






 文章提出了一种名为TPNet的新型网络,利用LSTM处理时间序列数据进行目标预测,应用于无人机的追逃任务。通过在Unity3d仿真环境中训练,考虑了无人机坠毁和多agent合作的问题。采用了双向LSTM和AC结构,评论员获取全局信息,行动者处理局部信息。实验设定包括二维空间、速度和加速度限制,以及合作与竞争的目标追踪奖励函数。
文章提出了一种名为TPNet的新型网络,利用LSTM处理时间序列数据进行目标预测,应用于无人机的追逃任务。通过在Unity3d仿真环境中训练,考虑了无人机坠毁和多agent合作的问题。采用了双向LSTM和AC结构,评论员获取全局信息,行动者处理局部信息。实验设定包括二维空间、速度和加速度限制,以及合作与竞争的目标追踪奖励函数。
创新点:
1.基于长短期记忆网络LSTM(处理有时间关系的数据)设计了TPNet,实现目标预测,达成先预测后决策的目的。(将预测的思想引入无人机领域)
采用监督学习的方法,训练数据包括:n个时间步长训练数据px(目标位置、agents位置和速度)和k个时间步长标签数据py(目标位置)。
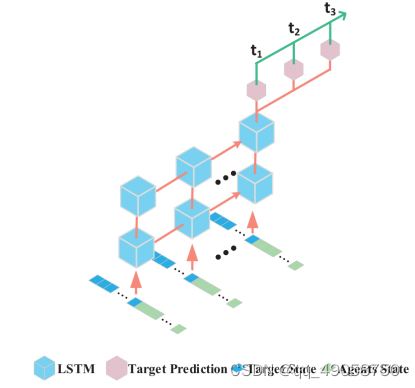
2. 使用更逼真的仿真引擎Unity 3d,构建的用于无人机追逃的仿真环境。
3.改进DRL框架,考虑无人机的坠毁问题。(可变数量的agents)
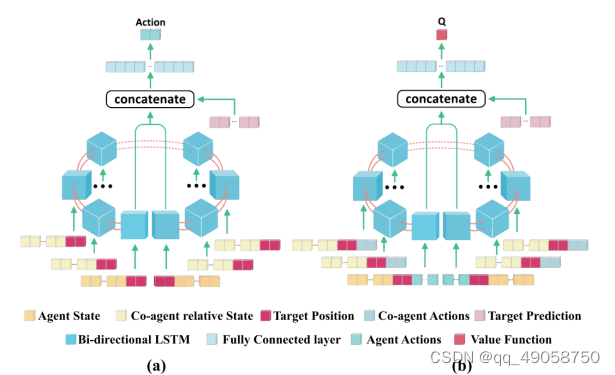
使用bilstm 双向lstm结构来处理信息。采用AC结构,评论员能获取全局信息,行动者只能获取局部信息。
实验假设:
二维平面,无人机飞行在不同高度,不会相撞。
Target的最大速度 大于agent
Target的最大加速度 小于agent
任务目标:2米内5个时间步。
Agents间只合作,与target竞争
奖励函数:
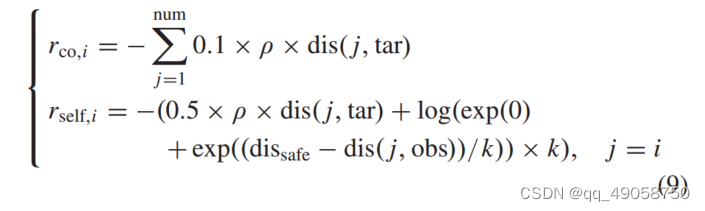
包括合作奖励和个人奖励。Dis(j,tar)表示智能体j到目标的距离。

















 887
887

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









