







小罗碎碎念
在结直肠癌诊疗领域,微卫星不稳定性(MSI)检测意义重大,却受传统检测方法制约。
今天分享的这篇文章有点旧了(23年年底发的),按照我的习惯,我是不太喜欢介绍相对较久的文献的。
但是,最近知识星球总有提问微卫星不稳定性相关的问题,并且这次还给出了具体的文献,我就想着系统介绍一下。
正好,粉丝们都很感兴趣,我是怎么读文献的。那这期推送,我就一边带领大家读一下文献,一边分析用户提出的问题。
这个用户的提问很有意思,涉及到了很多非常关键的点,包括模型的选择,以及模型的微调等。由于要想回答好这个问题,就必须去看文献原文,所以我就借着这个机会写了这期推送。
在回答问题的时候,意外发现了一个写作套路——关于论文撰稿时数据量级陈述的套路,我们看看nature communication的文章,是如何合理偷换概念,造成视觉偏差的。
关于模型的微调,我也准备了一个教程——先从多分类模型的构建讲起,再介绍数据增强,最后再介绍如何对模型进行微调(明天发)。
文献速览
这篇文章聚焦于此,开发出MSIntuit这一基于AI的临床预筛查工具,为解决难题提供新方向。它借助自监督学习从大量结直肠癌病理图像中提取特征,经多步骤优化,在600例患者独立数据集上完成盲法验证。

