






前言
首先感谢se3tracket的研究作者及其团队发布的文章与源码,以及一众大佬作的翻译和解析,在之前大佬的基础上,我提出一点自己的拙见。
文章内容回顾
对机器人的操作来说,追踪视频序列中物体的6D姿态是非常重要的。并且现在这项任务面临着很多挑战:
- 机器人操作中有很多明显的遮挡物。
- 对于6D姿势来说,数据和注释的收集很麻烦,也很困难,这使得机器学习解决方案变得复杂。
- 在长期的跟踪中,增量误差偏移经常会累积到需要重新初始化对象的姿势。
作者提出了一种数据驱动的优化方法,可以用来长期、6D姿势跟踪。它的目的是给定当前的RGB-D观测值和以先前的最佳估计和物体模型为条件的合成图像,确定最佳的相对姿势。作者还提出了一种新型的神经网络架构,它能够适当地拆分特征编码,目的是帮助减少域的偏移,并通过Lie Algebra进行有效的3D方向表示。因此,即使只使用合成数据对网络进行训练,也能在真实图像上有效地工作。
改进的基本思想
目标6D姿态估计旨在估计相机坐标系下目标的位置和方向。该项技术不仅是人工智能领域、增强现实领域和人机交互领域等高级图像处理领域的核心,也是计算机视觉领域的研究热点。传统方法采用人工设计的方法提取特征,并基于这些特征执行投票策略、关键点匹配和模板匹配等算法解耦出目标的6D姿态,但传统算法在遮挡、固有的几何模糊性和庞大的特征搜索空间等诸多限制下,算法性能较低。依托于充足的RGB-D图像数据,基于深度学习数据驱动的6D姿态估计技术凭借强大的表征能力、面对数据噪声的鲁棒性以及良好的准确率,在性能上逐渐取代了传统的姿态估计算法。然而获取RGB-D图像需要专业设备,深度学习训练网络模型需要大量人工标注的数据,这导致了采用深度学习的方式及进行姿态估计成本极高,在后续高级应用中将会带来很大的挑战。为此,本文提出了一种复用预测网络模型,在依靠少量的数据训练网络模型的同时保持良好的准确率,总结下来就是一句话:大佬网络够精准了,我很难提升上去了。但是我选择另一个角度—就是使用更少的数据来训练网络,以达到同样水准。(有可能在同样少数据量的条件下,超越原作者的网络),有小伙伴可能会说,原文已经提到合成数据集了,这么做没有意义,但是合成数据集与真实拍摄的数据集总归是由差距的,比如光照,阴影或者其它更复杂的物理因素干扰,这篇文章改进的思想是围绕真实的数据集开展的。
核心理论
