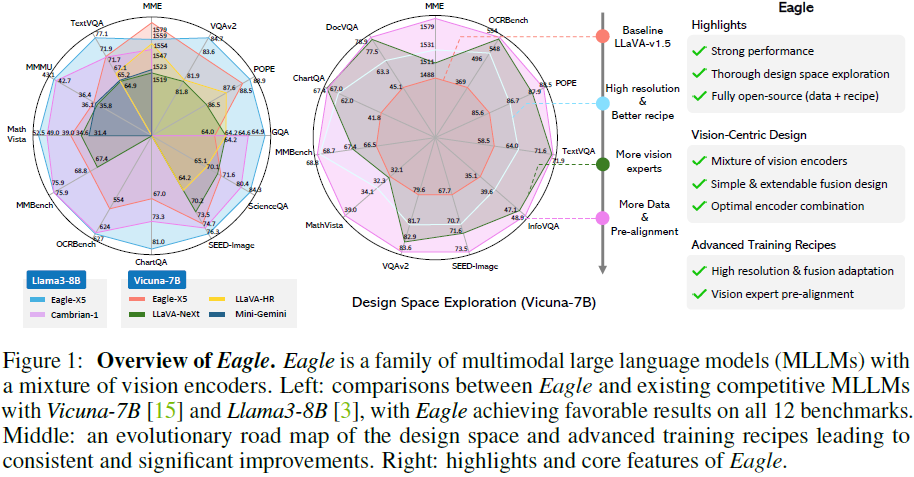
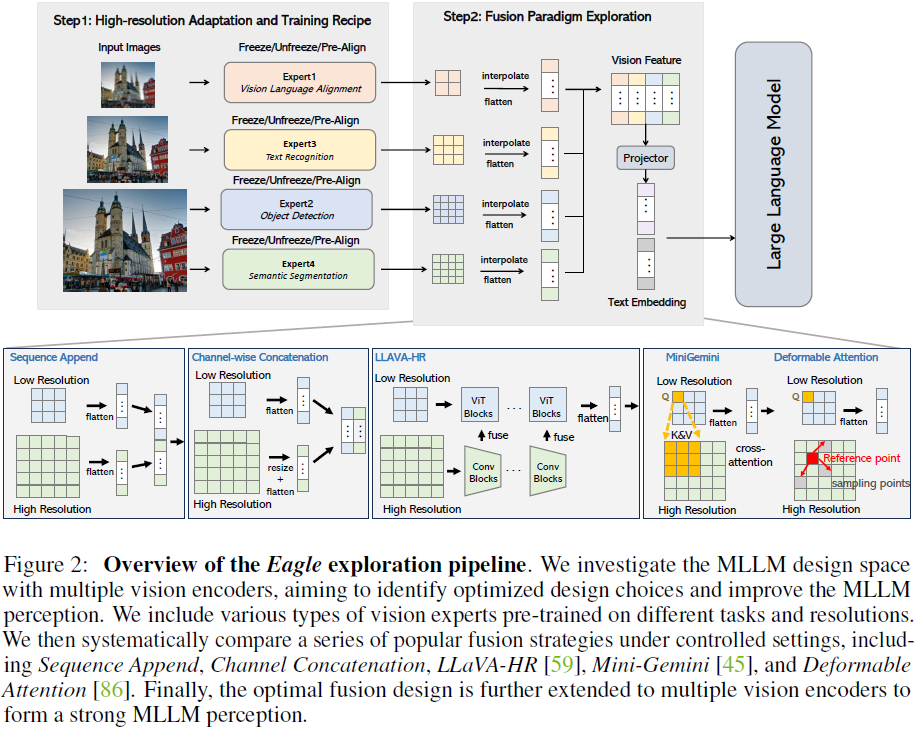
2. 设计空间探索
如图 2 所示,
- 将基本 CLIP 编码器扩展为具有不同架构、预训练任务和分辨率的一组视觉专家
- 然后,利用这些专家比较不同的融合架构和方法,并研究如何在给定更多编码器的情况下优化预训练策略
- 还对如何选择要集成的视觉编码器进行了详细分析
- 将所有发现汇总在一起,并进一步扩展到具有不同分辨率和领域知识的多个专家视觉编码器。
2.1 基础设定
Eagle 基于 LLaVA-1.5 架构,包括:
- 大语言模型(LLM):Vicuna-7B
- 视觉编码器:初始使用 CLIP
- 投影层:将视觉 embedding 投影到文本 embedding 空间
训练数据:
- 预训练数据:595k 图文对
- 监督微调数据:934k 样本,包含 LLaVA-1.5、DocVQA、ChartQA 等数据集
2.2 更强的 CLIP 编码器
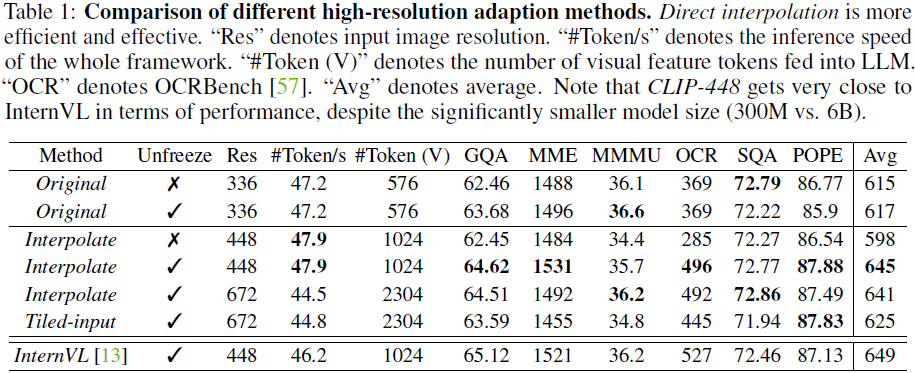
实验发现,解冻 CLIP 编码器并提升最大输入分辨率从 336×336 至 448×448,可显著提高 MLLM 性能。除了多补丁输入(tiling)并对补丁分别编码的方法外,直接上采样输入分辨率并插值 ViT 的位置编码更加高效。