研究结果显示,MSIntuit性能卓越。在不同扫描仪上表现稳定,敏感性高达0.96 - 0.98,能精准识别多数MSI患者,同时排除近一半非MSI人群,极大减轻检测负担。其结果具备可解释性,还优于传统临床病理评分系统。
不过,该工具也存在局限,仅在手术标本切片完成验证,活检样本上的有效性有待确认,校准环节所需样本在小中心获取困难。
交流群
欢迎大家加入【医学AI】交流群,本群设立的初衷是提供交流平台,方便大家后续课题合作。
目前小罗全平台关注量61,000+,交流群总成员1400+,大部分来自国内外顶尖院校/医院,期待您的加入!!
由于近期入群推销人员较多,已开启入群验证,扫码添加我的联系方式,备注姓名-单位-科室/专业,即可邀您入群。
知识星球
如需获取推文中提及的各种资料,欢迎加入我的知识星球!
一、引言
约15%的结直肠癌(CRC)患者存在MSI,其在CRC的临床管理中起着关键作用,具有重要的诊断、预后和治疗意义。
微卫星不稳定性(MSI)是一种肿瘤基因型,其特征为被称为微卫星的重复DNA序列出现错配错误,由DNA错配修复(MMR)系统缺陷导致,该系统负责修复DNA复制过程中出现的错误,因此MSI是错配修复缺陷(dMMR)的标志。
MSI是林奇综合征(LS)的标志,LS是结直肠癌最常见的遗传易患形式,且MSI肿瘤对免疫检查点抑制剂治疗敏感。2017年,这种基因组不稳定表型成为美国食品药品监督管理局(FDA)批准的首个泛癌生物标志物,允许对患有不可切除或转移性MSI实体瘤的患者使用 pembrolizumab进行治疗 。
鉴于MSI在患者护理中的诸多意义,许多医学组织如英国国家卫生与临床优化研究所(NICE)和美国国家综合癌症网络(NCCN),都推荐对所有新诊断的CRC患者进行MSI状态的普遍筛查 。
dMMR/MSI可通过免疫组织化学(MMR-IHC)检测MMR蛋白的缺失和/或通过聚合酶链反应(MSI-PCR)、下一代测序(NGS)等分子检测方法进行诊断。
MMR-IHC检测需要良好的组织固定、切片制备时间、经验丰富的病理学家,且会消耗组织材料,对于小肿瘤而言,组织材料可能非常有限。
MSI-PCR检测需要特定的基础设施,通常周转时间较长,可能会延迟治疗决策,而NGS成本过高,无法常规使用。在过去二十年中,随着生物标志物数量稳步增加,MMR-IHC和MSI-PCR检测给病理学家和技术人员带来了日益增加的工作量 。
鉴于全球病理学家短缺,利用人工智能(AI)可以减轻病理学家的工作量,从而缓解MSI检测负担 。2019年的一项研究表明,深度学习可以从CRC的苏木精 - 伊红(H&E)染色切片中准确检测MSI 。
此后,多项研究展示了基于深度学习的CRC中从H&E染色切片检测MSI的分类器,证实了其补充标准MSI筛查方法的潜力 。
尽管取得了这些进展,但仍有一些问题阻碍基于AI的MSI预测工具在临床实践中的应用。
大多数现有研究将受试者工作特征曲线下面积(AUROC)作为主要性能指标。虽然该指标有助于比较多个机器学习模型的性能,但正如Kleppe所指出的,它可能掩盖模型严重缺乏泛化性的问题,且与临床实践无关 。
这里的模型泛化性是指模型在不同的独立验证队列(如不同种族)、不同临床环境(如使用不同扫描仪进行数字化)中保持一致的敏感性和特异性的能力。AUROC衡量的是模型对患者进行正确排序的能力。
在本研究中,高AUROC意味着MSI患者(平均)得分高于微卫星稳定(MSS)患者。因此,在不改变顺序的情况下改变所有得分,AUROC不会改变。然而,在临床环境中,选择一个阈值将患者分为阴性或阳性时,得分的改变可能会导致患者分类的巨大变化,改变模型的敏感性和特异性,进而导致误诊。
据作者所知,目前还没有研究评估从组织学切片预测MSI的AI工具的性能时,以一种能够使其在临床常规中使用的方式解决模型泛化性问题。在本研究中,作者建议关注敏感性、特异性和阴性预测值,以评估MSIntuit™ CRC(MSIntuit)的诊断准确性。
MSIntuit是一种AI预筛查解决方案,可利用原发性切除的结直肠肿瘤的H&E染色切片早期排除非MSI患者。
MSIntuit的输出结果为 “MSS-AI”(无需进一步检测)或 “未确定”(需要进行标准MSI检测)(图1a)。
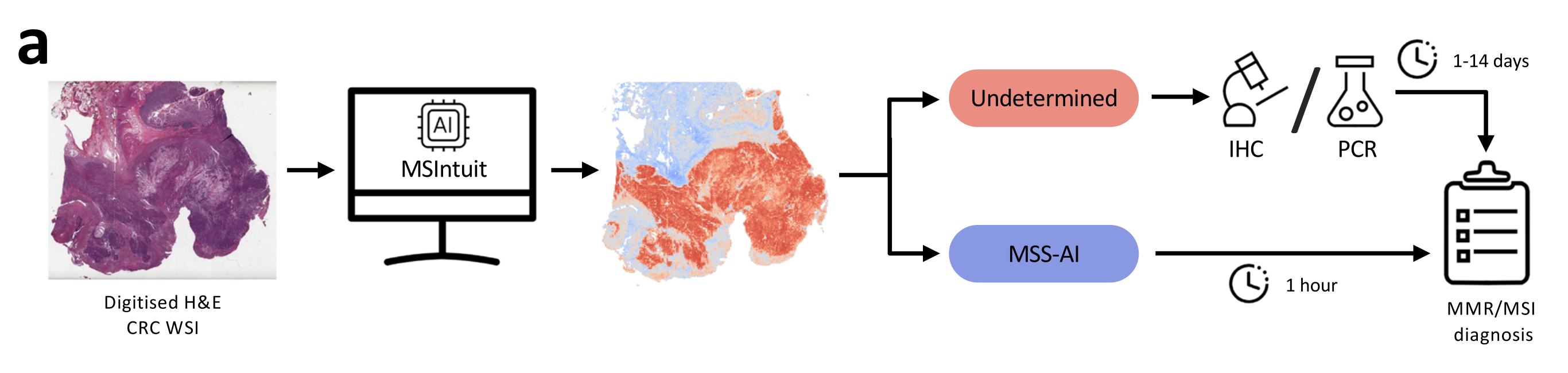
重要的是,作为排除性检测的MSI预筛查工具必须具有非常高的敏感性。因此,作者提出了一种方法,以确保在新的病理实验室中维持该工具的敏感性。
自监督学习(SSL)在计算机视觉领域已成为一种强大的方法,可从图像中学习丰富的向量表示。与传统的监督学习不同,SSL通过训练特征提取器来解决 “ pretext任务”,即不需要人工标注的任务。
这些任务可以是重建图像中被遮蔽的部分,或者为同一图像的两个增强版本生成相似的表示 。MSIntuit利用了一个专为组织学定制的特征提取器,通过SSL在400万张结直肠癌病理图像上进行训练。