首先,复用预测网络(这是我起的名字,后续有解释)以当前时刻的RGB-D图像和上一时刻的目标渲染值作为输入,通过两个独立的特征编码器提取特征矩阵。在其中一个特征编码器中引入通道注意力机制,通过深度学习的方式获取到每个特征通道的重要程度,从而强化重要特征通道,抑制非重要特征通道。然后构建复用预测模块,相比普通的卷积操作,复用预测模块更加注重时序信息和数据的利用率,该模块的输出结果由当前时刻的网络参数和前一时刻的输出结果共同决定。最后,利用李代数方法计算出目标的6D姿态。
在不同数量的数据集上,采用复用预测网络的方法相比较最近的先进算法Se(3)-Tracknet进行对比实验,在两个评价指标上分别提升13.75%与7.73%。由实验结果可以得出结论,复用预测网络在使用少量数据的情况下较TEASER++方法和Se(3)-Tracknet等方法有不同程度的提升。表明采用复用预测网络进行目标6D姿态估计可以减少收集与标注目标姿态数据的成本。
实现方法
框架
这里的整体框架依旧沿用原作者的框架(真的好用)
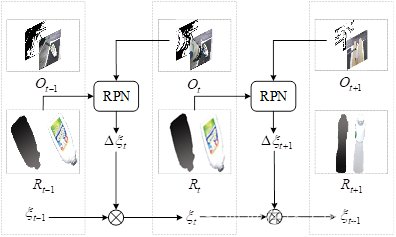
(图基本就是原图,这里就不做解释了。)
复用预测网络
复用预测网络的结构与原文不同,这里加以改进,增加了复用预测模块。
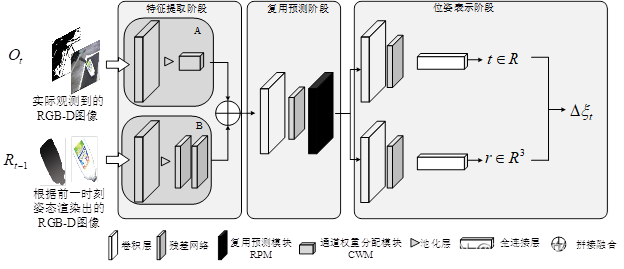
复用预测网络整体分为三个阶段:特征提取阶段、复用预测阶段以及位姿表示阶段。特征提取阶段:由两个特征提取器完成特征提取任务,通过特征提取器A和B完成对RGB-D图像的特征提取。在得到特征图后,将两个特征图进行拼接融合,并将结果传入复用预测阶段;复用预测阶段:通过提出的复用预测模块对上一阶段的结果进行处理得到可以表示目标位姿的旋转矩阵与平移矩阵并将结果传入位姿表示阶段;位姿表示阶段:通过李代数的方式使用旋转矩阵和平移矩阵对目标位姿进行计算并表示。
图中t代表时间序列,Q(t)为在t时刻的观测值(RGB-D图像),R(t)为t时刻的渲染值(RGB-D图像)。将t时刻的观测值Q和前一时刻的渲染值R(t-1)共同传入RPN中,由该网络计算出相对变换姿态△ξ,通过△ξ与t-1时刻的姿态ξ(t-1)共同计算出t时刻的姿态ξ(t) ,最后渲染出t时刻网络的预测结果R(t)。计算目标在t时刻的6D姿态需要满足的条件与原文一致,并无额外说明。
复用预测模块
图中的黑色方块就是复用预测模块,接下来主要介绍一下这个模块,
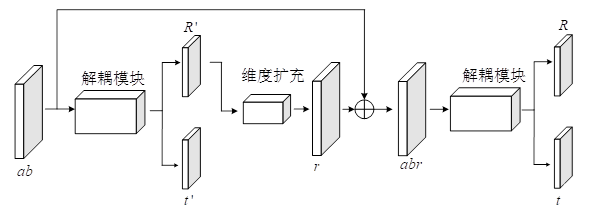
(ps:这里的公式我不太会打,所以干脆把我写的文档中的原文给拿出来了)