- 当插值至与 CLIP 预训练分辨率不同的更高 MLLM 输入分辨率时,解冻 CLIP 编码器可带来显著改进。当分辨率保持不变时,性能也不会下降。
- 当 CLIP 编码器冻结时,直接将其调整到更高的 MLLM 输入分辨率会严重损害性能。
- 在比较的策略中,使用解冻的 CLIP 编码器直接插入到 448 × 448 在性能和成本方面既有效又高效。
- 尽管模型大小明显较小(300M 对 6B)且预训练数据较少,但最佳 CLIP 编码器的性能接近 InternVL。
2.3 多任务视觉专家
为了增强 MLLM 感知能力,我们引入不同任务预训练的视觉编码器:
- 图文匹配(Vision-Language Alignment):CLIP、ConvNeXt
- 目标检测(Object Detection):EVA-02
- 光学字符识别(OCR):Pix2Struct
- 语义分割(Semantic Segmentation):SAM
- 自监督学习(Self-Supervised Learning):DINOv2
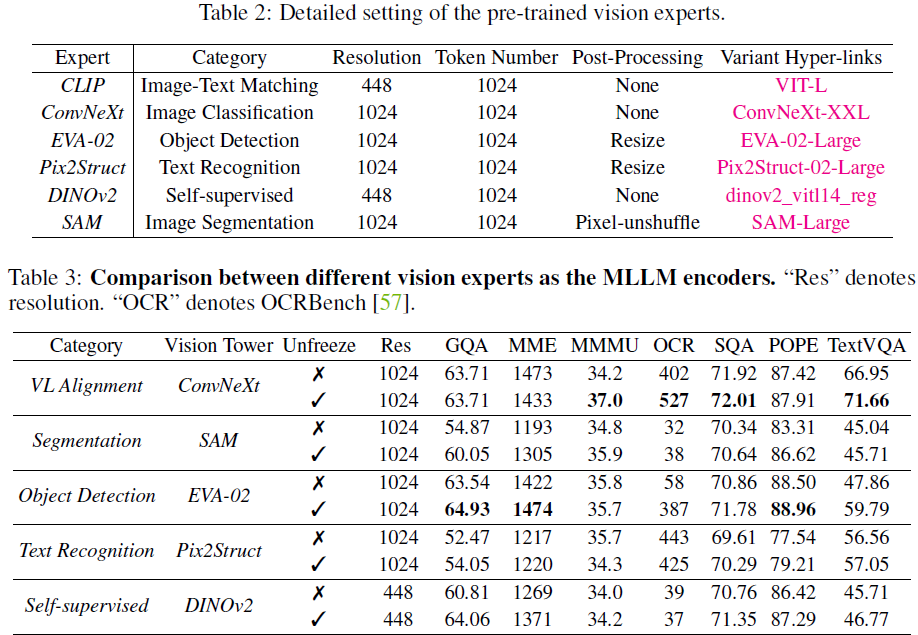
实验结果表明,EVA-02 在目标检测任务上表现最佳,Pix2Struct 在 OCR 任务上表现最优,而 CLIP 和 ConvNeXt 则在扩展的任务中表现稳定。
2.4 视觉融合策略
不同的融合策略对多视觉编码器的整合效果不同:
- 序列追加(Sequence Append,SA):直接将多个编码器的视觉 token 连接