在本研究中,作者对MSIntuit在600例连续切除的CRC病例的大型外部队列中进行了盲法临床验证。作者发现,将MSIntuit用作预筛查工具可以排除近一半的非MSI人群,从而简化了MSI筛查流程。
作者的工具包括自动切片质量检查,并通过校准步骤解决了定义操作阈值的问题,使其可直接应用于临床实践。作者还通过研究MSIntuit在扫描仪内部和之间的变异性以及不同肿瘤块之间的变异性,解决了临床常规使用中的关键问题。
二、数据+代码
2-1:数据可用性
本研究中使用的癌症基因组图谱(TCGA)队列的所有图像以及相关的微卫星不稳定性(MSI)状态数据,均可在https://portal.gdc.cancer.gov/和cBioPortal(https://www.cbioportal.org/)上公开获取。
来自病理人工智能平台(PAIP)队列的去标识化病理图像和注释,可通过向http://www.wisepaip.org/paip提交适当的数据访问请求来获取。
MPATH-DP200和MPATH-UFS数据集归法国Owkin公司所有,仅可应学术用途请求提供。本文提供了源数据。
2-2:代码可用性
- U-Net的一种实现方式可在https://github.com/milesial/Pytorch-UNet获取。
- Momentum Contrast v2(MoCov2)的实现可在https://github.com/facebookresearch/moco获取。
- Chowder算法的实现可在https://github.com/CharlieCheckpt/msintuit(https://zenodo.org/badge/latestdoi/670039349)获取 。
三、方法
3-1:全切片图像预处理
在训练任何模型之前,采用了一套预处理流程来降低数据维度并清理数据(图6a)。
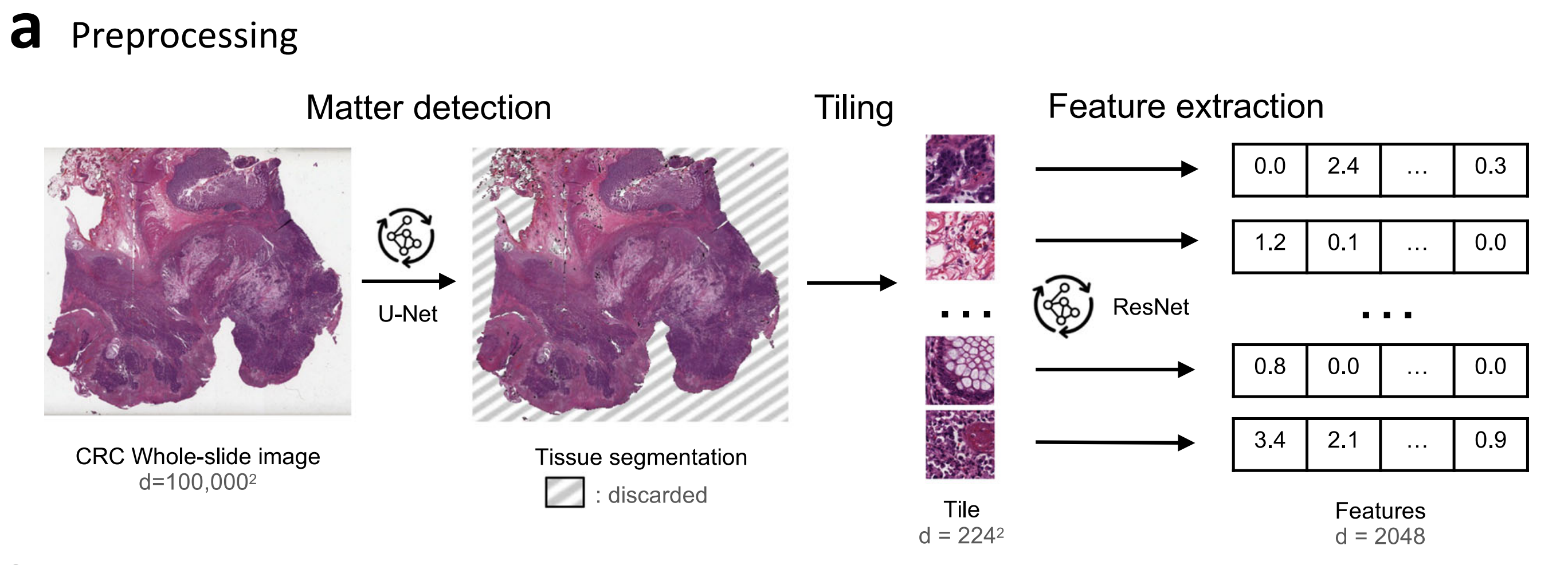
预处理流程的第一步是检测WSI上的组织:使用U-Net神经网络对图像中包含相关物质的部分进行分割,并去除模糊、笔痕等伪影以及背景 。
U-Net是一种广泛应用于生物医学图像分割任务的全卷积神经网络架构。
该U-Net网络先前在内部数据集的460张H&E和免疫组化(IHC)切片上进行训练,这些切片的组织经过人工标注,并在115张切片上进行验证,Dice系数达到0.96。将该网络应用于从WSI中提取的尺寸为2048×2048μm(512×512像素,分辨率为4MPP)的图像。
第二步是将切片分割成较小的图像,即“图块”,尺寸为112×112μm(224×224像素,分辨率为0.5MPP)。U-Net模型检测到图块中至少50%为前景时,该图块才会被保留。训练时,每张切片最多提取8000个图块,而推理时则提取所有图块。