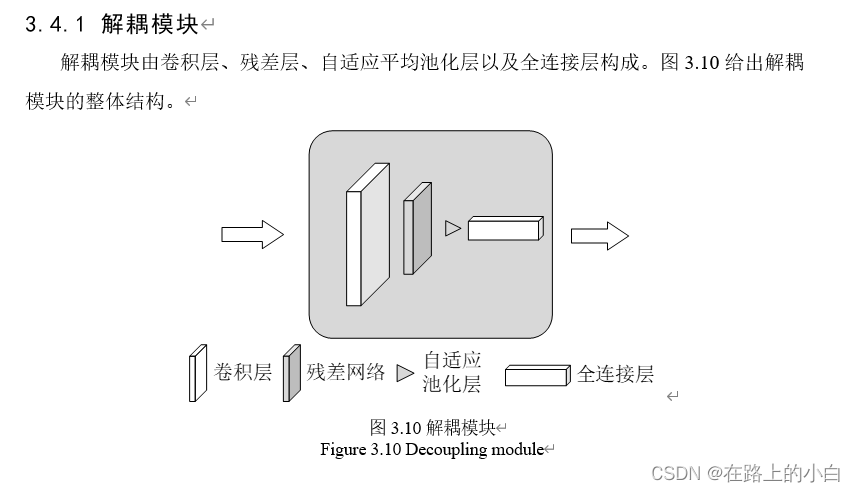

实验及可视化结果
客观结果
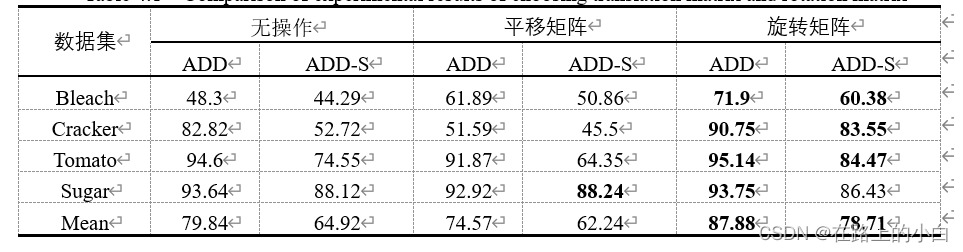
本文所提出的面向目标6D姿态估计网络,主要刚体数据收集困难,数据利用不充分的情况,在依赖少量数据的前提下,提高刚体姿态估计的准确率。下表复用预测模块中将旋转矩阵与平移矩阵分别回传与输入矩阵 融合的实验结果。结果显示,在某项指标上将旋转矩阵与 融合效果较高,但整体来看将旋转矩阵与矩阵 融合的效果更好。在两项评价指标中分别提升8%与14%左右。因此本文选择将旋转矩阵与 融合来构建复用预测模块。
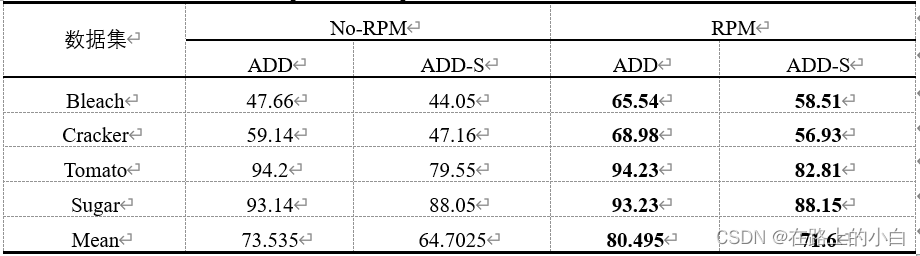
采用本文方法复用预测模块与不采用复用预测模块的se(3)-TrackNet方法进行对比实验的结果。使用复用预测模块的复用预测网络方法可以明显提高预测目标6D姿态的准确率。在两项评价指标上均高出7%左右。
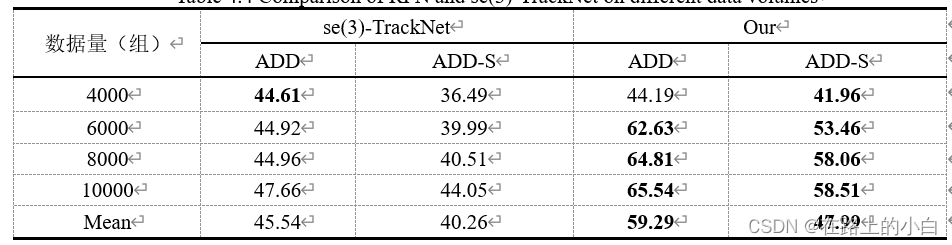
复用预测网络与目前较为先进的方法se(3)-TrackNet[29]在不同数据量的小数据集(Bleach)上估计目标6D姿态的对比的实验。由表可知,虽然复用预测网络方法在4000组数据量中ADD指标结果稍逊,但是综合考虑所有数据量上的实验,在两项评价指标上,复用预测网络方法优于se(3)-TrackNet方法6%与7%左右。
可视化结果




总结

原方法
现方法















 315
315











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