- 通道拼接(Channel Concatenation,CC):在通道维度拼接 token
- LLaVA-HR(LH):使用混合分辨率适配器
- Mini-Gemini(MG):跨窗口注意力机制
- 可变形注意力(Deformable Attention,DA):替换 Mini-Gemini 的窗口注意力
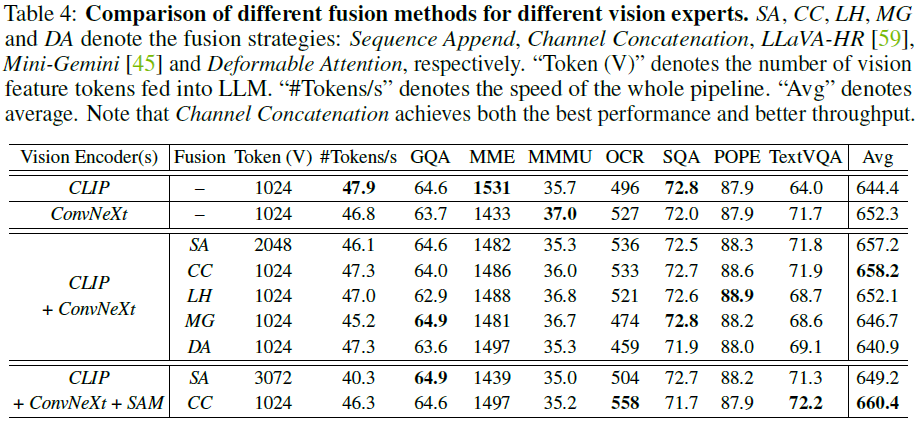
实验表明,通道拼接(Channel Concatenation)策略在性能与吞吐量上均表现最佳。
2.5 视觉-语言预对齐(Pre-Alignment)
由于某些视觉专家(如 EVA-02)并未在文本任务上预训练,可能导致表征不匹配。为此,我们提出 预对齐(Pre-Alignment)策略:
- 个别视觉编码器与 LLM 预对齐(保持 LLM 冻结,仅训练投影层)
- 联合训练投影层(使用图文对数据)
- 最终微调(使用监督数据训练整个模型)
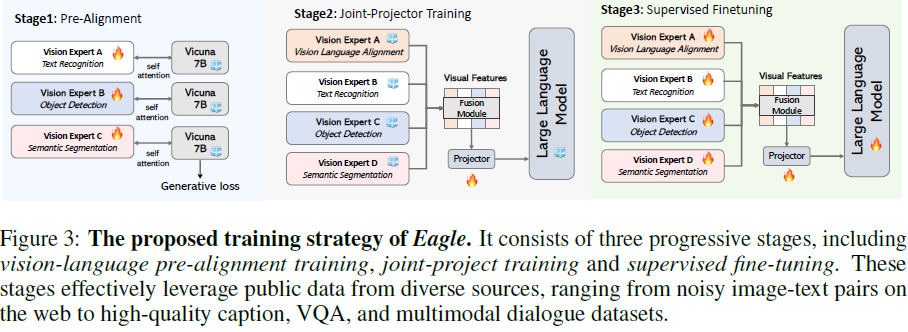
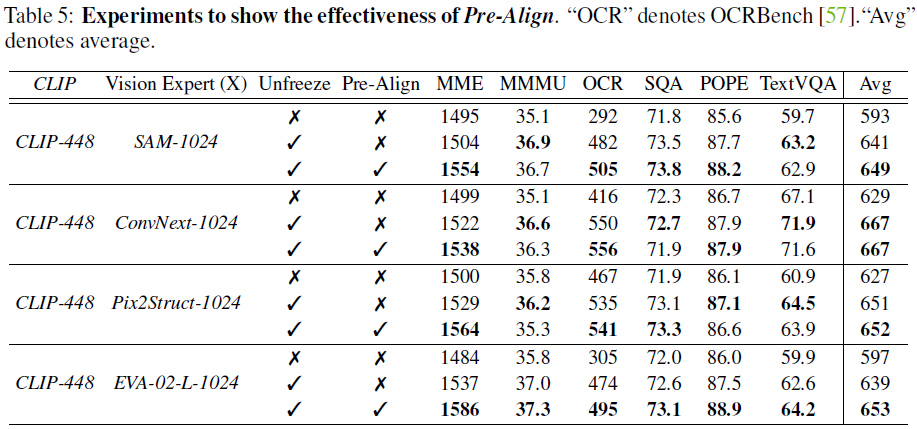
实验表明,预对齐可有效减少视觉专家的表征差异,稳定训练过程,提升模型整体性能。
2.6 扩展至多视觉专家
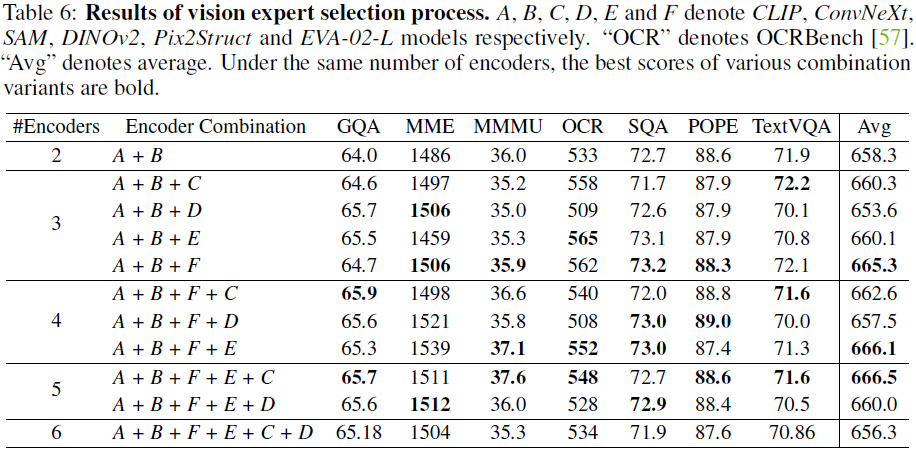