最后一步是从每个图块中提取特征:使用具有50层的宽残差网络(ResNet50,每个模块的瓶颈通道数是原来的两倍),通过动量对比(MoCo)v2以自监督方式进行训练,提取2048个相关特征 。
该网络在来自TCGA-COAD数据集的400万个图块上进行训练,采用大量数据增强手段(随机裁剪、随机翻转、颜色抖动、随机灰度化、高斯模糊),且不使用任何标签。
在推理和训练过程中,特征提取器的权重均被固定。
3-2:模型描述
研究采用Chowder模型的变体,基于发现队列进行训练,利用全切片图像预处理步骤(见全切片图像预处理,图6c)末尾生成的切片特征(输入)来预测MSI状态(输出) 。
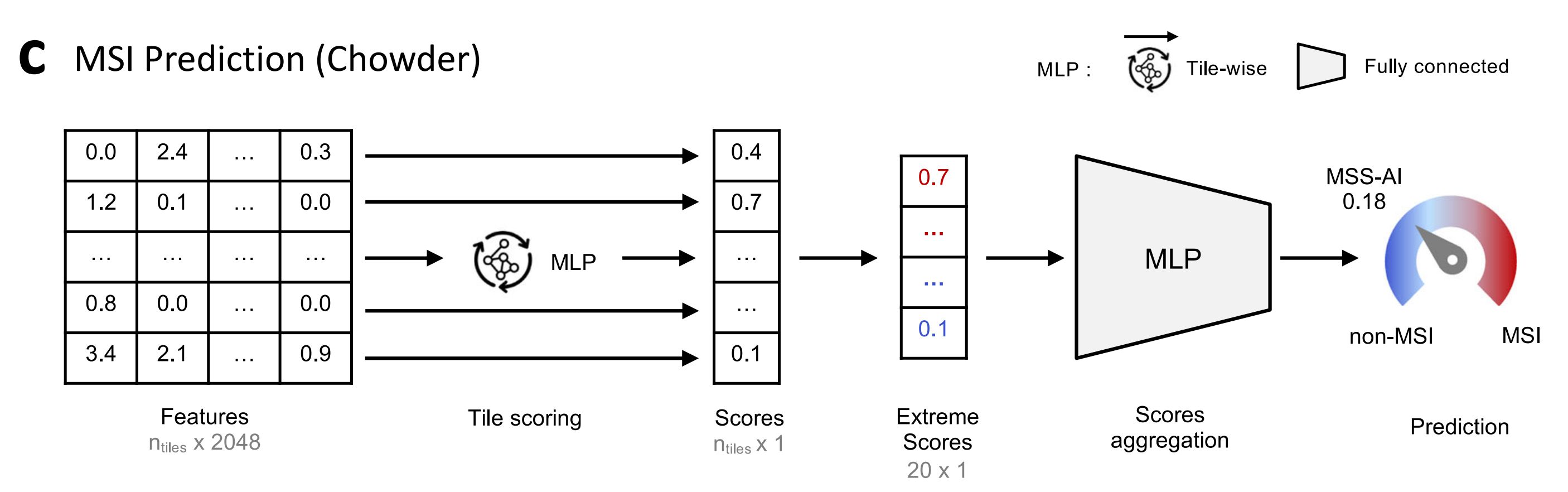
- 输入特征(Features):输入是维度为 ( n t i l e s × 2048 n_{tiles}×2048 ntiles×2048) 的图块特征矩阵,( n t i l e s n_{tiles} ntiles) 代表图块数量 ,2048是每个图块提取的特征数量。这些特征是经过全切片图像预处理得到的。
- 图块评分(Tile scoring):通过一个多层感知器(MLP)对每个图块的特征进行处理,输出每个图块对应的一个分数,得到维度为 (n_{tiles}×1) 的分数矩阵。
- 极端分数选取(Extreme Scores):从所有图块分数中选取排名前十和后十的分数(共20个分数 ,维度为 (20×1) )。图中用红色和蓝色分别突出显示了其中较高和较低的分数示例。
- 分数聚合(Scores aggregation):将选取的20个极端分数输入到另一个MLP中进行处理。
- 预测(Prediction):最终通过一个仪表盘样式的可视化方式呈现预测结果,显示为MSS - AI(一种非MSI状态,此处概率为0.18 )、non - MSI(非微卫星不稳定性)和MSI(微卫星不稳定性),指示样本属于不同MSI状态的概率情况。
Chowder模型的第一层是一个具有128个隐藏神经元且采用sigmoid激活函数的多层感知器(MLP),其作用是对每个图块的特征进行处理,输出一个分数。
然后,选取分数排名前十的和后十的分数进行拼接,并将其输入到另一个具有128个和64个隐藏神经元且同样采用sigmoid激活函数的MLP中。
该模型以二元交叉熵作为损失函数进行训练,并且根据发现集中MSI的流行程度对权重进行平衡。
四、问题解答
首先我需要说明一下,这并不是一个成功的提问示例,因为他没有分点陈述,如果不是我比较有耐心,我可能就会漏掉部分关键点。
(PS:此外,我觉得提问者还缺少一点点客套的礼貌用语,虽然你是付费用户,我有义务解答你的问题,但是回答程度就看我心情了。不过好在我现在见到的奇葩多了,容忍程度已经被练出来了。但是,我还是看着有点膈应,下次提问记得最起码打个招呼)
4-1:训练数据
写作技巧
提问里提到了,文章的训练数据是400万张病理图片,这里其实作者写作的技巧。

