






 文章探讨了Transformer在视觉任务中的表现,指出未经调整的Transformer在大规模数据集上可媲美或超越CNN,但在中等数据集如ImageNet上可能因缺乏归纳偏置导致精度下降。CNN的归纳偏置包括局部性和平移等变性,适合处理空间结构数据,而Transformer擅长序列数据的语义特征提取。两者在计算复杂度和应用场景上也有所差异。
文章探讨了Transformer在视觉任务中的表现,指出未经调整的Transformer在大规模数据集上可媲美或超越CNN,但在中等数据集如ImageNet上可能因缺乏归纳偏置导致精度下降。CNN的归纳偏置包括局部性和平移等变性,适合处理空间结构数据,而Transformer擅长序列数据的语义特征提取。两者在计算复杂度和应用场景上也有所差异。
vit论文指出:
transformer在大规模的数据集上做预训练的话,那么我们就可以让一个标准的transformer,不在视觉上做更改,即可取的超越或同等目前最强cnn的效果。
在中等数据集比如imagenet上,如果没有强规则对transformer进行约束,精度会比resnet低几个点。作者认为transformer跟cnn相比,缺少一些inductive biases(归纳偏置)
归纳偏置是指先验知识,即指我们做好的假设,cnn的两个归纳偏置:
-
locality:假设图片上相邻的区域有相邻的特征,比如桌子和椅子一般在一起,卷积核滑动一点点卷积。
-
translation equivariance:平移等变性,先做平移和先做卷积,都是一样的。
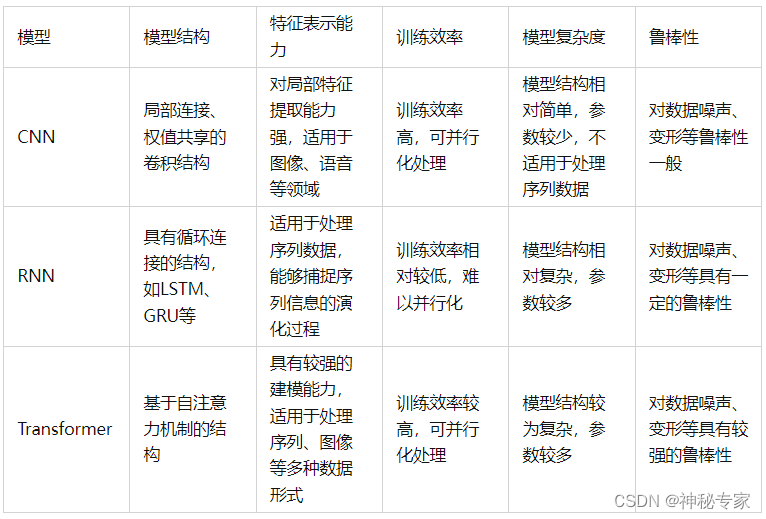
chatgpt的回答:
CNN(卷积神经网络)和Transformer都是深度学习中非常重要的模型结构,在不同领域都有广泛的应用。它们的区别主要体现在以下几个方面:-
输入形式:CNN主要应用于处理图像、语音等空间结构数据,而Transformer主要应用于自然语言处理中的序列数据。
-
特征提取方式:CNN通过一系列卷积和降采样操作,提取图像等数据的空间特征,而Transformer则利用自注意力机制提取序列数据中的语义特征。
-
结构形式:CNN具有层次结构,一般由多个卷积层和池化层交替组成;而Transformer则是由多个自注意力机制和前馈网络构成的编码器和解码器组成,可用于序列到序列的任务。
-
应用场景:由于CNN擅长处理空间数据,因此广泛应用于图像识别、物体检测等计算机视觉领域。而Transformer主要应用于机器翻译、文本分类、机器阅读理解等自然语言处理领域。
-
计算复杂度:相比于CNN,Transformer计算复杂度相对较高,因为自注意力机制需要计算所有序列位置之间的相似度,不能利用卷积等局部计算方法,因此在处理较长序列时,可能会遇到计算资源或时间上的瓶颈。
总之,CNN和Transformer分别适用于不同类型的数据处理任务,具有各自独特的特点和应用场景。在实际应用中,需要根据具体情况来选择合适的模型结构。
-

















 1444
1444

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