采用贪心搜索策略,我们逐步引入新的视觉专家。最终发现,CLIP、ConvNeXt、SAM、Pix2Struct、EVA-02 的组合表现最佳,因此用于 Eagle 最终模型。
3. 实验与评测
3.1 主要评测
我们在多个任务上评测 Eagle:
- 视觉问答(VQA):GQA、VQAv2、VizWiz
- OCR与图表理解:OCRBench、TextVQA、ChartQA
- 多模态基准测试:MME、MMBench、SEED、MathVista、MMMU、ScienceQA、POPE
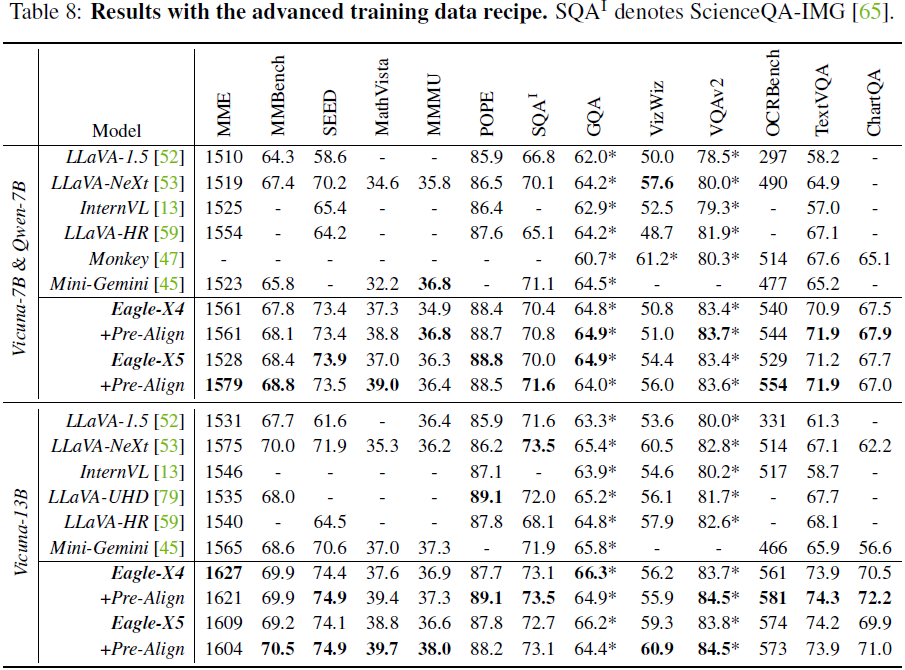
主要结果
- Eagle-X5 在 VQA 任务(GQA、VQAv2)上取得最先进性能
- 在 OCRBench 和 TextVQA 上超越所有基准模型
- 在 POPE 基准测试上表现突出,降低视觉幻觉问题
- 预对齐策略进一步提升模型性能
3.2 与 Cambrian-1 对比
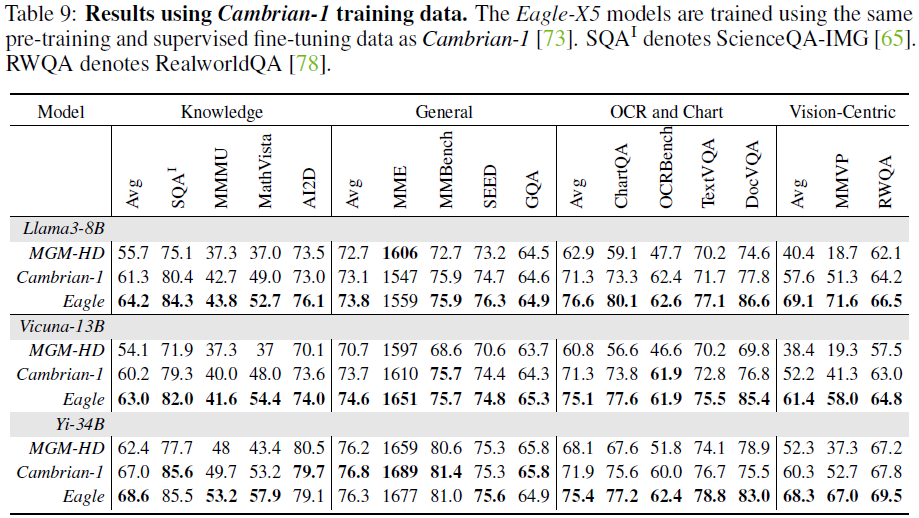
使用相同的训练数据(2.5M 预训练数据 + 7M 微调数据),Eagle 相较 Cambrian-1 表现更优:
- 在OCR与图表理解任务上大幅领先
- 在知识推理与视觉理解任务上均有明显提升
4. 相关工作
4.1 多模态 LLM 架构