注意用词,这里用的是images,而不是slides。这就是在利用读者的潜意识,因为人类潜意识中更关注数字,而不是数字背后的名词。

但是,如果真是数据量很大的,作者就会明确表示出slides。
400万这个数据怎么来的?
其实也比较好理解,600*8000=4,800,000 ,由于第二个红框中提到,8000是max值,所以总数是小于这个值,但是大于4,000,000的。

至于为啥要把这个数据单拎出来分析呢?因为,作者采用的特征提取器是在这个数据上训练的,此外,模型做了一些改动。

所以我不清楚提这个问题的人,有没有修改ResNet的参数——理论上这样修改以后,可以提升特征提取的能力。
至于提问中提到的权重文件,这个就不要想了,因为看看一作单位就知道了——法国 Owkin 公司。

所以,这种文章,我看到以后都不会深入分析,更不会想着去复现,因为基本很难去得到自己想要的效果。
4-2:模型微调
微调的定义
- 微调(Fine-tuning) 是迁移学习的一种方法,指在预训练模型的基础上,通过调整部分或全部参数,使其适应新任务的过程。
- 关键目标:利用预训练模型在通用任务(如ImageNet分类)中学到的特征,减少新任务(如医学图像分类)的训练成本。
微调是否需要预训练权重?
- 必须性:微调的前提是存在预训练权重。若没有作者的权重,复现需重新训练或寻找替代方案。
- 论文的特殊性:作者的自监督预训练依赖大量私有数据(400万张病理图),公开数据集难以复现同等效果。
替代方案
- 重新预训练:若用户有足够病理数据,可尝试自监督预训练(如MoCo、SimCLR等算法)。

- 使用其他预训练模型:例如CTPath(你老板推荐的)或者最新的基础模型(UNI、MUSK……)
微调是修改模型吗?
答案:是的,但分两种情况:
- 冻结特征提取器:仅修改后续分类层(如全连接层),此时模型底层参数固定,微调的是“特征计算部分”。
- 解冻特征提取器:调整整个模型(包括 ResNet50 的部分或全部层),此时模型结构和参数均被修改。
论文中的情况:作者固定了 SSL 预训练的 ResNet50(仅用其提取特征),后续通过 Chowder 模型(MLP 层)进行微调。

