







PyramidBox阅读笔记
PyramidBox: A Context-assisted Single Shot Face Detector(ECCV 2018)
论文链接:论文链接
代码链接:代码链接,原版代码在paddle,但是现在不知道为什么找不到了,这里提供的是其他版本
- 我是专门来看这篇文章中的context的做法的
- context能不能用于进行坐标回归里面,而不仅仅用在分类当中
- context相关论文:CMS-RCNN、SSH、FAN
动机
- 使用context解决小目标,模糊目标,部分遮挡的目标检测
解决方案
- 整体方案(基于context)
- Low-level Feature Pyramid Network(LFPN):将足够的high level特征和 low level 的特征结合在一起
- Context-sensitive prediction module (CPM):引入context信息
- PyramidAnchors:设计一种“context anchor”,通过半监督方法监督high level上下文特征学习
- Data-anchor-sampling:增加不同尺度的训练样本数量
网络结构
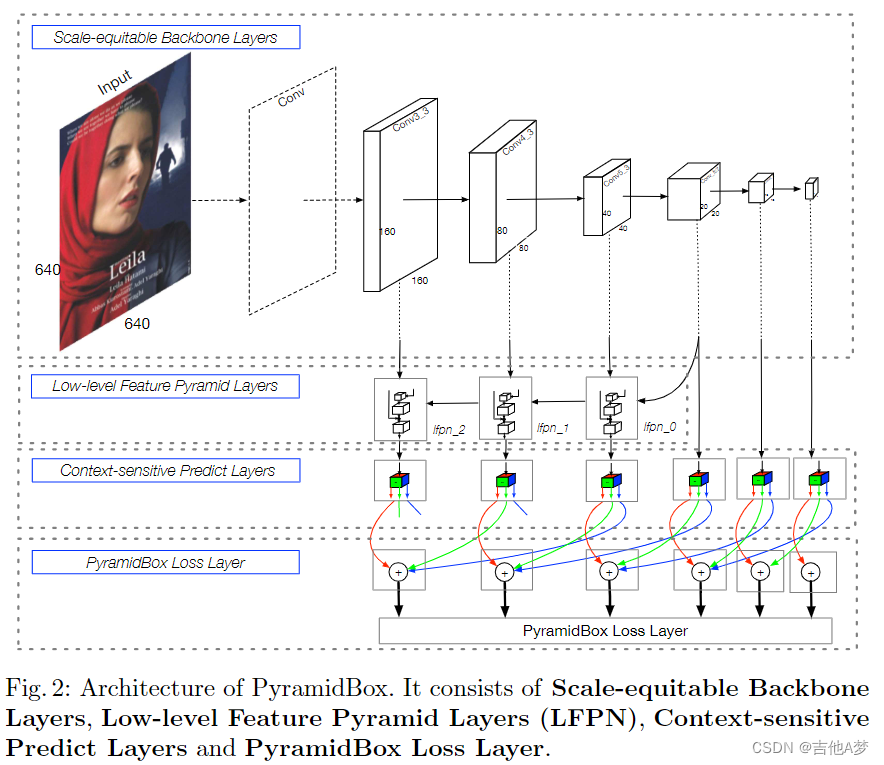
(能不能不要下采样,因为下采样之后,high-level的特征对应原图感受野太大了,特征融合之后的效果感觉更多的是一个整体的特征,并不能精细化)
Low-level Feature Pyramid Network(LFPN)

- 和FPN不一样的地方在于,LFPN将低层的一些特征进行了融合,而高层特征因为感受野太大了,不适合用于人脸检测
Context-sensitive Predict Module(CPM)
- CPM借鉴了SSH和DSSD。SSH通过在不同分支上不同的stride+conv堆叠来扩展感受野大小,学习更多的contextual information;DSSD使用residual block,得到deeper的预测分支。将SSH中的context module中的conv层换成DSSD的残差预测模块,这样CPM同时包含了DSSD+SSH的上下文信息的优势
- CPM的输出。 w l × h l × c l w_l×h_l×c_l wl×hl×cl,其中 w l = h l = 640 2 2 + l w_l=h_l=\frac{640}{2^{2+l}} wl=hl=22+l640(和LFPN每个输出特征图的大小一致),通道 c l = 20 c_l=20 cl=20,每个通道的特征分别用来进行分
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 4873
4873











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