根据视觉信号如何融入语言模型,MLLM 大致可分为 跨模态注意 和 前缀微调(Prefix-Tuning)。前者使用跨模态注意将视觉信息注入 LLM 的不同层,而后者将视觉 token 视为语言 token 序列的一部分,并直接将其附加到文本嵌入中
Eagle 属于前缀微调类别,其核心设计类似于 LLaVA,但采用了混合视觉编码器。
4.2 视觉编码器优化
高分辨率适配:LLaVA-UHD、InternVL等模型使用 Tiling 方法,而 Eagle 采用混合视觉专家策略
多视觉编码器融合:Mini-Gemini、Mousi 等模型采用复杂融合策略,而 Eagle 采用更简单的通道拼接
5. 结论
本研究系统探索了多视觉编码器在 MLLM 中的设计空间,发现了一系列关键设计原则:
- 解冻视觉编码器并提高分辨率可显著提升 MLLM 性能
- 通道拼接是一种高效的多视觉专家融合策略
- 预对齐策略可改善不同视觉编码器之间的表征一致性
- 逐步引入多个视觉专家可持续提升模型感知能力
最终,Eagle 模型在多个基准测试上超越现有最先进模型,并提供了一个性能强大且易于复现的 MLLM 解决方案。
论文地址:https://arxiv.org/abs/2408.15998
项目页面:https://github.com/NVlabs/Eagle
进 Q 学术交流群:922230617

















 2083
2083

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