4-3:应该在特征提取器还是后续部分微调?
- 仅微调分类层:冻结ResNet50的主干,仅训练新增的分类层。适用于小数据集或特征提取器足够强。
- 端到端微调:解冻全部层,调整所有参数。适用于大数据集或任务差异较大时。
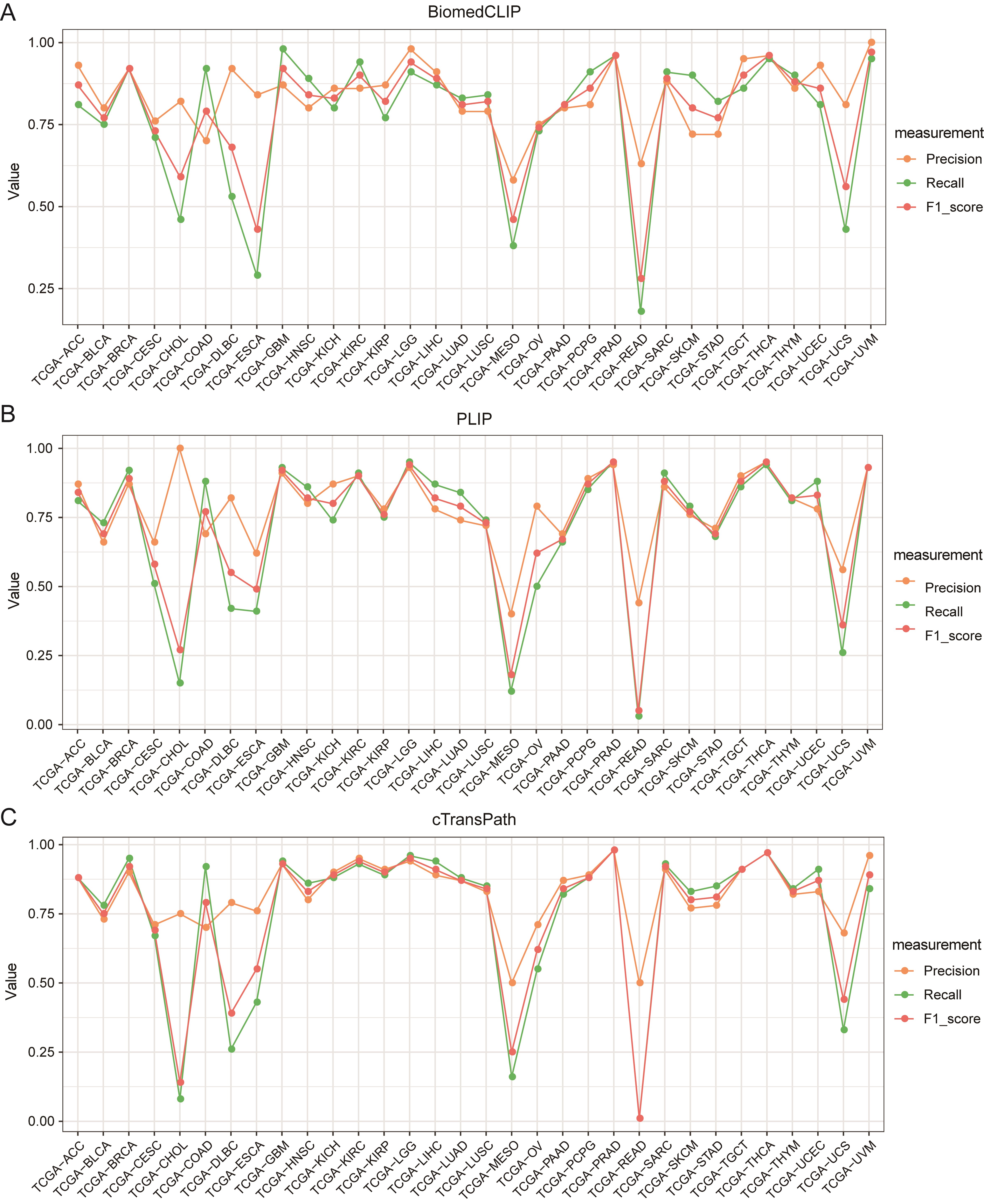
4-4:为什么选CTranspath?
原因很简单,因为CTransPath 是专门在组织病理图像上预训练的模型,其泛化能力优于 ImageNet 预训练模型。
并且有大量的实验证明了CTransPath的性能,感兴趣可以自行研究一下,这里简单展示一个模型对比图。
结束语
本期推文的内容就到这里啦,如果需要获取医学AI领域的最新发展动态,请关注小罗的推送!如需进一步深入研究,获取相关资料,欢迎加入我的知识星球!


















 362
362

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









